Accelerating Mayo Clinic’s data platform with BigQuery and Variant Transforms
Jonathan Sheffi
Senior Product Manager, Life Sciences, Google Cloud
Saman Vaisipour
Software Engineer, Life Sciences, Google Cloud
Genomic data is some of the most complex and vital data that our customers and strategic partners like Mayo Clinic work with. Many of them want to work with genomic variant data, which is the set of differences between a given sample and a reference genome, in order to diagnose patients and discover new treatments. Each sample’s variants are usually stored as a Variant Call Format file, or VCF, but files aren’t a great way to do analytics and machine learning on these data. In 2018, we introduced Variant Transforms, an easy way to load VCF data into BigQuery to enable these use cases.
Since then, we’ve been hard at work improving Variant Transforms, adding features such as the ability to get VCFs back out of BigQuery for customers who want to use file-based tools. We’re now announcing a new schema for Variant Transforms that uses new BigQuery features to significantly reduce the cost of running queries:
Sharding: Variant Transforms shards its output into multiple tables, each containing variants of a specific region of a genome—in this case, a whole chromosome. By storing each chromosome’s variants in its own table, you don’t pay to query every chromosome if you’re only analyzing a small genomic region on one of the chromosomes. In addition to making each table smaller and more manageable, sharding is a prerequisite for integer-range partitioning.
Integer-range partitioning: A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data. By dividing a large table into smaller partitions, you can improve query performance and you can control costs by reducing the number of bytes read by a query. Variant Transforms uses integer-partitioned tables to only query the necessary variants.
Clustering is a technique for automatically organizing a table based on the contents of one or more columns in the table’s schema. Clustered columns are used to colocate related data. BigQuery sorts the data based on the values of the clustered columns and organizes the data into multiple blocks in BigQuery storage. Using clustering in addition to partitioning is very effective for large variant tables, because it efficiently organizes and sorts the variants inside each partition.
The result? Queries to find all variants of a typical gene are now five to 40 times cheaper than before. For queries that span a short genomic region, the associated cost can be up to 200 times lower.1
How Mayo Clinic is using Variant Transforms
This kind of performance is empowering partners like Mayo Clinic. In 2019, Mayo Clinic built a new Omics Data Platform (ODP) on Google Cloud. They use Variant Transforms along with the Google Cloud Healthcare API and the Google Cloud Life Sciences API to deliver next-generation patient insights for Mayo Clinic patients. Mayo Clinic has integrated ODP with their pipelines that are producing variant data and are also loading all of their historical data.
“Mayo Clinic is interested in finding the meaning in all of the variants. Is the variant pathogenic or benign? Is the variant potentially high impact? Does the variant affect how a patient metabolizes a drug?” says Mike Mundy, IT technical specialist from Mayo Clinic, who’s leading the implementation of ODP. “There are many sources of variant annotations and they are constantly being updated with new knowledge.” Mayo Clinic’s ODP also supports managing annotation sources, and annotation data is loaded into BigQuery. Variant data and annotation data is kept separate, which allows for dynamic variant annotation with the latest knowledge.
ODP is implemented using a microservices architecture that is built on Google Cloud, using Cloud IAM for managing accounts and permissions, Cloud Storage for the data lake, and BigQuery for the data warehouse. The ODP security model keeps research subject data and clinical patient data separate. Each research study or clinical sequencing project gets its own Google Cloud project for fine-grained access control. ODP also includes an Omics Data Console that uses ODP’s microservices to provide a user interface for querying variant data and running dynamic annotations.
How much better is Variant Transforms?
