リアルタイムな市場データ向けのサーバーレス パイプラインの構築
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: この投稿は、Google Cloud での市場データの処理に関する特別シリーズの第 2 部です。今回は、サーバーレス コンポーネントをどのように活用して、柔軟性の高いデータ取り込みパイプラインを構築したかに焦点を当てます。クラウドでのリアルタイムな市場データの可視化については、最初の投稿をご覧ください。
資本市場企業は、無限にあるリアルタイム データセットから迅速に分析情報を抽出する必要があります。企業の市場データのパイプラインは、主要な設計上の考慮事項としてエンドユーザーのデータアクセス要件を検討する必要があるものの、硬直化したデリバリーのメカニズムと分析ツールがこの目標を阻害します。サーバーレス データは、最適な新しいツールの導入時に運用上の障害を取り除くことで、この問題を解決できます。これにより、1 つのデータ パイプラインを、たとえばリアルタイム機械学習モデルのトレーニングと過去データの分析といったような、別々のユーザー目標に利用することが容易になります。
サーバーレス データ パイプラインを使用すれば、資本市場企業はインフラストラクチャではなく分析に集中できるため、急速に変化する業界で常に優位性を保つことができます。この投稿では、CME Group の Smart Stream による Top Of Book(TOB)JSON フィードを使ったリアルタイムのデータ取り込みのベスト プラクティスをご紹介します。