Striim と BigQuery による ML でのリアルタイム データ処理
Google Cloud Japan Team
※この投稿は米国時間 2024 年 1 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
現在のようなデータドリブンな世界において、ML アプリケーションでリアルタイム データを活用できることは非常に画期的です。この分野の主要企業である Striim と Google Cloud、そして BigQuery は、これを可能にする強力な組み合わせです。Striim はリアルタイム データ統合プラットフォームとして機能し、多様なソースのデータをクラウド データベース、メッセージング システム、データ ウェアハウスといった場所にシームレスかつ継続的に移動させる、最新のデータ アーキテクチャに不可欠なコンポーネントです。BigQuery は、マルチフォーマット、マルチストレージ、マルチエンジンのあらゆるデータとワークロードを統合する、優れた機能を備えたエンタープライズ データ プラットフォームです。BigQuery ML は BigQuery 環境に組み込まれているため、統一された単一のエクスペリエンスで、SQL のような構文を使用して ML モデルを作成およびデプロイできます。
ML においてリアルタイム データ処理が可能であれば、データ サイエンティストやエンジニアはモデル開発やモニタリングに集中できます。従来の方法では、元データの収集、クリーニング、ラベル付けをバッチ処理で行うワークフローやコードを手作業で実行していたため、遅延が生じ、応答性が低下することもしばしばでした。Striim の強みは 150 以上のデータソースに接続できる点にあり、事実上あらゆる場所からリアルタイムでデータを取得し、データ変換を簡素化できます。これにより、企業は ML モデルを迅速に作成してデータに基づく意思決定と予測を速やかに行えるようになり、最終的には顧客体験の向上とオペレーションの最適化を実現できます。最新のデータを取り込むことで、組織は意思決定プロセスの精度をさらに高めることができ、利用可能な最新の情報からインサイトを導き出し、より多くの情報に基づいた戦略的なビジネス成果につなげることができます。
前提条件
Striim と BigQuery ML を統合し、ML におけるリアルタイム データ処理を実現するための取り組みを開始する前に、確実に整えておくべき前提条件がいくつかあります。
