Cloud Run による I/O Adventure の負荷テスト

Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
16 万人のバーチャル会議の参加者をシミュレートした方法
2021 年と 2022 年の Google I/O では、Google Cloud のテクノロジーを活用したオンライン会議体験である I/O Adventure で、遠く離れた参加者同士が出会い、バーチャルな世界を探求しました(詳細については、前回の投稿をご参照ください)。
I/O Adventure などのオンライン体験を構築する場合、早い段階でプロビジョニング戦略を決定することが大切です。しかしその前に、参加者数をある程度正確に予測する必要がありました。
対面式イベントの参加者数を見積もることは、無料のオンライン イベントの見積もるよりも簡単です。私たちは、このオンライン イベントの見積もりは、推測値から大きく乖離することがあると認識していました。唯一の安全な戦略は、実際の想定をはるかに超えるトラフィックを処理できるサーバー アーキテクチャを設計することでした。I/O Adventure の開催期間は数日間しかなかったため、イベント開始前に多くのサーバー インスタンスをスピンアップしておけば、オーバープロビジョニングが可能になると判断しました。
さらに、トラフィックの輻輳により参加者のエクスペリエンスが低下しないように、キューを実装することにしました。このシステムは、スムーズにサポートできる数の同時参加者を迎え入れ、それ以上のユーザーを待機キューに誘導します。万が一、十分に割り当てられた容量をトラフィックが超えた場合でも、キューがあればシステムが過度に混雑することがなくなります。
私たちのプロジェクトにおいて、スケーラブルなクラウド アーキテクチャを設計することと、重い負荷に対応することは、それぞれ別の課題でした。この投稿では、単一の VM などの個々のクラウド コンポーネントではなく、システム全体でクラウド バックエンドに負荷テストを行った方法について説明します。
クラウド バックエンド全体の負荷テストを行う場合、コンポーネント レベルのテストでは必ずしも考慮されない複数の懸念事項に対処する必要があります。割り当ての問題がその良い例です。割り当ての問題を、事前に予測することは容易ではありません。さまざまな割り当ての問題について検討する必要があったのです。