Deployment patterns for Dataproc Metastore on Google Cloud
Rajashekar Pantangi
Big Data & Analytics Cloud Consultant
Vince Gonzalez
Data & Analytics Engineering Manager
If you work with big data, you're likely familiar with Apache Hive, and the Hive Metastore, which has become the de facto standard for managing metadata in the big data ecosystem. Dataproc Metastore is a fully managed Apache Hive metastore (HMS) that runs on Google Cloud. Dataproc Metastore is highly available, autoheals, auto-scales, and is serverless. All of this helps you manage your data lake and metadata, and provides interoperability between various data processing engines and any tools that you're using.
If you are in the process of migrating from an on-premises Hadoop environment with multiple Hive Metastores to Dataproc Metastore on Google Cloud, you may be seeking ways to effectively organize your Dataproc Metastores (DPMS). When designing a DPMS architecture, there are several important factors to consider: centralization vs. decentralization, single-region vs. multi-regions, and persistence vs. federation. These architectural decisions can significantly impact the scalability, resilience, and manageability of your metadata.
The blog post explores four DPMS deployment patterns:
-
A single centralized multi-regional DPMS
-
Centralized metadata federation with per-domain DPMS
-
Decentralized metadata federation with per-domain DPMS
-
Ephemeral metadata federation
Each of these patterns has its own advantages to help you determine the best fit for your organization's needs. The designs are presented in increasing order of complexity and maturity, allowing you to choose the most suitable pattern based on your organization’s specific DPMS requirements and usage.
Note: In the context of this blog post, a domain refers to a business unit, department, or a functional area within your organization. Each domain may have its own specific requirements, data processing needs, and metadata management practices.
Let’s take a closer look at each of these patterns.
1. Centralized multi-regional Dataproc Metastore
This design is suitable for simpler use cases where you have a limited number of domains and can consolidate all metastores into a single multi-regional (MR) Dataproc Metastore.
In this design, a single multi-regional DPMS is deployed by consolidating all the metastores across the domains within a central shared project. This setup allows all domain projects within the organization to access metadata from this centralized DPMS. The primary objective of this design is to provide a straightforward and easy-to-manage solution for organizations with a limited number of domains and a relatively simple use case.
When you create a Dataproc Metastore service, you permanently set a geographic location for your service to reside in, otherwise known as a region. You can select either a single region or a multi-region. A multi-region is a large geographic area that contains two or more geographic places and provides higher availability. Multi-regional Dataproc Metastore services store your data in two different regions and use the two regions to run your workloads. For example, the multi-region nam7 contains the us-central1 and us-east4 regions.
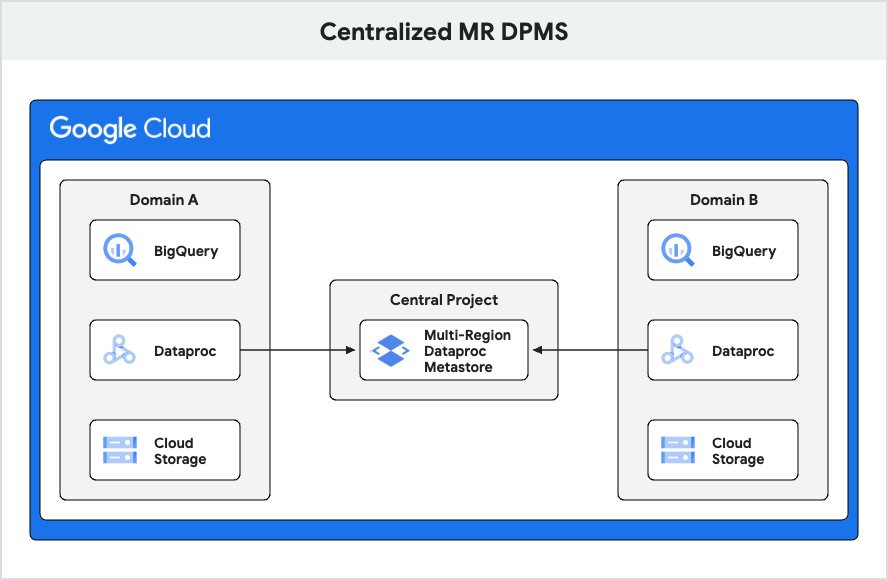
Advantages of this design:
-
By consolidating multiple metastores into a single DPMS, you can simplify metadata management and reduce the complexity of your data environment.
-
Managing permissions/access becomes more straightforward.
2. Centralized metadata federation with per domain DPMS
This design is a little more advanced and is used when you have multiple domains, each with its own DPMS, and consolidating them into a single metastore is not feasible. In such cases, if you still want to enable collaboration and metadata sharing across domains, you can leverage a foundational block called metadata federation to achieve this.
Metadata federation is a service that enables access to multiple sources of metadata from a single endpoint. At the time of writing this blog, these sources include Dataproc Metastores, BigQuery datasets and Dataplex lakes. The federation service exposes this endpoint using the gRPC (Google Remote Procedure Call) protocol. This protocol facilitates request handling by checking the source ordering among metastores to retrieve the required metadata. gRPC is known for its high performance and is widely used for building distributed systems.
