Give your data processing a boost with Dataflow GPU
Shan Kulandaivel
Product Lead, Streaming
We are excited to bring GPUs to the world of big data processing, in partnership with NVIDIA, to unlock new possibilities for you. With Dataflow GPU, users can now leverage the power of NVIDIA GPUs in their data pipelines. This brings together the simplicity and richness of Apache Beam, serverless and no-ops benefits of Dataflow, and the power of GPU based computing. Dataflow GPUs are provisioned on-demand and you only pay for the duration of your job.
Businesses of all sizes and industries are going through hard data driven transformations today. A key element of that transformation is using data processing in conjunction with machine learning to analyze and make decisions about your systems, users, devices and the broader ecosystem that they operate in.
Dataflow enables you to process vast amounts of data (including structured data, log data, sensor data, audio video files and other unstructured data) and use machine learning to make decisions that impact your business and users. For example, users are using Dataflow to solve problems such as detecting credit card fraud, physical intrusion detection by analyzing video streaming, and detecting network intrusion by analyzing network logs.
Benefits of GPUs
Unlike CPUs, which are optimized for general purpose computation, GPUs are optimized for parallel processing. GPUs implement an SIMD (single instruction, multiple data) architecture, which makes them more efficient for algorithms that process large blocks of data in parallel. Applications that need to process media and apply machine learning typically benefit from the highly parallel nature of GPUs.
Google Cloud customers can now use NVIDIA GPUs to accelerate data processing tasks as well as image processing and machine learning tasks such as predictions. To understand the potential benefits, NVIDIA ran tests to compare the performance of the Dataflow pipeline that uses a TensorRT optimized BERT (Bidirectional Encoder Representations from Transformers) ML model for natural language processing. The following table captures the results of the tests: using Dataflow GPU to accelerate the pipeline resulted in an order of magnitude reduction in CPU and memory usage for the pipeline.