To test the performance of the new schema, we wrote a query to find all variants in a genomic region of fixed length and examined several region lengths, from 1,000 base pairs to 1,000,000. We ran each query 10 times from random starting points and recorded the median cost (bytes billed). We repeated this process on two chromosomes, a large one and a small one, to examine the effect of chromosome size on the efficiency of our new schema. Here’s how the new schema performs on the 1000 Genomes dataset, in MB processed (lower is better):
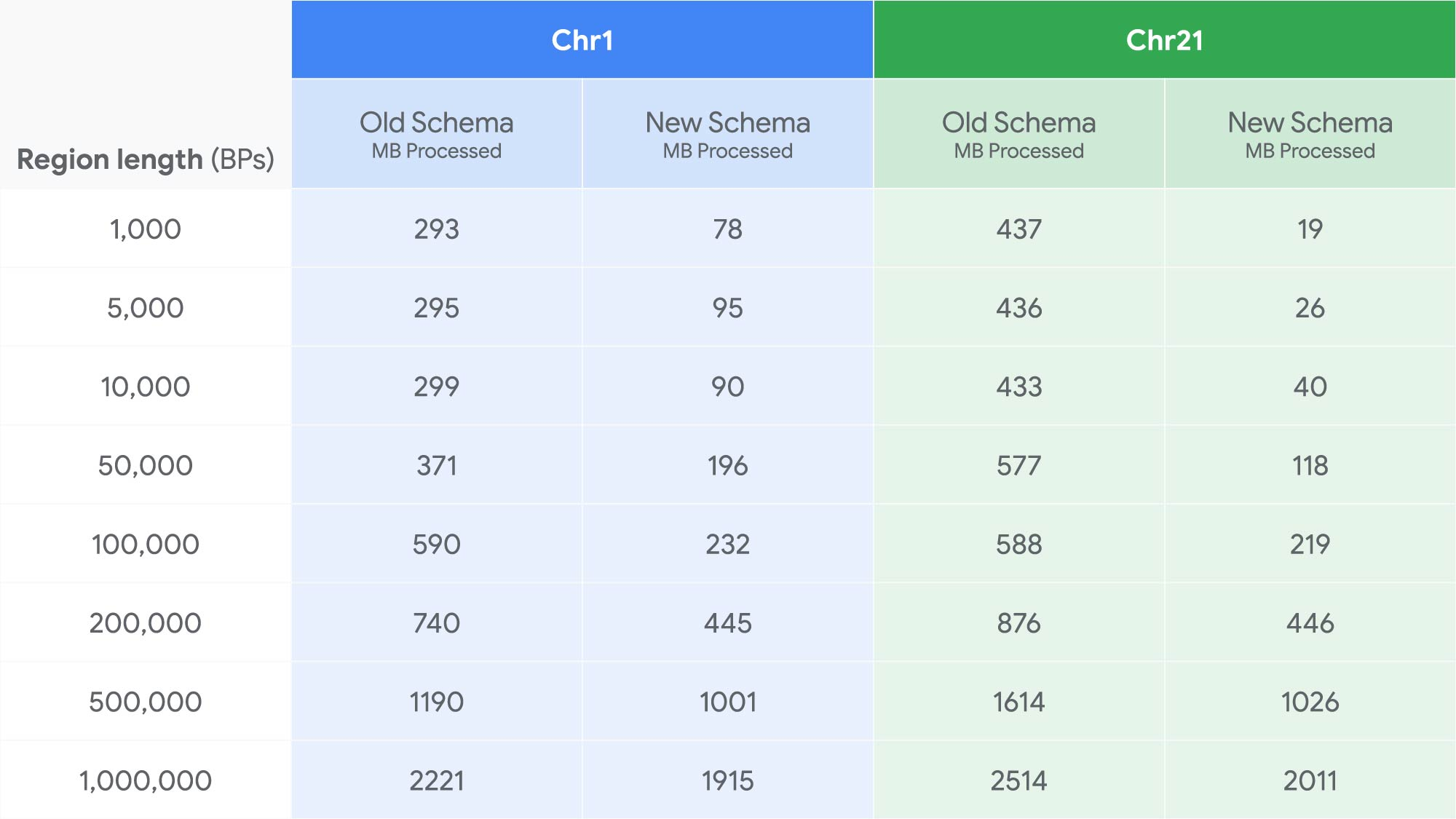
And here’s the new schema performance on the gnomADv3 data set, in MB processed (lower is better):
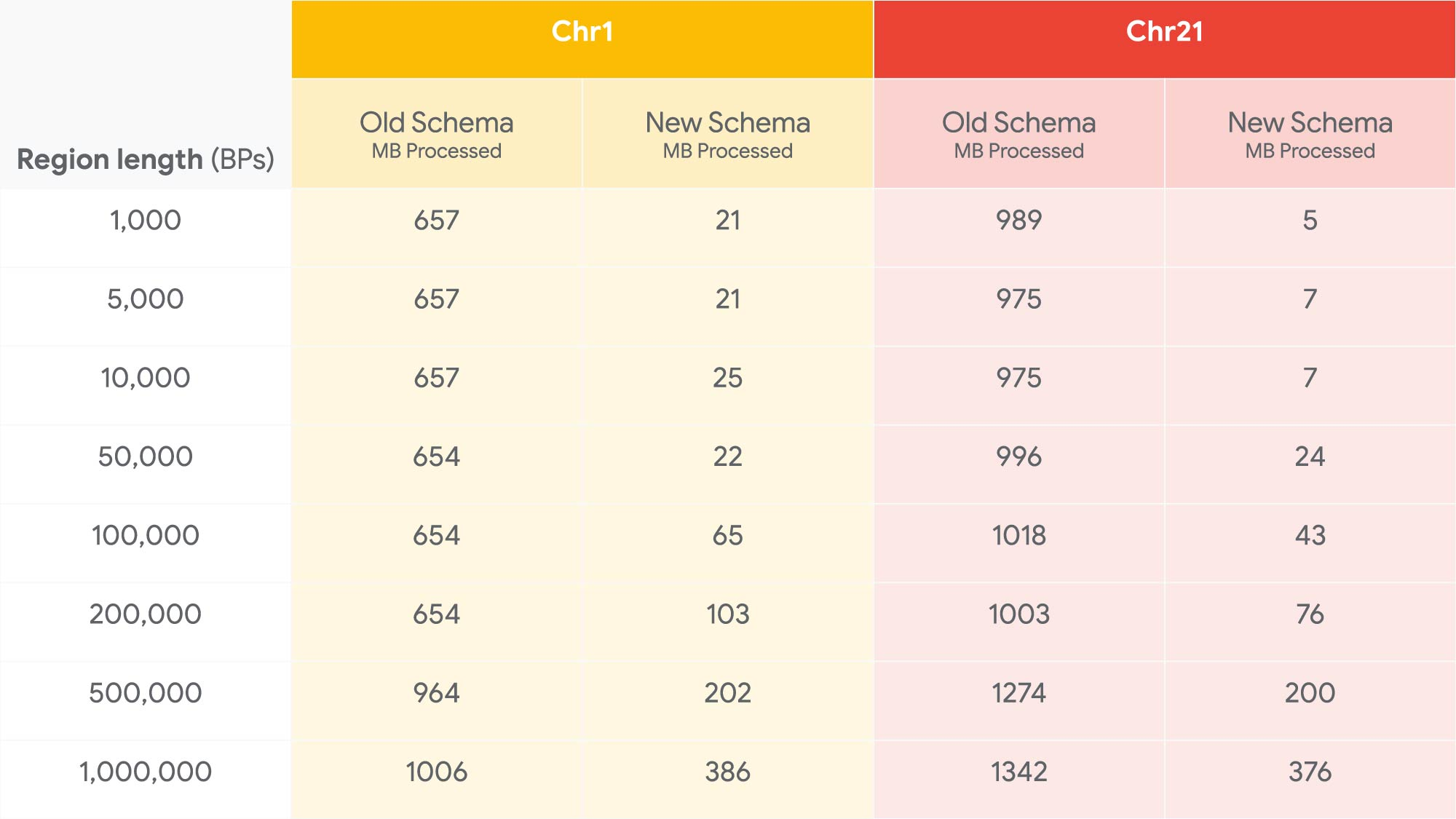
As the approximate length of a typical gene is less than 50,000 base pairs, running a query to find all variants of a gene in gnomADv3 costs about 25MB. This means users can run around 42,000 similar queries each month at no cost, assuming use of the 1TB free offering of BigQuery.
As Mayo Clinic scales out sequencing to hundreds of thousands of patients, they estimate saving $1.5 million over three years by using Google Cloud and Variant Transforms instead of their existing solution. The new version of Variant Transforms is accelerating the team’s ability to deliver on the promise of precision medicine.
Learn more about Mayo Clinic and about Variant Transforms.
1. Based on tests described in the “How much better is Variant Transforms” section of this post. Your own experience with the performance improvement of Variant Transforms may vary. Performance depends on many factors, including the size of the sharded output table, the density of variants, and the presence of repeated calls (in the case of joint genotyped inputs).