リファレンス アーキテクチャは、データ使用パターンとスキーマを考慮して、ストレージ オプションとトランスポート オプションを選択します。また、ビジネス ロジックを Cloud Functions にカプセル化することで、開発の速度を向上させて運用上の複雑さを軽減します。こうしたパターンと設計は、さまざまなユースケースに幅広く適用できます。
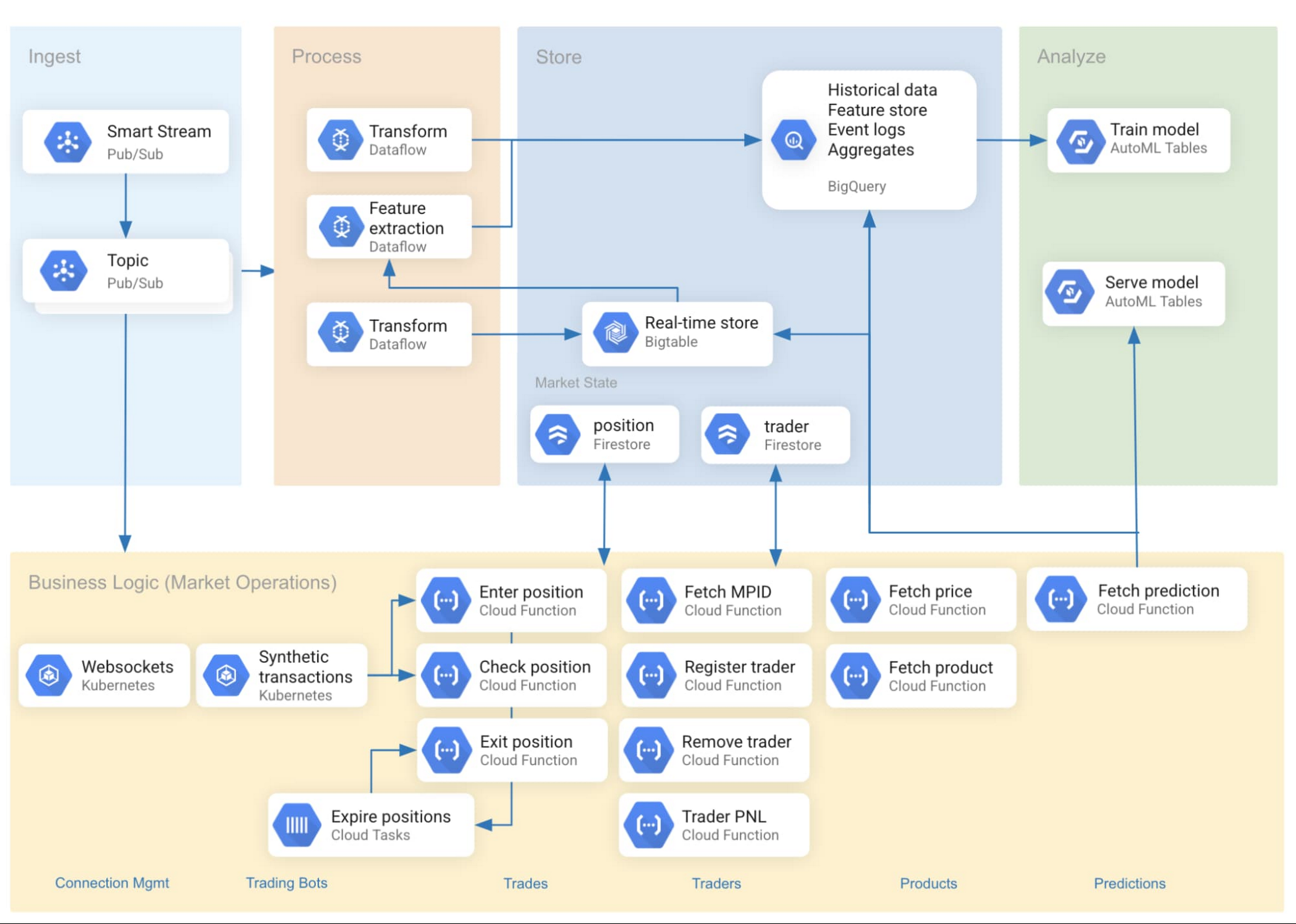
図 1 は、取り込みパイプラインのリファレンス アーキテクチャを示しています。
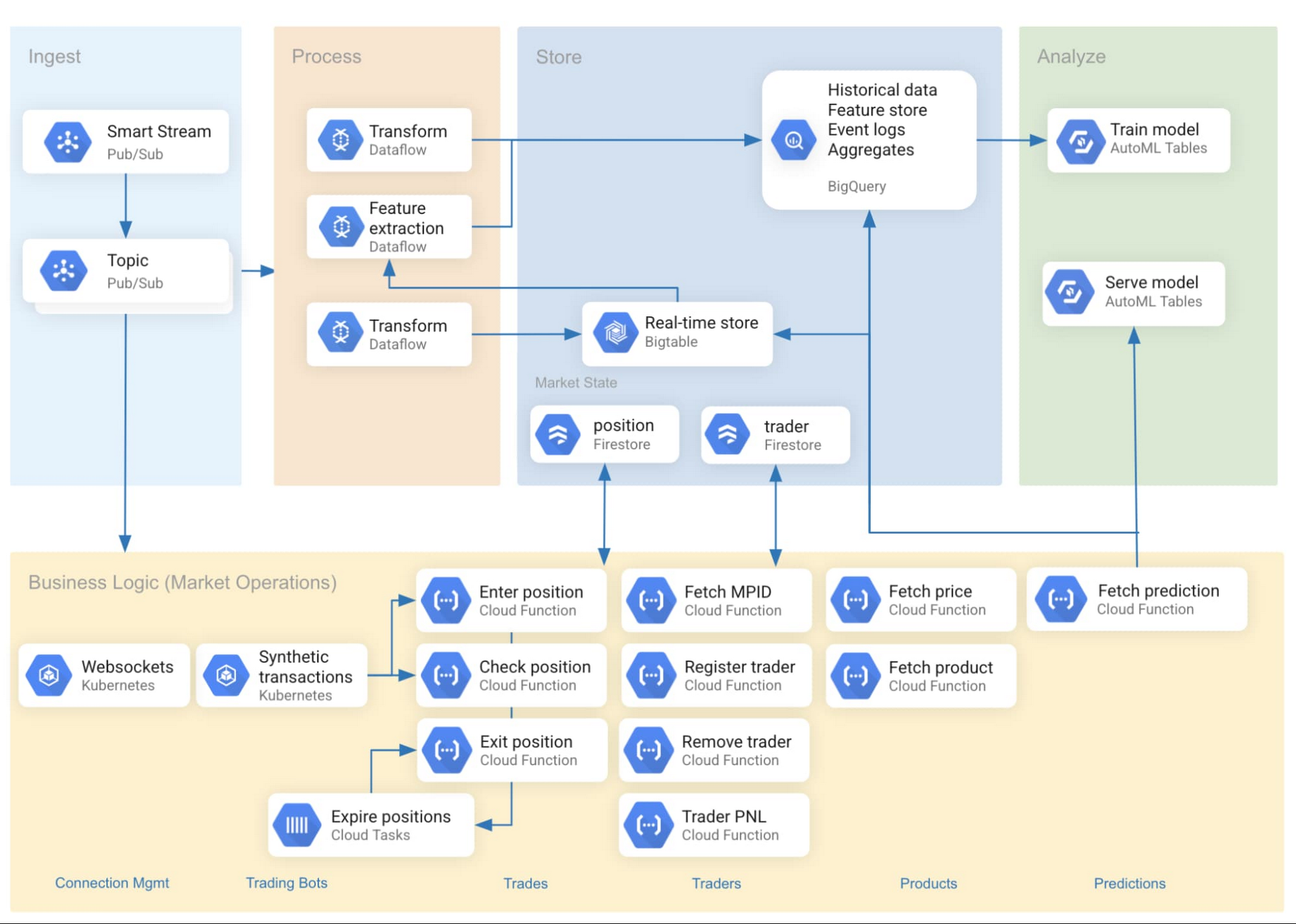
リアルタイムのデータ取り込みの設定方法
使用したリアルタイム データソースは、Google Cloud で利用できるサービスである CME Group の Smart Stream です。データは、UDP で実行されるマルチキャスト ストリームとして CME Globex 取引プラットフォームから送信されます。商品の価格データは、相互接続を介してさまざまな Pub/Sub トピックに転送され、それぞれが銀や濃縮オレンジ ジュースの先物などの単一の商品に対応します。
Pub/Sub はサーバーレスで、その他の Google Cloud サービスと緊密に統合されています。また、Google により完全に管理されており、ユーザーが抱えているスケーリング、プランニング、信頼性に関する多くの問題を緩和します。Google は、BigQuery や Cloud Storage などのさまざまなシンクに Pub/Sub からデータを取り込むためのオープンソースの Dataflow テンプレートを提供しています。
