Fivetran と BigQuery による不正行為の自動検出
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
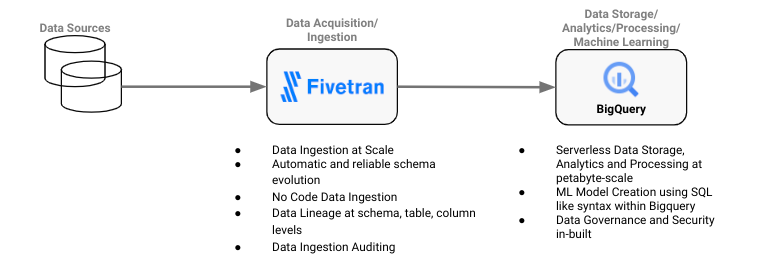
現在の流動的な環境において、企業は不正なトランザクションを特定し、それらに対処するため、より迅速なデータ分析と予測的な分析情報を必要としています。一般的に、データ エンジニアリングと ML の観点から見た不正行為への対処は、主に以下の手順で構成されます。
- データの取得と取り込み: トレーニング データを取り込んで保存するため、分散したさまざまなソース(ファイル システム、データベース、サードパーティ API)にまたがるパイプラインを確立します。このデータは有用な情報を豊富に含み、不正行為を予測する ML アルゴリズムの開発に役立ちます。
- データの保存と分析: スケーラブルで信頼性に優れた高性能なエンタープライズ クラウド データ プラットフォームを活用して、取り込まれたデータを保存、分析します。
- ML モデルの開発: 保存されたデータからトレーニング セットを構築し、それらのデータに対して ML モデルを実行することで、不正なトランザクションと正当なトランザクションを識別できる予測モデルを構築します。
不正行為を検出するためのデータ エンジニアリング パイプラインの構築においては、一般的に以下の課題が発生します。
- スケールと複雑性: データの取り込みは、特に多様なソースからのデータを利用する組織では複雑な作業になることがあります。取り込みパイプラインを社内で開発する場合、多くのデータ エンジニアリング リソースが数週間または数か月単位で必要となり、中核となるデータ分析業務から貴重な時間が奪われる可能性があります。
- 管理作業とメンテナンス: 手動でのデータ保存とデータ管理(バックアップと障害復旧、データ ガバナンス、クラスタ サイジングを含む)は、ビジネスのアジリティを大幅に妨げ、価値の高いデータ インサイトの生成を遅らせる可能性があります。
- 修得の難しさと厳しいスキル要件: データ パイプラインと ML モデルの両方を構築するデータ サイエンス チームを編成する場合、不正行為検出ソリューションを導入し、活用できるようになるまでに大幅な期間がかかる可能性があります。
こうした課題を解決するには、価値実現までの期間、設計のシンプルさ、スケーリング能力という 3 つの主要テーマを重視した戦略的アプローチが必要です。Fivetran をデータの取得、取り込み、移動に活用し、BigQuery を高度なデータ分析と ML 機能に活用することで、これらの課題に対処できます。
Fivetran によるデータ統合の効率化
ソースシステムの増分変更をクラウド データ プラットフォームに確実に保存するという課題は、日常的にこの処理に携わっていなければその重要性を過小評価しがちです。私は以前に法人向け金融サービス会社と仕事をしていましたが、その会社は主任アーキテクトいわく「遅くていいかげんな」古いテクノロジーのせいで行き詰まっていました。DB2 ソースに新しい列を追加すると面倒なプロセスが発生し、変更が分析プラットフォームに反映されるまでに 6 か月もかかっていました。
この遅れが原因となり、この会社では、ダウンストリームのデータ プロダクトに供給されるデータの新しさと精度が大幅に低下しました。その結果、ソースのデータ構造が変更されるたびに、長く、混乱を招くダウンタイムが分析プロセスで発生していました。この会社のデータ サイエンティストは、不完全で古い情報に悩まされていました。
効果的な不正行為検出モデルを構築するには、すべてのデータで以下の条件が満たされている必要がありました。
- 利用者とコンテキストへの適合性: データはパーソナライズされ、ユースケース固有でありながら、品質、真実性、透明性、信頼性に優れている必要があります。
- 可用性と適時性: データは常に利用でき、パフォーマンスが高く、使い慣れたダウンストリームのデータ使用ツールで円滑にアクセスできる必要があります。
この会社が Fivetran を選んだ主な要因は、スキーマ進化と、複数のソースから新しいクラウド データ プラットフォームへのスキーマ ドリフトを、自動で確実に処理できることでした。ソースコネクタの数が 450 を超える Fivetran では、データベース、アプリケーション、ファイル、イベントなどの多様なソースからデータセットを作成できます。
この選択は状況を一変させました。Fivetran によって質の高い安定したデータフローが確立されたことで、この会社のデータ サイエンティストは、迅速なテストとそのモデルの改善、インサイトとアクションのギャップの縮小、ギャップの発生防止に専念できるようになりました。
この会社にとって最も重要だったのは、データの正規化と、新しいクラウドの移行先に移行するオンプレミスまたはクラウドベースの移行元で必要とされた変更の管理を、Fivetran が自動で確実に実現できることでした。これらの変更には、以下が含まれていました。
- スキーマの変更(スキーマ追加も含む)
- スキーマ内のテーブル変更(テーブルの追加、削除など)
- テーブル内の列変更 (列の追加、列の削除、復元可能な削除など)
- データ型の変換とマッピング(SQL Server がソースの例はこちら)
