Migrating IBM DataStage to Google Cloud
Sonakshi Pandey
Data Analytics Leader
Kalpita Raut
Data Analytics Cloud Consultant
In today's data-driven world, organizations rely on efficient and scalable data integration solutions to unlock valuable insights and drive informed decision-making. As technology evolves, so do the demands of managing data. Migrating from traditional data integration platforms to cloud-based solutions has become a strategic imperative, and Google Cloud provides several ways to approach the migration process. In this blog, we discuss the various strategies of migrating from on-prem IBM Datastage to Google Cloud and the advantages of the corresponding approaches.
IBM DataStage is a data integration tool that helps you design, build, and run jobs to move and transform data. It supports both ETL (extract, transform, load) and ELT (extract, load, transform) patterns. IBM DataStage supports a variety of data sources to a variety of targets, including the Netezza database.
IBM DataStage is a powerful data integration platform that can help businesses to manage their data more effectively. However, there are some disadvantages to having on-premises. It can be expensive to purchase and maintain. Businesses need to invest in hardware, software, and licensing costs, as well as the cost of hiring and training staff to manage the system. Additionally, it is difficult to scale. As businesses grow, they need to purchase additional hardware and software to accommodate more data and users. It is complex to set up and manage. Businesses need to have a team of skilled IT professionals to manage the system and ensure that it is running smoothly.
By adopting Google Cloud to run IBM DataStage transformations, businesses gain the agility and customization necessary to navigate the complex data landscape efficiently while maintaining compliance, keeping costs under control, and performance improvements, and ultimately positioning them to thrive in a dynamic environment.
Migration Strategy: Google Cloud equivalent architecture
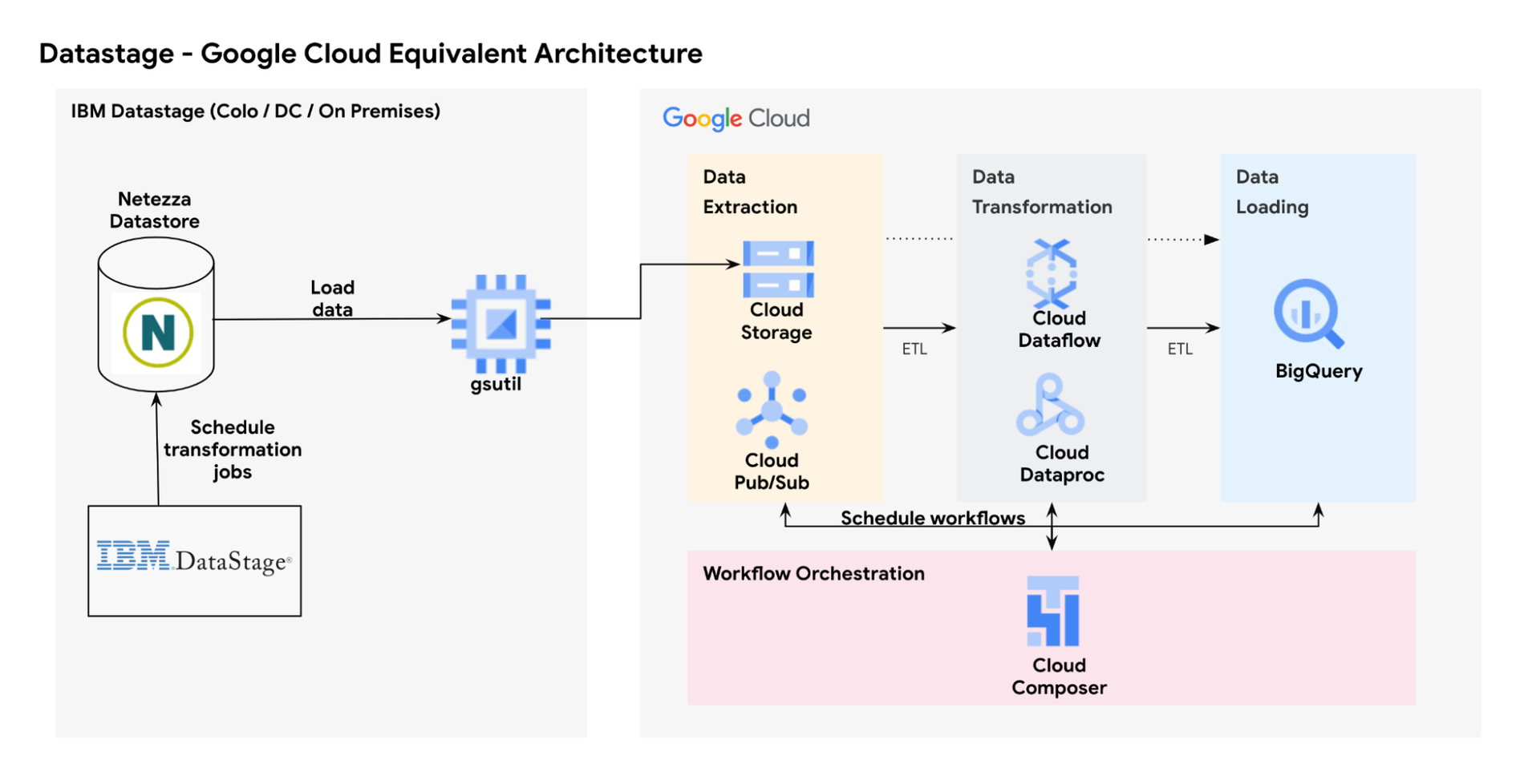
In order to migrate to Google Cloud, the process involves:
- Data extraction: Replace DataStage's data extraction functionality with Cloud Storage for batch data ingestion and Cloud Pub/Sub for real-time data ingestion.
- Data transformation: Transform data from Cloud Storage to BigQuery using either BigQuery stored procedures/Dataflow/serverless Dataproc which can serve as alternatives for transforming and processing data.
- Data loading: BigQuery becomes the ideal counterpart for DataStage's data loading capabilities, offering a serverless, highly scalable data warehouse solution.
- Workflow orchestration: Cloud Composer can be used to orchestrate data workflows, ensuring smooth execution.
1. Data extraction