Bigtable はリアルタイムのデータストアとして活用され、最新のデータと機能を予測エンドポイントに提供してきました(エンドポイントは、このデータを Google Cloud の AI Platform でホストされる機械学習モデルに渡します)。これと並行して、BigQuery はスケーラブルな分析データハウスとしても使用されています。Pub/Sub データは、別々の Dataflow ジョブを使用して両方のシンクにストリーミングされました。
図 2 は、Google 提供の PubSub-to-BigQuery パイプライン用テンプレートを使用した、シェル スニペットによる Dataflow ジョブの起動です。
図 2: Pub/Sub から BigQuery へのメッセージ取り込みのための Dataflow テンプレートの起動
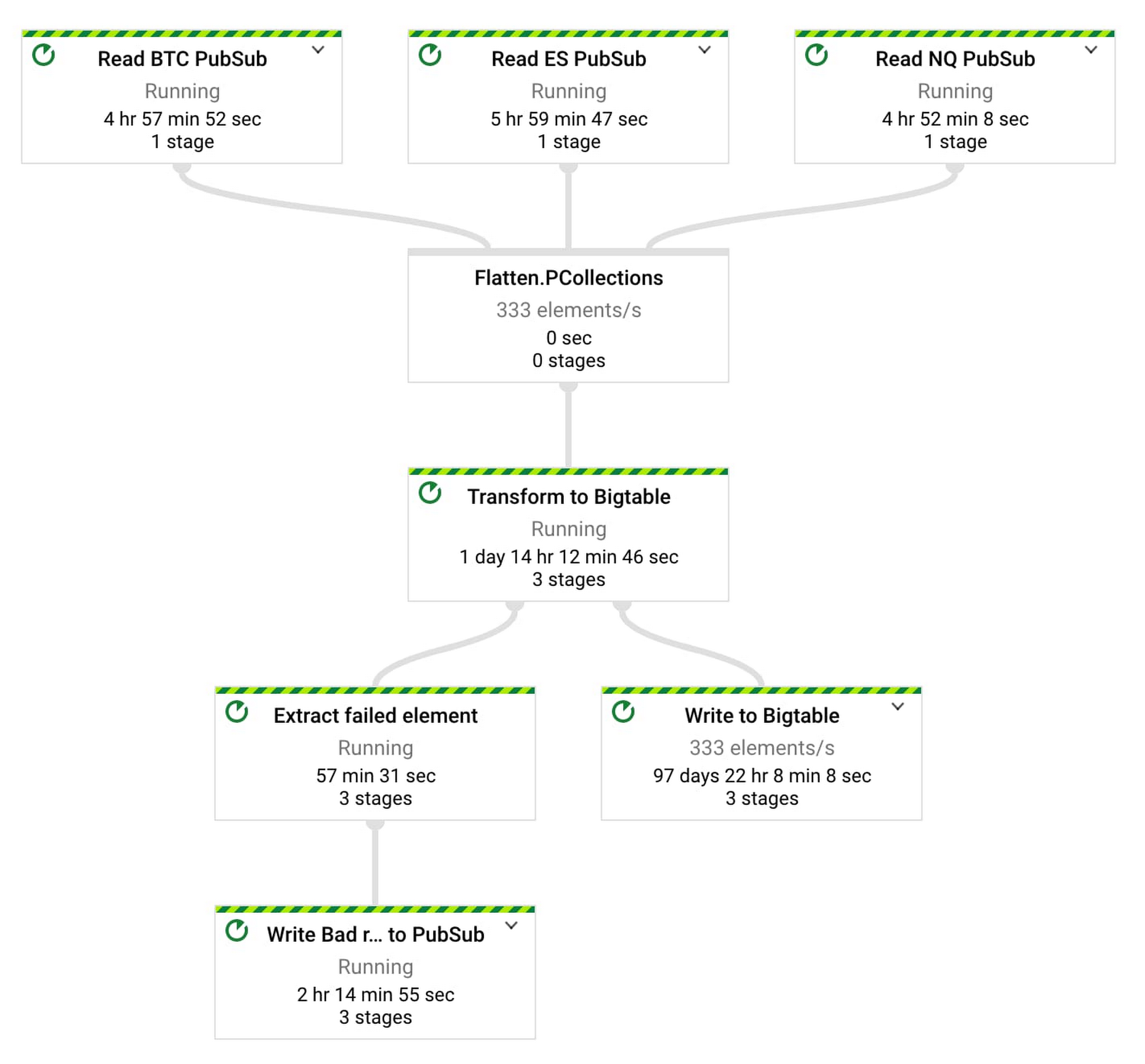
図 3 は、入力 Pub/Sub トピックが 3 つの Dataflow パイプライン(取引インストルメンテーションあたり 1 つ)とシンクとしての Bigtable を示しています。
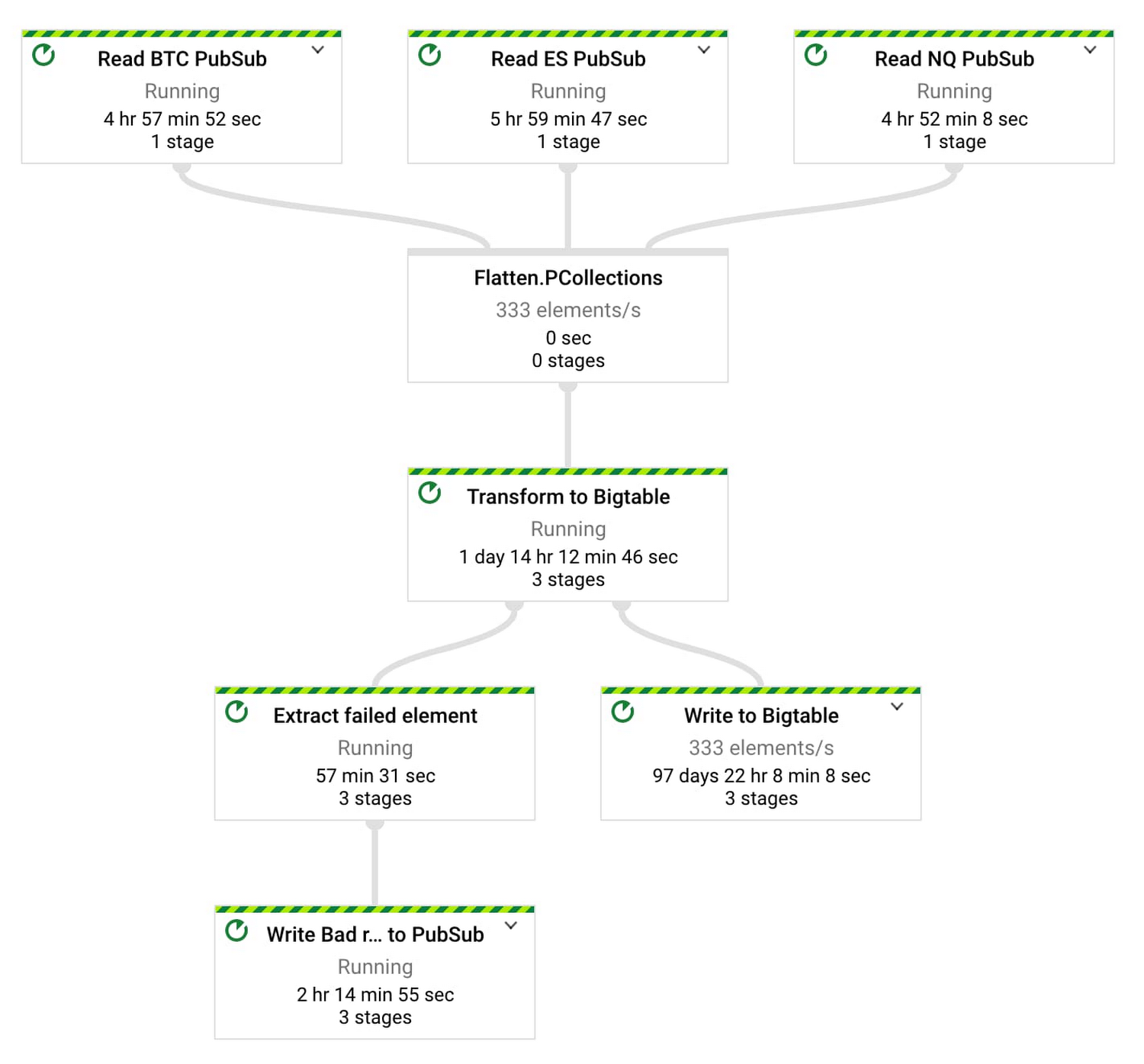
図 4 のクラスは、Apache Beam パイプラインを定義して、1 つのトピック(商品コード)からデータを取り込み、Bigtable に書き込みます。
図 4: Apache Beam 取り込みパイプラインから Bigtable へ
一見すると、アプリの予測モデルとウェブ フロントエンドのグラフでは、要求されるデータの更新頻度は似ています。ところが、よく観察すると相違点が浮かび上がります。グラフはデータストアを介在せずに、Smart Stream の価格データを直接使用できます。そのため、フロントエンドのデリバリーは、WebSocket を介した Pub/Sub に決定しました。
