Building Generative AI applications made easy with Vertex AI PaLM API and LangChain
Anand Iyer
Group Product Manager, Vertex Generative AI
Rajesh Thallam
Solutions Architect, Generative AI Solutions
At Google I/O 2023, we announced Vertex AI PaLM 2 foundation models for Text and Embeddings moving to GA and expanded foundation models to new modalities - Codey for code, Imagen for images and Chirp for speech - and new ways to leverage and tune models. These models help developers to build powerful yet responsible Generative AI applications, backed by enterprise ready features including safety, security and privacy.
LangChain is a trending open-source framework that has emerged to develop new interfaces for Generative AI applications powered by language models. It makes it easy to swap out abstractions and components necessary to work with language models. It has been widely adopted by the open-source community, with various integrations to other tools and new features being added. While language models can be simple to use, you may quickly encounter challenges that LangChain can help overcome as you develop more complex applications.
Vertex AI PaLM 2 foundational models for Text and Chat, Vertex AI Embeddings and Vertex AI Matching Engine as Vector Store are officially integrated with the LangChain Python SDK, making it convenient to build applications on top of Vertex AI PaLM models.
In this blog post, we will show you how you can build a Generative AI application - Document based Q&A - using the Vertex AI PaLM Text and Embedding API, Matching Engine, and of course, LangChain. Let’s dive in!
Building generative applications
Large language models (LLMs) have advanced considerably in recent years and can now comprehend and reason with human language to a reasonable extent. To build effective Generative AI applications, it is key to enable LLMs to interact with external systems. This makes models data-aware and agentic, meaning they can understand, reason, and use data to take action in a meaningful way. The external systems could be public data corpus, private knowledge repositories, databases, applications, APIs, or access to the public internet via Google Search.
Here are a few patterns where LLMs can be augmented with other systems:
Convert natural language to SQL, run the SQL on a database, analyze and present the results
Call an external webhook or API based on the user query
Synthesize outputs from multiple models, or chain the models in a specific order
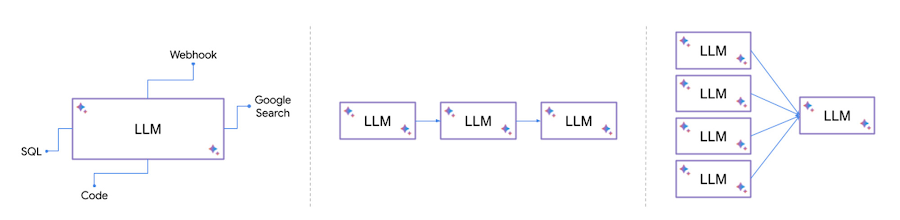
It may look trivial to plumb these calls together and orchestrate them but it becomes a mundane task to write glue code again and again e.g. for every different data connector or a new model. That’s where LangChain comes in!
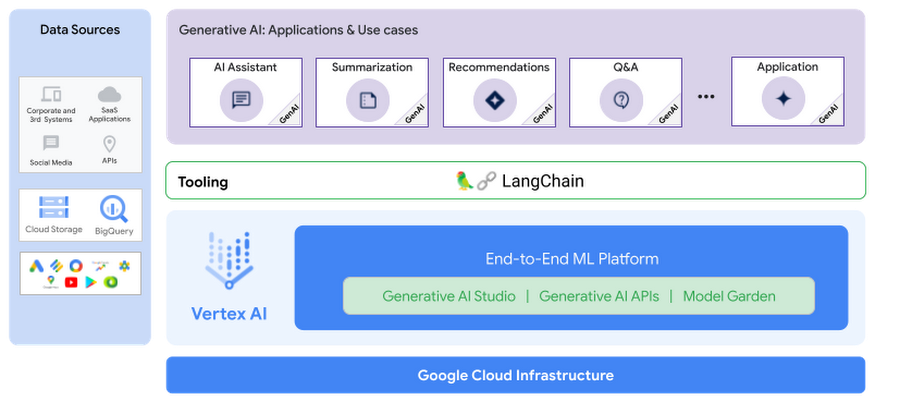
LangChain’s modular implementation of components and common patterns combining these components makes it easier to build complex applications based on language models. LangChain enables these models to connect to data sources and systems as agents to take action.
Components are abstractions that work to bring external data, such as your documents, databases, applications,APIs to language models
Agents enable language models to communicate with its environment, where the model then decides the next action to take.
