AI のマルチツールのご紹介: ベクトル エンベディング
Google Cloud Japan Team
※この投稿は米国時間 2022 年 3 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
エンベディング(埋め込み)は、機械学習における最も汎用性のある手法の一つであり、すべての ML エンジニアが使用するべき重要なツールです。したがって、エンベディングとは何か、また何に役立つかを理解している人が少ないのは、とても残念なことです。
問題は、エンベディングがやや抽象的で難解に聞こえることかもしれません。
機械学習において、エンベディングとは、データを N 次元空間の中にある点として表現する手法で、類似したデータポイントをクラスタ化できます。
退屈でつまらない?騙されてはいけません。なぜなら、この ML マルチツールを理解すれば、検索エンジンからレコメンデーション システム、chatbot など、あらゆるものを構築できるようになるからです。さらに、ML の専門知識を備えたデータ サイエンティストでなくても、このツールを活用できますし、膨大なラベル付きデータセットも必要ありません。
難解に思えるツールの素晴らしさを、ご理解いただけましたか??
それでは、詳しく見ていきましょう。今回の投稿では、次のことを掘り下げます。
エンベディングとは何か
何のために使えるか
オープンソースのエンベディング モデルを、どこでどのように見つけるか
どのように使うか
エンベディングで構築できるもの
エンベディングとは何かという話をする前に、何を構築できるかについて簡単に確認しておきましょう。ベクトル エンベディングの能力:
レコメンデーション システム(例: 「この映画が好きなら、この映画も好きでしょう」とすすめる Netflix スタイル)
あらゆる種類の検索
テキスト検索(Google 検索など)
画像検索(Google の画像を使用した検索など)
chatbot や質問応答システム
データの前処理(機械学習モデルに投入するデータの準備)
ワンショット学習、ゼロショット学習(例: トレーニング データがほとんどない状態から学習する機械学習モデルなど)
不正行為の検出、外れ値検出
タイプミスの検出とあらゆる種類の「ファジー一致」
ML モデルの陳腐化(ドリフト)の検出
その他いろいろ
このリストにあるようなことを試していない場合でも、エンベディングの用途は非常に広いので、何かの役に立つかもしれません。ぜひ続けてご覧ください。
エンベディングとは
エンベディングは、テキスト、画像、動画、ユーザー、音楽など、ほとんどすべての種類のデータを、空間内の点として表現する手法で、そのような点が位置する空間は、セマンティクス的に有意なものです。
この意味を直感的に理解する最も効果的な方法は、例を挙げてみることです。では、最も代表的なエンベディングの一つである Word2Vec を見てみましょう。
Word2Vec(word to vector の略)は、2013 年に Google が考案した単語のエンベディング手法です。単語を入力すると、N 次元の座標(つまり「ベクトル」)が出力され、この単語ベクトルを空間にプロットすると、類義語がクラスタ化されるというものです。以下は図で表したものです。
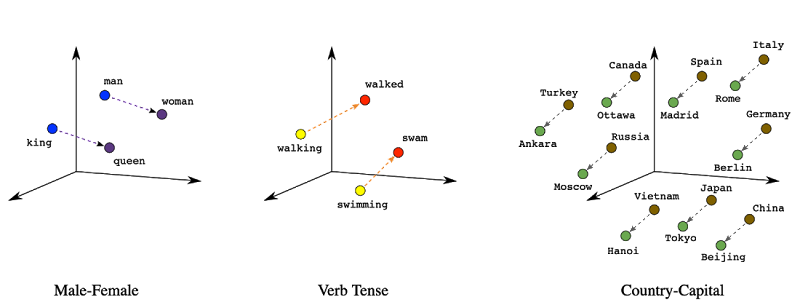
Word2Vec を使用すると、似た単語が空間でクラスタ化され、「王」「女王」「王子」を表すベクトル / 点はすべて近くに集められます。類義語(「歩く」、「散歩する」、「ゆっくり走る」)も同じようになります。
他のデータ型についても同じです。歌のエンベディングでは、似たような曲調の歌が近くにプロットされます。画像のエンベディングでは、似たような画像が近くにプロットされます。消費者のエンベディングでは、買い物の傾向が似ている消費者が近くにプロットされます。