Pub/Sub をサーバーレス取り込みコンポーネントで使用することで、アーキテクチャの柔軟性が高まり、制約になっていた運用上の複雑性が緩和されました。1 つの Pub/Sub トピックから配信されるデータは、機械学習のために Bigtable に保存されるか、分析のために BigQuery に保存されます。これに加えて、WebSocket 経由で直接送信されて、急速に変化する可視化を強化します。
ストレージとスキーマの考慮事項
データの使用時間に対して、データ管理に費やされる時間を最小限にとどめることが理想的です。スキーマの設計とストレージ アーキテクチャが適切に行われると、ユーザーは、自分たちがデータのために働くのではなく、データが自分たちのために働いていると実感できます。
行キーの設計は、あらゆる Bigtable パイプラインにとって重要です。Google のキーは、商品のシンボルと反転タイムスタンプを連結します。これにより、アクセス パターン(「N 件の最新レコードをフェッチ」)を最適化しながら、ホットスポット化を回避します。
タイムスタンプの反転は、プログラミング言語の長整数の最大値(Java の java.lang.Long.MAX_VALUE など)からタイムスタンプを引くことによって行います。これで、<SYMBOL>#<INVERTED_TIMESTAMP> というキーが形成されます。商品コードの最新イベントはテーブルの先頭に現れ、クエリ応答時間のスピードが向上します。