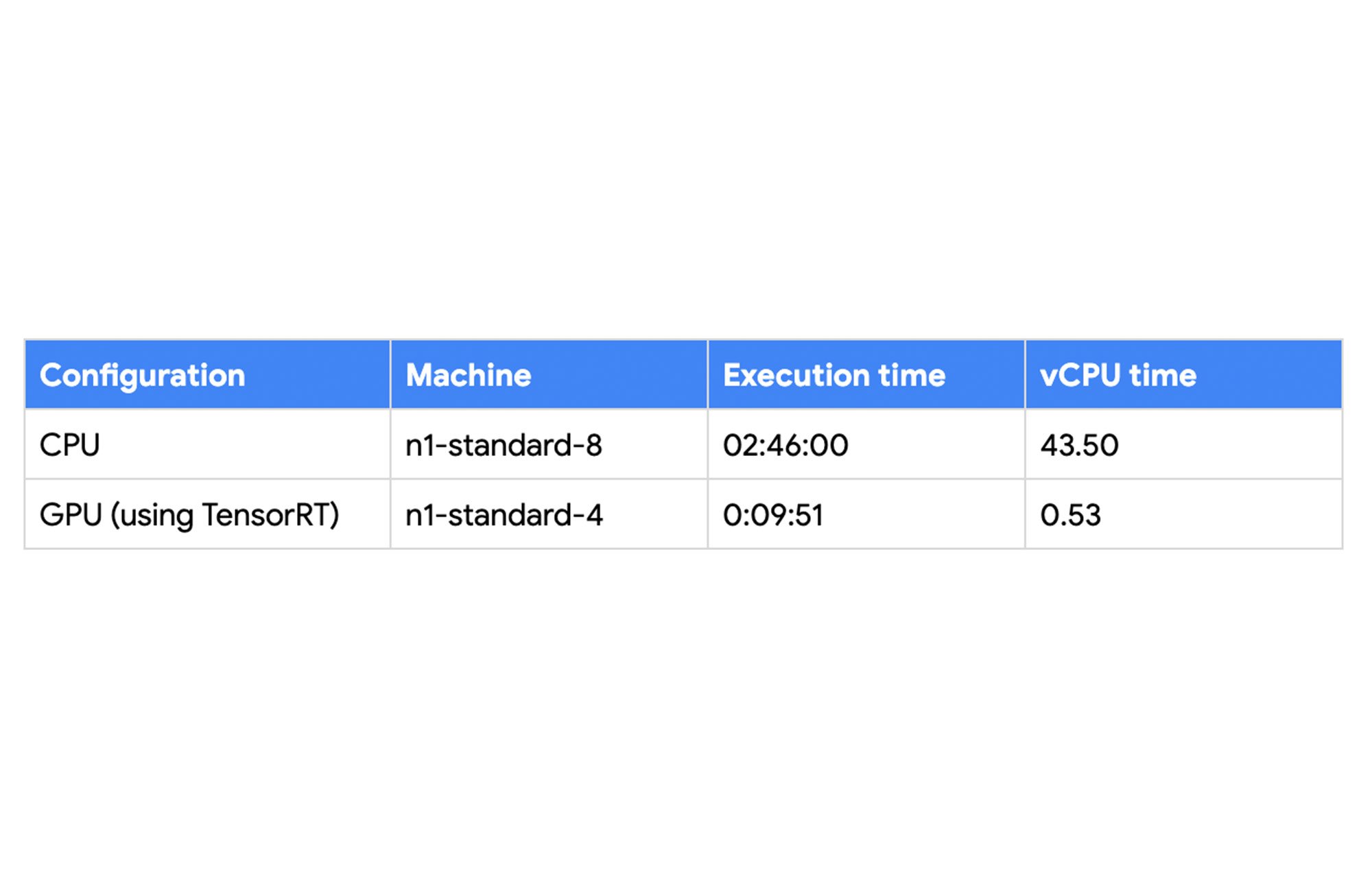
You can see more details about the test setup and test parameters at the blog post by NVIDIA.
We recommend testing Dataflow GPU with your workloads since the extent of the benefit depends on the data and the type of computation that is performed.
What customers are saying
Cloud to Street, uses satellites and AI to track floods in near real-time anywhere on earth to insure risk and save lives. The company produces flood maps at scale for disaster analytics and response by using Dataflow pipelines to automate batch processing and downloading of satellite data at large scale. Cloud to Street uses Dataflow GPU to not only process satellite imagery but also apply resource intensive machine learning tasks in the Dataflow pipeline itself.
“GPU-enabled Dataflow pipelines asynchronously apply machine learning algorithms to satellite imagery. As a result, we are able to easily produce maps at scale without wasting time manually scaling machines, maintaining our own clusters, distributing workloads, or monitoring processes,” said Veda Sunkara, Machine Learning Engineer, Cloud to Street.
Getting started with Dataflow GPU
With Dataflow GPU, customers have the choice and flexibility to use any of the following high performance NVIDIA GPUs: NVIDIA® T4 Tensor Core, NVIDIA® Tesla® P4, NVIDIA® V100 Tensor Core, NVIDIA® Tesla® P100, NVIDIA® Tesla® K80.
Using Dataflow GPU is straightforward. Users can specify the type and number of GPUs to attach to Dataflow workers using the worker_accelerator parameter. We have also made it easy to install GPU drivers by automating the installation process. You instruct Dataflow to automatically install required GPU drivers by specifying the install-nvidia-driver parameter.
Apache Beam notebooks with GPU
Apache Beam notebooks enable users to iteratively develop pipelines, inspect your pipeline graph interactively using JupyterLab notebooks. We have added support for GPU to Apache Beam notebooks which enables you to easily develop a new Apache Beam job that leverages GPU and test it iteratively before deploying the job to Dataflow. Follow the instructions at Apache Beam notebooks documentation to start a new notebooks instance to walk through a built in sample pipeline that uses Dataflow GPU.
