AI で強化されたチャットによるスケーラブルなテクニカル サポート
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
パンデミック中に Google 社員は在宅勤務に移行したことから、技術的問題の解決について支援を受ける際にチャットベースのサポートを利用するケースがますます増えています。Google の IT サポートチームは、テクニカル サポートの需要の増大にすばやく効率的に応えられるように、多くのオプションを検討しました。
スタッフの増員?パンデミック中は簡単ではありません。
サービスレベルを低下させる?とんでもありません。
アウトソーシング?Google の IT 要件では不可能です。
自動化?もしかしたら可能かもしれませんが...
AI を活用してサポート業務をスケールアップし、サポートチームの効率を高めるにはどうすればいいでしょうか。
その答えはスマート リプライです。これは、Google Research チームが機械学習、自然言語理解、会話モデリングの専門知識を駆使して開発した技術です。このプロダクトのおかげで、Google が所有するチャットデータのコーパスを使用して Google 社員からの問い合わせに回答するエージェントの能力向上を図ることができました。スマート リプライは、エージェントにリアルタイムで応答の候補を提示するモデルをトレーニングします。これにより、エージェントが複数の人と並行してチャットしているときの認知負荷が軽減され、問題の解決に向けてセッションを進めることができます。
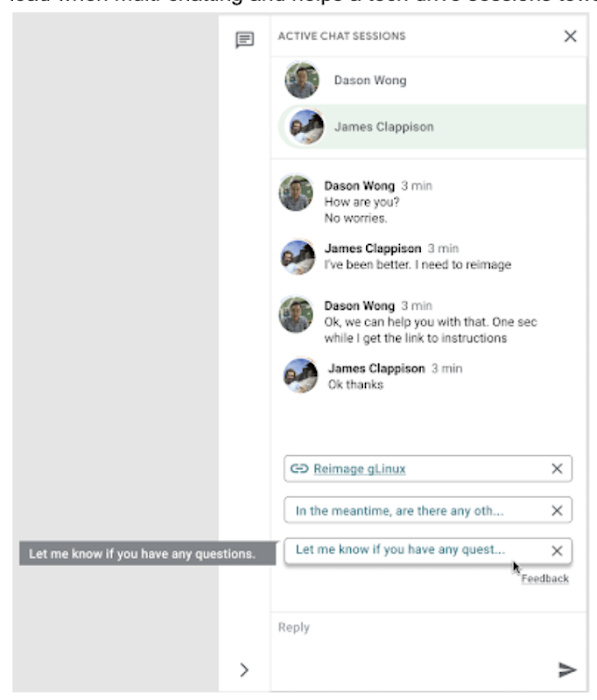
以下に説明するソリューションを通じて、似た状況にある IT チームが、同じような時間節約ソリューションを実装するうえで、そのベスト プラクティスや近道を見つけることができればと思っています。それでは始めましょう。
データの準備における課題
Techstop と呼ばれる Google 社員向けのテクニカル サポート サービスは、チャット、メール、その他のチャネルを通じて幅広いプロダクトや技術スタックのサポートを提供する複雑なサービスです。