- Striim インスタンス: 開始する前に Striim インスタンスを作成し、そのインスタンスにアクセスできるようにしておきます。Striim はこの統合を支えるバックボーンであり、データ パイプラインを設定してソース データベースに接続するためには、正常に機能する Striim インスタンスが必要不可欠です。無料トライアルをご希望の方は、Google Cloud トライアル https://go2.striim.com/trial-google-cloud で Striim Cloud にご登録ください。
- Striim の基礎知識: Striim の基本的な概念を理解し、データ パイプラインを作成できる状態にしておく必要があります。たとえば、Striim 環境の利用方法、データソースの設定方法、データフローの設定方法についての理解が求められます。Striim を初めて使用する場合、または Striim のコア機能について復習が必要な場合は、以下のドキュメントやリソースをご覧ください。https://github.com/schowStriim/striim-PoC-migration
このブログ投稿の以下のセクションでは、Striim と BigQuery ML とのシームレスな統合について説明し、Postgres データベースへの接続から ML モデルのデプロイまで、手順を詳しくご紹介します。Striim のリアルタイム データ統合機能と BigQuery ML の強力な ML サービスを統合することで、データをシームレスに移動できるだけでなく、ML モデルの構築とデプロイに最新のデータを活用できるようになります。デモでは、これらのツールを使用することでリアルタイムのデータ取得、変換、モデルのデプロイをどれだけスムーズに行えるかを示し、最終的に組織がオペレーションの効率を最適化しつつ、データに基づいた迅速な意思決定と予測を行えるようになる仕組みを紹介します。
セクション 1: ソース データベースとの接続
この統合の最初の手順は、ML 用の元データを含むデータベースに Striim を接続することです。このブログでは、PostgreSQL データベースを使用します。このデータベースには、次の列構造を持つ iris_dataset テーブルが含まれます。
