分散 AI エージェントの構築

Amit Maraj
AI Developer Relations Engineer
※この投稿は米国時間 2026 年 3 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
率直に言って、1 回だけ動作する AI エージェントを構築するのは簡単です。しかし、本番環境で確実に動作する AI エージェントを構築し、既存の React や Node.js アプリケーションと統合する場合は、まったく別の話です。
(説明は省略して、コードに直接移動したい場合は、GitHub のコース作成エージェントのアーキテクチャをご覧ください。)
身近な例で考えてみましょう。トピックを調査し、コンテンツを生成して、それを評価するという複雑なワークフローがあるとします。このワークフローを、1 つの巨大な Python スクリプトまたは大きなプロンプトに詰め込んだとしましょう。ローカルマシンでは正常に動作しましたが、スマートな外観のフロントエンドに接続しようとすると、厄介なことになります。レイテンシが急上昇し、デバッグが困難で、スケールするためにモノリス全体の複製が必要となります。
一方、AI に対応するために、アプリケーション全体を書き換える必要がないとしたらどうでしょうか。プラグを差し込むだけで使えるとしたら?
この投稿では、オーケストレーター パターンという優れた方法について説明します。具体的には、すべてを請け負う強力なエージェントを 1 つだけ作るのではなく、複数の特化した分散マイクロサービスから成るチームを構築します。このアプローチにより、モノリスの書き換えに悩まされることなく、強力な AI 機能を既存のフロントエンド アプリケーションに直接統合することが可能となります。
そのために、Google の Agent Development Kit(ADK)を使ってエージェントを構築し、Agent-to-Agent(A2A)プロトコルによって複数のエージェントを接続して相互通信し、Cloud Run 上でスケーラブルなマイクロサービスとしてデプロイします。
分散エージェントを使用する理由(フロントエンド チームに感謝される理由)
すでに完成された状態の Next.js アプリケーションがあるとします。これに、「コース作成ツール」という機能を追加したいとしましょう。
そのためにモノリス エージェントを構築すると、フロントエンドは、長時間かかる単一プロセスがすべて完了するまで待たされることになります。調査部分が滞ると、リクエスト全体がタイムアウトになります。また、個々のエージェントを必要に応じてスケールするといったこともできません。たとえば、評価エージェントがより多くの処理能力を必要とする場合、評価エージェントだけでなく、すべてのエージェントをスケールアップすることになります。
これに対し、分散オーケストレーター パターンを使用すれば、スケーラビリティと柔軟性が得られます。
-
シームレスなインテグレーション: フロントエンドは 1 つのエンドポイント(オーケストレーター)と通信し、オーケストレーターがバックグラウンドで複雑な処理を管理します。
-
個別にスケーリング: 評価ステップに時間がかかる場合は、そのサービスだけを 100 インスタンスにスケールアップし、調査サービスは小規模のままにできます。
-
モジュール式: 高パフォーマンスのネットワーキング部分を Go で、データ サイエンス部分を Python で記述できます。これらの通信には HTTP を使用します。
全体的な設計: コース作成アプリ
では、コース作成システムを構築しましょう。以下の 3 つのスペシャリストに分けて考えます。
-
調査担当: 情報を掘り起こすスペシャリスト。
-
評価担当: 品質を保証する QA スペシャリスト。
-
オーケストレーター: 作業間の調整を行い、フロントエンドと通信するマネージャー。