IBM DataStage is a popular data integration platform that provides a wide range of features for data extraction, transformation, and loading (ETL). However, it can be expensive and complex to implement and maintain. Google Cloud offers a number of services that can be used to replace IBM DataStage's data extraction functionality, including Cloud Storage for batch data ingestion and Pub/Sub for real-time data ingestion.
Batch data ingestion with Cloud Storage
Cloud Storage is a highly scalable and durable object storage service that can be used to store and manage large amounts of data. To ingest batch data into Cloud Storage, you can use a variety of methods, including:
- Transfer jobs: You can use the Google Cloud console or the gsutil command-line tool to create transfer jobs that will automatically transfer data from your on-premises systems to Cloud Storage.
- Dataproc: You can use Dataproc, a managed Hadoop and Spark service, to process and ingest batch data into Cloud Storage.
- Cloud Data Fusion: You can use Data Fusion, a fully-managed data integration service, to build and manage batch data pipelines that ingest data into Cloud Storage.
- Real-time data ingestion with Pub/Sub: Pub/Sub is a fully-managed real-time messaging service that can be used to ingest data from a variety of sources, including sensors, devices, and applications. Once data is ingested into Pub/Sub, it can be processed and consumed by a variety of downstream applications, including data warehouses, data lakes, and streaming analytics platforms.
Real-time data into Pub/Sub
You can use a variety of methods, including:
- Pub/Sub client libraries: Google Cloud provides client libraries for a variety of programming languages, including Java, Python, and Go. You can use these client libraries to create publishers that will publish data to Pub/Sub.
- Cloud IoT Core: IoT Core is a fully-managed service that connects, manages, and secures millions of IoT devices. You can use IoT Core to publish data from IoT devices to Pub/Sub.
- Dataflow: Dataflow is a fully-managed streaming analytics service that can be used to process and ingest real-time data into Pub/Sub.
2. Data transformation
Google Cloud offers a variety of services that can be used to transform data from Netezza SQL to BigQuery SQL. Three of the most popular options are BigQuery stored procedures, Dataflow, and serverless Dataproc.
BigQuery stored procedures are user-defined functions that can be stored in BigQuery and executed on demand. They can be used to perform a variety of data transformation tasks, such as filtering, aggregating, and joining data. One of the benefits of using BigQuery stored procedures for data transformation is that they are very efficient. They are executed directly in the BigQuery engine, so there is no need to move data around. Additionally, BigQuery stored procedures can be parallelized, so they can handle large datasets quickly.
