Bigtable transforms the developer experience with SQL support
Christopher Crosbie
Group Product Manager
Gary Elliott
Engineering Manager, Bigtable
Bigtable is a fast, flexible, NoSQL database that powers core Google services such as Search, Ads, and YouTube, as well as critical applications for customers such as PLAID and Mercari. Today, we’re announcing Bigtable support for GoogleSQL, an ANSI-compliant SQL dialect used by Google products such as Spanner and BigQuery. Now you can use the same SQL with Bigtable to write applications for AI, fraud detection, data mesh, recommendations, or any other application that would benefit from real-time data.
Bigtable SQL support allows you to query Bigtable data using the familiar GoogleSQL syntax, making it easier for development teams to work with Bigtable’s flexibility and speed. With over 100 SQL functions at launch, Bigtable SQL support also makes it easy to analyze and process large amounts of data directly within Bigtable, unlocking its potential for a wider range of use cases, ranging from JSON manipulation for log analysis, hyperloglog for web analytics, or kNN for vector search and generative AI.
At Plaid, a leading provider of customer experience (CX) solutions, Bigtable's enhanced SQL support and counters are game-changers for developers.
“Seamless SQL integration and efficient counter functionality will empower us to build more robust and scalable solutions for our customers. We applaud Bigtable's commitment to innovation and eagerly anticipate leveraging these enhancements to simplify working with big, complex, and fast moving data.” - Jun Kusahana, Executive Officer, VP of Engineering, Plaid
Let's get started and explore how GoogleSQL can enhance your Bigtable experience.
A SQL interface for a NoSQL database? How does that work?
Bigtable is one of the pioneering techs of the big data movement, inspiring popular open-source projects such as Apache HBase and Cassandra. One of its defining characteristics is its wide-column data model, which allows each row to have a different set of columns — and many thousands of them if necessary. This flexibility is beneficial for many use cases but leads to data models and access patterns that are quite different from the typical relational databases where SQL originated. Because of this, most NoSQL database systems had to rely on proprietary key-value APIs, even though SQL has been a skill in every developer’s tool belt as the de-facto data management standard for decades.
Bigtable SQL support adds new types and functions that align with wide-column data structures and enhance SQL with time-series capabilities. But while Bigtable SQL introduces expanded capabilities, its default behavior is designed to ensure that basic queries still behave as close to common SQL as possible. That said, Bigtable remains a NoSQL system, so you'll still need to optimize your schemas for performance using schema design best practices. This means that if you’re looking for a low-latency, scalable NoSQL database but don’t want to learn a new query API, SQL on Bigtable is an option that provides data model flexibility.
Let’s learn more about how to get started with some of these enhancements for flexible schema in SQL.
Support for flexible data models with map data types
In Bigtable’s wide column model, there is a row key and then a set of values, each grouped within a column family. When these column families are queried through SQL, Bigtable treats existing tables as a collection of SQL columns of type MAP<key, value> and a _key column for the row key. In essence, the Bigtable column family becomes a map data type in SQL.
With this approach, a flexible schema is maintained within the confines of SQL. Each Bigtable row can have many thousands of columns (if necessary) within column families and can be completely different between rows without having to pay for NULL storage or take other performance penalties.
The below example shows how you would return a column attribute of street from within the column family of address.
JSON
JSON is another commonly used format for storing flexible and dynamic data. Bigtable can enable quick retrieval across a range of JSON documents using a LIKE operator against a key range. You can then utilize various JSON SQL functions within GoogleSQL to work with these JSON documents.
For instance, you can retrieve the value of the JSON attribute abc from the latest version of data in the session column family along with the row key using the following query.
Time travel and version history
Bigtable captures a timestamp with each write, which is an ideal model when you want to quickly return the history of a particular item, for example, averaging readings from a sensor or reviewing the purchase history for a particular product. You can also set a TTL on items grouped within column families, automating the process of removing data when it’s no longer needed.
While useful, this pattern is quite different from a traditional SQL table where each value is only the most recently written value. In Bigtable SQL, the default response is what you would expect from a traditional SQL database — only the last updated value is returned. However, Bigtable SQL introduces the concept of history, letting you return all the historical results too.
The above query returns home addresses for the user’s entire history with timestamps that show when different changes took effect.
Similarly, you can request the value as of a certain point in time.
In this case, since the address change below happened in 2020 and the next change didn’t happen until 2023, it is returned as the valid address as of the 2022 timestamp provided.
Key use cases
With this launch, Bigtable extends its API with SQL support to reach different types of users with varying use cases. This expansion caters to application developers who favor SQL for building efficient operational systems, as well as data scientists who demand low-latency responses to their SQL query requests, to keep their GPUs busy.
Here, we list several examples of the most common scenarios for GoogleSQL on Bigtable.