ステップ 1: スペシャリスト(リサーチャー)の配備
まず、調査の担当者が必要です。ADK を使って、Google 検索の部分のみを担当するエージェントを構築しましょう。
ご覧のように、とても簡単です。このエージェントは、コースやフロントエンドについては関知しません。調査のみを行います。
ステップ 2: 評価担当者(構造化されたデータ出力)
エージェントからの長ったらしい説明はいりません。コード側で判断しやすいよう、合格(pass)または不合格(fail)の厳密な評価が必要です。Pydantic を使って、このデータ規定を適用しましょう。
これで、評価担当者が JSON で話すようになり、アプリケーション ロジックはそれを信頼できます。
ステップ 3: 共通言語(A2A プロトコル)
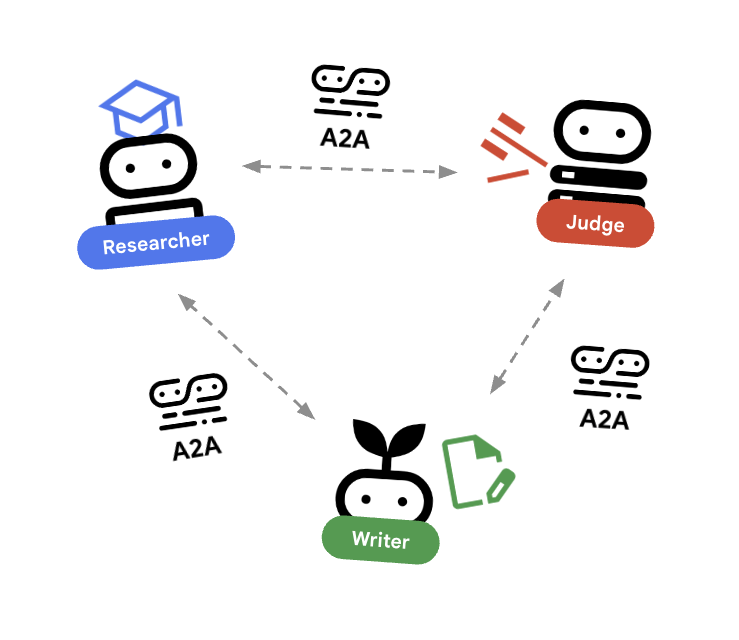
ここでマジックを使いましょう。A2A プロトコルを使って、これらのエージェントをウェブサービスとしてラップします。エージェントの共通言語のようなものとお考えください。エージェントは機能を説明し(agent.json)、標準の HTTP で通信します。
これで、リサーチャー(ポート 8000 で実行されるマイクロサービス)を配備できました。このサービスを、オーケストレーターなど、あらゆるものから呼び出すことが可能です。
ステップ 4: オーケストレーター パターン
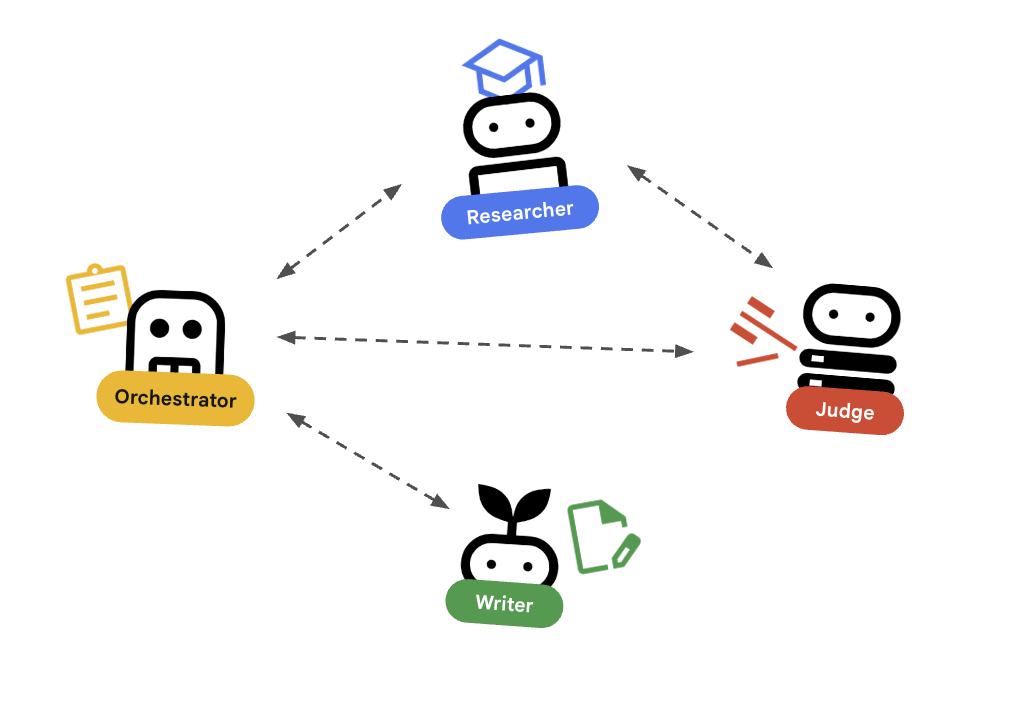
では、すべてを組み合わせましょう。オーケストレーターは、請負業者のようなものです。つまり、自分で調査を行わず、リサーチャーを雇います。自分で判断を下さず、評価担当者に尋ねます。
重要な点は、フロントエンドはこのエージェントのみを識別できればよいということです。
オーケストレーターが複雑な処理(再試行、ループ、状態管理)を担当するため、フロントエンドはクリーンかつシンプルに保たれます。
デプロイ:「食料品店」モデル
このシステムを Cloud Run にデプロイすることを、私は「食料品店」モデルと呼んでいます。チェックアウトの列(リサーチャーのタスク)が長くなっても、新しい店舗を建設する必要はありません。レジを増やせばいいだけです。Cloud Run は、調査の負荷増大に対応するために調査サービスのみをスケールし、評価サービスはそのまま保たれます。
注意事項、セキュリティ上の配慮
もちろん、大いなる力には大きな責任が伴います(そして、セキュリティ チェックが必要となります)。
-
認証: このデモでは、エージェントはオープンな HTTP を介して通信しています。本番環境では、このアクセスを制限する必要があります。mTLS、OIDC、または API キーを使用して、オーケストレーターのみがリサーチャーと通信できるようにします。
-
レイテンシ: ホップごとに時間が追加されます。オーケストレーター パターンは、詳細レベルの頻繁なインタラクションではなく、ざっくりとしたタスク(「このトピックを調査して」など)に使用するようにしましょう。
-
エラー処理: ネットワークにはエラーがつきものです。オーケストレーターには、タイムアウトと再試行を適切に処理できるような堅牢性が必要です。
構築を始めるにあたって
あらゆる作業を請け負う 1 つの巨大なエージェントを構築するのはやめましょう。オーケストレーター パターンと分散マイクロサービスを使用することで、スケーラブルで保守が容易な AI システムを構築できるだけでなく、既存のアプリとスムーズに連携できるというメリットも得られます。
コードについては、GitHub のコース作成エージェントのアーキテクチャで詳細をご確認ください。
準備ができたら、Cloud Run、ADK、A2A を使ってさっそくエージェント チームを結成しましょう。
- AI デベロッパーリレーションズ エンジニア、Amit Maraj