200 台の VM をスピンアップするのに十分な割り当てがあるか?具体的には、使用する機械の種類(E2、N2 など)に対して十分な割り当てがあるか?もっと具体的には、プロジェクトがデプロイされるクラウド リージョンでの割り当ては十分か?インフラストラクチャ
数千人の参加者を想定した負荷テストを設計するには、2 つの重要な要素を考慮する必要がありました。
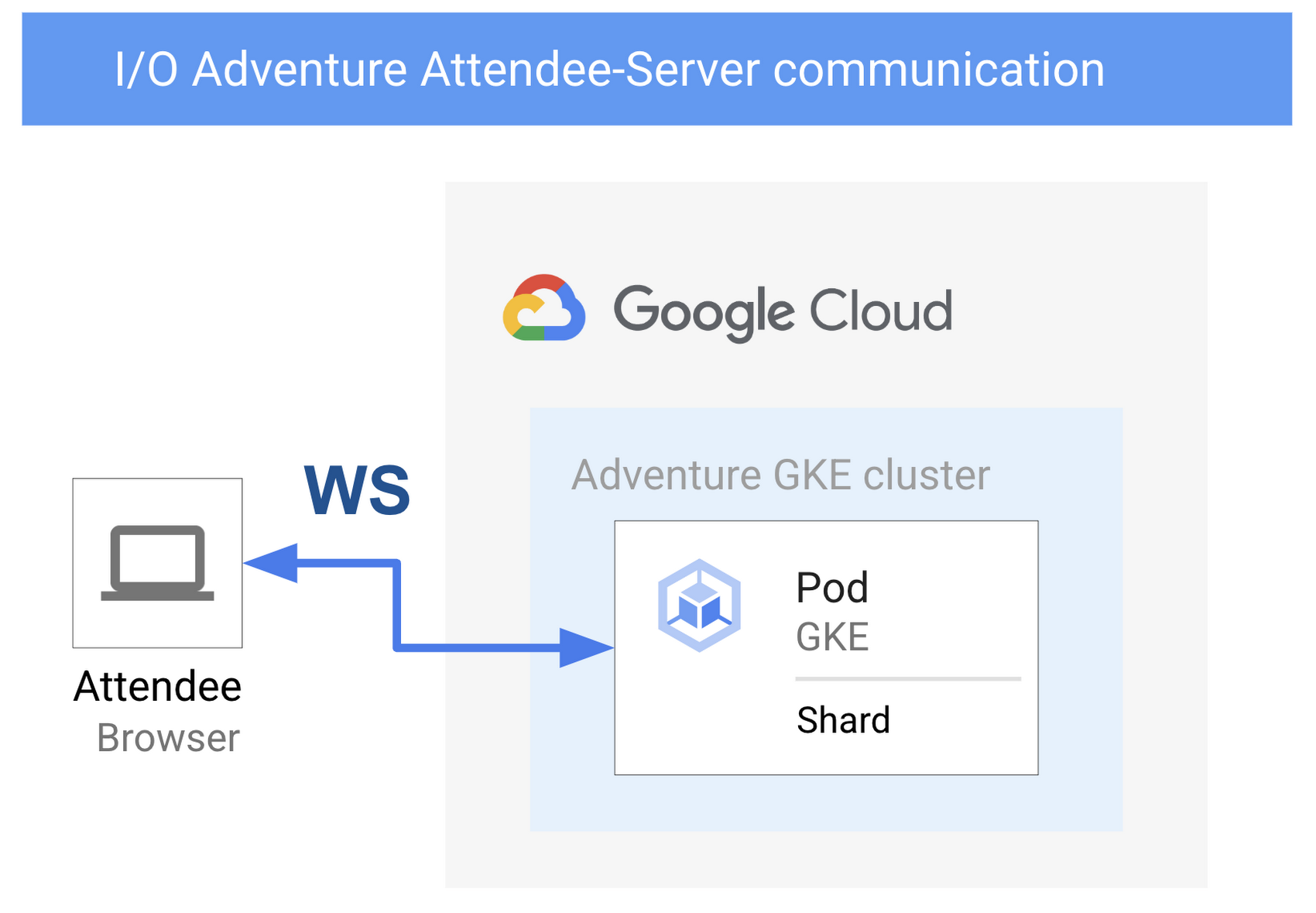
参加者は WebSocket を使用して、ブラウザからクラウド バックエンドと通信します。
通常の参加者のセッションは、少なくとも 15 分間切断されずに継続します。これは、個々の HTTP リクエストに焦点を当てた一般的な負荷テスト手法による時間を超えるものです。
VM のプロビジョニングと管理によって負荷テストスイートをセットアップすることは可能ですが、私たちには Cloud Functions や Cloud Run などのサーバーレス ソリューションへの強いこだわりがありました。そのため、そのうちのいずれかを使ってユーザー セッションをシミュレートし、ロード インジェクタの役割を果たせないかと考えたのです。