Techstop が保持しているデータは膨大です。Techstop に寄せられるヘルプ リクエストの数は 1 年に数十万件に達します。Google はこれまでのすべての社内サポートデータを単一のデータベースに保存しており、その保存形式はプロトコル バッファではなくテキスト形式です。これはモデル トレーニングにあまり適していません。ユーザーのプライバシーを守るため、PII(個人を特定できる情報 - ユーザー名、実名、住所、電話番号など)がモデルに取り込まれないようにする必要があります。
このような課題に対処するため、テキストを受け取ってエージェントおよびサポート依頼者から送信された各メッセージを個々の行に分割し、繰り返しフィールドとしてプロトコル バッファに保存する FlumeJava パイプラインを構築しました。このタスクの実行中にテキストを Google Cloud DLP API にも送信し、セッション テキストから個人情報を除去してリダクション(秘匿化)でこの情報を置き換えます。後からフロントエンドで使用する際にはこの秘匿化された情報が使用されます。
データを正しい形式で準備できたら、モデル トレーニングを開始できます。このモデルは、会話の全体的なコンテキストに基づいて、次のメッセージ候補をエージェントに提示します。モデルをトレーニングするにあたって、トークン化、エンコード、対話属性を実装しました。
テキストの分割
エージェントとサポート依頼者の間でやり取りされたメッセージは、使いやすいようにトークン化(異なるチャンクに分割)されます。テキストのトークンへのこのような分割は、次のような理由から慎重に検討する必要があります。
トークン化により、そのテキストをカバーするために必要な語彙のサイズが決まります。
テキストの意味を抽出するため、トークンの分割は論理的な境界に沿って行う必要があります。
各トークンのサイズの間でトレードオフが生じる可能性があります。トークンが小さいほど処理要件は増加しますが、異なるテキスト範囲同士の関連付けは容易になります。