もうおわかりだと思います。エンベディングを使用すると、類似するデータポイントを検出できるのです。たとえば、ある単語(例: 「王」)を入力すると、それに最も近い類義語を 10 個検出する関数を構築できます。これは最近傍探索と呼ばれています。単語で試してもそれほど面白くないので、代わりに映画のプロットを丸ごと埋め込むことを想像してみてください。すると、指定したある映画のあらすじと似たような映画を 10 本検出する関数が構築されます。あるニュース記事を指定すれば、意味的に類似した記事が提示されます。
さらに、エンベディングによって、埋め込まれたデータポイント間の数値的な類似度スコア、つまり、「このニュース記事はあの記事とどれくらい似ているか?」を計算できるようになります。これを行う一つの方法が、空間に埋め込まれた 2 つの点と点の距離を計算することで、その距離が近ければ近いほど類似していると言えます。この測定値はユークリッド距離です(ドット積、コサイン距離、その他の三角法の測定値も使用できます)。
類似度スコアは、重複検出や顔認識などのアプリケーションに有効です。たとえば、顔認識を実装するには、人の顔の写真を埋め込みます。そして、2 枚の写真の類似度スコアが十分に高ければ、同一人物であると判断します。つまり、スマホのカメラで撮った写真をすべてエンベディングして、エンベディング空間で非常に近い写真が検出されれば、それらの点は重複に近い写真であるという結論を出せます。
類似度スコアは、タイプミスの修正にも活用できます。Word2Vec では、「こんにちは」、「こんちは」、「こににちは」、「こんんちは」などの、一般的なミススペルは同じ文脈で使われるため、類似性スコアが高くなる傾向があります。
上のグラフ(方向)は、Word2Vec のさらなる非常に優れた特性を示しています。それは、異なる軸が性別や動詞の時制など、文法的な意味を捕捉しているということですつまり、言葉のベクトルを足したり引いたりすることで、「男性は女性に、王は____に」というような類似性を解釈できるということです。これは単語ベクトルの非常に優れた特徴ですが、この特徴は画像や長い大量のテキストのような、より複雑なデータ型のエンベディングでは、必ずしも有用な形で変換されるとは限りません(詳しくは後述します)。
エンベディングが可能なものとは
多くのものが埋め込み可能です。
テキスト
Word2Vec の場合は個々の単語だけでしたが、文全体やテキスト チャンクもエンベディングできます。オープンソースの代表的なエンベディング モデルに、ユニバーサル センテンス エンコーダ(USE)と呼ばれるものがあります。USE という名前は少し誤解を招く可能性があります。USE は文(センテンス)だけでなく、テキスト チャンク全体をエンコードできるからです。以下は TensorFlow のウェブサイトからの画像です。ヒートマップは、異なる文がエンベディング空間における距離に基づいて、どの程度類似しているかを示しています。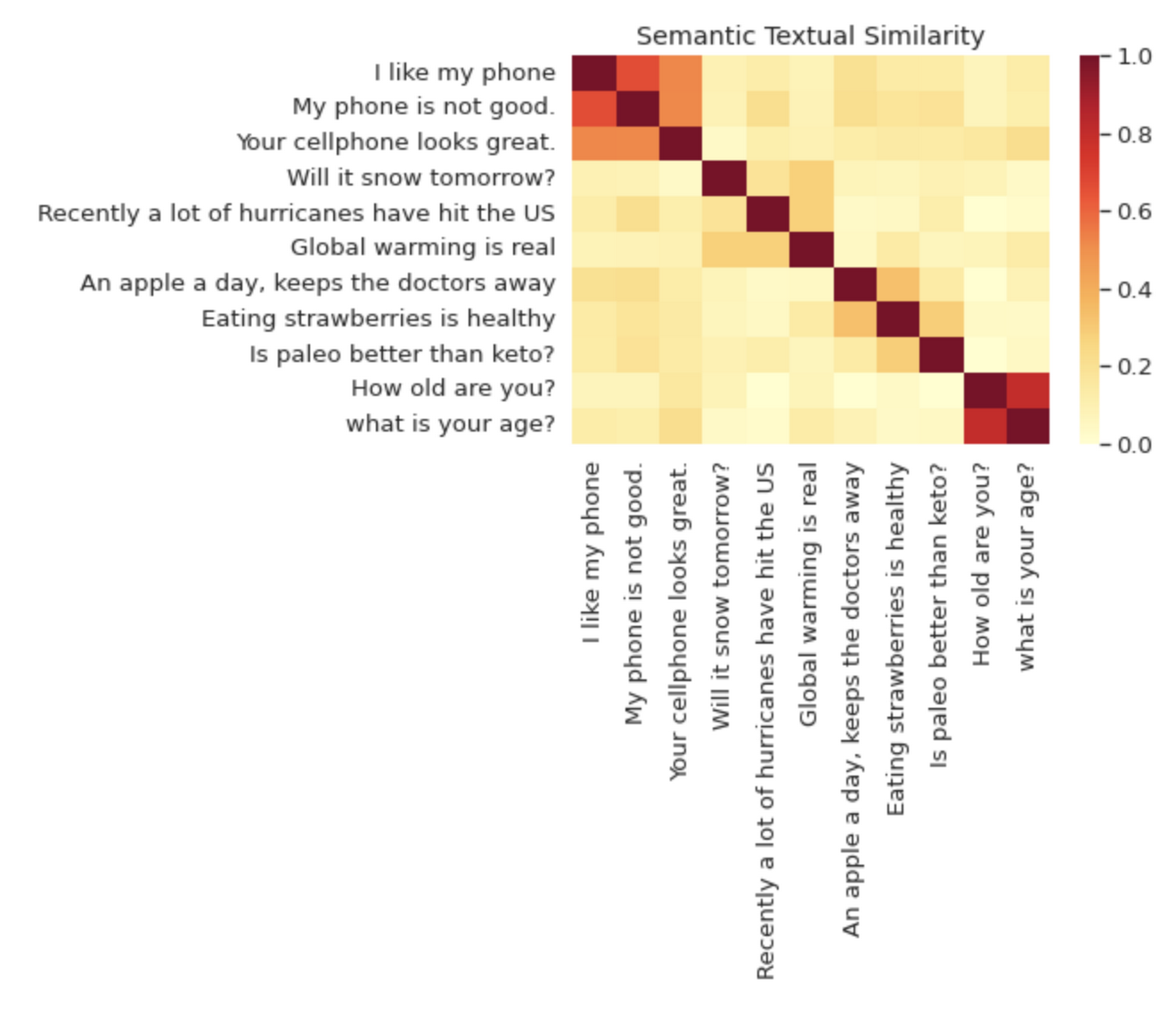
たとえば、New York Times の記事を検索できるデータベースを作りたいとします。
マイニュース記事のデータベース |
ここで、このデータベースを「食品」というテキストクエリで検索してみるとします。データベースの中で最も関連性の高い結果は、記事の見出しに「食品」という単語はありませんが、ブリトーに関する記事です。USE は、特定の単語の重複部分ではなく、テキストの意味類似性を捕捉しているので、生のテキスト自体ではなく、見出しの USE エンベディングで検索すれば捕捉できます。
ここで注目に値するのは、テキストに画像のテキスト キャプションや映画の文字起こしなど、多くのデータ型を関連付けることができるので、この手法をマルチメディアのテキスト検索に応用できるという点です。その一例として、検索可能な動画アーカイブをご覧ください。
試してみる: BigQuery でテキストの類似度検索とドキュメントのクラスタリングを行う方法|Lak Lakshmanan|Towards Data Science
画像