You can use a BigQuery stored procedure to filter data from a Cloud Storage file and load it into a BigQuery table. You can also use a BigQuery stored procedure to join two Cloud Storage files and load the joined data into a BigQuery table.
Dataflow is a fully-managed streaming analytics service that can be used to process and transform data in real time or in batch mode. Dataflow pipelines can be used to transform data from Cloud Storage to BigQuery, and they can also be used to perform other data processing tasks, such as machine learning and data filtering. One of the benefits of using Dataflow for data transformation is that it is very scalable. Dataflow pipelines can be scaled up or down to meet the needs of your workload. Additionally, Dataflow pipelines are very reliable, and they can handle large datasets with ease.
You can use a Dataflow pipeline to read data from a Cloud Storage file, transform it using Apache Spark, and load it into a BigQuery table. For example, you can use a Dataflow pipeline to split a CSV file into individual rows and load the rows into a BigQuery table.
Serverless Dataproc is a fully-managed service that allows you to run Apache Spark workloads without having to provision and manage your own cluster. Serverless Dataproc can be used to transform data from Cloud Storage to BigQuery, and it can also be used to perform other data processing tasks. One of the benefits of using serverless Dataproc for data transformation is that it is very easy to use. You simply need to submit your Spark job to the serverless Dataproc service, and the service will take care of the rest. Additionally, serverless Dataproc is very scalable, so you can easily scale your data transformation pipelines to meet the needs of your workload.
You can use a serverless Dataproc Spark job to read data from a Cloud Storage file, transform it using Apache Spark, and load it into a BigQuery table. For example, you can use a serverless Dataproc Spark job to convert a JSON file to a Parquet file and load the Parquet file into a BigQuery table.
Which option should you choose?
The best option for transforming data from Cloud Storage to BigQuery will depend on your specific needs and requirements. If you need a highly efficient and scalable solution, then Google BigQuery stored procedures or Dataflow would be a good choice. If you need a solution that is easy to use and manage, then serverless Dataproc would be a good choice.
Here is a table that summarizes the key differences between the three options:

3. Data loading
BigQuery is a serverless, highly scalable data warehouse solution that can be used as a counterpart for DataStage's data loading capabilities. BigQuery offers a superior data loading solution compared to IBM DataStage due to its scalability, speed, real-time data loading, seamless integration with the Google Cloud ecosystem, cost efficiency, user-friendliness, robust security, and management. BigQuery's serverless infrastructure and pay-as-you-go pricing model reduces operational overhead and capital costs.
BigQuery is a fully-managed data warehouse that offers a number of benefits over traditional ETL tools, including:
- Serverless architecture: BigQuery is a serverless data warehouse, which means that you don't need to provision or manage any infrastructure. BigQuery will automatically scale your resources up or down to meet the needs of your workload.
- High scalability: BigQuery is highly scalable, so you can easily handle large datasets. BigQuery can handle datasets of any size, from petabytes to exabytes.
- Real-time Data Loading: BigQuery supports real-time data loading, allowing organizations to ingest and analyze data as it arrives. This is crucial for applications requiring up-to-the-minute insights and responsive decision-making.
- Security and Compliance: Google Cloud provides robust security features and compliance certifications, ensuring data loading and storage meet stringent security and regulatory requirements.
- Managed Service: Google takes care of managing, monitoring, and maintaining the infrastructure, ensuring high availability and reliability. This allows organizations to focus on their core data loading and analytical tasks.
BigQuery can be used as a counterpart for DataStage's data loading capabilities in a number of ways. For example, you can use BigQuery to:
- Load data from a variety of sources: BigQuery can load data from a variety of sources, including Cloud Storage, Cloud SQL, and Dataproc. This means that you can use BigQuery to load data from any system that you are currently using.
- Transform data during loading: BigQuery can transform data during loading using SQL. This means that you can clean, filter, and aggregate data as you load it into BigQuery.
- Orchestrate data workloads: BigQuery can be used to schedule data loads. This means that you can automate the process of loading data into BigQuery using various Orchestration tools based on your requirements.
Here are a few examples of how you can use BigQuery to load data from DataStage:
- Use the BigQuery Data Transfer Service: The BigQuery Data Transfer Service is a fully-managed service that allows you to automate the process of loading data from a variety of sources into BigQuery. You can use the BigQuery Data Transfer Service to load data directly from DataStage into BigQuery or from DataStage to Cloud Storage to BigQuery.