テキストをトークン化する方法には、SAFT や空白文字での分割などいろいろありますが、今回はセンテンス ピース トークン化を選択しました。この方法では、各トークンは 1 つのワード セグメントを意味します。
エンコーダによる予測
トークン化された値を使用したニューラル ネットワークのトレーニングでは、イテレーションを数回繰り返しました。チームが採用したエンコーダ / デコーダ アーキテクチャは、特定のベクトルとトークンを受け取り、softmax 関数を使用してそのトークンが文/会話中の次のトークンである確率を予測するというものでした。下の図は、LSTM ベースの回帰ネットワークを使用してこの方法を表したものです。この種のエンコードの力は、エンコーダが次のトークンだけでなく次の一連のトークンをどれだけ効果的に予測できるかによります。
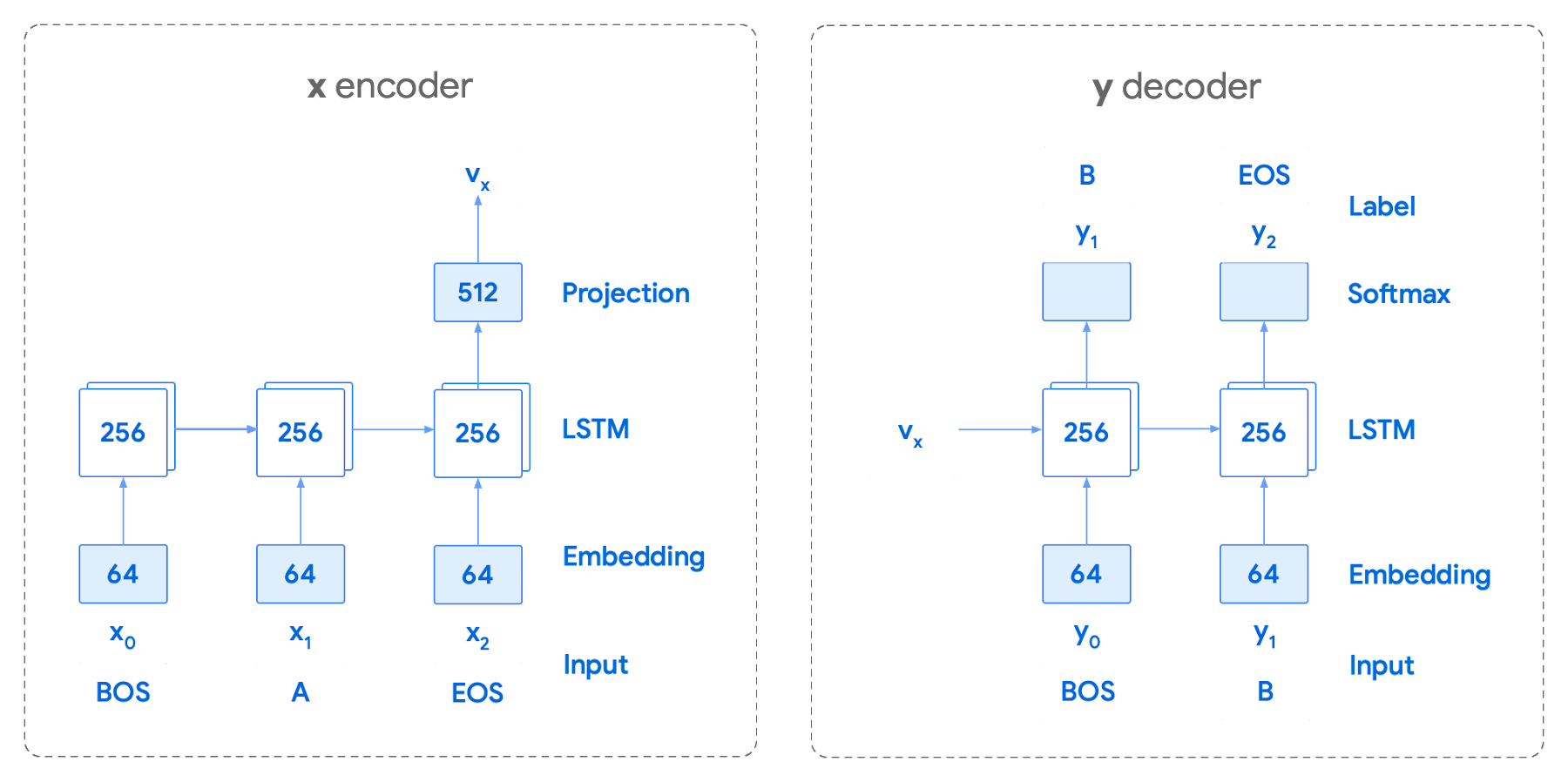
これはスマート リプライにとって非常に有用であることが証明されています。最適なシーケンスを見つけるには、後に続く可能性のあるトークンの各ツリーに対する指数探索を行う必要があります。そのため、全体的なメモリ使用量の増加を防ぎ、候補リストを返すためのランタイムを短縮することを狙いとして、固定サイズの最良候補リストに対するビーム探索を使用することにしました。これを実現するため、トークンをトライ構造に整理し、いくつかの後処理手法と特定の候補に対するヒューリスティックな最大スコアの計算を使用して、トークンリスト全体の反復処理にかかる時間の短縮を図りました。これによってランタイムは改善されますが、モデルから提示されるシーケンスはやや短くなる傾向があります。
次に、レイテンシを短くしてコントロールを改善するため、エンコーダ / エンコーダ アーキテクチャに移行することを決めました。これまでは、次の単一のトークンを予測し、モデルを複数回呼び出して以降の一連の予測をデコードしていましたが、新しいアーキテクチャでは候補シーケンスをニューラル ネットワークでエンコードします。
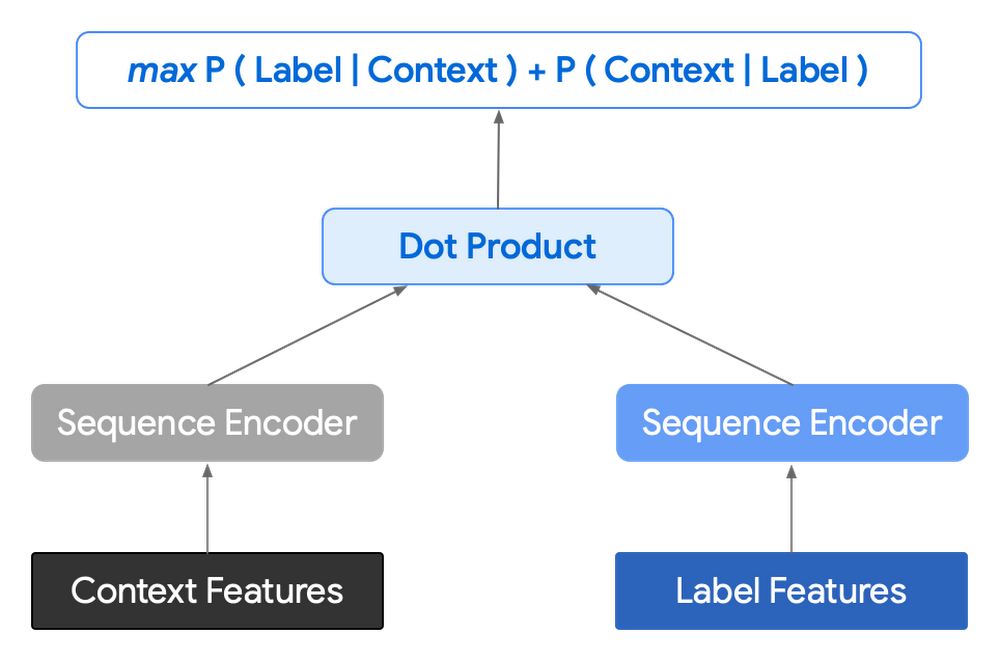