この手法で主要な(複数の新しい商品シンボルをクエリする)アクセス パターンに対応できますが、その他のパフォーマンスは低下する可能性があります。時系列データ用の Bigtable スキーマ設計に関する投稿には、さらに多くのコンセプト、パターン、例が掲載されています。
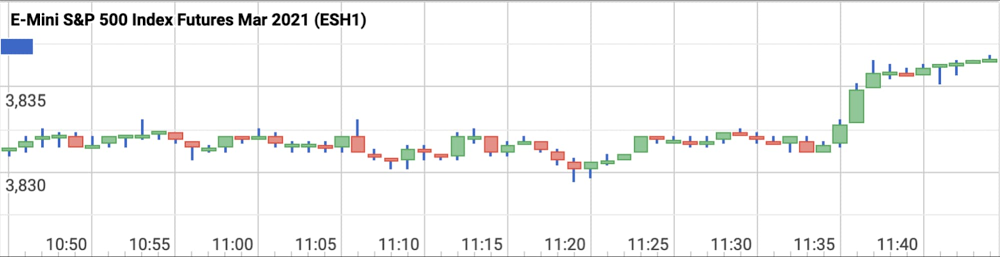
図 5 は、Bigtable に取り込まれたサンプル データポイントを示しています。
図 5: Bigtable における市場データレコードの表現
Bigtable は低レイテンシのデータを機械学習モデルに配信するのには適していますが、より長いルックバック分析のためには、さらに分析的に調整されたクエリエンジンが必要でした。BigQuery が最適だったのは、サーバーレスでスケーラブルという性質に加えて、AutoML のようなツールと統合されているためです。
設計にあたって、BigQuery データを従来の OHLC「ローソク足」として可視化するための 3 つのオプションを検討しました。最初のオプションは、ネストした Pub/Sub JSON を BigQuery に格納し、複雑な SQL クエリを書いてネスト解除と集計を行う方法です。2 つ目のオプションは、ネストを解除するビューを書き、次に(ネスト解除せずに)集計を行う、より簡単な SQL クエリを書くことです。最後は、BigQuery に格納できるよう Pub/Sub レコードを「フラット」形式にネスト解除する Dataflow ジョブを開発して実行し、簡単な SQL クエリで集計するオプションです。