このテーブルには、さまざまな種類のアヤメ属の花の特徴に関する元データが含まれています。これらのデータはパブリック ソースから収集されているため、いくつかのフィールドには null 値が含まれていることに注意してください。なお、各種類のラベルは数値で表されています。具体的には、このデータセットでは「1」が「setosa(ヒオウギアヤメ)」を、「2」が「versicolor(ブルーフラッグ)」を、「3」が「virginica(ヴァージニアアイリス)」をそれぞれ表しています。
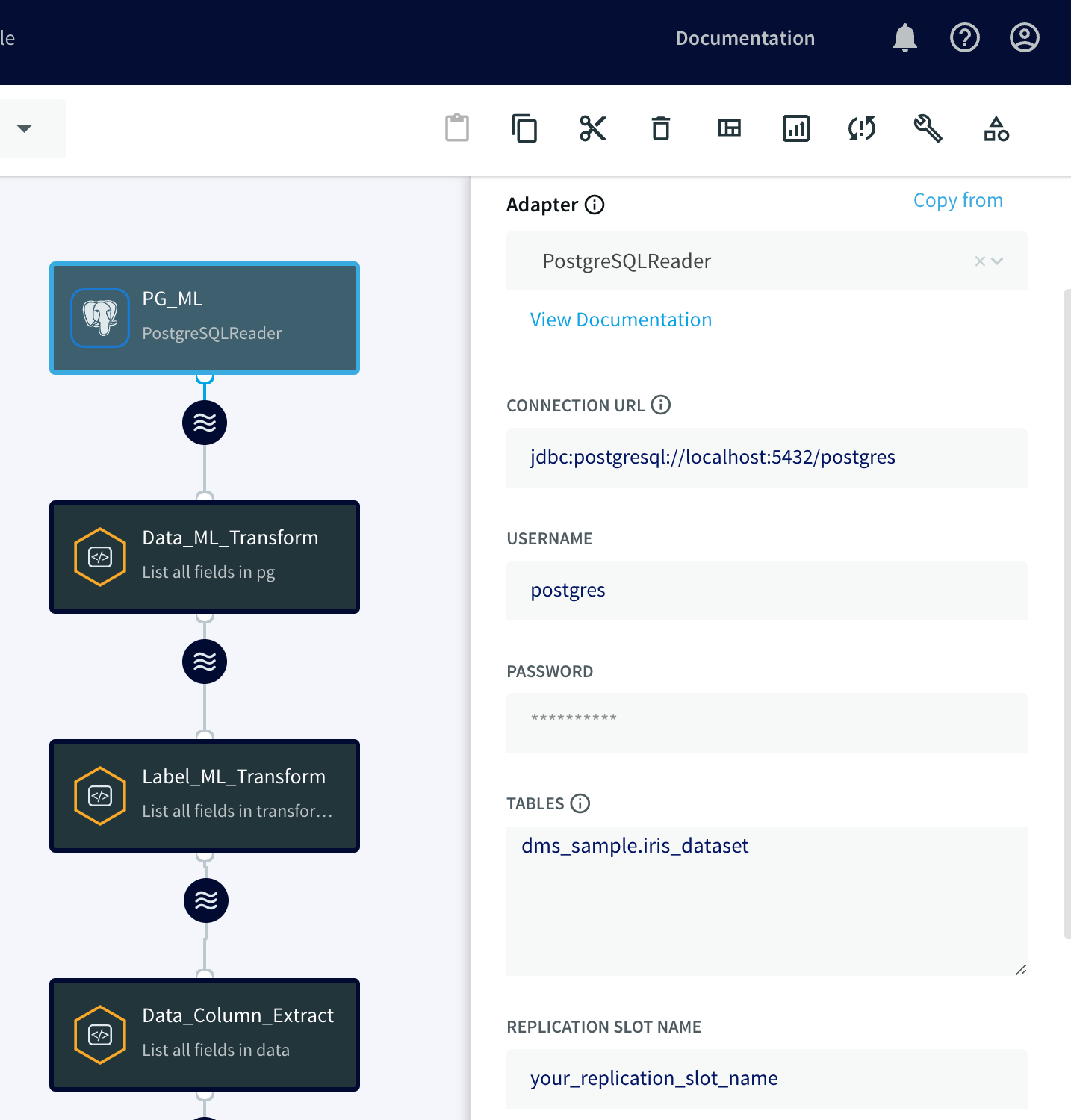
PostgreSQL データベースから元データを読み込むには、Striim の PostgreSQL Reader アダプタを使います。このアダプタは、PostgreSQL ログファイルからすべてのオペレーションと変更をキャプチャします。
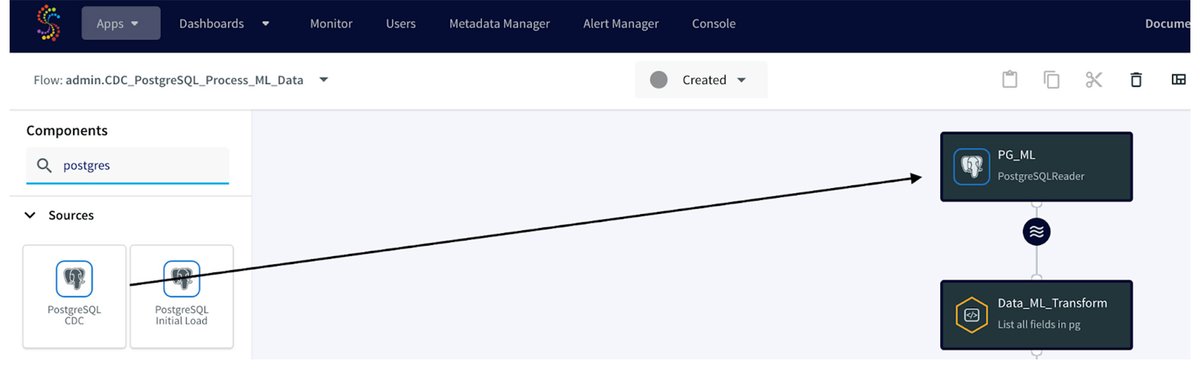
PostgreSQL Reader アダプタを作成するには、コンポーネント セクションからアダプタをドラッグ&ドロップし、接続 URL、ユーザー名、パスワードを指定し、テーブル プロパティに iris_dataset テーブルを指定します。PostgreSQL Reader アダプタは、PostgreSQL データベースの wal2json プラグインを利用してログファイルを読み取り、変更をキャプチャします。したがって、設定の一環としてソース データベース内にレプリケーション スロットを作成し、レプリケーション スロット プロパティにその名前を指定する必要があります。
セクション 2: Striim Continuous Query(CQ)アダプタの作成
Striim のコンテキストにおいて CQ とは、SQL クエリに似た Striim クエリを使用して、処理中のデータを変換するクエリを継続的に実行することを意味します。これらのアダプタを使用すると、イベントのフィルタリング、集約、結合、拡充、変換を行えます。
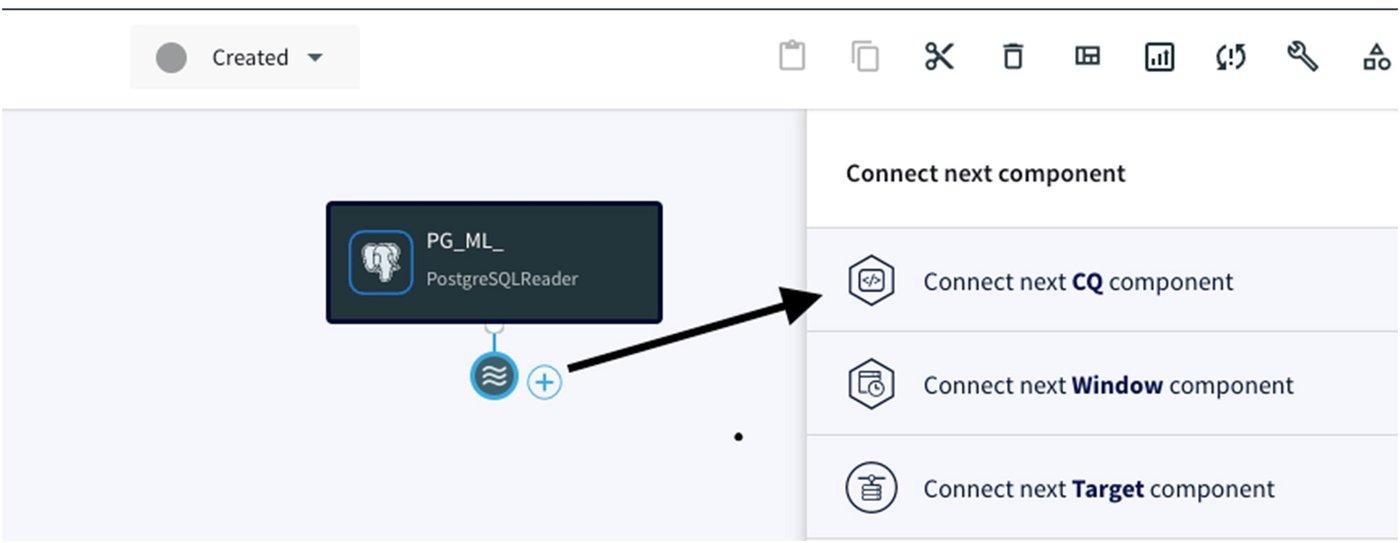
このアダプタは、BigQuery ML での ML のためにデータを変換して準備するのに役立つため、この統合において重要な役割を果たします。前のアダプタの下に CQ アダプタを作成して接続するには、ウェーブ アイコンと「+」記号をクリックし、[Connect next CQ component] を選択する必要があります。