実際には、コンテキスト エンコードと単一の候補出力のエンコードの 2 つのベクトルをドット積で結合して、特定の候補のスコアを導き出します。このネットワークの目標は、正の候補(たとえば、トレーニング セットに実際に登場した候補)のスコアを最大化し、誤の候補のスコアを最小化することにあります。
陰性のメッセージをどのようにしてサンプリングするかは、モデル トレーニングに大きな影響を及ぼします。以下に、使用可能ないくつかの戦略を示します。
同じバッチ内の他のトレーニング例から取得した陽性ラベルを使用する。
一般的なメッセージのセットからランダムに抽出する。これは、各メッセージの経験的確率が正しくサンプリングされていることが前提となります。
コンテキストからのメッセージを使用する。
別のモデルから陰性メッセージを生成する。
このエンコードにより候補の固定リストが生成され、事前に計算して保存しておくことができるため、予測が必要となるたびにコンテキスト エンコードのみを計算し、それを候補エンベディングの行列と乗算するだけで済みます。これにより、ビーム探索法の時間が短縮され、応答が短くなる固有バイアスも軽減されます。
対話属性
会話というのは、単純なテキスト モデリングにとどまりません。当事者間の会話の全体的な流れから重要な情報が提供され、各メッセージの属性がそれに応じて変わります。誰がいつ誰に対して何を言ったかといったコンテキストは、モデルが予測を行う際の有益な情報源となります。そのため、モデルでの予測中に以下の属性を使用しました。
ローカル ユーザー ID - 特定の会話の当事者用に有限の番号を用意し、当事者に値を割り当てることでメッセージを受け取る番を表せるようにしました。ほとんどのサポート セッションでは当事者は 2 人であり、ID 0 と 1 が必要となります。
返答か継続か - 当初、モデリングは返答のみに焦点を合わせていました。しかし、実際の会話には、当事者同士が以前に送信されたメッセージについて引き続きやり取りする場合も含まれます。これを考慮して、同じユーザーに対する候補と「別の」ユーザーに対する候補の両方についてモデルをトレーニングしました。
タイムスタンプ - 会話中の時間的隔たりはいろいろなことを示す可能性があります。サポートの見地から見ると、時間的隔たりはユーザーが連絡を断ったことを示す場合があります。モデルはタイムスタンプからメッセージ間の経過時間に注目し、その値に基づいて異なる予測を提供します。