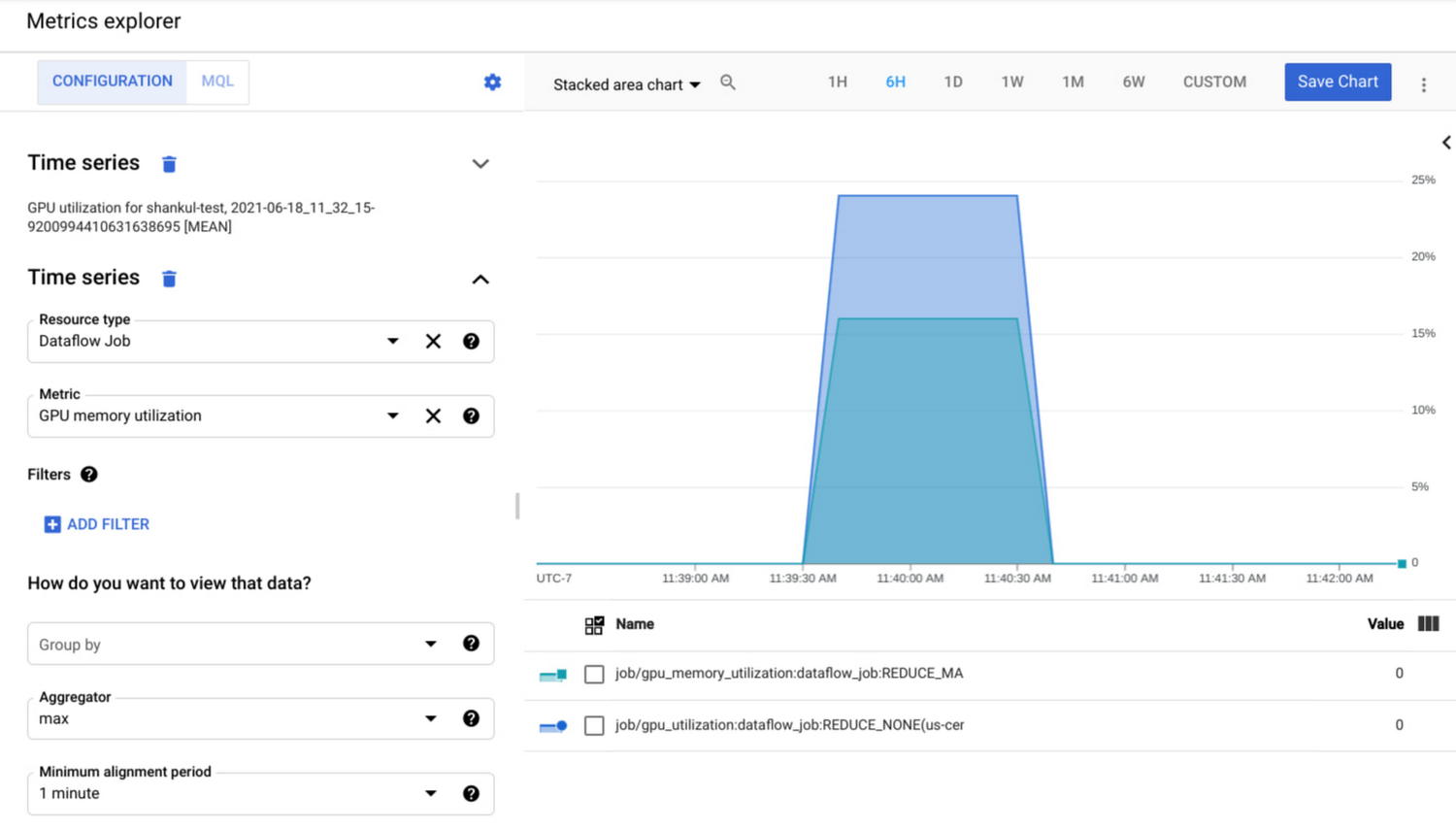
Integrated monitoring
Furthermore, we have integrated monitoring of GPU into Cloud Monitoring. As a result you can easily monitor the performance and usage of GPU resources in your pipeline and optimize accordingly.
Looking ahead: Right Fitting for GPU
We are also announcing a new breakthrough capability called Right Fitting as part of Dataflow Prime Preview. Right Fitting allows you to specify the stages of the pipeline that need GPU resources. That allows the Dataflow service to provision GPUs only for the stages of the pipeline that need it, thereby reducing the cost of your pipelines substantially. You can learn more about the Right Fitting capability here. You can find more details about Dataflow GPU at Dataflow support for GPU. Dataflow GPU are priced on a usage basis. You can find pricing information at Dataflow Pricing.


