Vertex AI で ML トレーニング ワークフローを合理化
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
多くの方が機械学習(ML)にローカル コンピューティング環境を使用したことがあるかと思います。GPU 搭載のノートブックやデスクトップ コンピュータを使用したことがある方も多いのではないでしょうか。問題によっては、ローカル環境で十分な場合もあります。また、ローカル環境には柔軟性が高いというメリットもあります。Python と JupyterLab をインストールするだけで開始できます。
しかし、その次に直面するのは、モデル トレーニングに非常に時間がかかりすぎるという状況です。新たなレイヤを追加し、一部のパラメータを変更し、精度が向上したか確認するのに 9 時間も待てるでしょうか。答えはノーです。クラウド コンピューティング環境に移行することで、さまざまな強力なマシンタイプを利用できるようになります。クラウドでは、同じコードでも桁外れの速さで命令を実行することができるでしょう。
Deep Learning VM images(DLVM)を使用すれば、追加設定を行わずに ML フレームワーク、ドライバ、アクセラレータ、ハードウェアのすべてをスムーズに連携させることが可能です。また、ノートブック インスタンスも利用できます。このインスタンスは DLVM に基づいており、JupyterLab にも容易にアクセスできます。
Vertex AI カスタム トレーニング サービスを利用するメリット
クラウドで VM を使用すると、ML チームの生産性が大幅に向上します。さらには、Vertex AI の新しいカスタム トレーニング サービスを活用することもできるようになります。このサービスでは、ノートブック インスタンスでモデルを直接トレーニングするのではなく、ノートブックからトレーニング ジョブを送信できます。
トレーニング ジョブは自動的にコンピューティング リソースをプロビジョニングし、ジョブが完了するとプロビジョニングを解除します。高性能の仮想マシン構成が実行されたままになってしまう心配もありません。
トレーニング サービスはアーキテクチャのモジュール化をサポートします。本記事で後ほど詳しくご説明しますが、トレーニング コードをコンテナに格納してポータブル ユニットとして動作させることができます。トレーニング コードは入力データの場所やハイパーパラメータなどのパラメータをコンテナに渡すことができるため、再デプロイせずにさまざまなシナリオに対応できます。また、トレーニング コードはトレーニング済みモデルのファイルをエクスポートできるため、一部を切り離して他の AI サービスと連携できます。
このトレーニング サービスは再現性もサポートします。それぞれのトレーニング ジョブはトラッキングされ、入出力、使用されたコンテナ イメージが記録されます。ログメッセージは Cloud Logging で確認でき、実行中のジョブをモニタリングすることもできます。
