How NTUC Enterprise created a centralized Data Portal for frictionless access to data across business lines
Minh Nhat Nguyen
Principal Data Engineer, NTUC Enterprise
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialAs a network of social businesses, NTUC Enterprise is on a mission to harness the capabilities of its multiple units to meet pressing social needs in areas like healthcare, childcare, daily essentials, cooked food, and financial services. Serving over two million customers annually, we seek to enable and empower everyone in Singapore to live better and more meaningful lives.
With so many lines of business, each running on different computing architectures, we found ourselves struggling to integrate data across our enterprise ecosystem and enable internal stakeholders to access the data. We deemed this essential to our mission of empowering our staff to collaborate on digital enterprise transformation in ways that enable tailor-made solutions for customers.
The central issue was that our five main business lines, including retail, health, food, supply chain, and finance, were operating on different combinations of Google Cloud, on-premises, and Amazon Web Services (AWS) infrastructure. The complex setup drove us to create a unified data portal that would integrate data from across our ecosystem, so business units could create inter-platform data solutions and analytics, and democratize data access for more than 1,400 NTUC Enterprise data citizens. In essence, we sought to create a one-stop platform where internal stakeholders can easily access any assets they require from over 25,000 BigQuery tables and more than 10,000 Looker Studio dashboards.
Here is a step-by-step summary of how we deployed DataHub, an open-source metadata platform alongside Google Cloud solutions to establish a unified Data Portal that allows seamless access for NTUC Enterprise employees across business lines, while enabling secure data ingestion and robust data quality.
DataHub's built-in data discovery function provides basic functionality to locate specific data assets from BigQuery tables and Looker Studio dashboards for storage on DataHub. However, we needed a more seamless way to ingest the metadata of all data assets automatically and systematically.
We therefore carried out customizations and enhancements on Cloud Composer, a fully managed workflow orchestration service built on Apache Airflow, and Google Kubernetes Engine (GKE) Autopilot, which helps us scale out easily and efficiently based on our dynamic needs.
Next, we built data lineage, which enables the end-to-end flow of data across our tech stack, drawing data from Cloud SQL into Cloud Storage, then channeling the data back through BigQuery into Looker Studio dashboards for easy visibility. This was instrumental in enabling users across NTUC Enterprise’s business lines to access data securely and intuitively on Looker Studio.
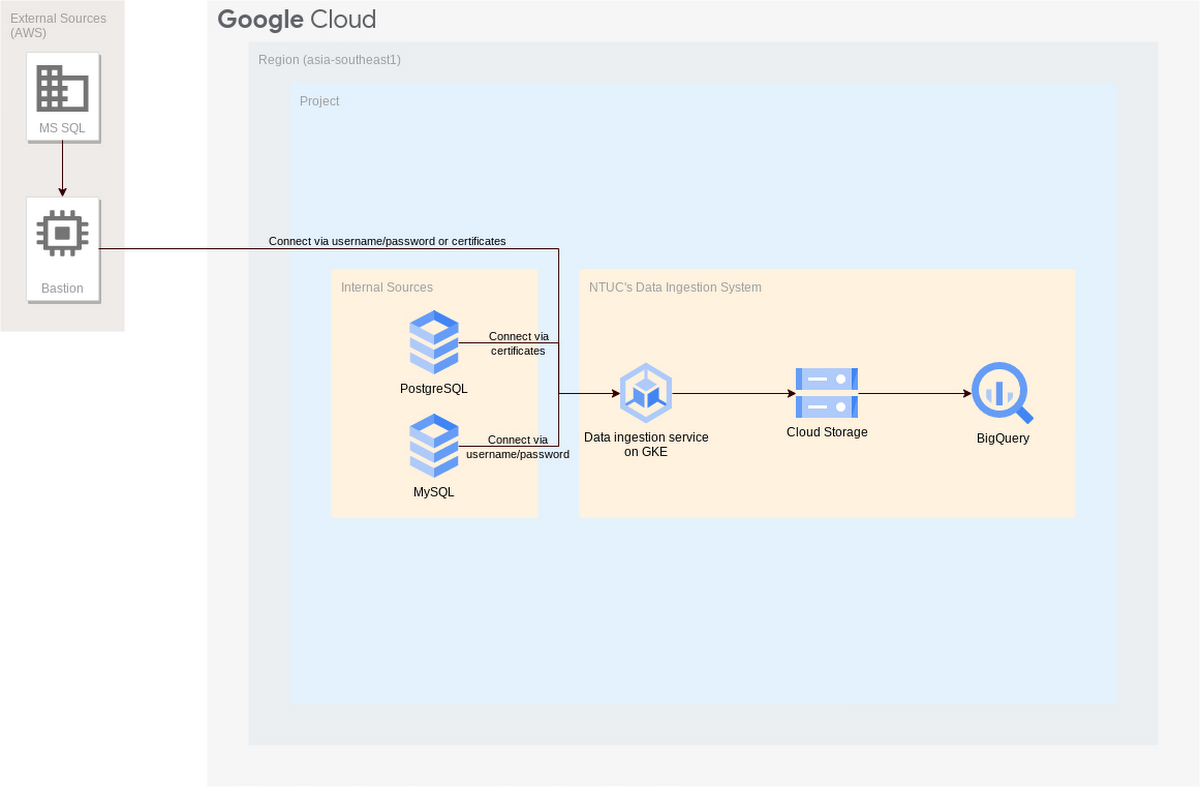
Having set up the basic platform architecture, our next task was to enable secure data ingestion. Sensitive data needed to be encrypted and stored in Cloud Storage before populating BigQuery tables. The system needed to be flexible enough to securely ingest data in a multi-cloud environment, including Google Cloud, AWS, and our on-premises infrastructure.