画像も埋め込めるので、画像を使用した検索、つまり「画像で検索」ができます。一例として、Vision Product Search があります。これは、Google Cloud のプロダクトです。
たとえば、衣料品店で検索機能を構築するとします。「レザー ゴス スタッズ ミニスカート」のようなテキストクエリに対応させたい場合、USE エンベディングのようなものを使用すれば、そのユーザーのテキストクエリを、商品説明とマッチさせることができるかもしれません。でも、ユーザーがテキストだけでなく、画像で検索できるようになったら、素晴らしいと思いませんか?画像で検索ができれば、買い物客は Instagram からトレンドのトップスをアップロードして、在庫の類似商品と照合できます(このチュートリアルでは、まさにその構築方法を紹介しています)。
画像検索を利用したプロダクトで私が気に入っているのは、Google レンズです。カメラの写真と、見た目が類似した商品をマッチさせます。ここでは、私のスニーカーと類似するオンライン商品をマッチさせてみます。

文のエンベディングと同様、画像のエンベディング モデルも無料で使用できるものがたくさんあります。この TensorFlow Hub のページでは、「feature vector」というラベルが付いた、多くのモデルを提供しています。これらのエンベディングは、大きなデータセットで画像分類を行うために最初にトレーニングされた、大規模なディープ ラーニング モデルから抽出されたものです。MobileNet のエンベディングを使用した画像検索のデモを見るには、こちらのデモをご覧ください。写真をアップロードすると、Wikimedia のすべてを検索して類似画像を見つけられるようになります。
残念なことに、オープンソースの画像のエンベディングは、文のエンベディングと異なり、特定のタスクに対して高い質を保つために、調整が必要な場合が多くあります。たとえば、衣類の類似度検索を構築したい場合、エンベディングをトレーニングする衣類のデータセットが必要になるでしょう(エンベディングのトレーニング方法については、もう少し詳しく説明します)。
もっと読む: 機械学習を使用した画像の圧縮、検索、補完タイプ、クラスタリング|Lak Lakshmanan|Towards Data Science
商品と買い物客
エンベディングは、特に小売業界において商品をおすすめする際に効果を発揮します。Spotify はどのようにリスナーの再生履歴に基づいた曲をおすすめしているのでしょうか。Netflix はどのように映画をおすすめしているのでしょうか。Amazon は、買い物客の購入履歴に基づいたおすすめ商品を、どのように識別しているのでしょうか。
現在、レコメンデーション システムを構築する最先端の方法は、エンベディングを使うことです。小売業者は、購入、再生、視聴履歴データを使用して、ユーザーと商品を埋め込むモデルをトレーニングします。
これは何を意味するのでしょう。
たとえば、私が BookShop という架空のハイテク書籍販売サイトのリピート客だとします。BookShop では、購入履歴データを使用して、2 つのエンベディング モデルをトレーニングしました。
1 つ目は、ユーザーのエンベディング モデルで、本の購入者である私を、購入履歴に基づいてユーザー スペースにマッピングします。たとえば、私は O’Reilly の技術ガイド、ポピュラーサイエンスの本、ファンタジー系の本などをたくさん買うので、このモデルはユーザー スペース内の他の「オタク」の近くに私をマッピングします。
一方、BookShop では、本を商品スペースにマッピングする商品エンベディング モデルも管理しています。商品スペースでは、同じようなジャンルやテーマを扱う本がクラスタ化されることが予想されます。つまり、フィリップ・K・ディックの『アンドロイドは電気羊の夢を見るか?』とウィリアム・ギブソンの『ニューロマンサー』は、テーマ的にも文体的にも似ているので、それを表すベクトルは近接しています。
エンベディングの作成方法