次に、CQ アダプタで SQL 状のクエリを記述する手順を詳しく説明します。また、Postgres データベースからデータを読み込んだ後、処理中のデータが Striim によってどのように変換されるかを説明します。
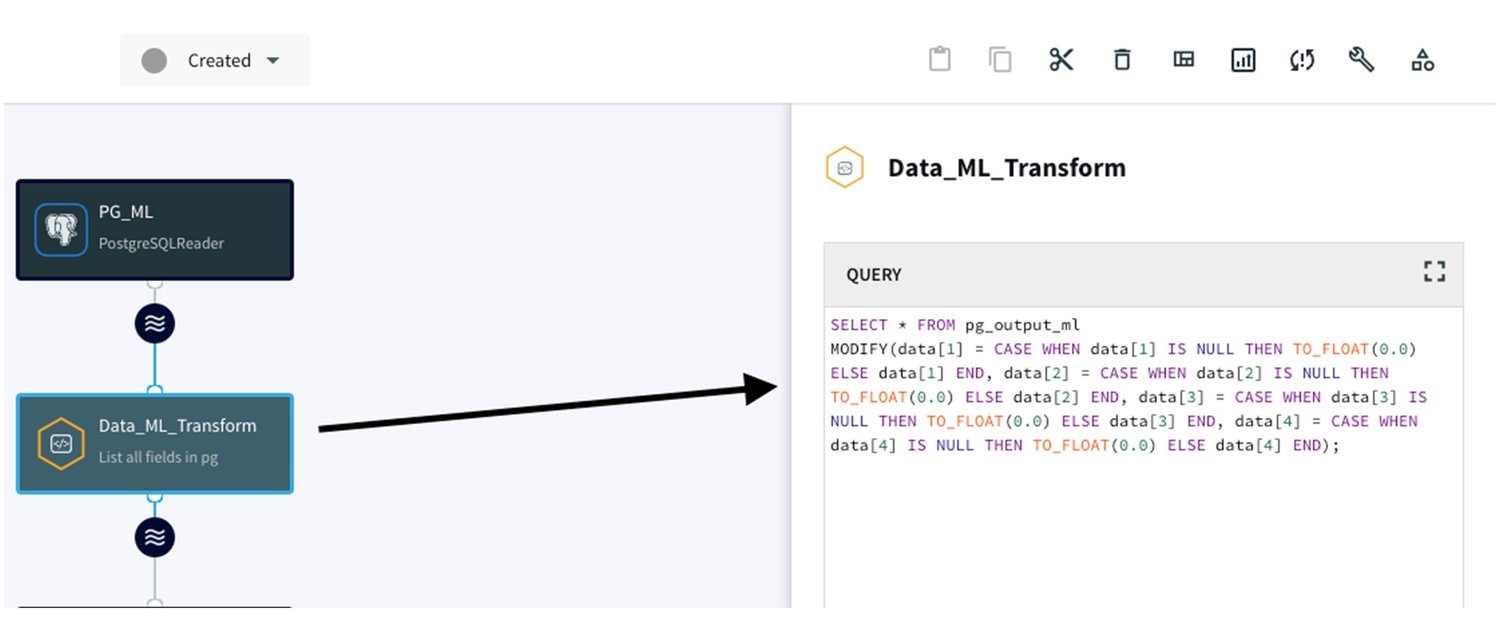
- null 値の処理:
null 値を浮動小数点数 0.0 に変換する CQ アダプタを構築し、データの整合性と完全性を確保します。この変換を行うための SQL クエリは次のとおりです。
この CQ に PostgreSQL Reader アダプタを接続することで、シームレスなデータ処理を実現します。
2. 種類を表す数値クラスのテキスト変換:
種類を表す数値クラスをテキストクラスに変換するために、もう一つ CQ アダプタを作成します。これにより、人がより読みやすいデータとなり、ML モデルにとって解釈しやすいものになります。
Data_ML_Transform CQ アダプタをこの CQ に接続して、ラベルの処理を行います。
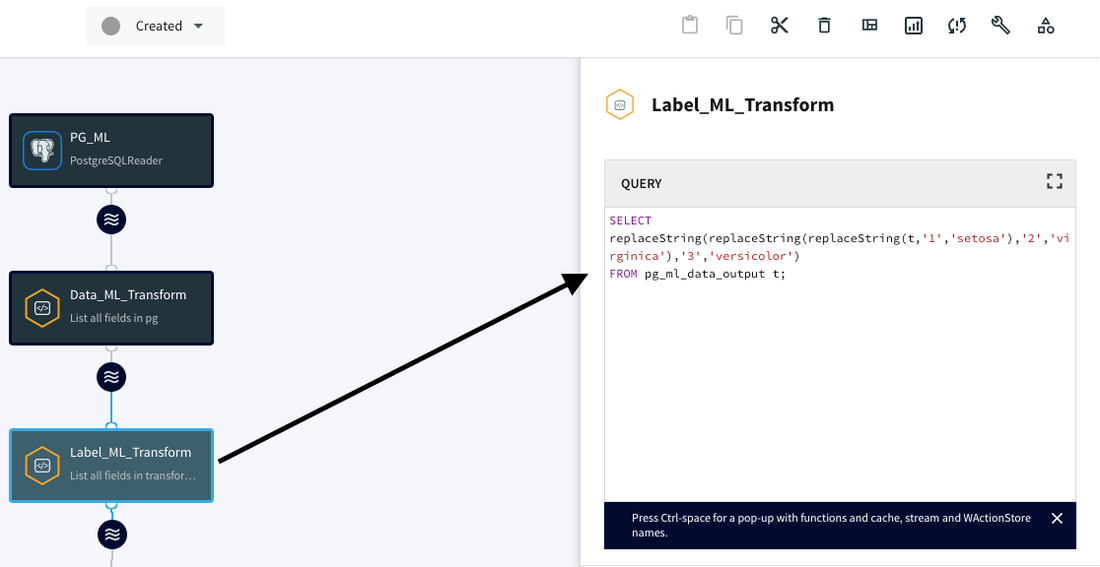
3. データ変換:
最後に、最終データを抽出して変数名 / カラム名に割り当てるための最後の CQ アダプタを作成して、BigQuery ML と統合できるようにします。
Label_ML_Transform CQ アダプタをこの CQ に接続して、データ フィールドを各変数に割り当てます。
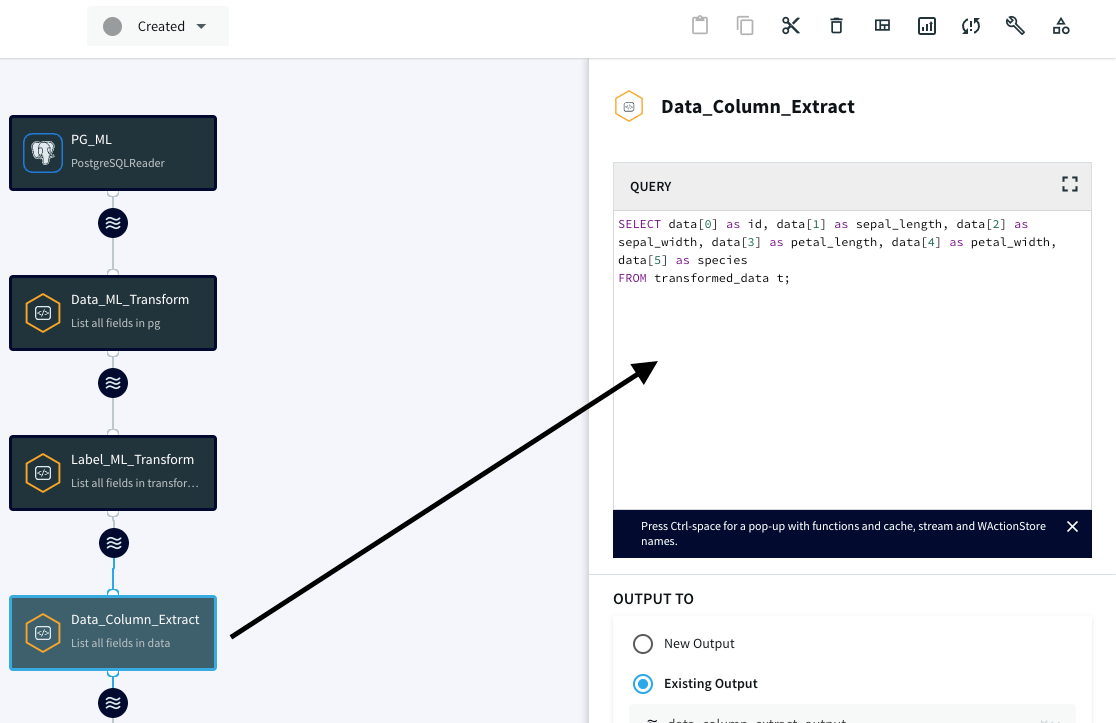
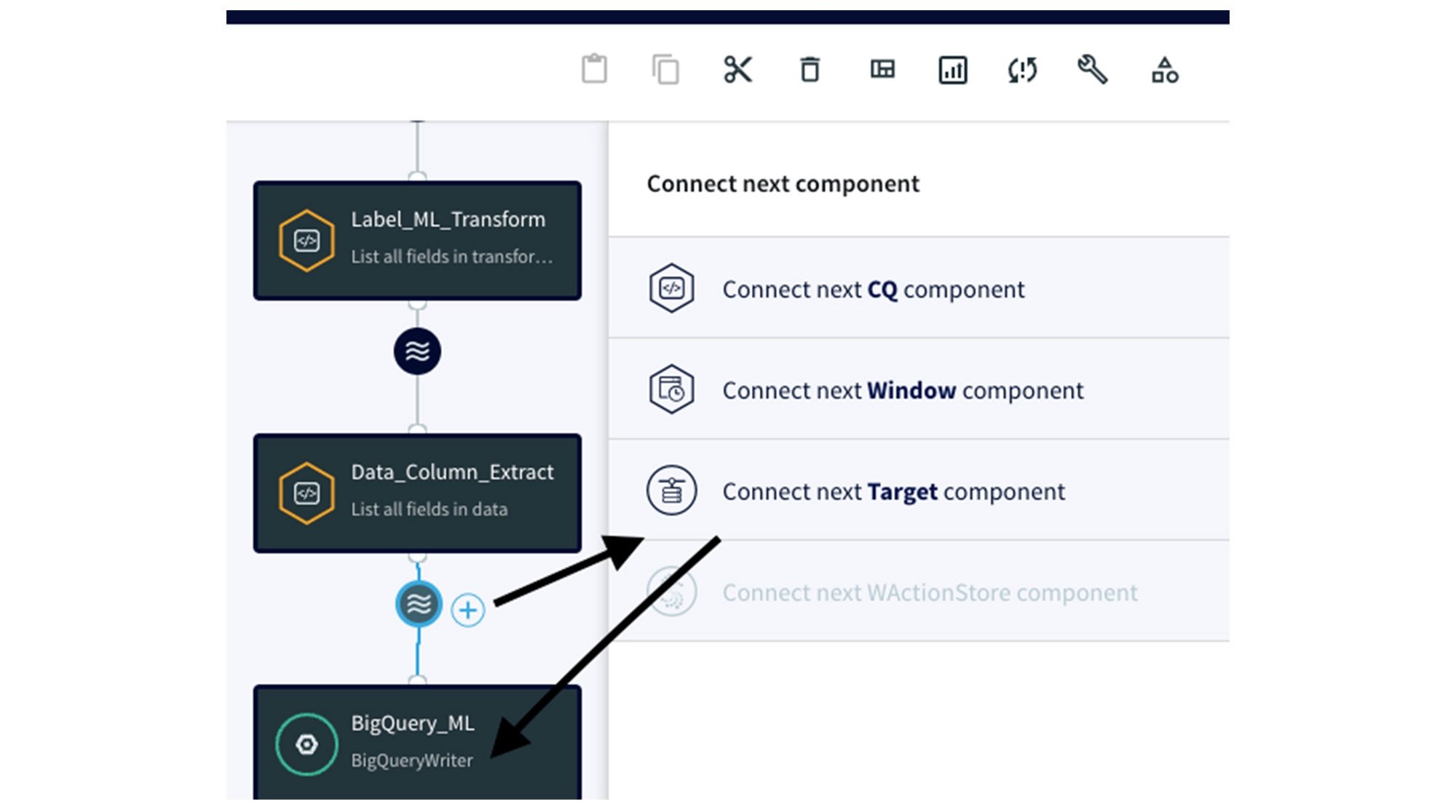
セクション 3: CQ の BigQuery Writer アダプタへの接続
各 CQ アダプタを使用してデータを準備できたので、データを BigQuery にストリーミングするためのゲートウェイである BigQuery Writer アダプタに CQ アダプタを接続する必要があります。ウェーブ アイコンをクリックし、BigQuery アダプタを接続すると、作成した CQ アダプタと BigQuery との接続が確立されます。
[Tables] プロパティでは、ColumnMap を使用して、変換されたデータを適切な BigQuery 列に接続します。
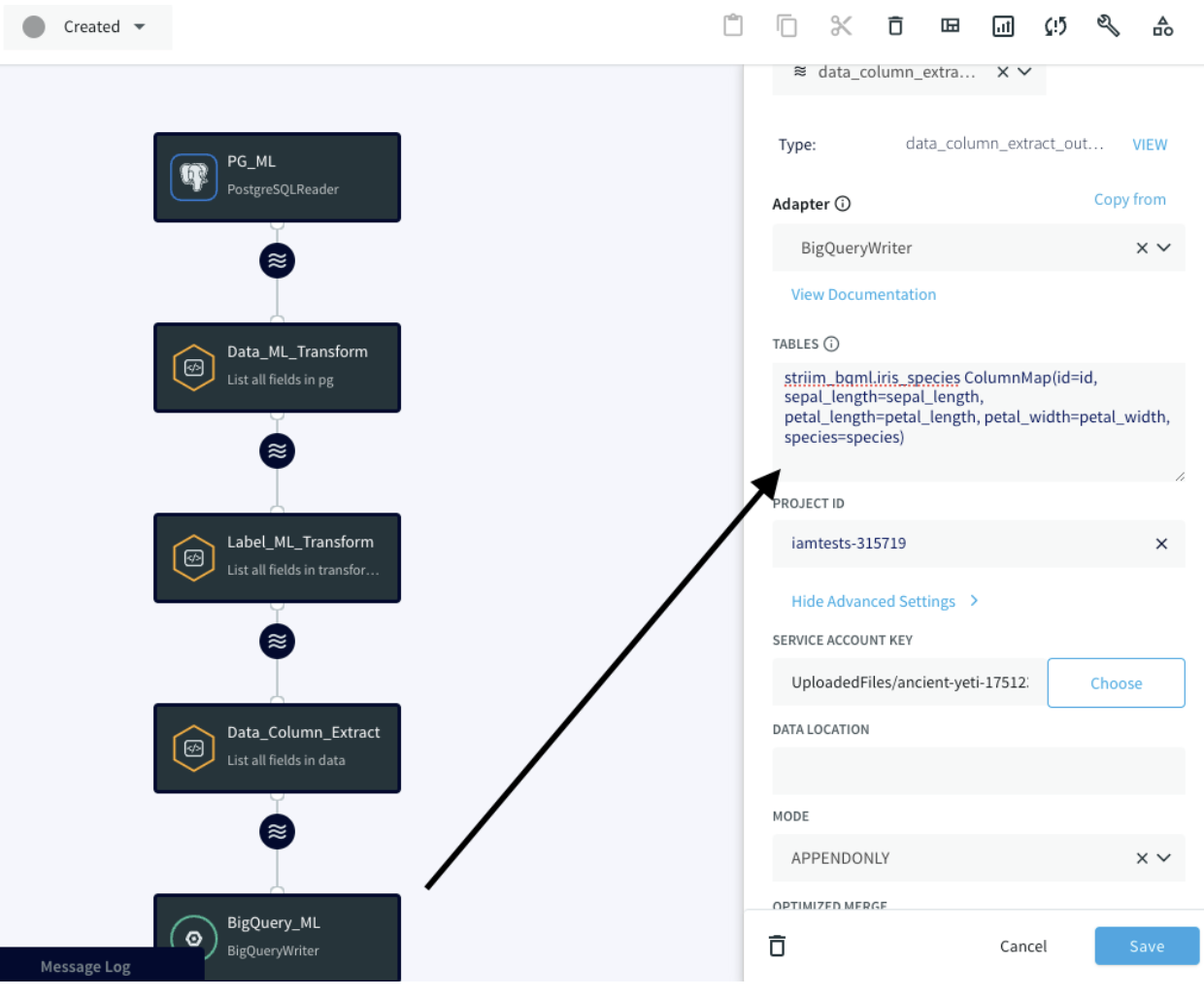