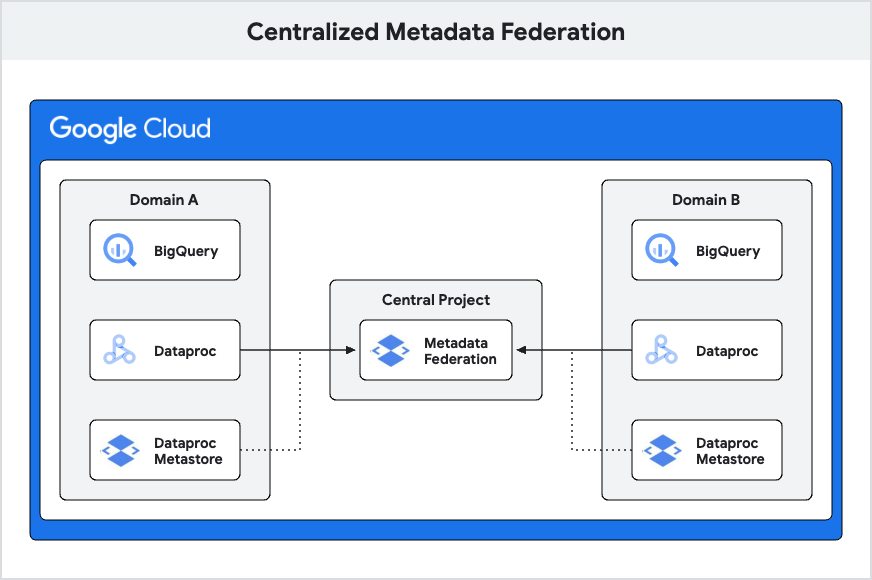
To set up federation, create a federation service and then configure your metadata sources. After, the service exposes a single gRPC endpoint that you can use to access all of your metadata. In this design, each domain is responsible for owning and managing their own Dataproc Metastores. A central project hosts the metastore federation, which integrates each domain's DPMS and BigQuery resources. This setup allows teams to operate autonomously, develop data pipelines and access metadata. When necessary, teams can utilize the federation service to access data and metadata from other domains.
Advantages of this design include:
-
Per-domain DPMS: Each domain having its own Dataproc Metastore creates clear boundaries for metadata and data access, simplifying management and access control.
-
Centralized metastore federation: The centralized federation offers a unified view of metadata across all domains, providing a comprehensive and easily accessible overview of the entire ecosystem.
3. Decentralized metadata federation with per-domain DPMS
This design is a bit more advanced still and is used when you have multiple DPMS instances inside each domain — some single-region and some multi-region. While you want each individual team in a domain to own and manage its DPMS, you also want a metadata federation that ties together all DPMS instances within a single domain to enable collaboration across the domain's metastores.
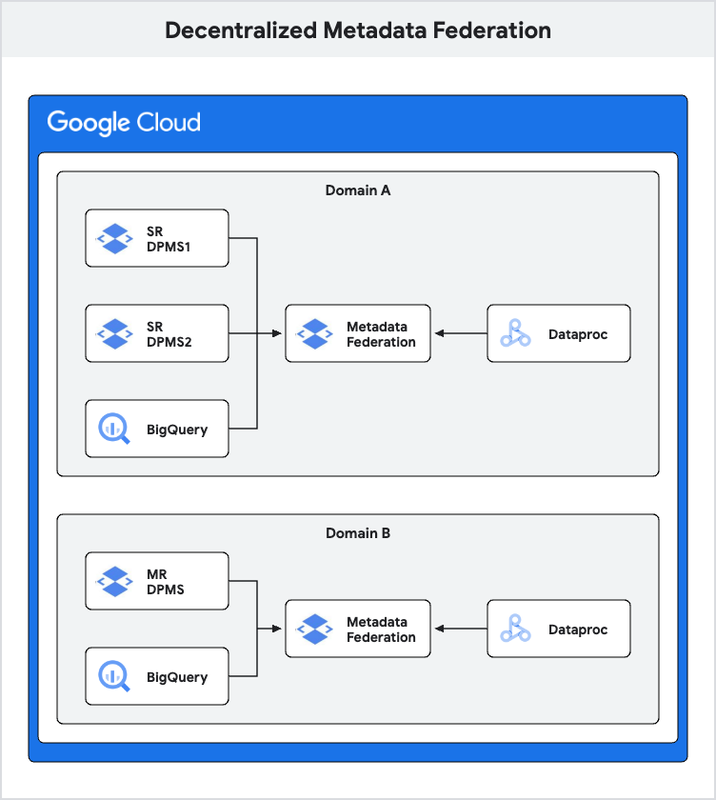
In this architecture, each domain manages its own Dataproc Metastores, which may consist of multiple DPMS instances or a single consolidated MR DPMS. A Metastore federation is established per domain, connecting DPMS instances (one or more), BigQuery, and Dataplex lakes within its domain. This federation service can also integrate metadata (DPMS, BigQuery, lakes) from other domains as needed, building on the metadata federation concept covered under the centralized metadata federation section above.