Google Cloud のサーバーレス インフラストラクチャは、このユースケースに必要なプロトコルである WebSocket に対応しているでしょうか?
答えはイエスです。Cloud Run は、WebSocket に外向きと内向きで対応しており、リクエストごとのタイムアウトを最長 1 時間に構成できます。
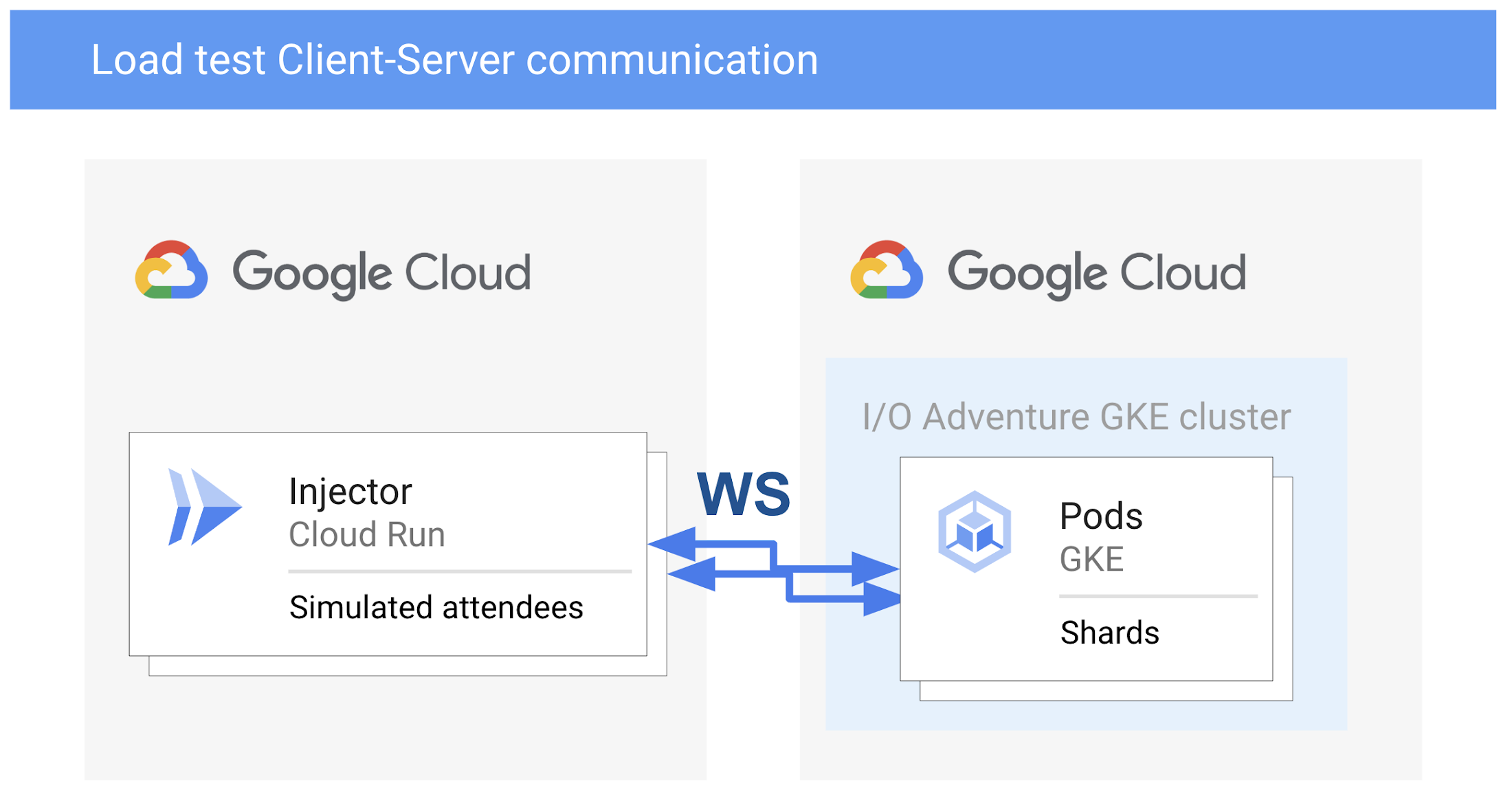
負荷テストでは、WebSocket 接続が切断されることなく数分にわたって何千ものメッセージを送信する、一般的な参加者のセッションをシミュレートしました。
同時実行
バックエンドでは、以下の方法で I/O Adventure のサーバーが数千人の同時参加者に対応しています。
各シャードで 500 人の参加者を受け入れる(シャードは、参加者同士が交流できる会議の一部に相当するサーバー)
事前プロビジョニング済みの、数百の独自のシャードを持つ
各 GKE ノードで複数のシャードを実行する
新たな参加者を、空き容量のあるシャードにルーティングする
クライアント側(ロード インジェクタ)では、以下のような複数レベルの同時実行を行いました。