BigQuery Writer アダプタの設定を完了するために、Google Cloud アカウント内にサービス アカウントを作成する必要があります。このサービス アカウントには、BigQuery 内の特定のロールが必要となります(BigQuery ドキュメントの「ガイド」>「BigQuery の IAM の概要」>「BigQuery の IAM 事前定義ロール」を参照)。
bigquery.dataEditor(ターゲット プロジェクトまたはデータセット用)
bigquery.jobUser(ターゲット プロジェクト用)
bigquery.resourceAdmin
詳しくは、こちらのリンクをご覧ください。
サービス アカウントキーを作成した後、プロジェクト ID を指定し、サービス アカウントキーの JSON ファイルを提供して、Striim に BigQuery への接続権限を付与します。
セクション 4: データを BigQuery にレプリケートするための CDC データ パイプラインの実行
CDC データ パイプラインを実行するには、画面上部の [Created] プルダウンで [Deploy App] をクリックするだけです。
さらに [Start App] を選択すると、データ パイプラインが開始されます。
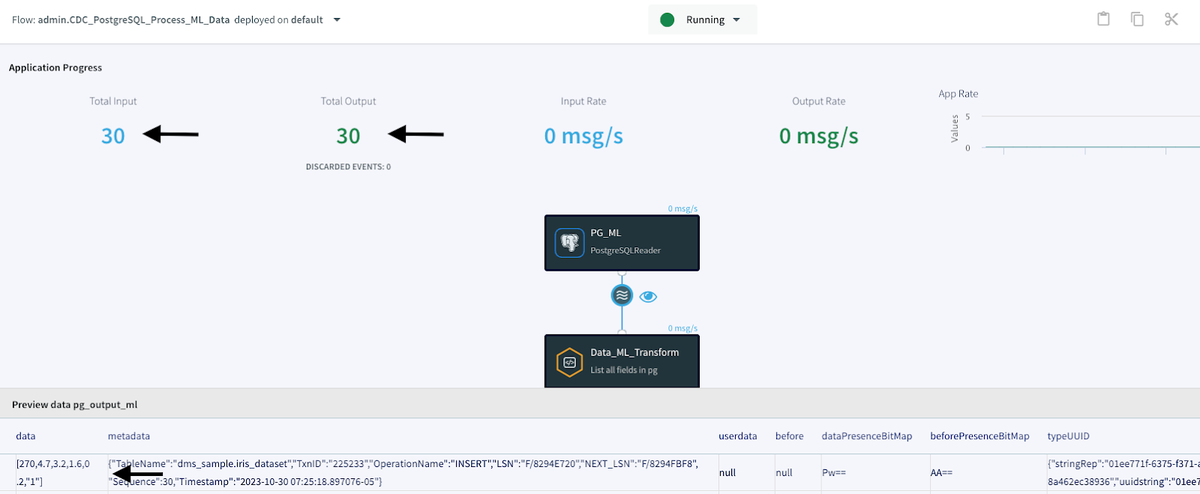
CDC データ パイプラインが正常に実行されると、進行中の 30 件の変更がソース データベースから読み取られ、この 30 件のレコードと変更が BigQuery データベースに書き込まれたことが [Application Progress] ページに表示されます。[Application Progress] ページの下部では、ソース コンポーネントとターゲット コンポーネントの間にあるウェーブ アイコンと目のアイコンを順にクリックすると、ソースからターゲットに送信されるデータをプレビューできます。以下は、元データの一例です。
以下に、CQ 変換を行った後の処理済みデータを示します。[petal_width] 列の null 値が「0.0」に変換され、種類を表す数値クラス「1」が「setosa」に変換されていることに注目してください。
セクション 5: BigQuery ML モデルの構築