後処理
より望ましい最終ランキングを得るために、候補をさらに操作できます。そのような後処理には、次のものが挙げられます。
より長い候補の優先順位を上げるため、現在の候補に含まれるトークンの数を乗算して生成されたトークン係数を追加する。
以前に送信されたメッセージと重複する部分が多い候補のランクを下げる。
エンベディング距離の類似性に基づいてより多様性の高い候補のランクを上げる。
最適な応答に目を向けてそれらを調整できるようにするため、チームが優先順位リストを作成しました。これにより、モデルの出力に影響を与えることが可能になり、不適切な応答の優先順位を下げることができます。抽象的に言うと、これはサポート依頼者のニーズに最も適したものに候補を絞り込むフィルタと考えることができます。
エージェントに応答候補を提示する
モデルが完成したら、次にこれをエージェントの手に渡す必要がありました。このソリューションはチャット プラットフォームにできるだけ依存しないようにしたいと考えました。そうすれば、ツールの変更に直面したときにも俊敏に対応でき、他の効率化機能も迅速にデプロイできます。この目的を達成するため、gRPC または HTTPS を介してクエリを実行できる API が必要となりました。そこで、使用状況をログに記録し、フロントエンドとして使用する Chrome 拡張機能とモデルとの橋渡しをする Google Cloud API を設計しました。
隠れたステップ、測定
これでモデル、インフラストラクチャ、拡張機能の準備は整いましたが、まだ IT プロジェクトにとって大きな問題が残っていました。それは「どのような効果が得られたか」ということです。Google の IT 部門で働くことの素晴らしい点の一つは、決して退屈しないことです。計画されたもの、予期しないものを含め、そこには絶えず変化があります。しかし、そうした状況では、このようなデプロイメントの成果を測定するのは実に困難です。サポートチームのサービスは改善されたのでしょうか、それとも単に問い合わせが少なかっただけなのでしょうか?