With the integration of LangChain with Vertex AI PaLM 2 foundation models and Vertex AI Matching Engine, you can now create Generative AI applications by combining the power of Vertex AI PaLM 2 foundation models with the ease of use and flexibility of LangChain.
Introducing LangChain concepts
Let’s take a quick tour of LangChain framework and concepts to be aware of. LangChain offers a variety of modules that can be used to create language model applications. These modules can be combined to create more complex applications, or can be used individually for simpler applications.

Models are the building block of LangChain providing an interface to different types of AI models. Large Language Models (LLMs), Chat and Text Embeddings models are supported model types.
Prompts refers to the input to the model, which is typically constructed from multiple components. LangChain provides interfaces to construct and work with prompts easily - Prompt Templates, Example Selectors and Output Parsers.
Memory provides a construct for storing and retrieving messages during a conversation which can be either short term or long term.
Indexes help LLMs interact with documents by providing a way to structure them. LangChain provides Document Loaders to load documents, Text Splitters to split documents into smaller chunks, Vector Stores to store documents as embeddings, and Retrievers to fetch relevant documents.
Chains let you combine modular components (or other chains) in a specific order to complete a task.
Agents are a powerful construct in LangChain allowing LLMs to communicate with external systems via Tools and observe and decide on the best course of action to complete a given task.
Here are snippets showing Vertex AI PaLM API and LangChain integration:
- LangChain LLMs with Vertex AI PaLM API for Text for language tasks
- LangChain Chat Model with Vertex AI PaLM API for Chat for multi-turn chat
- LangChain Text Embedding Model with Vertex AI Text Embedding API
Please refer to the LangChain Conceptual Guide for more details.
“Ask Your Documents”: Building Question Answering Application with Vertex AI PaLM API, Matching Engine and LangChain
There are a few ways to implement a document Q&A system in Google Cloud. For an easy out-of-the-box experience, you can use Cloud AI's fully-managed Enterprise Search solution to get started in minutes and create a search engine powered by Google's proprietary search technology. In this section, we show how you can also “build your own” Q&A system using components offered in the Vertex AI stack.
There has been a significant improvement in LLMs both quantitatively and qualitatively. The scale has unlocked emergent abilities which LLMs learn simply by understanding natural language, without being directly trained on these abilities such as question answering, summarization, content generation. However, there are a few constraints with LLMs:
LLMs are trained offline on a massive corpus and are unaware of events after the training cut-off. For example, a model trained on data up to 2022 would not have information on today's stock price.
The knowledge learned by an LLM from its training data is called parametric memory and stored in its neural weights. LLMs respond to queries from parametric memory, but in most cases the source of information is unknown and an LLM cannot provide a verbatim citation. We prefer that an LLM based system "cites its sources" and the outputs are "grounded" (connected) to the facts.
LLMs are good at generating text from general corpus, but businesses need to generate text from private knowledge bases. AI assistants need to answer questions based on knowledge bases to provide accurate and relevant responses.
To solve for the constraints, one of the approaches is to augment the prompt sent to LLM with relevant data retrieved from an external knowledge base through Information Retrieval (IR) mechanism. The prompt is designed to use the relevant data as context along with the question and avoid/minimize using parametric memory. The external knowledge base is referred to as non-parametric memory. This approach is called retrieval augmented generation (RAG), also known as Generative QA in the context of the QA task. This type of approach was introduced in the paper - Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
In this section, we show how to build a QA system based on RAG pattern that responds to questions based on a private collection of documents and adds references to the relevant documents. We will use a sample of Google published research papers as a private document corpus and run the QA on it. You can find the accompanying code on the GitHub repository.
There are two main components in RAG based architecture: (1) Retriever and (2) Generator.
