Exploring container security: Day one Kubernetes decisions
Maya Kaczorowski
Product Manager, Container Security
Congratulations! You’ve decided to go with Google Kubernetes Engine (GKE) as your managed container orchestration platform. Your first order of business is to familiarize yourself with Kubernetes architecture, functionality and security principles. Then, as you get ready to install and configure your Kubernetes environment (on so-called day one), here are some security questions to ask yourself, to help guide your thinking.
How will you structure your Kubernetes environment?
What is your identity provider service and source of truth for users and permissions?
How will you manage and restrict changes to your environment and deployments?
Are there GKE features that you want to use that can only be enabled at cluster-creation time?
Ask these questions before you begin designing your production cluster, and take them seriously, as it’ll be difficult to change your answers after the fact.
Structuring your environment
As soon as you decide on Kubernetes, you face a big decision: how should you structure your Kubernetes environment? By environment, we mean your workloads and their corresponding clusters and namespaces, and by structure we mean what workload goes in what cluster, and how namespaces map to teams. The answer, not surprisingly, depends on who’s managing that environment.
If you have an infrastructure team to manage Kubernetes (lucky you!), you’ll want to limit the number of clusters to make it easier to manage configurations, updates and consistency. A reasonable approach is to have separate clusters for production, test, and development.
Separate clusters also make sense for sensitive or regulated workloads that have substantially different levels of trust. For example, you may want to use controls in production that would be disruptive in a development environment. If a given control doesn’t apply broadly to all your workloads, or would slow down some development teams, segment them out into separate clusters and give each dev team or service its own namespace within a cluster.
If there’s no central infrastructure team managing Kubernetes--if it’s more “every team for itself”—then each team will typically run its own cluster. This means more work and responsibility for them enforcing minimum standards—but also much more control over which security measures they implement, including upgrades.
Setting up permissions
Most organizations use an existing identity provider, such as Google Identity or Microsoft Active Directory, consistently across the environment, including for workloads running in GKE. This allows you to manage users and permissions in a single place, avoiding potential mistakes like accidentally over-granting permissions, or forgetting to update permissions as users’ roles and responsibilities change.
What permissions should each user or group have in your Kubernetes environment? How you set up your permission model is strongly tied to how you segmented your workloads. If multiple teams share a cluster, you’ll need to use Role-Based Access Control (RBAC) to give each team permissions in their own namespaces (some services automate this, providing a self-service way for a team to create and get permissions for its namespace). Thankfully, RBAC is built into Kubernetes, which makes it easier to ensure consistency across multiple clusters, including different providers. Here is an overview of access control in Google Cloud.
Deploying to your Kubernetes environment

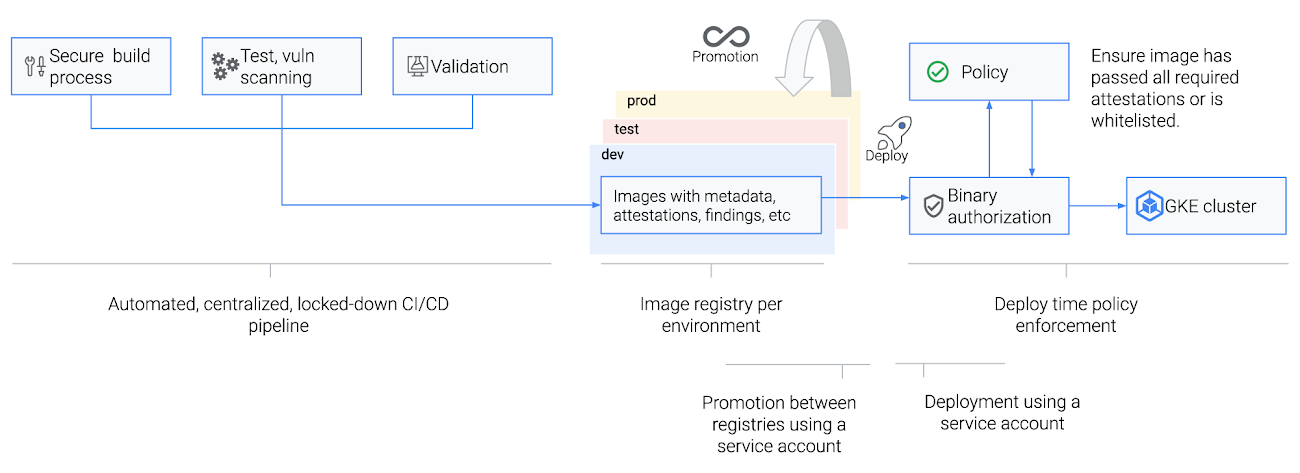
In some organizations, developers are allowed to deploy directly to production clusters. We don’t recommend this. Giving developers direct access to a cluster is fine in test and dev environments, but for production, you want a more tightly controlled continuous delivery pipeline. With this in place, you can set up steps to run tests, ensure that images meet your policies, scan for vulnerabilities, and finally, deploy your images. And yes, you really should set up these pipelines on day one; it’s hard to convince developers who have always deployed to production to stop doing so later on.
Having a centralized CI/CD pipeline in place lets you put additional controls on which images can be deployed. The first step is to consolidate your container images into a single registry such as Container Registry, typically one per environment. Users can check images into a test registry, and once tests pass and they’re promoted to the production registry, push them to production.
We also recommend that you only allow service accounts (not people) to deploy images to production and make changes to cluster configurations. This lets you audit service account usage as part of a well-defined CI/CD pipeline. You can still give someone access if necessary, but in general it’s best to follow the principle of least privilege when granting service account permissions, and ensure that all administrative actions are logged and audited.
Features to turn on from day one
A common day-one misstep is failing to enable certain security features that you might need down the road at cluster-creation time, because you’ll have to migrate your cluster once it’s up and running to turn them on. There are some GKE security features that you can’t turn on in an existing cluster that aren’t turned on by default, for example private clusters and
Google Groups for GKE. Rather than trying to make a cluster you’ve used to experiment with these different features production-ready, a better plan is to create a test cluster, make sure its features work as intended, resolve issues, and only then make a real cluster with your desired configurations.
As you can see, there’s a lot to keep in mind when setting up GKE. Keep up to date with the latest advice and day two to-dos with the GKE hardening guide.



{kind=link}