Our solution was to build an in-house framework to fit requirements of Python and YML, as well as GKE and Cloud Composer. We created the equivalent of a Collibra data management platform to suit NTUC Enterprise’s data flow (from Cloud Storage to BigQuery). The system also needed to conform to NTUC Enterprise data principles, which are as follows:
All data in our Cloud Storage data lake must be stored in a compressed form like Avro, a data security service
Sensitive columns must be hashed using Secure Hash Algorithm 256-bit (SHA-256)
The solution must be flexible for customization depending on needs
Connection must be made by username and password
Connection must be made with certificates (public key and private key), including override functions in code
Connections require one logical table from hundreds of physical tables (MSSQL sharding tables)
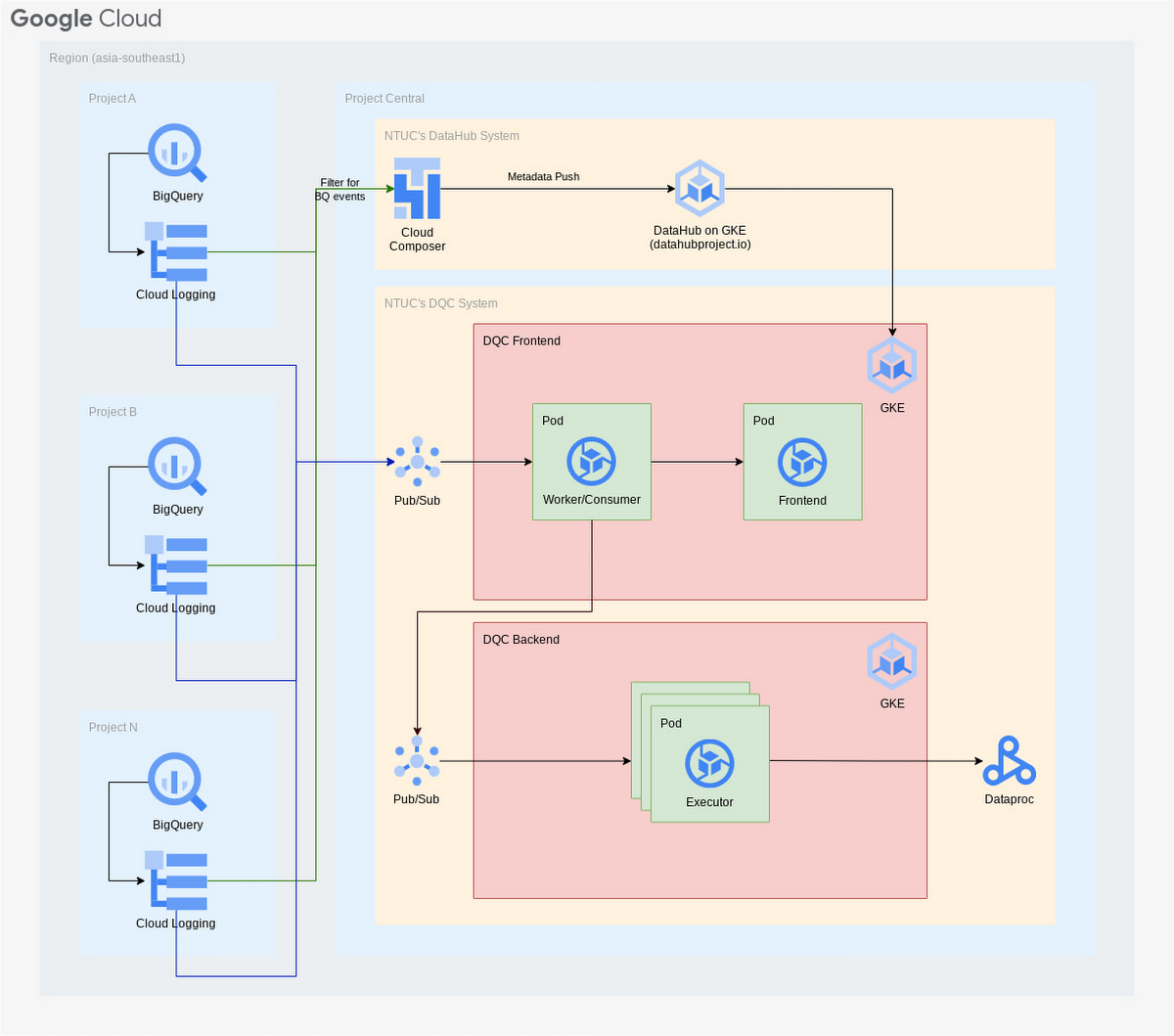
Our next task for the Data Portal was creating an automated Data Quality Control service to enable us to check data in real-time whenever a BigQuery table is updated or modified. This liberates our data engineers, who were previously building BigQuery tables by manually monitoring hundreds of table columns for changes or anomalies. This was a task that used to take an entire day, but is now reduced to just five minutes. We enable seamless data quality in the following way:
Activity in BigQuery tables is automatically written into Cloud Logging, a fully managed, real-time log management service with storage, search, analysis, and alerts
The logging service can then filter out events from BigQuery into Pub/Sub for datastreams that are then channeled into Looker Studio, where users can easily access the specific data they need
In addition, the Data Quality Control service sends notifications to users whenever someone updates BigQuery tables incorrectly or against set rules, whether that is deleting, changing or adding data to columns. This enables automated data discovery, without engineers needing to go intoBigQuery to look up tables
These steps enable NTUC Enterprise to create a flexible, dynamic, and user-friendly Data Portal that democratizes data access across business lines for more than 1,400 platform users, opening up vast potential for creative collaboration and digital solution development. In the future, we plan to look at how we can integrate even more data services into the Data Portal, and leverage Google Cloud to help develop more in-house solutions.