長期的には 3 つ目のオプションが優れた設計のように思えましたが、時間的制約があったため 2 つ目のオプションのほうが魅力的でした。BigQuery ビューは簡単にセットアップでき、フラット化されたスキーマにクエリを実行する際のチームの生産性は迅速に向上しました。DATE パーティション フィルタのおかげで、SQL ビューの定義は、見積もりが保存されている基盤となるテーブルから最新の日付のみをスキャンできます。これによって、ビューに対するクエリ実行のパフォーマンスは劇的に改善します。
2 つ目の手法を使用した、この特定のグラフのデータ変換とビューの例は、図 6 と図 7 に示されています。
図 6: 元のソースレコードをフラット化するための SQL ビューの定義
図 7: OHLC バー(「ローソク足」)を生成する SQL ビューの定義
Bigtable と BigQuery はどちらもサーバーレスなので、各ストレージ ソリューションのメンテナンスは最低限で済みます。そのため、ストレージ アレイの調達と運用の複雑性にまつわるキャパシティ プランニングに時間を費やすのではなく、データから価値を導き出して提供するために多くの時間を使えます。
市場データのマイクロサービス
Cloud Functions は、デベロッパーに 2 つの主な利点をもたらします。1 つ目の利点は、差別化要因にならない低レベルな実装の詳細を回避して、ビジネス固有のコードのほうを選べることです。2 つ目の利点は、ビジネス ロジックをデータベースの外部にカプセル化することで、柔軟なデータの使用が可能なことです。そのため Google のパイプラインでは、分離されたタスク固有のコードチャンクに Cloud Functions を使用しました。