また、トレーニング サービスは分散トレーニングもサポートしているため、複数のノード間でモデルを並行してトレーニングできます。これにより、単一の VM インスタンスで実行するよりもトレーニング時間を短縮できます。
サンプル ノートブック
このブログ投稿では、Vertex AI のサンプル コード スニペットを例にして、カスタム トレーニング サービスを使用する方法について説明します。これから使用するノートブックでは、カスタム トレーニングとオンライン予測のエンドツーエンド処理を取り上げます。使用するノートブックは ai-platform-samples リポジトリの一部であり、Vertex AI の使用方法に関して多数の有用なサンプルが含まれています。

カスタムモデル トレーニングの概要
カスタムモデルのトレーニング サービスは、TensorFlow, PyTorch、scikit-learn、XGBoost などの一般的なフレームワークをサポートするビルド済みのコンテナ イメージを提供します。このコンテナを使用することで、トレーニング コードと適切なコンテナ イメージをトレーニング ジョブに提供できます。
また、カスタム コンテナ イメージを作成することも可能です。Python 以外の言語や、ビルド済みのコンテナ イメージがサポートしていない ML フレームワークを使用している場合は、カスタム コンテナ イメージを使用することをおすすめします。このブログ投稿では、GPU をサポートするビルド済み TensorFlow 2 イメージを使用します。
Console、gcloud CLI、REST API、Node.js / Python SDK など、カスタム トレーニング ジョブを管理する方法は複数あります。ジョブを作成した後、現在のステータスをクエリすると、ログがストリーミングされます。
トレーニング サービスはハイパーパラメータの調整もサポートしているため、モデルのトレーニングに最適なパラメータを見つけることができます。ハイパーパラメータ調整ジョブは、トレーニング イメージがジョブ インターフェースに提供される点で、カスタム トレーニングと似ています。トレーニング サービスは複数のトライアル、またはさまざまハイパーパラメータ セットのトレーニング ジョブを実行して、最適なモデルを洗い出します。このようなテストを行うには、テストするハイパーパラメータの範囲、トレーニング回数の詳細など、ハイパーパラメータを指定する必要があります。
カスタム トレーニングとハイパーパラメータ調整ジョブは両方ともトレーニング パイプラインにラップされます。トレーニング パイプラインはジョブを実行するだけでなく、オプションの手順として、Vertex AI にモデルをアップロードすることもできます。
トレーニング ジョブ用にコードをパッケージ化する方法
一般的に、モデル トレーニング コードを開発する際は自己完結型のコードを作成することをおすすめしています。コンテナ内でモデルを実行する場合は、なおさらです。自己完結型とは、トレーニング コードベースの実行時に、それが独立して動作することを意味します。