各トリガー(たとえばワークステーションから curl で開始する HTTPS リクエスト)が、15 分間の多数の同時実行セッションを立ち上げ、それらの完了を待つ
各 Cloud Run インスタンスが、多数の同時実行トリガー リクエストを処理する(各インスタンスあたりの最大同時リクエスト数)
Cloud Run は、既存のインスタンスの容量が限界に近づくと、自動的に新しいインスタンスを開始します。Cloud Run サービスは、必要に応じて数百、数千のコンテナ インスタンスにスケールできます。
負荷テストを増強する手段として、より多くの同時リクエストをメインの Cloud Run インジェクタにトリガーする Cloud Run サービスを新たに作成しました。
1 人の参加者のストーリーをシミュレートする
シミュレートされた「ユーザー ストーリー」を作成します。これはつまり、ログインし、シャードの GKE Pod にルーティングされ、15 分間ランダムに数百人の参加者が移動し、切断するという負荷テストのシナリオです。
今回は、Cloud Run でシミュレーションを行い、ノートパソコンから curl コマンドを実行してテストを開始しました。このセットアップでは、シナリオ(ストーリー)が WebSocket クライアントとして接続を開始し、Pod が WebSocket サーバーとなっています。
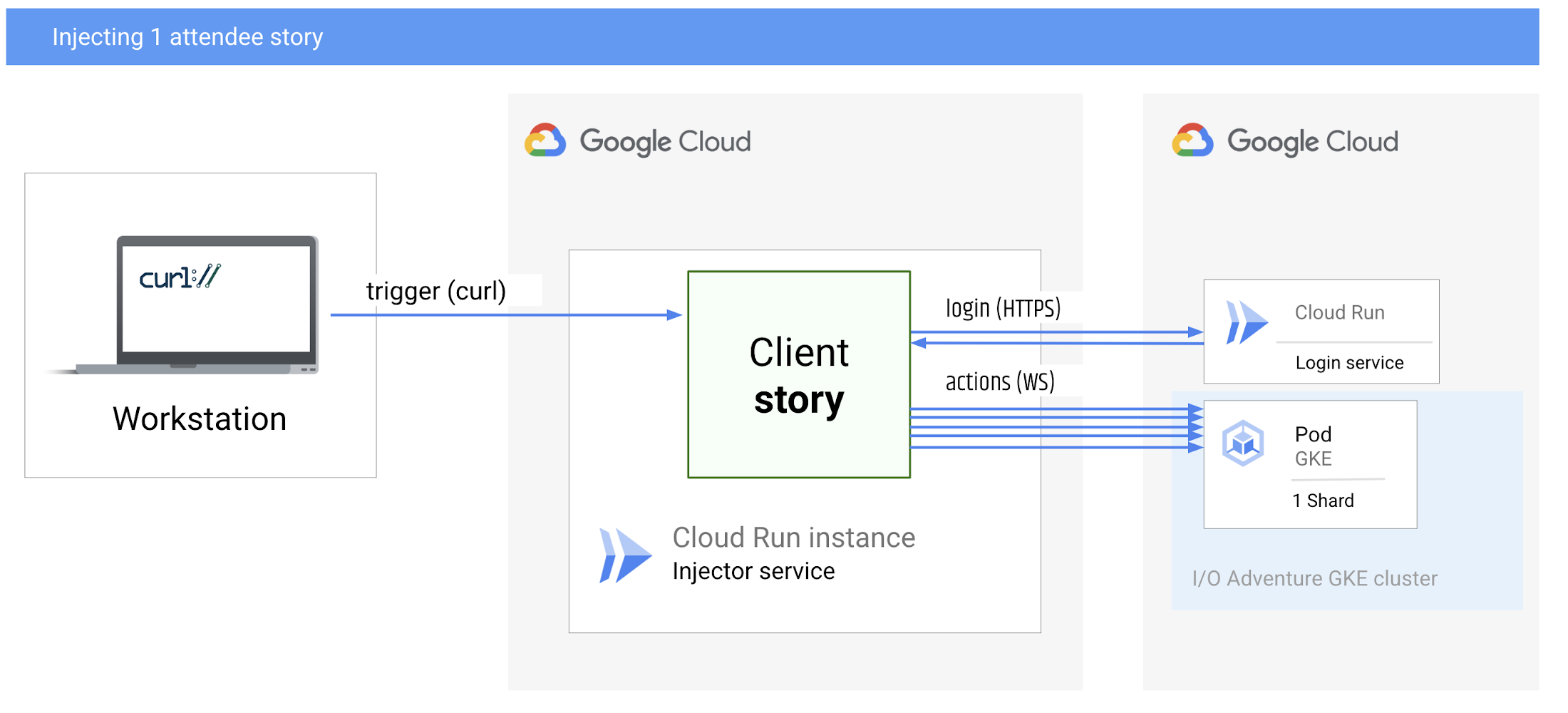
参加者のストーリーを 1 つ挿入する
1 つのトリガーで多くの参加者のストーリーを開始する
多くのストーリーを並行して開始し、その完了を待つ、インジェクタ サービス ハンドラ(Node.js スクリプトとして実装)を作成しています。
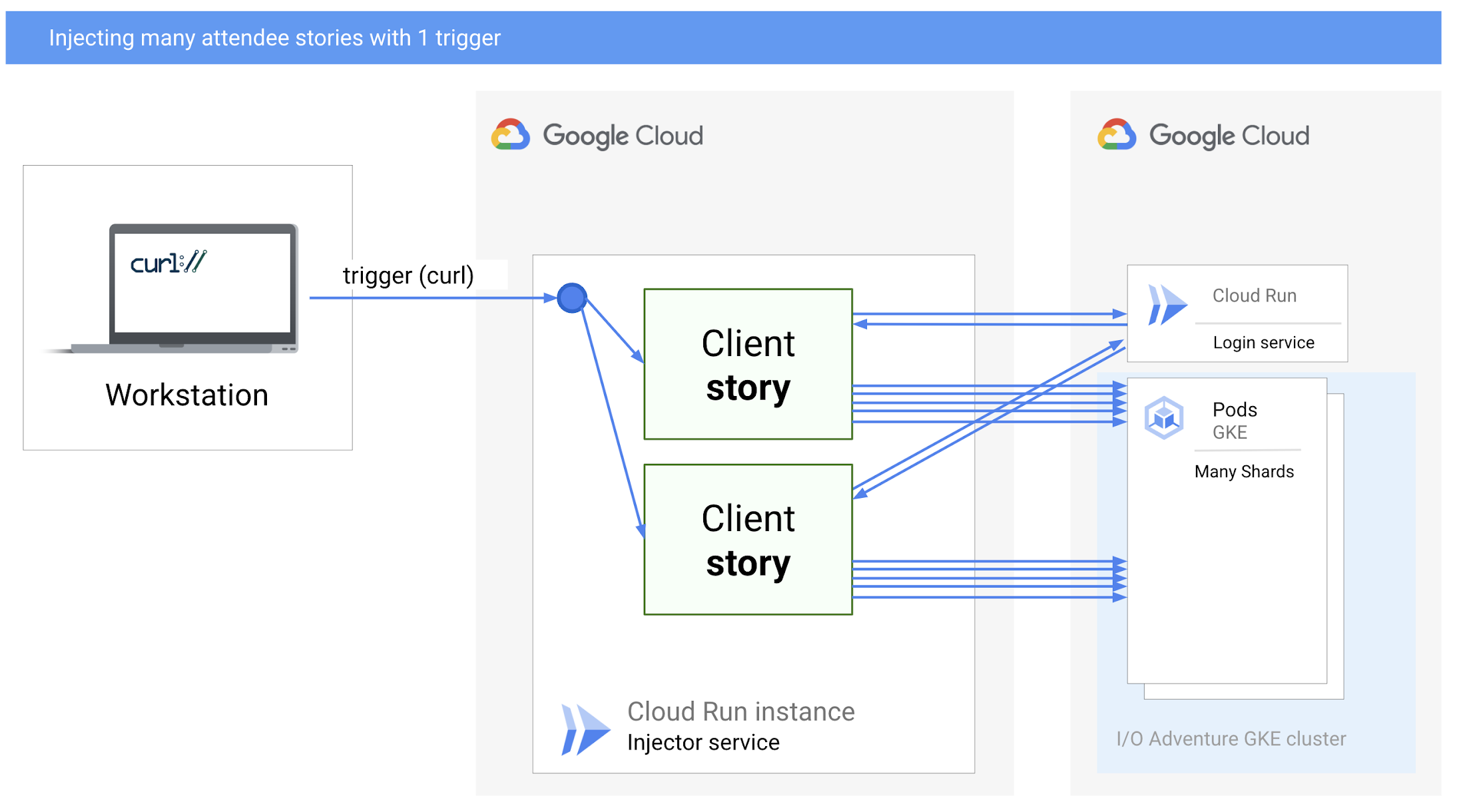
多くの参加者のストーリーを、いくつかの同時進行トリガーで挿入する
コマンドライン ターミナルから curl でインジェクタを同時に何度もトリガーすることで、負荷を増幅できます。
Cloud Run は、必要に応じて新たなインジェクタ マシン(Cloud Run インスタンス)をスピンアップすることで、自動的にスケールアップします。
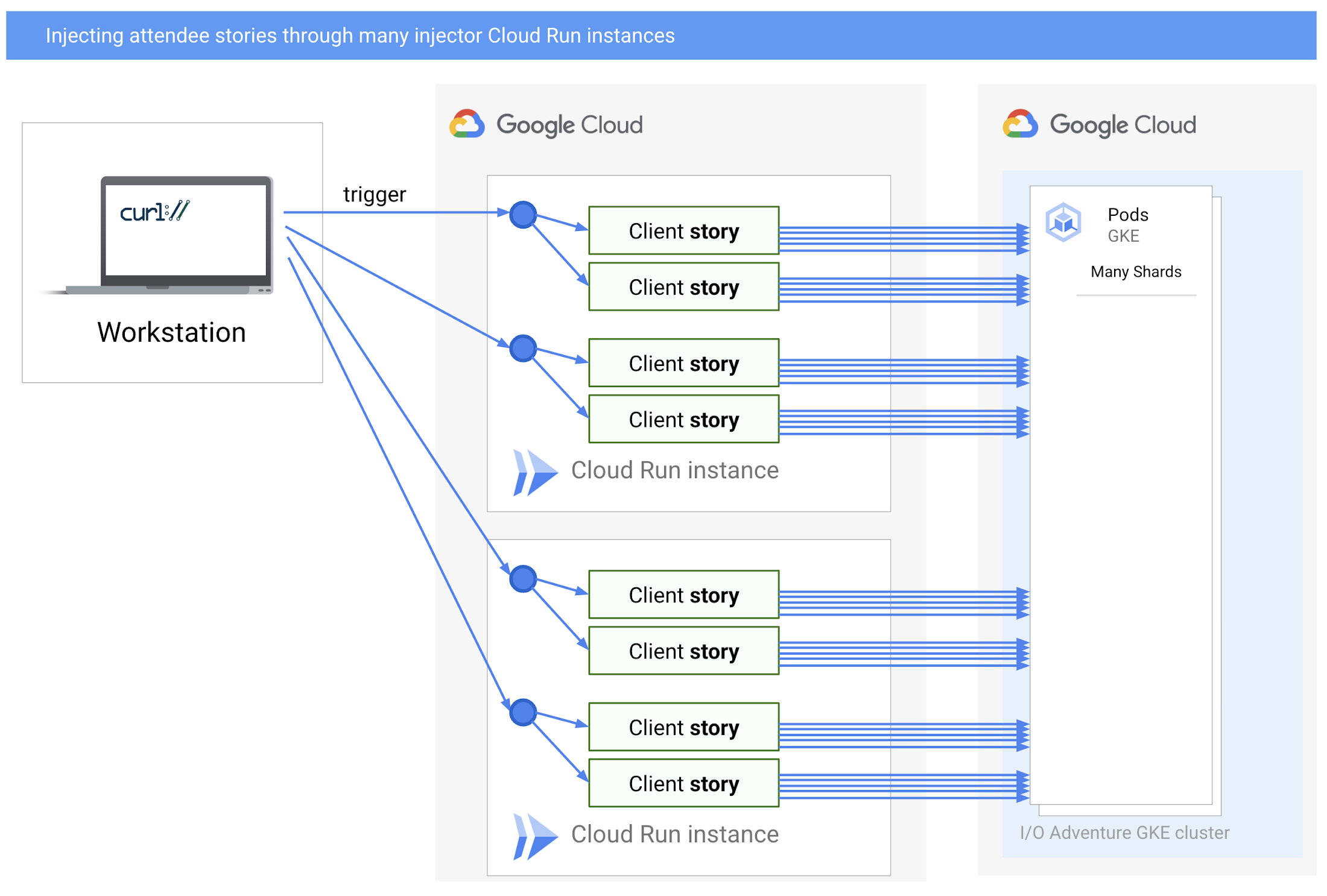
Cloud Run の追加サービスを通じて、より多くの参加者のストーリーを挿入する