Advantages of this design include:
-
The impact of an unplanned failure of a DPMS is significantly reduced compared to the single MR DPMS scenario (design 1).
-
The latency of searching multiple DPMS through federation is minimized because only necessary DPMS instances are included in the federation and the order in which DPMS instances are stitched determines the order for metadata search and collision priority.
-
Namespace issues are mitigated as only local metastores and those needed for ETL are part of the federation.
4. Ephemeral metadata federation
Building upon the previous design, where we discussed metadata federation within a domain, we can further extend the concept to enable ephemeral federation across domains. This design is particularly useful when you have ETL jobs that require temporary access to metadata from multiple DPMS instances across different projects or domains.
This design leverages ephemeral federation to dynamically stitch metastores for ETL purposes. When ETL jobs require access to additional metadata beyond what is available in the domain’s DPMS or BigQuery, you have the option to create a temporary federation that includes other DPMS instances across projects. This temporary federation allows ETL jobs to access the necessary metadata from the additional DPMS. This again leverages the metastore federation as the building block.
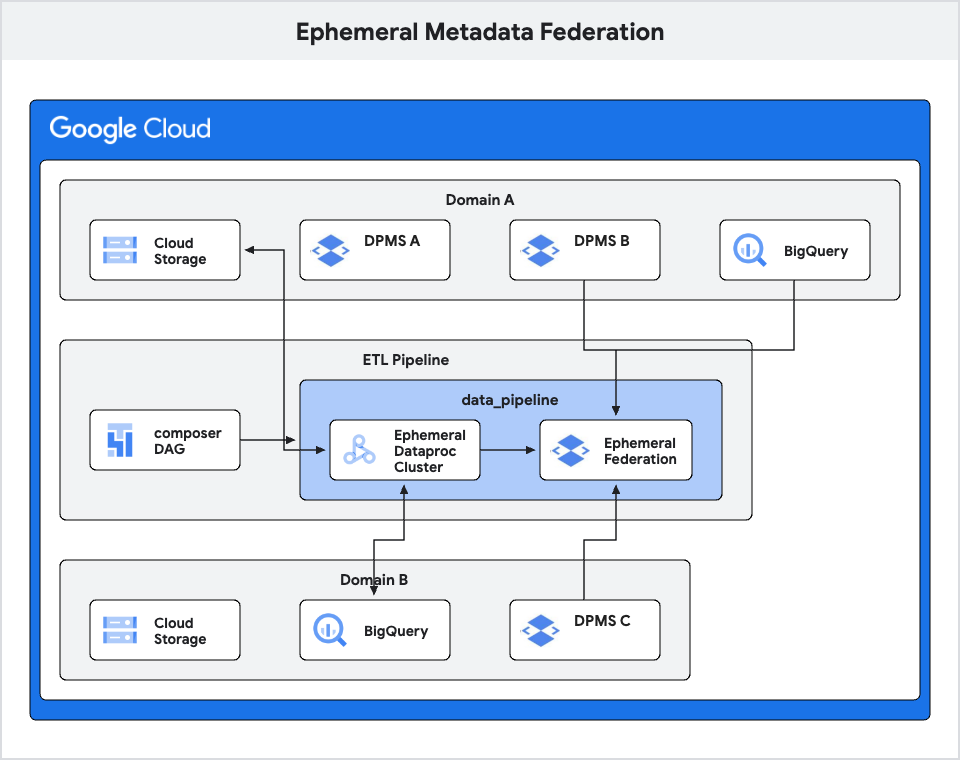
A key advantage of the ephemeral federation approach is the flexibility of being able to dynamically specify and stitch together different DPMS instances for each ETL job or workflow as needed. This allows limiting the federation to only the required metastores instead of a static, broader federation configuration. The temporary federation setup can be orchestrated when creating a Dataproc cluster and integrated into an Airflow DAG. This means the ephemeral federation provisioning and teardown can be fully automated to run alongside the ETL jobs for their duration.
Conclusion
Understanding the pros and cons of each DPMS deployment pattern is crucial for aligning with your organization's goals and infrastructure capabilities. When selecting the most suitable design pattern, consider the following key points:
-
Assess the complexity of your data environment, including the number of domains, teams, and data processing requirements.
-
Evaluate your organization's need for collaboration and metadata sharing across domains.
-
Consider the importance of data autonomy and the level of control each domain requires over their metadata.
-
Determine the desired balance between simplicity and flexibility in your metadata management architecture.
By carefully evaluating these factors and understanding the trade-offs between the different design patterns, you can make an informed decision that strikes the right balance between simplicity, scalability, collaboration, and resilience while ensuring successful metadata management at scale. Click here to create your Dataproc Metastore.