-
NoSQL migrations: SQL support means easier migrations from other wide column databases such as HBase and Cassandra. With GoogleSQL support and its extensions to support wide-column data models, the migration process from Cassandra’s SQL-like query language, CQL, or Apache Phoenix on HBase, should be greatly simplified.
“SQL support made it so much easier to grow adoption of Bigtable at Globo, which has historically relied heavily on Cassandra.” - Michel Aquino, Software engineer, Globo
-
Interactive and ever-changing data: A wide-column approach to SQL allows you to effortlessly add new data points as they emerge and gracefully retire outdated information, helping your application to stay agile and responsive in the face of evolving data.
-
Low-latency lookup of non-uniform data: You may want to use SQL to quickly obtain the full context of information available for a particular key, but each record contains a different set of fields. Having full context available with different fields and low latency is useful in real-time decision making applications such as fraud detection, RAG pipelines, recommendation engines, and model training.
-
BigQuery serving layer: BigQuery is loaded with capabilities for performing complex calculations, data manipulation, and machine learning. However, distributing the results of this analysis often becomes a challenge if you need very high QPS, single-digit millisecond latency, consistent response times, or global deployments. Customers such as Ricardo have found success by combining BigQuery with a Bigtable serving layer. You can automatically transfer BigQuery’s pre-computed results into Bigtable for serving and using a SQL language across both systems.
-