以前のセットアップでは、curl で長時間のトリガー リクエストを多く起動しすぎたことにより、ワークステーションがボトルネックになっていました。そのワークステーションは TCP 接続数を制限し、すべての SSL ハンドシェイクに必要な CPU 負荷になんとか追いついていました。
私たちは、大量のトリガーを処理する中間サービスを新たに作成することで、これを解決しました。また、インジェクタのスループットを最大化するため、いくつかのパラメータ値(トリガーごとのストーリー数、Cloud Run インスタンスごとの最大リクエスト数など)を試しました。
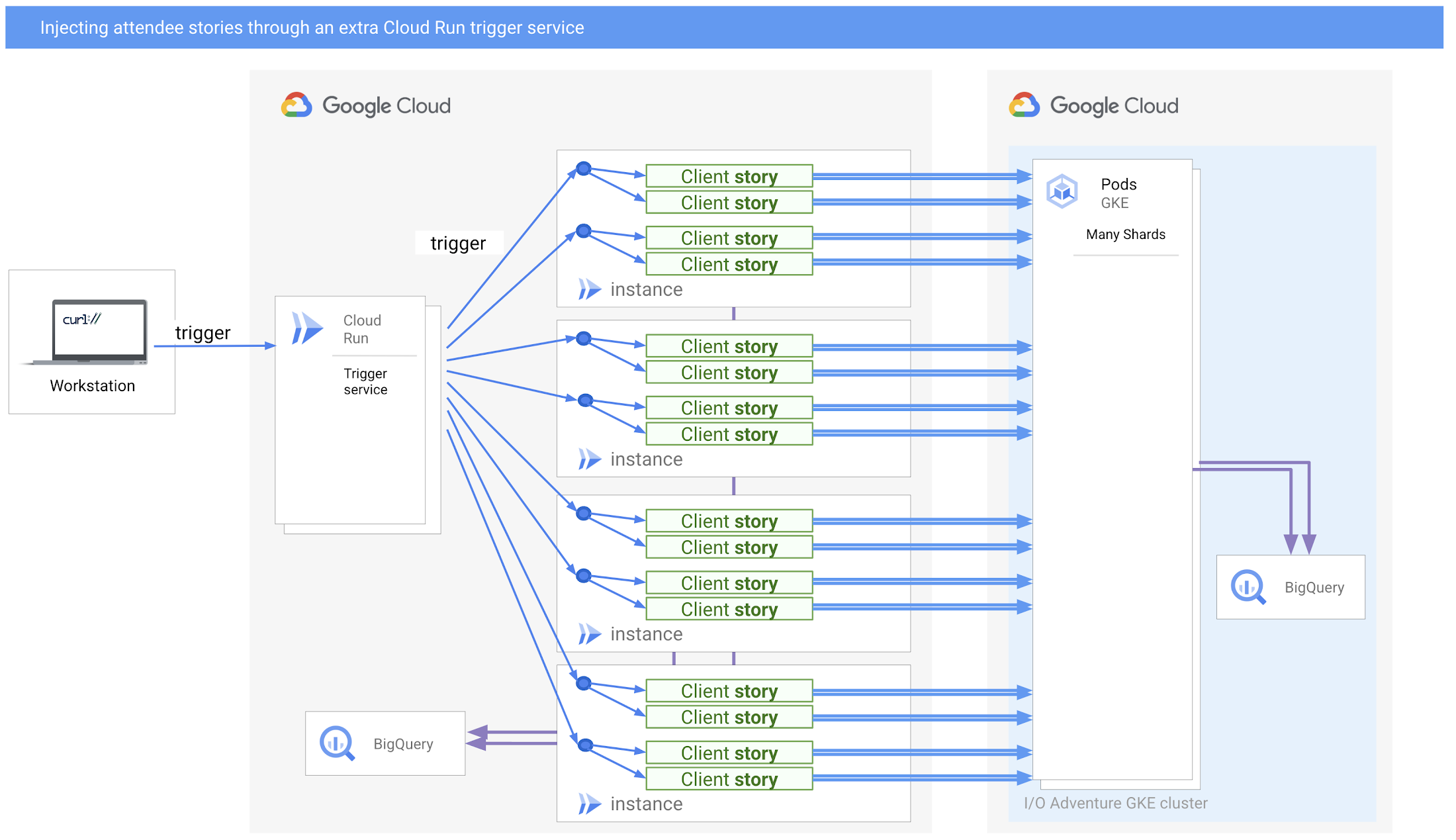
Cloud Run の追加トリガー サービスで参加者のストーリーを挿入
インジェクタ側とサーバー側の両方におけるログの取り込みに使用される BigQuery コンポーネントに注目してください。
成功率を測定
レスポンス コードが明示されている HTTP リクエストとは異なり、WebSocket メッセージは一方向であり、デフォルトでは確認応答を得られません。
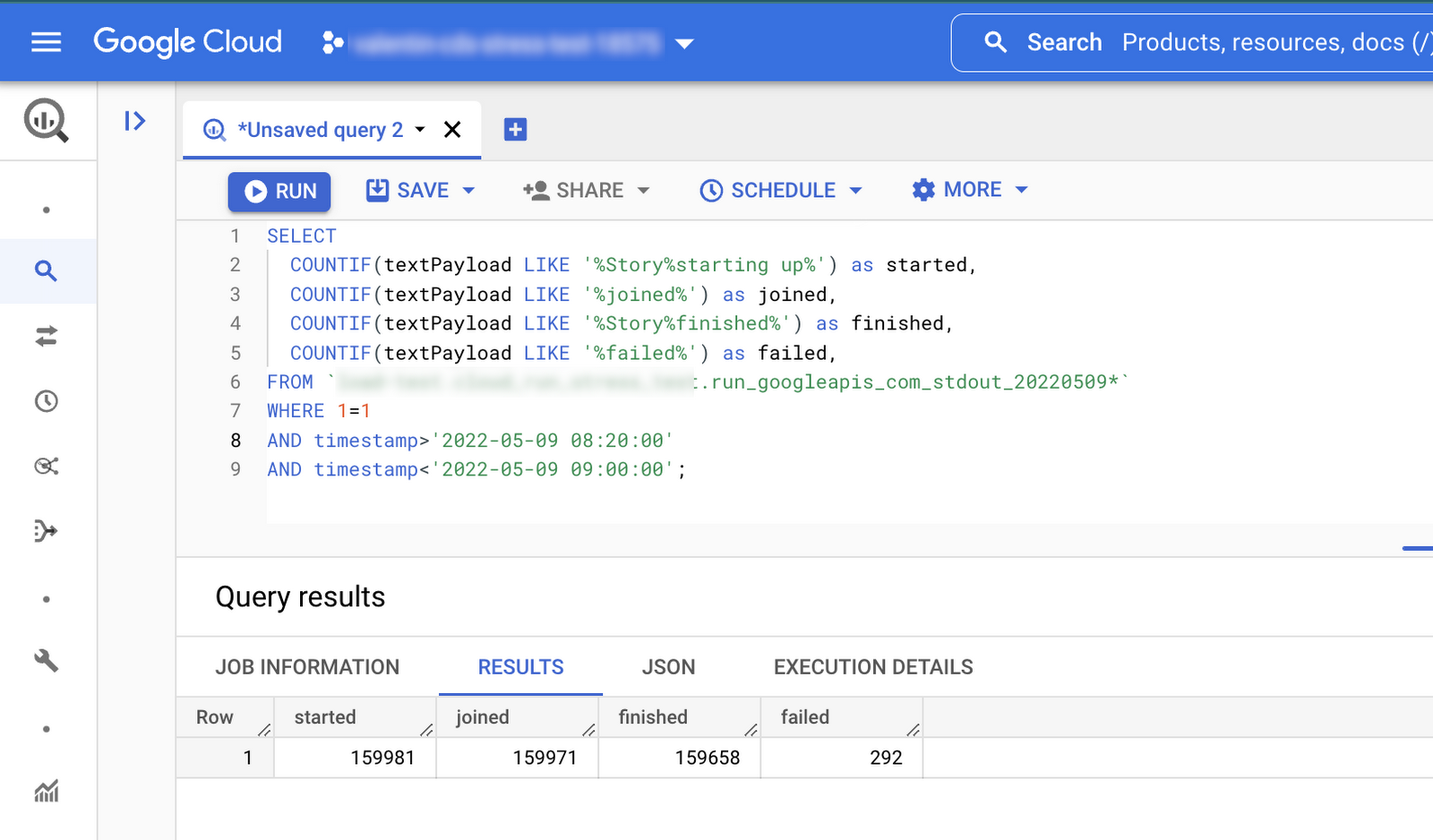