この会社では、新しいコネクタに対するデータセットを、希望するソース変更の処理方法を Fivetran に伝える単純なプロセスで選択でき、コーディング、構成、カスタマイズは不要でした。Fivetran はこのプロセスを設定して自動化し、クラウド データ プラットフォームに変更が移動する頻度を固有のユースケース要件に基づいてクライアントが決定できるようにしました。
Fivetran は、DB2 以外の幅広いデータソース(他のデータベースと多様な SaaS アプリケーションを含む)に対応できることを実証しました。大きなデータソース(特にリレーショナル データベース)の場合、Fivetran は膨大な量の増分変更にも対応できました。Fivetran が実現した自動化により、既存のデータ エンジニアリング チームは人員を増やすことなくスケーリングを実現できました。Fivetran のシンプルさと使いやすさにより、適切なガバナンスとセキュリティ対策を確立できたコネクタ設定を事業部門でも導入できるようになりました。
金融サービス会社では、ガバナンスと完全なデータの来歴が非常に重要です。最近リリースされた Fivetran Platform Connector は、これらの課題を解決し、各 Fivetran コネクタ、移行先、またはアカウント全体に関連付けられた豊富なメタデータへのシンプルで、簡単で、ほぼ即時のアクセスを可能にします。Fivetran の使用料金が発生しない Platform Connector は、データ パイプラインのメタデータをエンドツーエンドで可視化します(クラウド データ プラットフォームでは 26 のテーブルが自動的に作成されます。ERD はこちらを参照)。これには以下が含まれます。
- 移行元と移行先両方のリネージ: スキーマ、テーブル、列
- 使用量とボリューム
- コネクタの種類
- ログ
- アカウント、チーム、ロール
この可視性の向上により、金融サービス会社はデータをより深く理解できるようになり、データ プログラムへの信頼が高まります。これは、金融サービスとそのデータ アプリケーションのコンテキストでは不可欠な要素であるガバナンスとデータの来歴を提供する貴重なツールとなります。
BigQuery のスケーラブルで効率的な不正行為検出用データ ウェアハウス
BigQuery は、サーバーレスで費用対効果に優れたデータ ウェアハウスです。スケーラビリティと効率性に優れ、企業での不正検出に適しています。サーバーレス アーキテクチャにより、インフラストラクチャ設定と継続的なメンテナンスの必要性が最小限に抑えられ、データチームはデータ分析と不正行為の防止策に注力できます。
BigQuery の主なメリット:
- 分析情報生成の迅速化: BigQuery はアドホック クエリとテストをキャパシティの制約なしで実行できるため、迅速なデータ探索と、不正行為のパターンをより短時間で特定することが可能になります。
- オンデマンドのスケーラビリティ: BigQuery のサーバーレス アーキテクチャにより、状況に応じたスケールアップとスケールダウンが自動化されるため、リソースを必要に応じて確保し、オーバープロビジョニングを回避できます。これにより、時間がかかり、エラーが発生しがちなデータチームによるインフラストラクチャの手動スケーリングが不要になります。ここで重要なのは、BigQuery はクエリの実行中、処理中でもスケーリングが可能であるということです。これは、他の最新型クラウド データ ウェアハウスに対する明確な差別化要因となります。
- データ分析: BigQuery データセットはペタバイト単位までスケールできます。そのため、金融取引データをほぼサイズ制限なしで保存、分析できます。これにより、データ内に隠れたパターンと傾向を発見し、不正行為を効果的に検出できます。
- ML: BigQuery ML では、異常検出から分類まで、幅広い既成の不正行為検出モデルが提供されます。これらはすべて、シンプルな SQL クエリを介して実装されています。これによって ML をより多くの人が利用できるようになり、固有のニーズに応じた迅速なモデル開発が可能になります。BigQuery ML でサポートされている各種のモデルについては、こちらをご覧ください。
- 大規模な推論を可能にするモデルのデプロイ: BigQuery はバッチ推論をサポートしていますが、Google Cloud の Vertex AI を活用してストリーミング財務データをリアルタイムでも予測できます。BigQuery ML モデルを Vertex AI にデプロイし、即時のインサイトと実用的なアラートを取得することで、ビジネスをリアルタイムで保護します。
Fivetran と BigQuery を組み合わせることで、複雑な問題に対するシンプルな設計、つまりリアルタイムの実用的なアラートを提供できる効果的な不正行為検出ソリューションを実現します。本ブログ記事の次のシリーズでは、実際のデータセットを使用し、Fivetran と BigQuery のインテグレーションの実践的な導入に焦点を当て、不正なトランザクションを正確に予測できる ML モデルを BigQuery で作成します。
Fivetran は Google Cloud Marketplace で入手できます。
-Google、シニア クラウド データ アーキテクト Ankit Virmani
-Fivetran、パートナー セールス エンジニアリング担当シニア グローバル ディレクター Kelly Kohlleffel 氏