データが BigQuery にシームレスに流れるようになり、Google Cloud の ML サービスの力を活用できるようになりました。BigQuery ML は大規模なコーディングや外部ツールを必要とせず、ML モデルを作成するためのユーザー フレンドリーな環境を提供します。次に、BigQuery でロジスティック ML モデルを構築する手順を説明します。モデルの作成、トレーニング、予測の例を示し、プロセスの概要を把握できるようにしています。
- BigQuery iris_dataset テーブルにデータが正しく入力されていることを確認します。ここで、「ancient-yeti-175123」はプロジェクト名であり、「DMS_SAMPLE」は指定したデータセットです。個々のプロジェクト名とデータセット名は異なる場合があることに注意が必要です。

2. 次のクエリを実行して、iris_dataset テーブルからロジスティック回帰モデルを作成します。

ロジスティック回帰は、分類タスクに使用される統計的手法であり、さまざまな値を取り得る結果を予測するのに適しています。このアヤメ属のデータセットのコンテキストにおいてロジスティック回帰を使用すると、花の特徴に基づき、あるアヤメ属の花が特定の種類に属する確率を予測できます。このモデルは、従属変数が分類的である問題を扱うときに特に便利であり、分類のシナリオに関する貴重な情報を得られます。
では、このクエリの内容を詳しく見ていきましょう。
CREATE MODEL IF NOT EXISTS: クエリのこの部分は、指定した名前の ML モデル(ここでは「striim_bq_model」)を、まだ存在しない場合は新たに作成します。
OPTIONS: モデルに対するさまざまなオプションやハイパーパラメータを定義するセクションです。各オプションの意味は、それぞれ次のとおりです。
-
model_type='logistic_reg': ロジスティック回帰モデルを作成することを指定します。
-
ls_init_learn_rate=.15: モデルの初期学習率を 0.15 に設定します。
-
l1_reg=1: 正則化強度 1 の L1 正則化を適用します。
-
max_iterations=20: トレーニングの反復回数の上限を 20 に設定します。
-
input_label_cols=['species']: ロジスティック回帰のターゲット変数(ここでは「species」)を指定します。
-
data_split_method='seq': モデルのトレーニングと評価にデータのシーケンシャル分割手法を使用します。
-
data_split_eval_fraction=0.3: データの 30% をモデル評価に割り当てます。