以下は、コメントが多く寄せられる自己完結型の Python スクリプトのテンプレートです。ご自身のプロジェクトにご活用ください。
MODEL_DIR は Google Cloud Storage(GCS)バケット内に配置されている必要がある点に注意してください。これは、トレーニング サービスはバケットとしか通信できず、Google のローカル システムとは通信できないためです。GCS バケット内の場所のサンプルとしては、gs://caip-training/cifar10-model などが挙げられます。ここで、caip-training は GCS バケットの名前です。
前述のコードではカスタム モジュールを使用していませんが、通常の Python スクリプトと同様に簡単に組み込むことができます。詳細はこちらのドキュメントを参照してください。次に、使用する GPU の種類と数など、トレーニング インフラストラクチャの構成方法を確認し、インフラストラクチャ内で実行するトレーニング スクリプトを送信します。
使用するマシンの構成を含むトレーニング ジョブの送信方法
大規模なデータセットで効果的にディープ ラーニング モデルをトレーニングするには、高度に並列化された方法で行列乗算を実行するのに適したハードウェア アクセラレータが必要です。また、大規模なデータセットで大型モデルをトレーニングする場合、分散トレーニングが一般的です。この例として、1 基の Tesla K80 GPU を使用します。Vertex AI はさまざまな GPU をサポートしています(詳細はこちら)。
以下は Vertex AI SDK を使用してトレーニング ジョブを初期化する方法を示しています。
(aiplatform は google.cloud import aiplatform のからのものとしてエイリアスされます)
引数を詳しく見ていきましょう
display_name はトレーニング ジョブを容易に検索するための一意の識別子です。
script_path は実行するトレーニング スクリプトのパスです。この例では、前のセクションで説明したスクリプトが指定されています。
container_uri はトレーニング スクリプトの実行に使用されるコンテナの URI です。これには、複数のオプションがあります。この例では、gcr.io/cloud-aiplatform/training/tf-gpu.2-1:latest を使用します。デプロイにも同じコンテナを使用しますが、コンテナの URI は少しだけ異なります。モデル トレーニングに使用可能なコンテナはこちらです。また、デプロイに使用可能なコンテナはこちらです。
requirements では、トレーニング スクリプトの実行に必要な外部パッケージを指定できます。
model_serving_container_image_uri はデプロイ中に使用されるコンテナ URI を指定します。