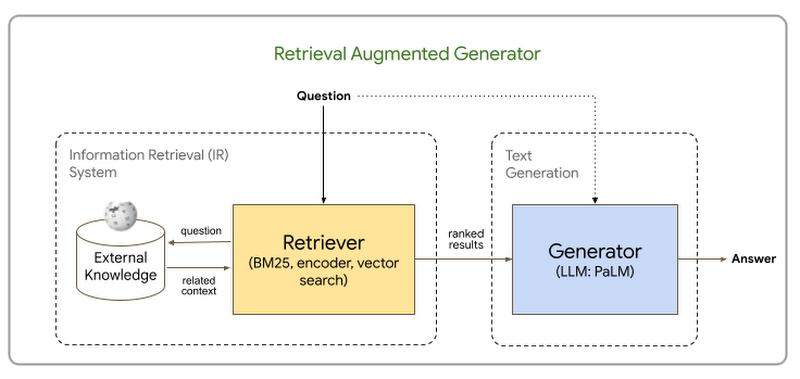
Retriever: The knowledge base is integrated with an IR mechanism, also known as a Retriever, to retrieve relevant snippets from documents based on the user's query. The knowledge base can be your own document corpus, databases, or APIs. The Retriever can be implemented using term-based search, such as keyword, TF-IDF, BM25, fuzzy matching, and so forth. Another approach is to use vector search based on dense embeddings, which captures semantically rich information in the text, leading to much more efficient information retrieval. The relevant snippets retrieved from the IR mechanism are passed as “context” to the next stage, Generator.
Generator: The context - relevant snippets from the knowledge base - are passed to an LLM to generate a well formed response grounded by the source documents.
This approach avoids the limitations of LLM memory and mitigates unexpected behaviors such as hallucinations by extracting only the relevant information from the knowledge base to respond to the query. An added advantage is you can keep your knowledge base up-to-date by adding new documents and their embedding representations. This will ensure that your responses are always grounded, accurate and relevant.
High Level Architecture
The architecture for the retrieval augmented generation pattern is enabled on Google Cloud with the following Vertex AI stack:
Vertex AI Embeddings for Text: Given a document or text of length up to 3072 tokens, the API generates a 768 dimensional text embedding (floating point vector) that can be added to any vector store.
Vertex AI Matching Engine: A fully managed vector store on Google Cloud that allows you to add embeddings to its index and run search queries with a key embedding for blazingly fast vector search. Vertex AI Matching Engine finds the most similar vectors from over a billion vectors. Unlike vector stores that run locally, Matching Engine is optimized for scale (multi-million and billion vectors) and it's an enterprise ready vector store.
Vertex AI PaLM API for Text: The API allows you to structure your prompts by adding contextual information, instructions, examples and other types of text content and use for any task such as text classification, summarization, question answering and more.
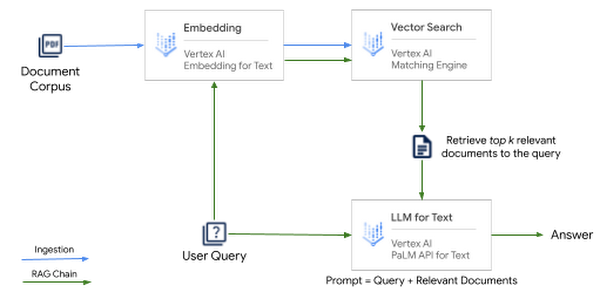
LangChain makes it seamless to orchestrate all of these components using the Retrieval QA chain which is integrated with Vertex AI PaLM API for Text, Vertex AI Embeddings and Matching Engine. The idea is that when given a question:
First, perform a retrieval step to fetch any relevant documents.
Then, feed the LLM the relevant documents along with the original question, and have it generate a response.
Before you can query your documents, you must first have the documents in a searchable format. There are broadly two stages:
Ingestion of documents into a queryable format, and
Retrieval augmented generation chain
LangChain provides flexible abstractions in the form of Document Loaders, Retrievers and Chains to implement these stages with just a few lines of code. Following is the high level flow of each stage:
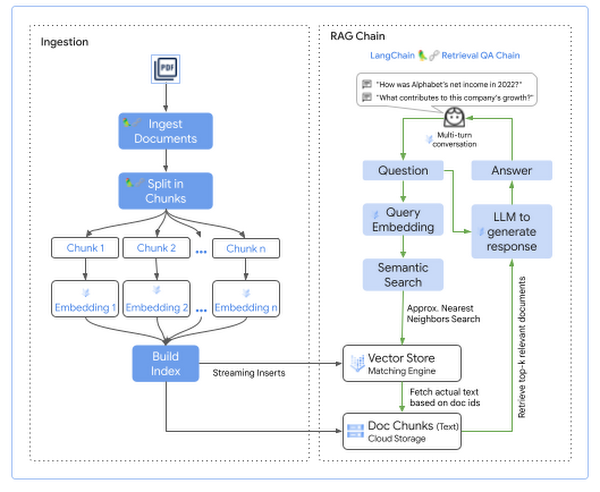
Implementation
As part of the initial setup, Matching Engine Index is created and deployed to an Index Endpoint to ingest documents and query the index to return approximate nearest neighbors.