-
data_split_col='id': [id] 列を使用して、データをトレーニング セットと評価セットに分割します。
AS: このキーワードは、モデルのデータソースを定義する SELECT ステートメントの開始を示します。
SELECT: クエリのこの部分は、iris_dataset テーブルから特徴とターゲット変数を選択します。このデータは、ロジスティック回帰モデルのトレーニングと評価に使用されます。
-
id、sepal_length、sepal_width、petal_length、petal_width は、モデルのトレーニングに使用される特徴列です。
-
species は、モデルが予測するターゲット変数またはラベル列です。
要約すると、このクエリは BigQuery ML の iris_dataset データを使用して、striim_bq_model という名前のロジスティック回帰モデルを作成します。さらに、モデルをトレーニングおよび評価するためのさまざまなモデル設定とハイパーパラメータを指定します。このモデルの目的は、特徴として指定した別の列に基づき、「種類(species)」を予測することです。
3. 次のクエリを実行して、モデルを評価します。

ML モデルのパフォーマンスを評価することは、新しい未知のデータに対する一般化の有効性を測るために不可欠なステップです。このプロセスには、モデルの予測精度を定量化し、そのメリット、デメリットについての情報を得ることも含まれます。このクエリは、以前に作成した striim_bq_model という名前の ML モデルの評価を実行します。このクエリが実行する内容は、次のとおりです。
SELECT * FROM ML.EVALUATE: クエリのこの部分は ML.EVALUATE 関数を使用します。これは、ML モデルのパフォーマンスを評価するための BigQuery ML 関数です。この関数は、テスト データセットの実際の値と比較することによってモデルの予測値を評価します。
(MODEL ancient-yeti-175123.DMS_SAMPLE.striim_bq_model, ... ): ここでは、評価するモデルを指定します。評価するモデルは striim_bq_model という名前であり、ancient-yeti-175123.DMS_SAMPLE データセット内に存在します。
