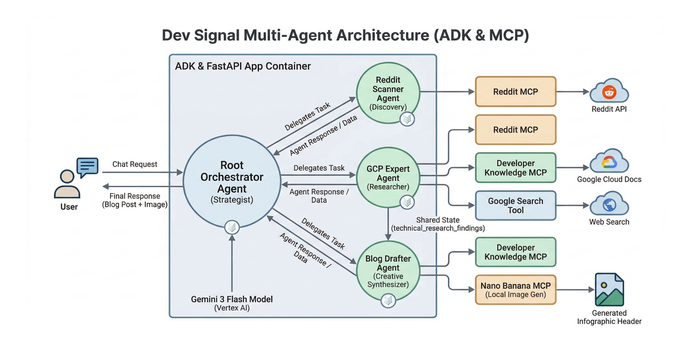
HarbourBridge とデータ検証ツールを使用した Cloud Spanner への移行
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
最近、MySQL や PostgreSQL などの既存のオープンソース リレーショナル データベースから Google Cloud Spanner に移行して水平方向のスケーリングを有効化することに多くの関心が寄せられています。このタイプの異種データベース間移行は複雑なものになる場合がありますが、HarbourBridge とデータ検証ツールの 2 つのオープンソース ツールが役に立ちます。HarbourBridge は、MySQL や PostgreSQL からスキーマとデータを取り込み、それを Spanner に移行するスタンドアロン ツールです。Spanner でサポートされているデータ型や機能をマッピングし、サポートされていないものは無視します。データ検証ツールは、その名の通りの働きをします。ソースとターゲットのデータベースに接続する Python CLI ツールであり、マルチレベルの検証やカスタムクエリによって 2 つのテーブルのデータが一致することを確認します。今回はプロセスの簡単な概要をご紹介します。近日中にすべてのプロセスを網羅したチュートリアルを公開する予定ですので、そちらもご覧ください。
HarbourBridge
HarbourBridge をインストールするには、Google Cloud SDK、Go、GCC が必要です。
ツールをダウンロードしてインストールします。
HarborBridge は、ダンプファイルに対して実行することも、データベースに直接接続することもできます。ダンプファイルを使用する場合、標準的な平文の pg_dump または mysqldump 形式ファイルである必要があります。ソースに直接接続されている場合、HarbourBridge はデータベースにクエリを発行してテーブル・スキーマとデータを取得します。
mydb という名前の PostgreSQL データベース ダンプに対してツールを使用するには、次を実行します。
mydb という名前の MySQL データベース ダンプに対してツールを使用するには、オプションを -driver=mysqldump に置き換えます。
PostgreSQL データベース上で直接ツールを使用するには、-driver=postgres を設定し、環境変数 PGHOST、PGPORT、PGUSER、PGDATABASE を指定します。
MySQL データベース上で直接ツールを使用するには、-driver=mysql を設定し、環境変数 MYSQLHOST、MYSQLPORT、MYSQLUSER、MYSQLDATABASE を指定します。
このツールは、環境変数 GCLOUD_PROJECT の Cloud プロジェクトを使用し、変換されたスキーマで Spanner インスタンスに新しいデータベースを作成し、データを読み込みます。また、スキーマ ファイル、セッション ファイル、レポート ファイル、ドロップ ファイルといった複数の出力レポート ファイルを作成します。これらのファイルには、ツールで実行された内容や、データやスキーマで発生したエラーに関する詳細な情報が含まれています。
HarbourBridge は、継続的なデータ移行や CDC を必要としない、約 100GB までの中規模なデータベースの移行に最適です。Spanner や大規模なデータベースへの継続的なデータ移行には、サードパーティ パートナーのプロダクト、Striim をおすすめします。Striim は CDC のストリーミングだけでなく、大量一括初期読み込みも実行できます。
データ検証ツール
データ検証ツール(DVT)をインストールするには、Google Cloud SDK、git、python3、python3-dev、pip、gcc、そしてオプションとして terraform が必要です。DVT は、デフォルトでは結果を標準出力に出力しますが、BigQuery に書き込むこともできます。レポート ハンドラとして BigQuery を活用し、出力の保存や確認を行うことをおすすめします。
リポジトリをローカルマシンにクローンし、terraform フォルダにアクセスします。フォルダの中には、編集して BigQuery のデータセットや出力用のテーブルを作成するために使用する terraform ファイルがあります。また、Google Cloud SDK の bq コマンドライン ツールで result_schema.json ファイルを使用してテーブルを作成することもできます。
これで DVT を pip でインストールできるようになりました。
DVT を実行するには、まずソースとなる MySQL への接続を作成する必要があります(他のデータベースもサポートされています)。
次に、対象の Cloud Spanner の接続を作成します。
その後、検証を実行するには、検証タイプ、ソース接続、ターゲット接続、比較するテーブルのリスト、BigQuery 出力テーブルを指定します。
BigQuery での出力は次のようになります。

デフォルトでは、列の型の検証には指定されたテーブルに対して簡単な COUNT(*) を実行します。場合によっては、代わりに各列の集計を実行する方が適切な場合もあります。--count columnName、--sum myFirstColumnName、--avg anotherColumnName を追加したり組み合わせたりすることで、異なるチェックを簡単に作成できます。他にも、DVT をより柔軟に使用するための集計、フィルタ句、さらにはカスタム SQL が用意されています。それぞれのタイプについての詳しい情報は、GitHub で DVT のページをご覧ください。
-c validate.yaml 引数を追加すると、DVT は指定された構成を保存した yaml ファイルを代わりに出力します。これは簡単に編集できる形式になっており、将来の参照と再現性のために保存できます。
保存した構成は、次のように簡単に実行できます。
詳細情報
MySQL から HarbourBridge 経由で Cloud Spanner へ
HarbourBridge のスキーマ アシスタントによる Cloud Spanner 移行の高速化
Striim を使用して Cloud Spanner に継続的なデータ レプリケーションを行う
HarbourBridge とデータ検証ツールは積極的に開発が続けられています。ぜひお試しいただき、フィードバックや問題の報告、修正や機能を強化するための PR の送付などのご協力をお願いいたします。これらのオープンソース ツールは、ユーザー コミュニティの一部であり、Google Cloud が公式にサポートするものではありません。
-データベース移行エンジニア Shashank Agarwal
-クラウド データベース移行エンジニア David Ng