一例としては、パイプラインの Fetch Prediction 関数があります。これは Bigtable から取引レコードを取得して、一次的な機能(平均、合計、最大など)を抽出し、機械学習モデルに入力します。これにより、bot がリアルタイムに近いアルゴリズム取引の決定を行うのに使用する、素早い予測が可能になります。
図 8 で、この処理について説明しています。
図 8: ランタイムのフェッチを予測する Python のルーチン
Fetch Candles は Cloud Functions の関数で、毎分ごとに観測された始値、終値、高値、安値を詳述する BigQuery から最新の値段のサマリーをフェッチします。リクエスト / レスポンスのパフォーマンスを改善するため、サーバーレス ネットワーク エンドポイント グループを使ってアプリの HTTP(S) 負荷分散を有効にし、次に Cloud CDN でデリバリーを最適化しました。このように構成することで、Fetch Candles は BigQuery に対して、特定の 1 分間と商品コードの最初のリクエストのみをクエリするようになります。後続のリクエストは、1 分間の最大キャッシュ TTL に達するまで、Cloud CDN のキャッシュから配信され続けます。これにより、ウェブ クライアントのトラフィックがスケールアップするため、クエリ実行の全体量が大幅に低減されます。データはルックバック ウィンドウにあるので、機能面で BigQuery に必要とされるのは、個々の期間あたり 1 回の集計を行う計算のみです。