(SELECT * FROM `ancient-yeti-175123.DMS_SAMPLE.iris_dataset): クエリのこの部分は、テスト データセットとして使用する iris_dataset からデータを選択します。モデルの予測値がこのデータセットの実際の値と比較され、パフォーマンスの評価が行われます。
要約すると、このクエリは iris_dataset のデータを使って striim_bq_model を評価し、このモデルの予測精度がどの程度かを推定します。この評価結果から、モデルの精度とパフォーマンスについての情報が得られます。
4. では、前の手順でトレーニングしたモデルを使用して、sepal_length、petal_length、sepal_width、petal_width の特徴に基づき、アヤメ属の花の種類を予測してみましょう。

上のスクリーンショットを見ると、striim_bq_model モデルにより、予測された種類、予測された種類の確率、ML.PREDICT 関数で使用された特徴列の値などの情報が提供されていることがわかります。
まとめ
Striim と BigQuery ML を統合すると、データ サイエンティストや ML エンジニアは、繰り返しソースからデータを収集してデータ クリーニング処理を実行する必要がなくなり、ML モデルの構築とモニタリングだけに集中できるようになります。この強力な組み合わせにより、意思決定を迅速化し、顧客体験を向上させ、オペレーションを合理化することができます。皆様のリアルタイム ML プロジェクトでも、この機能統合についてぜひご検討ください。この統合は、データの活用によってビジネスに関する分析情報と予測を得る方法を一変させる可能性を秘めています。Striim と BigQuery ML で、リアルタイムのデータ処理と ML の未来を体感しましょう。
Striim と Google Cloud の活用方法について詳しくはこちらのリンクをご覧ください。
謝辞: Bruce Sandell、Purav Shah をはじめ、プロセス実施中にこのコラボレーションに貢献し、ガイダンスを提供してくれた Google Cloud と Striim チームの多くのメンバーに感謝します。
ー Simson Chow 氏 Striim シニア クラウド ソリューション アーキテクト
ー Maruti C Google Cloud グローバル パートナー アーキテクト