SQL-based time-series solutions: Applications that need to ingest and query high volumes of data that consists of measurements and the times when the measurements were recorded can take advantage of Bigtable’s data model to cost-effectively collect, manage, and analyze this data using GoogleSQL’s functions for working with time data.
-
Write-time aggregates: If you want to aggregate your values at write time, you can use Bigtable distributed counters to take care of the heavy lifting associated with making sure values are merged correctly at scale and across the globe. You can then display those metrics with a simple GoogleSQL SELECT clause including functions like HLL_COUNT.EXTRACT.
Getting started
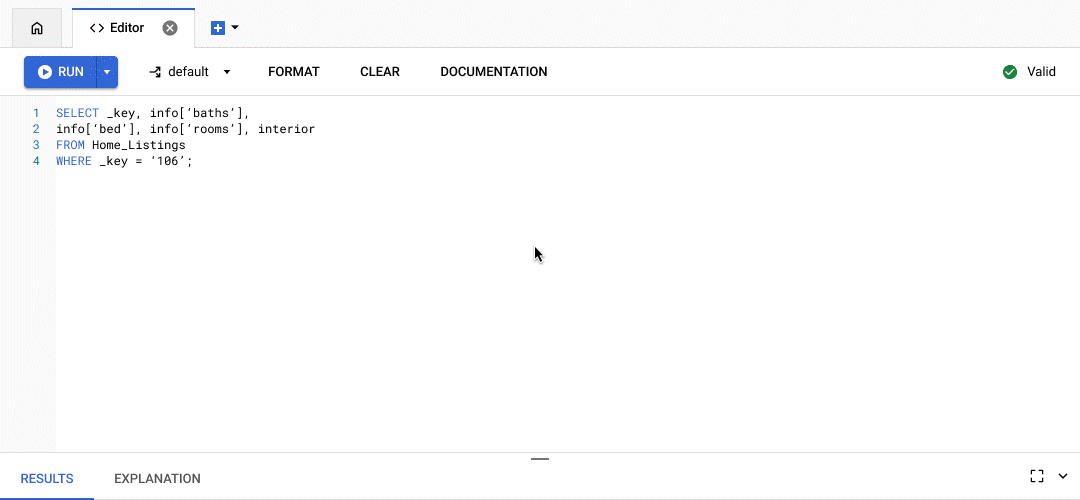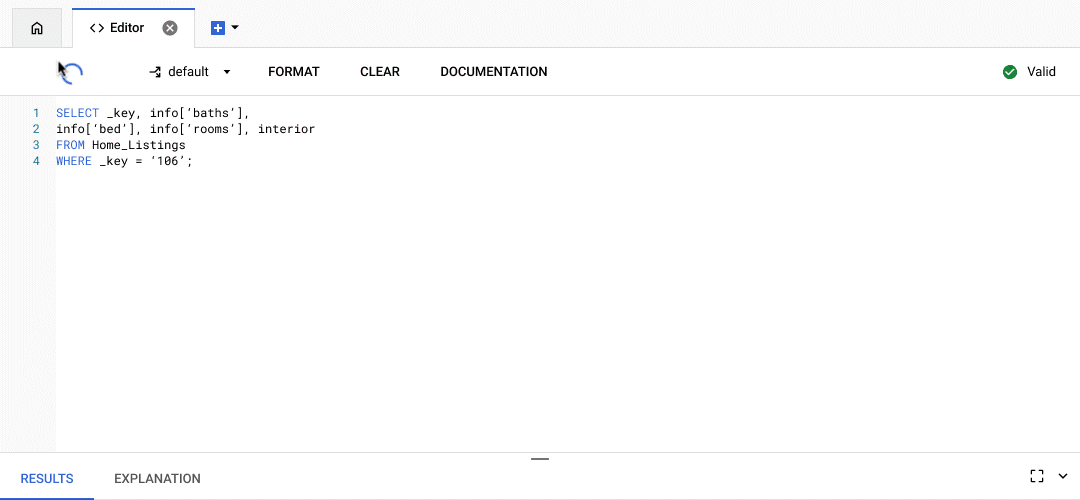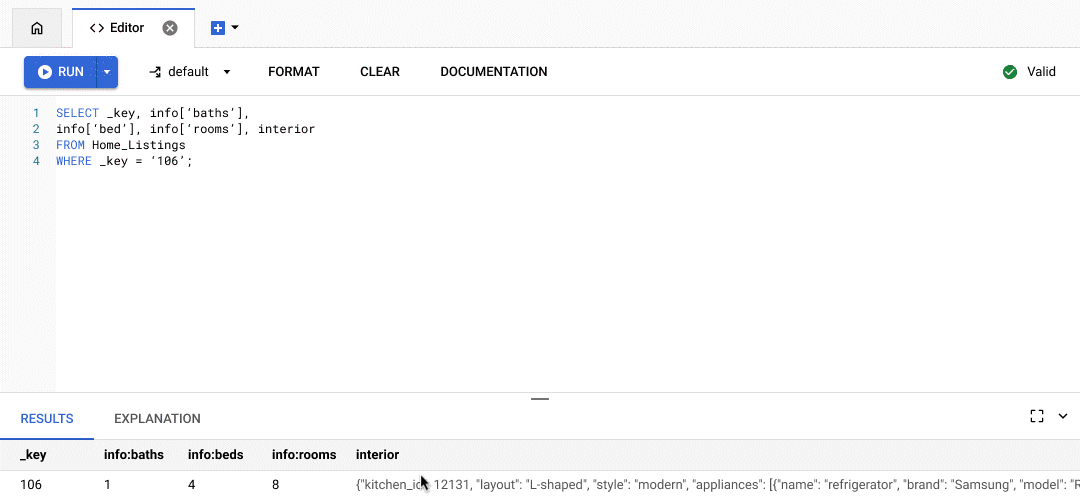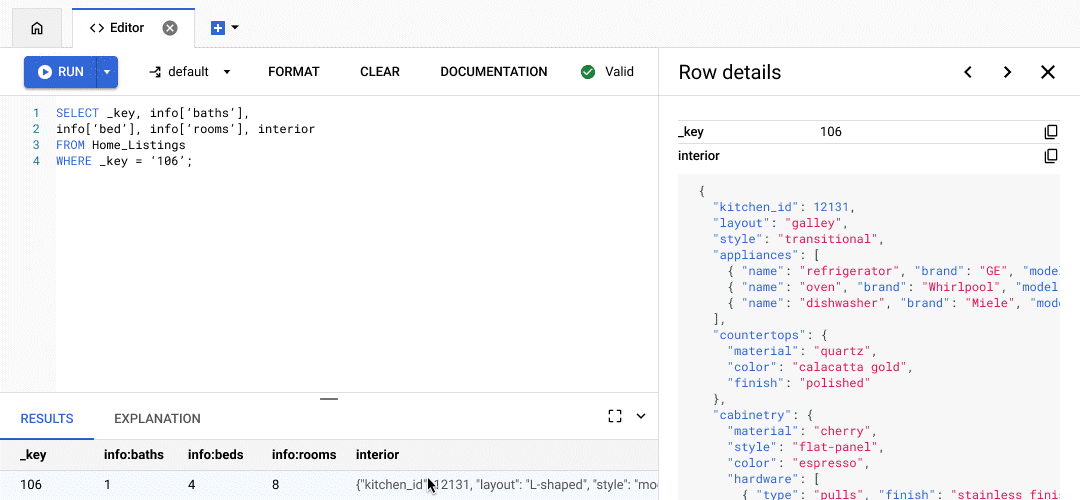
You can type your SQL queries into the SQL editor that’s available as part of Bigtable Studio.
To launch a new SQL editor tab, in the landing page, click <> New Editor button.
You can create additional editor tabs as needed using the + button.
Bigtable SQL is also available from both the Java and Python client libraries,with more options coming soon.
During this Preview phase, our primary focus is supporting common key-value access patterns with SELECT statements and laying foundations for future capabilities. While operations like JOINs or GROUP BYs, typical in relational databases, aren't available just yet, the future is bright. Stay tuned for upcoming enhancements to Bigtable's SQL support, as it evolves into a comprehensive application toolkit for developing real-time applications.
Learn more
-
Find out more about distributed counting with Bigtable

