What’s happening in BigQuery: Adding speed and flexibility with 10x streaming quota, Cloud SQL federation and more
Evan Jones
Technical Curriculum Developer, Google Cloud
We’ve been busy this summer releasing new features for BigQuery, Google Cloud’s petabyte-scale data warehouse. BigQuery lets you ingest and analyze data quickly and with high availability, so you can find new insights, trends, and predictions to efficiently run your business. Our Google Cloud engineering team is continually making improvements to BigQuery to accelerate your time to value.
Recently added BigQuery features include a newly built back end with 10x the streaming quota, the ability to query live from Cloud SQL datasets, and the ability to run your existing TensorFlow models in BigQuery. These new features are designed to help you stream, analyze, and model more data faster, with more flexibility.
Read on to learn more about these new capabilities and get quick demos and tutorial links so you can try these features yourself.
10x BigQuery streaming quota, now in beta
We know your data needs to move faster than your business, so we’re always working on adding efficiency and speed. The BigQuery team has completely redesigned the streaming back end to increase the default Streaming API quota by a factor of 10, from 100,000 to 1,000,000 rows per second per project. The default quota for maximum bytes per second has also increased, from 100MB per table to 1GB per project and there are now no table-level limitations. This means you get greater capacity and better performance for your streaming workloads like IoT and more.
Note that this quota increase is only applicable if you don’t need the best effort deduplication that’s offered by the current streaming back end. This is done by not populating the insertId field for each row inserted when calling the streaming API.
Check out this demo from Google Cloud Next ‘19 to see data stream 20 GB per second from simulated IoT sensors into BigQuery.

Check out the documentation for more on Streaming data into BigQuery.
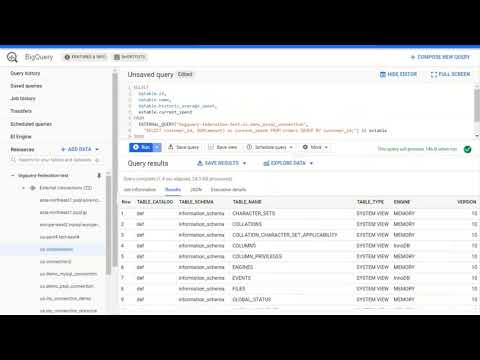
Query Cloud SQL from BigQuery
Data can only create value for your business when you put it to work, and businesses need secure and easy-to-use methods to explore and manage data that is stored in multiple locations. Within Google Cloud, we use our database tools and services to power what we do, including offering new Qwiklabs and courses each month. Internally, we manage the roadmap of new releases with a Cloud SQL back end. We then have an hourly Cloud Composer job that pipes our Cloud SQL transactional data from Cloud SQL into BigQuery for reporting. Such periodic export carries considerable overhead and the drawback that reports reflect data that is an hour old. This is a common challenge for enterprise business intelligence teams who want quicker insights from their transactional systems.
To avoid the overhead of periodic exports and increase the timeliness of your reports, we have expanded support for federated queries to include Cloud SQL. You can now query your Cloud SQL tables and views directly from BigQuery through a federated Cloud SQL connection (no more moving or copying data). Our curriculum dashboards now run on live data with one simple EXTERNAL_QUERY() instead of a complex hourly pipeline. This new connection feature supports both MySQL (second generation) and PostgreSQL instances in Cloud SQL.
After the initial one-time setup, you can write a query with the new SQL function EXTERNAL_QUERY(). Here’s an example where we join existing customer data from BigQuery against the latest orders from our transactional system in Cloud SQL in one query:
Note the cross database JOIN on rq.customer_id = c.customer_id. BigQuery actively connects to Cloud SQL to get the latest order data.
Getting live data from Cloud SQL federated in BigQuery means you will always have the latest data for reporting. This can save teams time, bring the latest data faster, and open up analytics possibilities. We hear from customers that they are seeing the benefits of immediate querying, too.
"Our data is spread across Cloud SQL and BigQuery. We had to maintain and monitor extract jobs to copy Cloud SQL data into BigQuery for analysis, and data was only as fresh as the last run,” says Zahi Karam, director of data science at Bluecore. “With Cloud SQL Federation, we can use BigQuery to run analysis across live data in both systems, ensuring that we're always getting the freshest view of our data. Additionally, we can securely enable less technical analysts to query Cloud SQL via BigQuery without having to set up additional connections."
Take a look at the demo for more:
Check out the documentation to learn more about Cloud SQL federated queries from BigQuery.
BigQuery ML: Import TensorFlow models
Machine learning can do lots of cool things for your business, but it needs to be easy and fast for users. For example, say your data science teams have created a couple of models and they need your help to make quick batch predictions on new data arriving in BigQuery. With new BigQuery ML Tensorflow prediction support, you can import and make batch predictions using your existing TensorFlow models on your BigQuery tables, using familiar BQML syntax. Here’s an example.