Matching Engine Index is created with streaming index update to add or update or delete documents to the index. With Streaming Updates, you can update and query your index within a few seconds.
Matching Engine Index Endpoint can be deployed as a public endpoint or private endpoint.
During the Ingestion stage, the documents are transformed from the corpus into embeddings and added to the Matching Engine Index to query them later using semantic search. Following are the steps:
Read the documents from the knowledge base stored in Cloud Storage
Split each document to include relevant parts of the document as context to the prompt. Typically, you want several of these chunks passed as context and size each chunk to fit within the context of LLM.
For each document chunk:
Generate embeddings using Vertex AI Embedding for Text.
Add generated embedding to the Matching Engine Index via Index Endpoint.
Add original document text to Cloud Storage to retrieve along with search results.
LangChain provides flexible components to perform these steps with a few lines of code. Following is the code snippet for the ingesting documents:
Following are some of the considerations when ingesting the documents:
Choosing document chunk size: When splitting the document, ensure each chunk can fit within the context length of LLM.
Choosing document parser: Depending on the content type within document, choose appropriate document loaders availables from LangChain or LlamIndex or build your own custom loader, for e.g. using Document AI processors
In the retrieval augmented generation chain, the Matching Engine uses semantic search to retrieve relevant documents based on the user's question. The resulting documents are then added as additional context to the prompt sent to the LLM, along with the user's question, to generate a response. Thus the response generated by LLM is grounded to the search result from the vector store. The final instruction sent to the LLM might look something like this:
Following are the steps to generate a response to a user query:
Use Vertex AI Embeddings for Text to generate an embedding for the user query.
Search the Matching Engine Index to retrieve the top k nearest neighbors from the embeddings space using the embedding of the user query.
Fetch the actual text for the retrieved embeddings from Cloud Storage, to add as additional context to the user's query.
Add the retrieved documents as context to the user query.
Send the context enhanced query to the LLM to generate a response.
Return the generated response to the user with references to the document sources.
LangChain provides a convenient component called RetrievalQAChain to accomplish these steps within a few lines of code. Following is the code snippet for the retrieval augmented generation:
There are a few considerations with the retrieval augmented generation chain:
The length of the document chunk and the number of search results impact the cost, performance, and accuracy of the response. A longer document chunk means that fewer search results can be added to the context, which may impact the quality of the response. The price of the response increases with the number of the input tokens in the context, so it is important to consider how many search results to include when generating a response.
Choosing chain type: It’s important to consider how to pass relevant documents as part of context to the LLM. LangChain offers different methods such as stuffing, map-reduce and refine. Stuffing is the simplest method where all the relevant documents are stuffed into the prompt along with the user’s query.
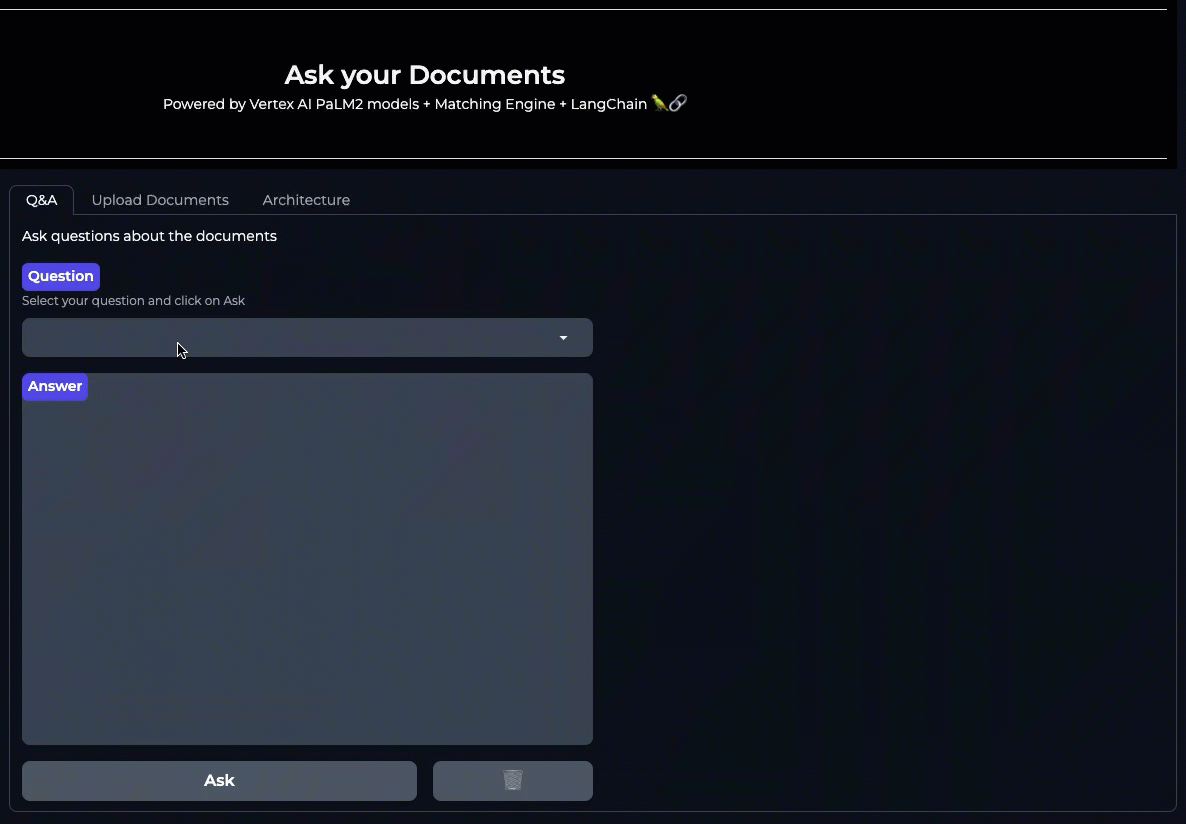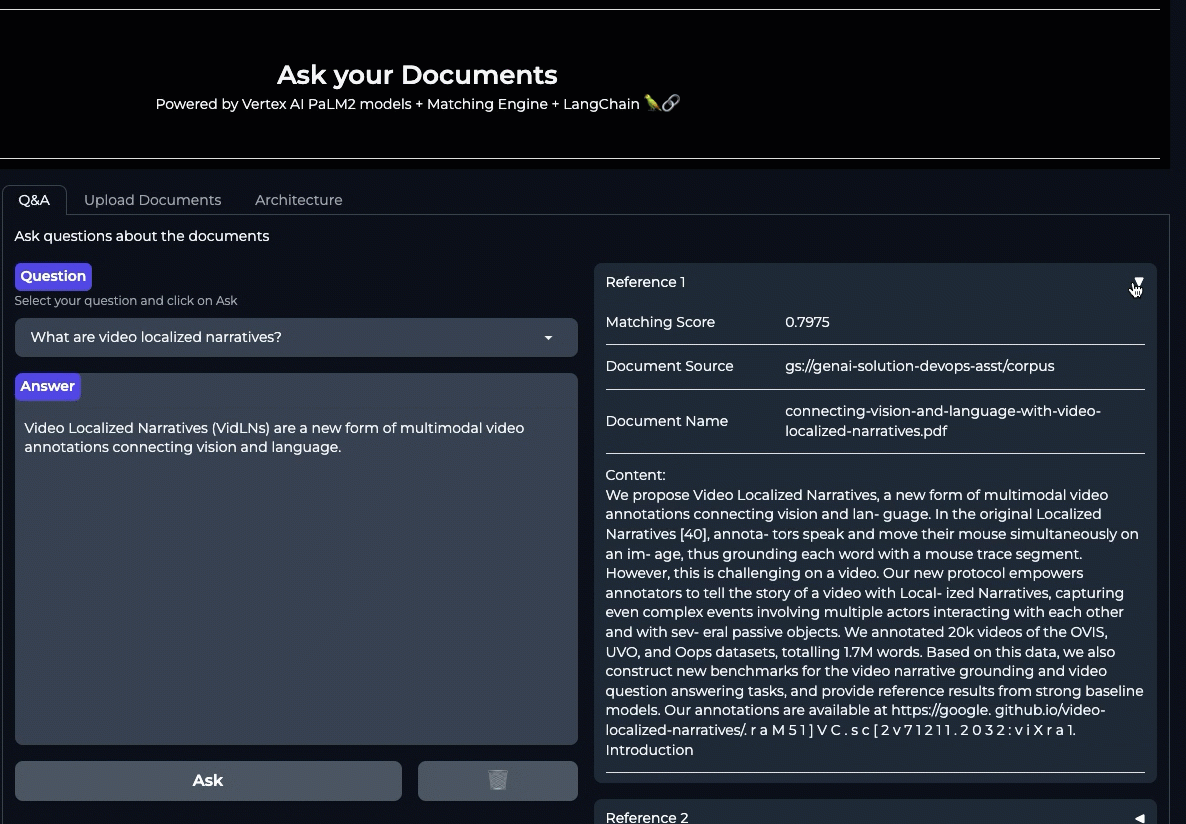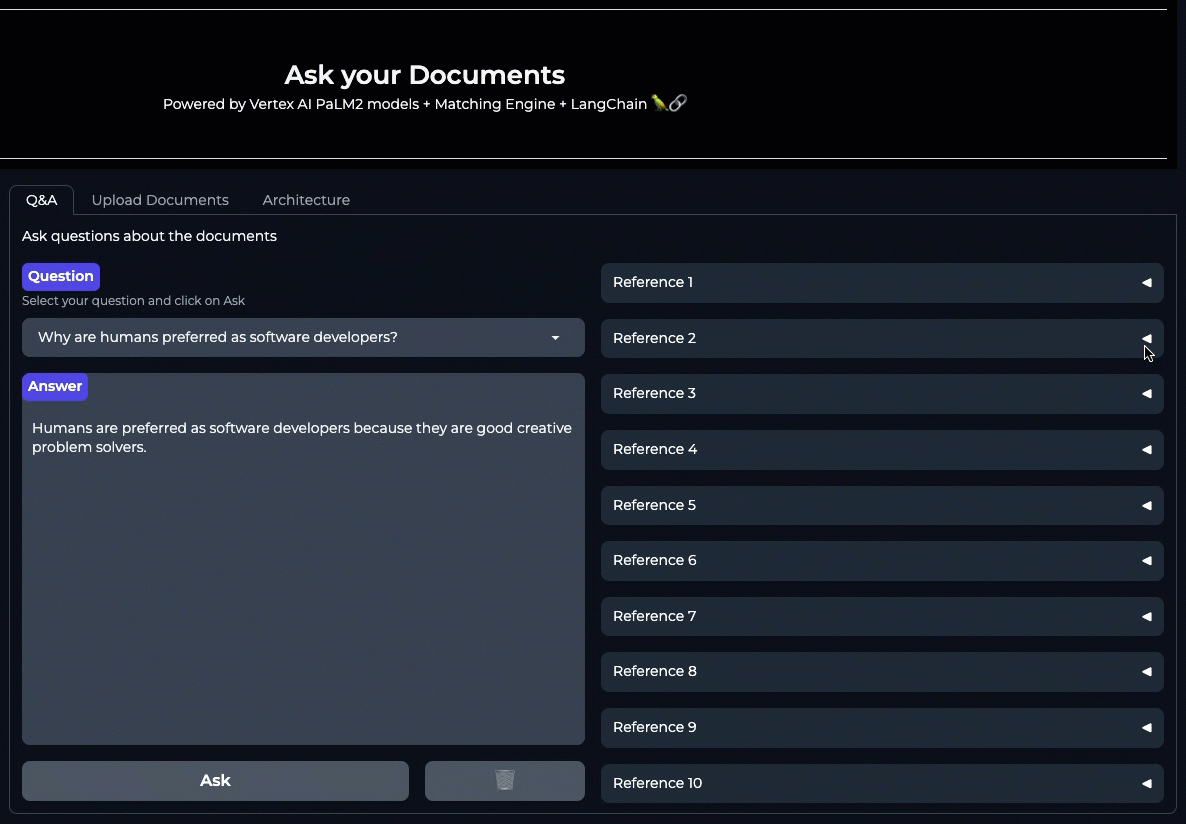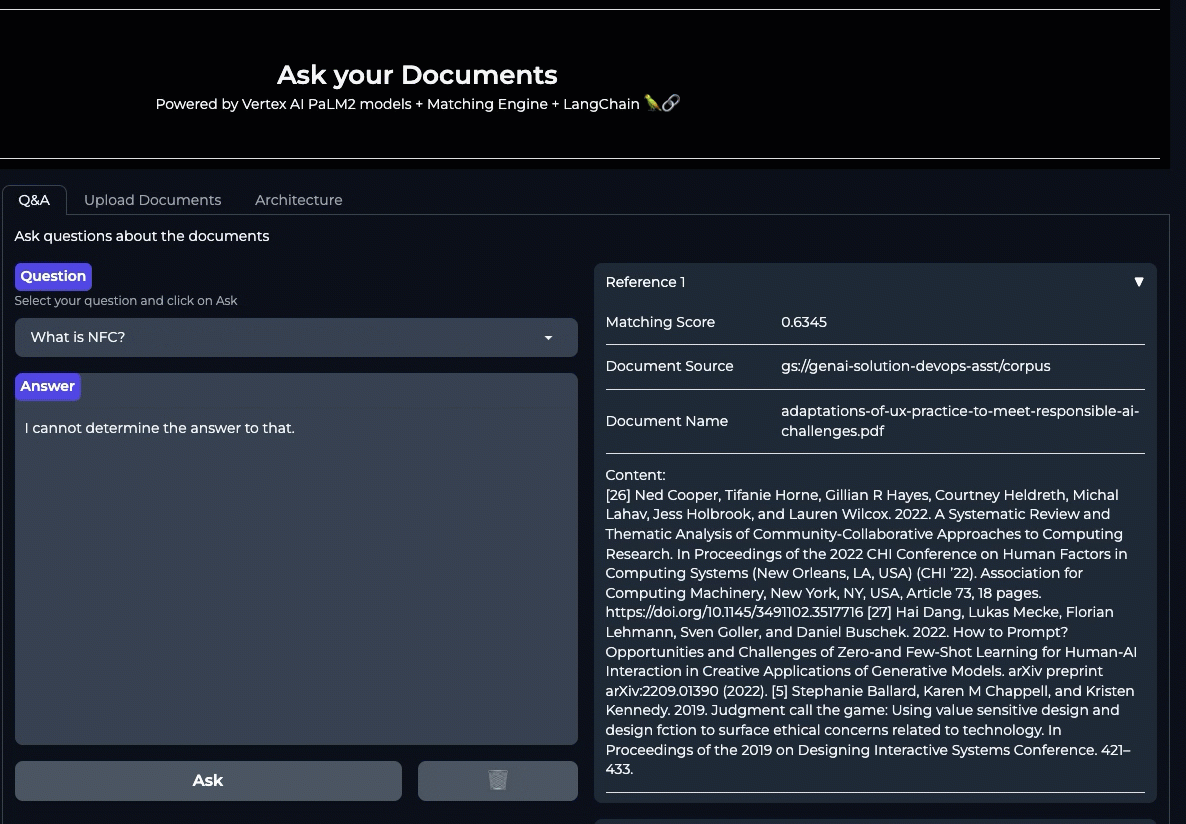
Let’s run through a question relevant to the corpus:
The response returned from the LLM includes both the answer and sources that lead to the response. This ensures the response from LLM is always grounded to the sources.
What happens if we ask a question outside of the corpus:
The LLM responds with "I cannot determine the answer to that" when the question is out of its domain. This is because the output is conditioned through the prompts to not respond when the question is out of context. This is one way of implementing guardrails to mitigate hallucinations when the question cannot be answered with the context retrieved. The following is the instruction in the prompt template configured to use with the LLM:
With that, we showed how you can build a QA system grounded to your documents with Vertex AI PaLM APIs, Matching Engine and LangChain .
How to Get Started
LangChain is a flexible and convenient tool to build a variety of Generative AI applications. The integration of LangChain with Vertex AI PaLM foundational models and APIs makes it even more convenient to build applications on top of these powerful models. In this post, we showed how to implement a QA application based on the retrieval augmented generation pattern using Vertex AI PaLM API for Text, Vertex AI Embedding for Text, Vertex AI Matching Engine and LangChain.
Clone the GitHub repository and get started with the notebook to try with your own documents.
Refer to the Vertex AI documentation for Generative AI support for Text and Embeddings models
Refer to the LangChain documentation for integrations with Vertex AI PaLM API for Text, Embedding API and Matching Engine.
Thanks to Crispin Velez, Leonid Kuligin, Tom Piaggio and Eugenio Scafati for contributing to LangChain integration with Vertex AI PaLM API and Vertex AI Embedding API and Vertex AI Matching Engine. Thanks to Kalyan Pamarthy and Jarek Kazmierczak for guidance and reviewing the blog post.