ここまでを要約すると、次のようになります。
エンベディングが有効なアプリの種類
エンベディングとは何か(データと空間内の点とのマッピング)
実際に埋め込むことができるデータ型の一部
エンベディングはどこで作成されるのか、もっと具体的に言うと、データを取り込んで、ユースケースに基づいてセマンティクス的に有意なエンベディングを出力する機械学習モデルを構築する方法について、まだ説明していません。
ここでは、ほとんどの機械学習で行われている、事前トレーニング済みのモデルを使う方法と、DIY、つまり独自のモデルをトレーニングする 2 つの方法をご紹介します。
事前トレーニング済みモデル
テキストを埋め込む、つまりテキスト検索やテキストの類似度検索を行う場合は簡単です。事前トレーニング済みのテキスト エンベディングは大量にあり、無料で手軽に利用できます。代表的なモデルとしては、先ほど紹介したユニバーサル センテンス エンコーダ モデルがあります。こちらの TensorFlow Hub のモデル リポジトリからダウンロードできます。このモデルをコードで使用するのはとても簡単です。このサンプルは、TensorFlow のウェブサイトから直接引っ張ってきたものです。
個人的には、Python コードを数行書くだけで、非常に高度な文のエンベディングが行えるのは、本当に、驚くべきことだと思います。
このようなテキスト エンベディングを実際に活用するためには、最近傍探索を実装し、類似度を計算する必要があります。そこで、センテンス エンベディングを使用したテキスト / セマンティック インテリジェントなアプリの構築という、ぴったりなトピックを扱った最近の私のブログ投稿をご紹介します。
オープンソースの画像エンベディングも簡単に入手できます。TensorFlow Hub ではこちらで検索できます。繰り返しになりますが、ドメイン固有のタスクで上手く使用するには、そのようなタイプのエンベディングをドメイン固有のデータ(衣料品の写真、犬種など)で微調整すると良いでしょう。
最後に、最近発表され注目されているエンベディング モデルの一つである、OpenAI の CLIP モデルについて触れないわけにはいかないでしょう。CLIP を使用すると、画像やテキストを入力して、両方のデータを同じエンベディング スペースにマッピングできます。これにより、画像に一番適切なキャプション(テキスト)を見つけ出すようなソフトウェアを構築できるようになります。
独自のモデルをトレーニングする
一般的なテキストや画像のエンベディングだけでなく、エンベディング モデルを独自のデータを使用してトレーニングすることが必要な場合が多くあります。現在、主流となっている方法は、Two-Tower モデルと呼ばれるものです。以下は Google Cloud のホームページからの抜粋です。
Two-Tower モデルでは、ラベル付きデータを使用することでエンベディングをトレーニングします。Two-Tower モデルでは、類似したベクトル オブジェクト(ユーザー プロフィール、検索クエリ、ウェブ ドキュメント、回答文、画像など)を同じベクトル空間にペアリングして、関連するアイテム同士を近接させます。Two-Tower モデルは、クエリと候補の 2 つのエンコーダ タワーで構成されています。これらのタワーでは、個別のアイテムを、マッチング エンジンが類似したアイテムを取得できる共有のエンベディング空間に埋め込みます。
今回の投稿では、two-tower モデルのトレーニング方法に関する詳細な説明はしません。これについては、Google Cloud で独自の Two-Tower モデルをトレーニングするためのガイドや、Tensorflow Recommenders のページで、独自の TensorFlow Two-Tower モデルとレコメンデーション モデルをトレーニングする方法が紹介されています。
いち早くフィードバックをくれた Kaz Sato に感謝します。

- AI 応用エンジニア Dale Markowitz