First, we’ll import the model from our project bucket:
Then we can quickly batch predictions with the familiar BigQuery ML syntax:
Want to run batch predictions at regular intervals as new data comes in? Simply set up a scheduled query to pull the latest data and also make the prediction. And as we highlighted in a previous post, scheduled queries can run as frequently as every 15 minutes.
Check out the BigQuery ML TensorFlow User Guide for more.
Automatic re-clustering now available
Efficiency is essential when you’re crunching through huge datasets. One key best practice for cost and performance optimization in BigQuery is table partitioning and clustering. As new data is added to your partitioned tables, it may get written into an active partition and need to be periodically re-clustered for better performance. Traditionally, other data warehouse processes like “VACUUM” and “automatic clustering” require setup and financing by the user. BigQuery now automatically re-clusters your data for you at no additional cost and with no action needed on your part.
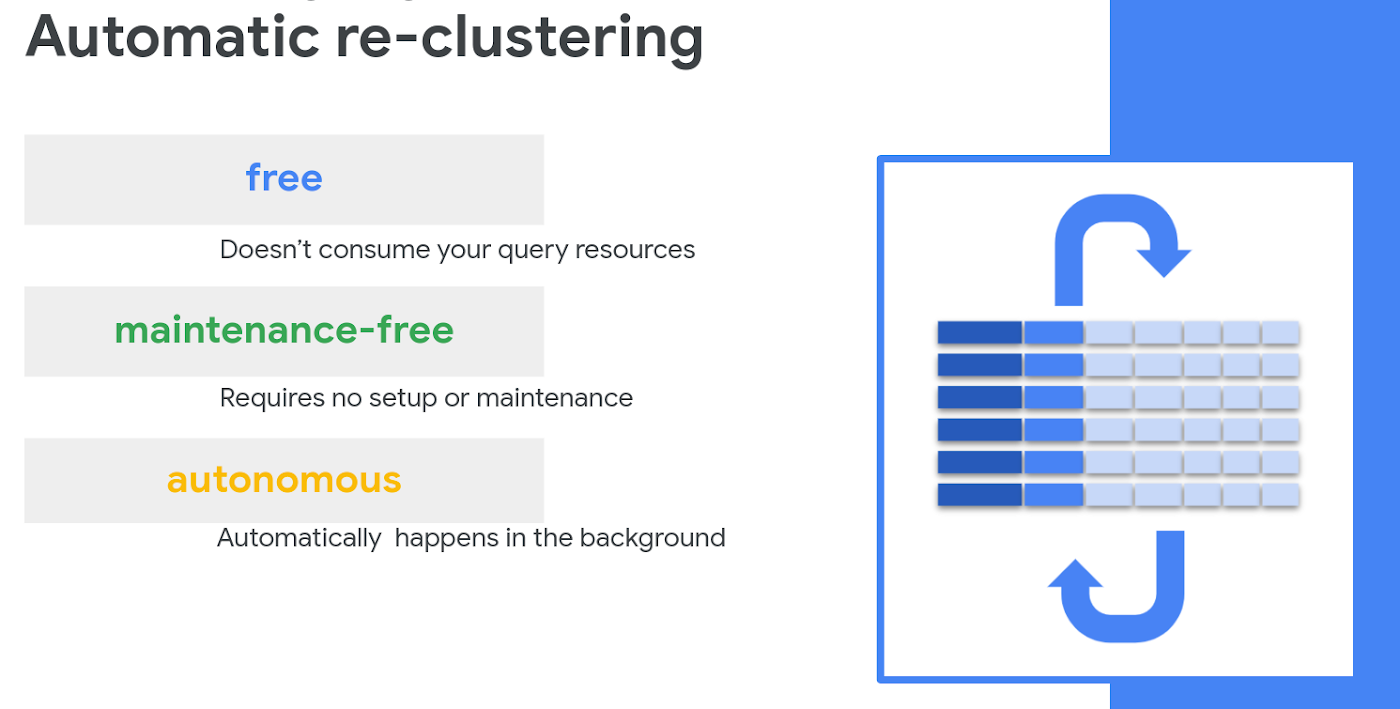
Check out our recent blog post Skip the maintenance, speed up queries with BigQuery's clustering for a detailed walkthrough. And get more detail in the documentation: automatic re-clustering.
UDF performance now faster
If you perform a query using JavaScript UDFs, it’ll now take around a second less to execute, on average, due to speedier logic for initializing the JavaScript V8 Engine that BigQuery uses to compute UDFs. Don’t forget you can persist and share your custom UDFs with your team, as we highlighted in our last post.
In case you missed it
For more on all things BigQuery, check out these recent posts, videos and how-tos:
Lab series: BigQuery for data analysts
GlideFinder: How we built a platform on Google Cloud that can monitor wildfires
To keep up on what’s new with BigQuery, subscribe to our release notes and stay tuned to the blog for news and announcements And let us know how else we can help.