注意: 目的ごとに適切に依存関係を分離できるようにするために、トレーニングやデプロイなど、個々の目的ごとに異なるコンテナを使用することをおすすめします。
これでカスタム トレーニング ジョブを送信する準備が完了しました。
各行を解説します。
model_display_name はトレーニング済みモデルを識別するための一意の名前です。これはパイプラインの後半で予測サービスを使用してデプロイする際に役立ちます。
args は、一般的にハイパーパラメータ値などを特定する場合に使用するコマンドライン引数です。
replica_count はトレーニング中に使用されるワーカーのレプリカの数を指定します。
machine_type はトレーニング中に使用されるベースマシンのタイプを指定します。
accelerator_type はトレーニング中に使用されるアクセラレータのタイプを指定します。Tesla K80 を使用する場合は、TRAIN_GPU を aip.AcceleratorType.NVIDIA_TESLA_K80 に指定しなければなりません(aip は、google.cloud.aiplatform import gapic as aip のからのものとしてエイリアスされます)
accelerator_count は使用するアクセラレータの数を指定します。単一ホストのマルチ GPU 構成では、replica_count を 1 に設定し、accelerator_count を対応するコンピューティング ゾーンで利用可能なリソースに応じた選択に基づいて指定します。
ここでのモデルは、google.cloud.aiplatform.models.Model オブジェクトを指します。このオブジェクトは、ジョブの完了後にトレーニング サービスによって返されます。
この設定により、モニタリング可能なカスタム トレーニング ジョブを実際に開始できるようになります。前述のトレーニング パイプラインを送信すると、以下のような初期ログが表示されます。

図 2 でハイライトされているリンクは、次のようなトレーニング パイプラインのダッシュボードにリダイレクトされます。
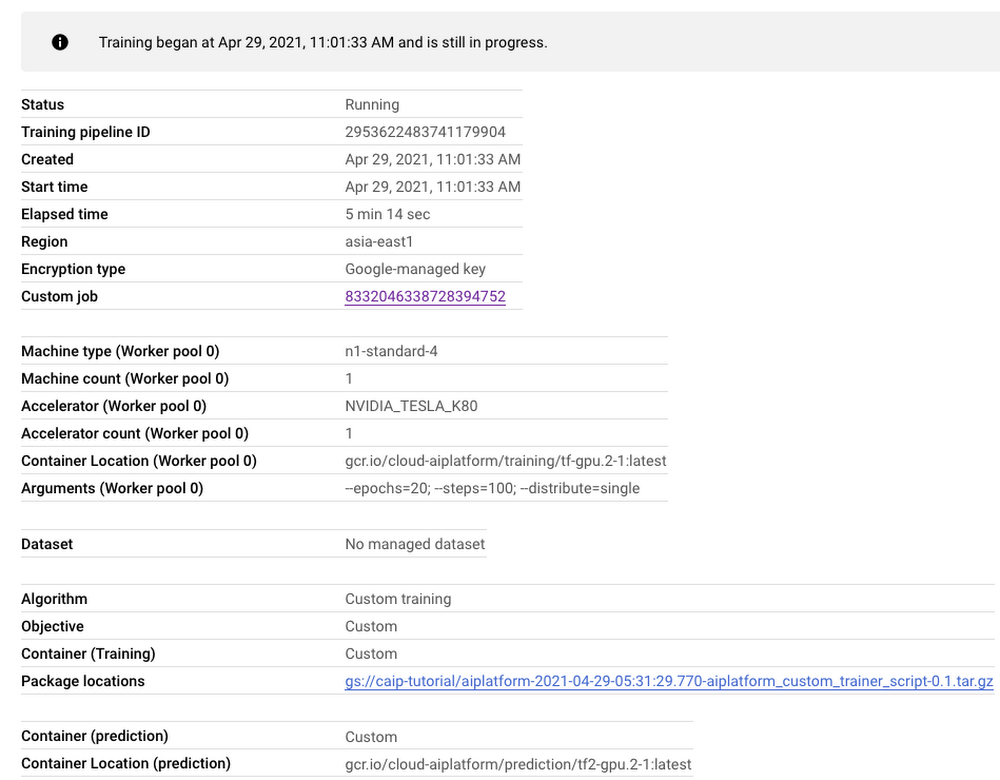
図 3 に示すとおり、ダッシュボードはトレーニング パイプラインに関連する必要なすべてのアーティファクトに関して包括的な概要を示します。また、モデル トレーニングのモニタリングは、特に初期のトレーニング バグを見つけるために重要です。トレーニング ログを表示するには、[カスタムジョブ] タブの横のリンクをクリックします(図 3 を参照)。図 3 で示した情報と似たものが表示されますが、今回はログも含まれています。
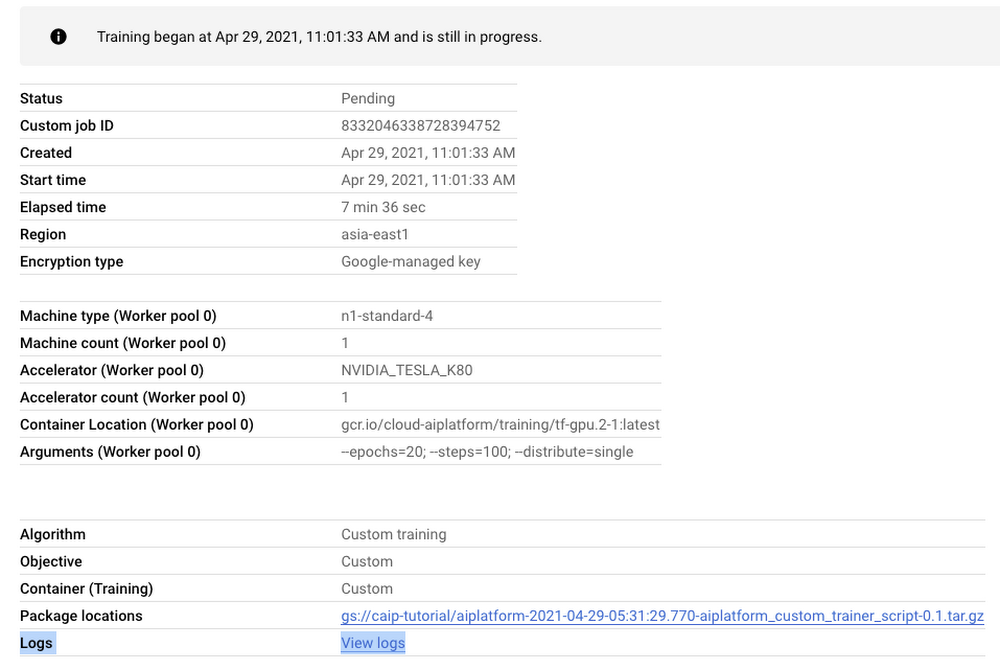
注意: カスタム トレーニング ジョブを送信すると、トレーニングをプロビジョニングするために、まずトレーニング パイプラインが作成されます。その後、作成されたパイプライン内で実際のトレーニング ジョブが開始されます。このため、2 つのダッシュボードは非常に似ていますが、目的が異なります。