- Use the BigQuery API: The BigQuery API is a RESTful API that allows you to interact with BigQuery programmatically. You can use the BigQuery API to load data from DataStage into BigQuery.
- Use a third-party tool: There are a number of third-party tools that can be used to load data from DataStage into BigQuery. For example, you can use the Fivetran connector for DataStage to load data from DataStage into BigQuery.
4. Workflow orchestration
The migration and on-going synchronization of data involves 100s of ETL processes. Many of these processes consist of (a) multiple steps which may be prone to failure and/or (b) dependencies which may require upstream jobs to complete successfully before a downstream job can run successfully. As a result, if your organization has specific requirements such as requiring an ability to restart processes which have failed or need to be re-run as a result of an upstream process running again, then Google Cloud proposes Cloud Composer. Composer is Google’s fully managed workflow orchestration service built on Apache Airflow. ETL workflows will be represented in Cloud Composer as Directed Acyclic Graphs (DAGs) that can be scheduled and manually triggered as needed.
While IBM Datastage does encompass workflow orchestration capabilities, Cloud Composer's core advantage lies in its ability to provide an agile and scalable solution that leverages the strengths of Apache Airflow, making it an attractive choice for organizations seeking seamless, adaptable, and reliable data pipeline management.
Here are some specific examples of how Cloud Composer/Airflow can be used to orchestrate data workflows more effectively:
- Parallel execution: Cloud Composer/Airflow can execute tasks in parallel, which can significantly optimize environment performance and cost.
- Dependency management: Cloud Composer/Airflow can automatically manage dependencies between tasks such as nested tasks in DAGs or managing a parent-child DAG relationship which can help to ensure that your data pipelines are executed in the right sequence reliably.
- Error handling: Cloud Composer/Airflow provides a number of features for handling errors during workflow execution, such as retrying failed tasks and notifying you of errors.
- Monitoring: Cloud Composer provides a built-in monitoring dashboard that gives you visibility into the status of your workflows and tasks.
Additional benefits of using Cloud Composer/Airflow
In addition to the benefits listed above, Cloud Composer/Airflow also offers a number of other benefits, including:
- Cloud-native: Cloud Composer/Airflow is a cloud-native solution, which means that it is designed to be deployed and managed in the cloud. This can offer a number of advantages, such as improved scalability and reliability.
- Extensibility: Cloud Composer/Airflow is extensible, which means that you can add custom features and functionality to meet the specific needs of your business.
- Vendor lock-in: Cloud Composer/Airflow is based on Apache Airflow, which is an open-source project. This means that you are not locked into a proprietary vendor, and you can easily switch to a different solution if needed.
Benefits of migrating IBM Datastage to Google Cloud
Migrating ETL workloads from IBM Datastage to Google Cloud provides you with the ability to tailor and scale the resources as needed for each job. Instead of deploying a one size fits all workload architecture targeting an “average” workload, Google Cloud enables a bespoke model where each workload resource can be customized based on your requirements, which help to cost-efficiently meet SLA targets. This customization results in performance and cost benefits, including:
- Scalability: Google Cloud infrastructure provides on-demand scalability, allowing you to scale resources as your data processing needs evolve.
- Cost efficiency: With a pay-as-you-go model, Google Cloud helps control costs by optimizing resource allocation based on actual usage.
- Integrated ecosystem: Google Cloud offers a comprehensive ecosystem of tools that seamlessly work together, simplifying the design, deployment, and management of data workflows.
- Real-time insights: Google Cloud’s real-time data processing capabilities enable quick and informed decision-making
Conclusion
Google Cloud provides a multifaceted approach to migration, with customization as its cornerstone. This tailoring of resources to match the unique requirements of each ETL job not only enhances performance but also ensures cost efficiency, which is further bolstered by the scalability and pay-as-you-go model. The integrated ecosystem of Google Cloud simplifies data workflow management and, combined with real-time data processing capabilities, empowers organizations to make swift, data-informed decisions.
Next Steps
If you want to start small, you can start exploring BigQuery and take advantage of its free-usage tier and no cost sandbox to get started. If you are considering migrating IBM DataStage to Google Cloud, please refer to the official documentation with more details on the prerequisites and foundational setup required in Google Cloud prior to getting started.