満足のいく結果を得ることができたのかどうかを確認するため、新しい拡張機能を使用するエージェントと使用しないエージェントの間で A/B テストを実施しました。テスト対象グループはグローバル チームの中から地域が偏らないよう配慮しながらランダムに選び、実務期間が 3 か月から 26 か月までの熟練度の異なるエージェントを混在させました。
第一の目標は、ツールを使用したときのエージェントのサポート効率を測定することでした。エージェントの効率を表す主要な代理指標として、次の 2 つに注目しました。
チャットの全体的な長さ。
エージェントが送信したメッセージの数。
テストの評価
得られたデータを評価するため、2 標本の並べ替え検定を使用しました。この際、帰無仮説は、「拡張機能を使用したエージェントのほうが使用しなかったエージェントよりも解決までの所要時間が短くなるわけではない、または送信できるメッセージの数が多くなるわけではない」とし、対立仮説は、「拡張機能を使用したエージェントのほうがより短時間でセッションを解決できる、またはほぼ同じ時間の間により多くのメッセージを送信できる」としました。
中間に位置するデータのみを使用することとし、3 標準偏差を超える外れ値を除外しました。チャットの長さは正規分布ではなく、比較的長い時間がかかった問題のロングテールが原因で大きく右に偏っていたため、今回のケースにとって意義のある中心極限定理(CLT)に基づいて平均値の差を測定しました。p 値が 1.0~9.0 の結果は棄却しました。
プール全体で、チャットの長さは 36 秒短縮されていました。
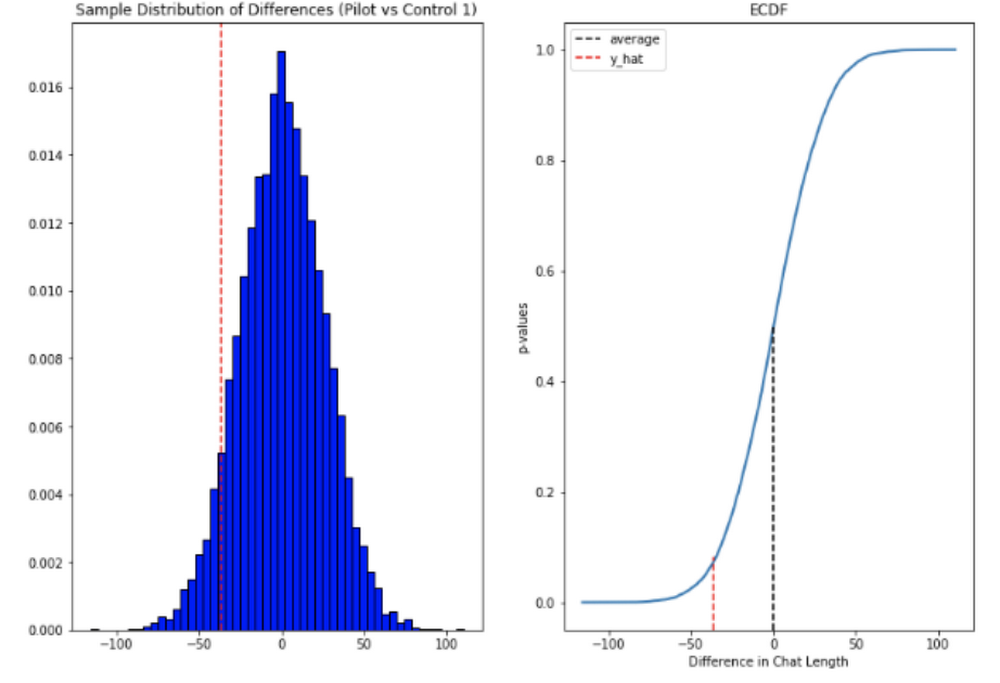
チャット メッセージの数に関しては、エージェントはより短い時間で平均 5~6 件多くのメッセージを送信していました。
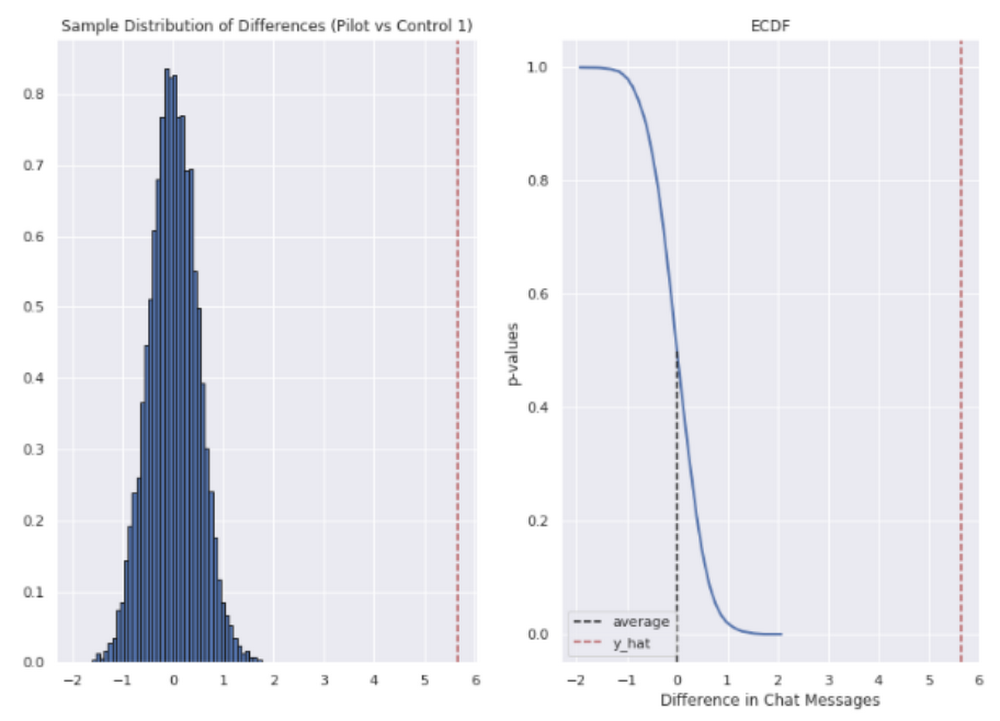
つまり、エージェントがより短い時間内により多くのメッセージを送信できたことが確認できました。さらに、これらの改善はサポート エージェントの在職期間が長いほど向上し、上級エージェントはサポート対応あたり平均約 4 分の時間を節約できたこともわかりました。