それではログを確認してみましょう(ログは Cloud Logging で自動的に管理されています)。
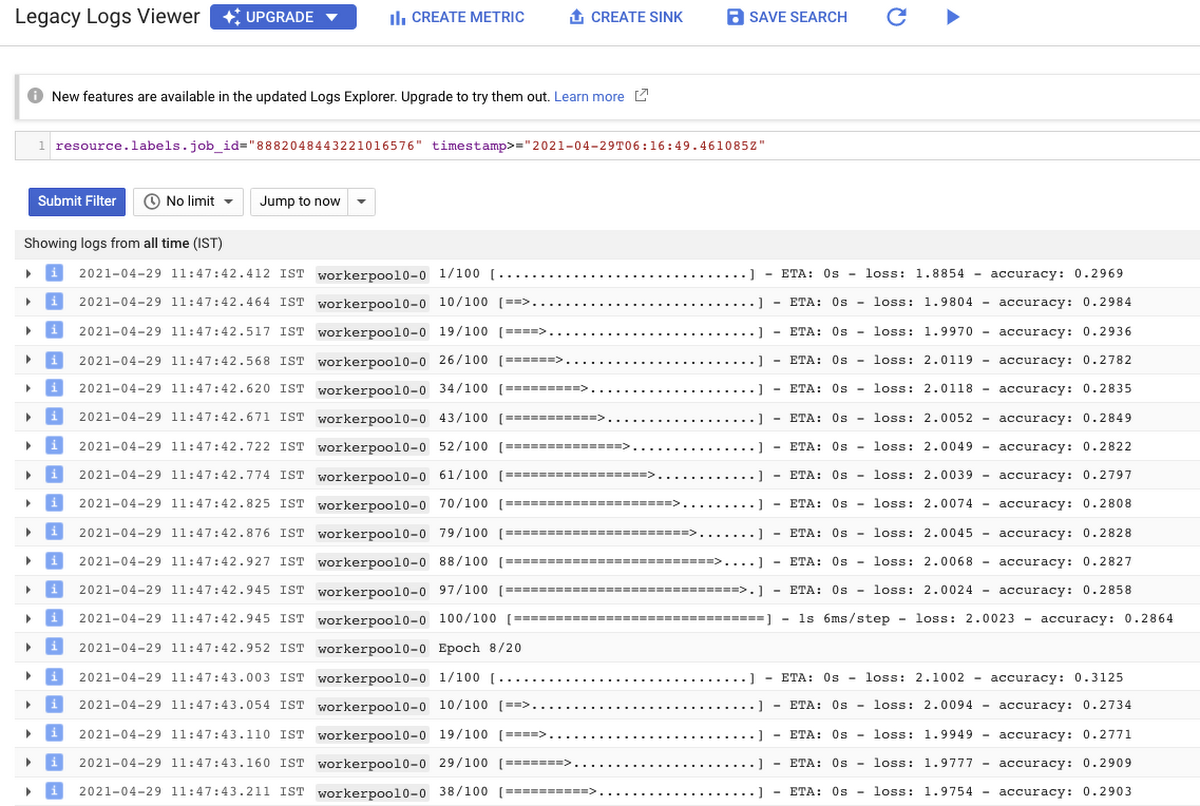
また、Cloud Logging では、さまざまな条件に基づいてアラートを設定できます。たとえば、トレーニング ジョブが失敗または完了した際にユーザーにアラートを出し、すぐに対処できるようにします。詳細はこちらの記事をご覧ください。
トレーニング パイプラインが完了すると、ユーザーに成功ステータスが示されます。

トレーニング済みモデルへのアクセス
トレーニング サービスとの互換性をモデルに持たせるために GCS バケット内でモデルをシリアル化していたかと思います。よって、モデルがトレーニングされた後は、GCS バケットからモデルにアクセスできます。次のコードを使用して直接読み込むこともできます。
トレーニングで生成された TensorFlow モデルを参照していることに注意してください。トレーニング サービスでは、類似する「モデル」名前空間も維持され、この名前空間はモデルの管理に役立ちます。トレーニング サービスが前述の google.cloud.aiplatform.models.Model オブジェクトを返すということを思い出してください。このオブジェクトには deploy() メソッドがあり、このメソッドを利用することで、さまざまオプションを指定して、プログラムによって数分でモデルをデプロイできます。このオプションを使用したモデルのデプロイについての詳細は、こちらのリンクをご確認ください。
また、Vertex AI では、トレーニングに成功したすべてのモデルに対してダッシュボードが提供されます。ダッシュボードはこちらからアクセスできます。ダッシュボードは以下のように表示されます。
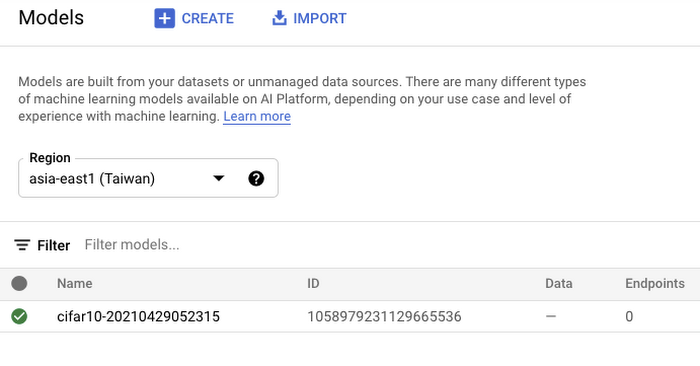
図 7 で示されているモデルをクリックすると、インターフェースから直接デプロイできます。
この記事では、デプロイについては説明しませんが、実際にお試しいただくことをおすすめします。モデルがエンドポイントにデプロイされたら、そのモデルを使用してオンライン予測を作成できます。
まとめ
このブログ記事では、再現性の向上やテスト管理など、Vertex AI カスタム トレーニング サービスを使用するメリットについてご説明しました。また、Jupyter Notebook のコードベースをコンテナ化された標準的なコードベースに変換する手順についても説明しました。この手順は、トレーニング サービスだけでなく他のコンテナベースの環境にも役立ちます。サンプル ノートブックは各手順を理解し、ご自身のプロジェクトのテンプレートとして使用するための出発点として役立ちます。
-デベロッパー アドボカシー担当マネージャー Karl Weinmeister
-機械学習 GDE Sayak Paul