マイクロサービス アーキテクチャを有効にすることで、デベロッパーは Cloud Functions を使用して好みの言語で開発を行い、分離された各関数を開発、テスト、デバッグできるようになりました。
図 10 は、Google の市場データ パイプラインで使用される主要な関数のインベントリを示しています。
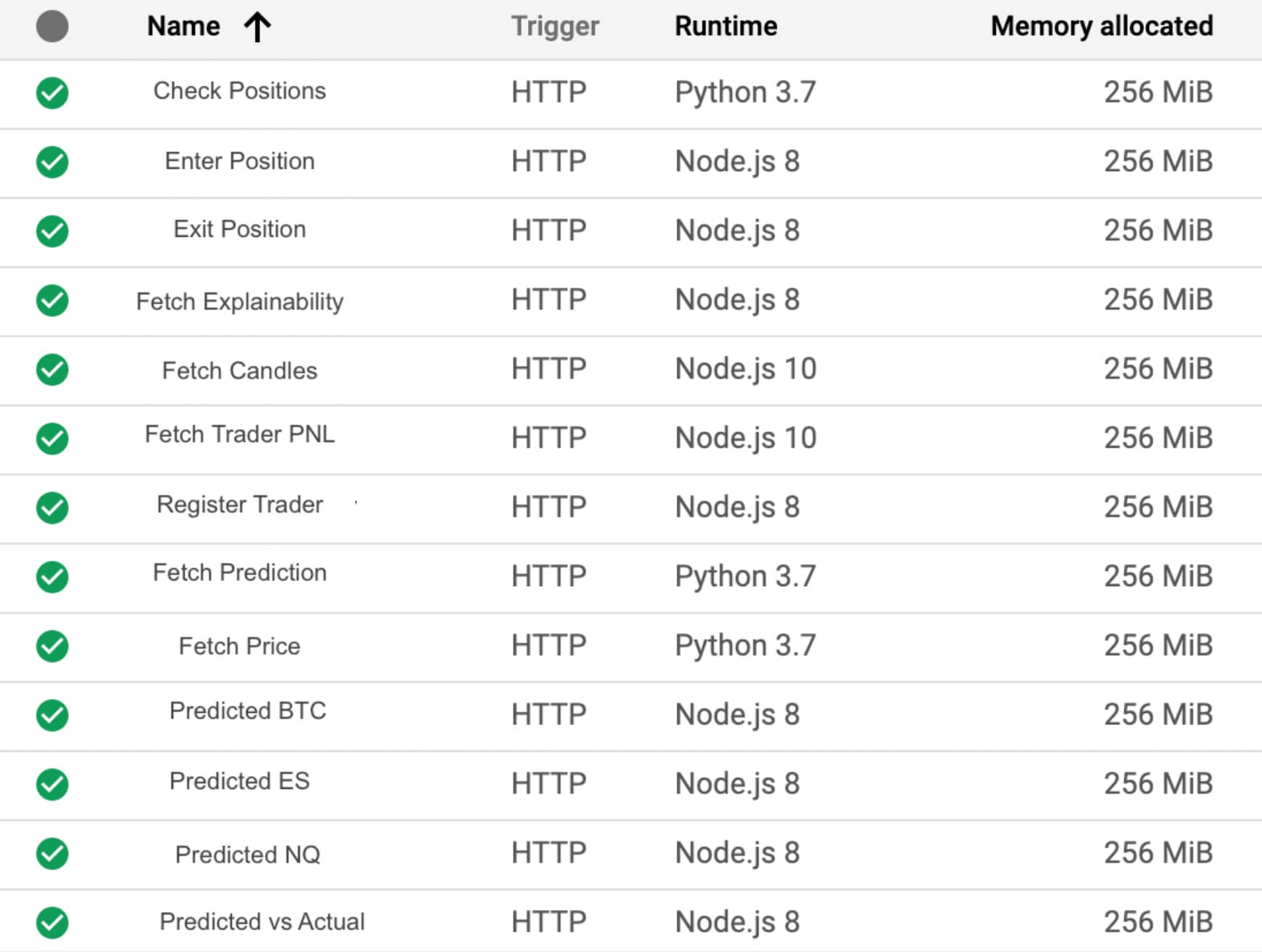
こうした関数の多くは機械学習モデルに情報を提供します。その他の関数は BigQuery からデータをフェッチして、リアルタイムの損益勘定書のトレーダー パフォーマンスを可視化します。
まとめ
サーバーレス コンポーネントから構築されたデータ パイプラインを活用すれば、資本市場企業はインフラストラクチャ管理に煩わされることなく、有益な分析とサービスの開発に集中できます。サーバーレス環境において、エンドユーザーのデータ アクセス パターンは、データ パイプラインのアーキテクチャとスキーマ設計に強い影響を与えます。マイクロサービス アーキテクチャと併用すれば、コードの複雑性を最小限に抑え、結合を減少させることが可能です。運用にデータソースと情報ツールを継続的に追加する企業は、サーバーレス コンピューティング モデルを使用することで、より的確な意思決定を行うためにデータを利用して付加価値のあるタスクに集中できるようになります。
詳しくは金融サービス向けの Google Cloud をご覧ください。
- Google Cloud カスタマー エンジニア Rachel Levy
- Google Cloud カスタマー エンジニア Bhupinder Sindhwani




{kind=link}
{kind=link}
{kind=link}
{kind=link}