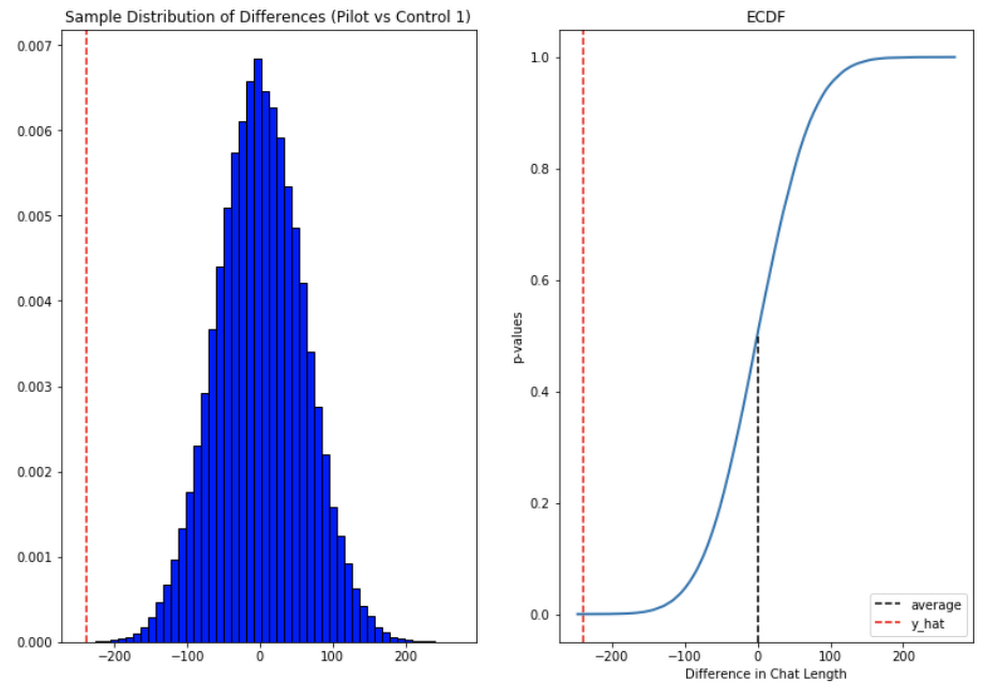
この結果はおおむね満足のいくものでした。完璧とは言えませんが、良い方向に前進していると実感できました。
次のステップ
他の ML プロジェクトと同様に、データの質が向上するにつれて結果も向上します。今後は、許可リストからの結果をクラスタ化することで標準的な応答候補をサポート エージェントに提供する方法を検討する予定です。また、モデルによって提供されたサポート記事を改良する方法も調べたいと考えています。特に経験の浅いエージェントが必要な情報を見つけやすくなるようなものがあれば、大きな利益となります。
これを実現するにはどうすればよいか
うまく応用された AI プロジェクトは常にデータから始まります。まず入手可能な情報を収集し、それを分割してから、情報の処理を開始します。得られる応答候補の質は供給するやり取りデータによって決まるため、強化したいパターンに即したデータを選択してください。
Google の Contact Center AI を使用すると、独自のモデルを設計またはトレーニングしなくても、あるいは独自の効果測定方法を構築しなくても、トークン化、エンコード、レポートの作成を行うことができます。データを適切な形式で準備すれば、あとはすべてのトレーニングが自動的に処理されます。
それでも、得られた応答候補をサポート システムのフロントエンドに統合する最適な方法を決める必要はあります。また、応答候補を提示することでサポート エクスペリエンスが向上しているかどうかを確かめるために統計モデルを導入することもおすすめします。
今回、チャットのやり取りにおいて既成の応答をエージェントに提供することにより、サポートチームの時間は節約されました。皆さんがサポートチームをスケーリングする際に、ここに挙げた方法がお役に立てば幸いです。
-シニア コーポレート オペレーション エンジニア James Clappison
-Google Cloud シニア デベロッパー リレーション エンジニア Max Saltonstall