完了まで正常に実行されたストーリーの数を追跡するために、標準出力にいくつかのイベント(ログイン、開始、終了など)を書き、ログのシンクを有効にしてすべてのログを BigQuery にストリーミングしました。イベントは、クライアント(インジェクタ)の視点と、サーバー(GKE Pod)の視点からログに記録されました。
これにより、集約的な SQL クエリで以下をかなり実行しやすくなりました。
最低でも 99% 以上のストーリーが成功したことの確認
ストーリーが想定時間内で収まったことの確認
さらに、いくつかの Grafana ダッシュボードを見ながら GKE クラスタのライブ指標をモニタリングし、CPU、メモリ、帯域幅のリソースが圧迫されていないことを確認しました。
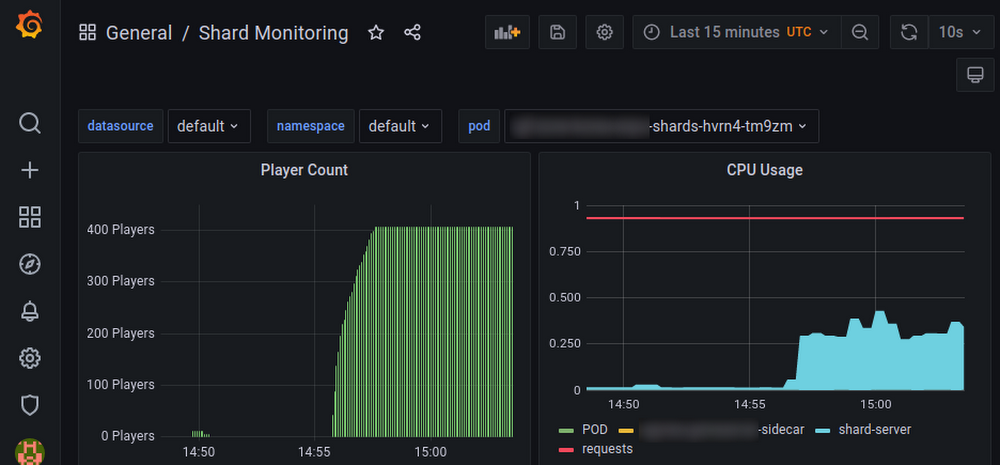
目視確認
ちょっとしたボーナスですが、実際に参加者としてつながり、いたる所で実行されている何百もの bot を見るのはとても楽しい体験でした。
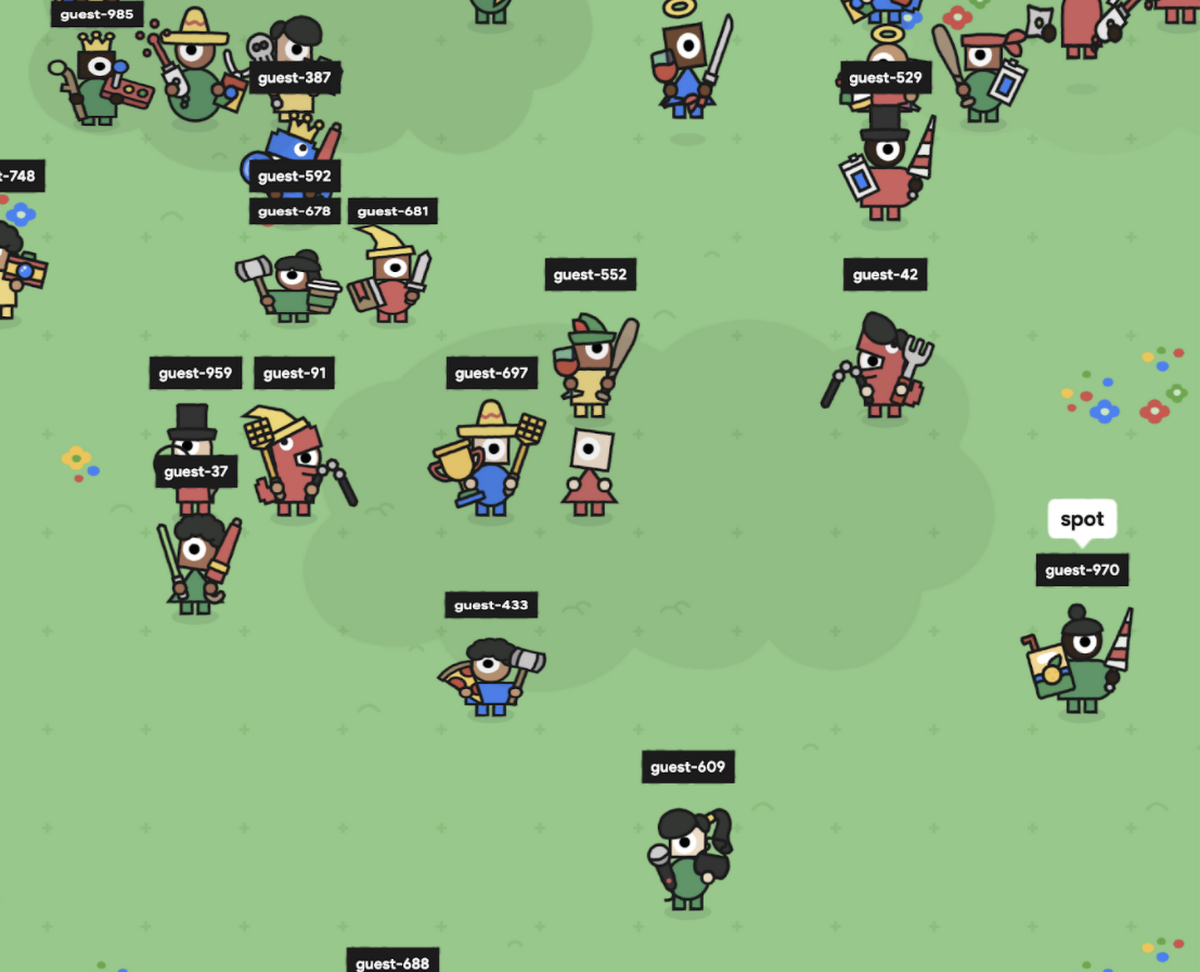
また、負荷のかかったシステムにブラウザで接続することで、主観的な体験を評価できるようになりました。たとえば、あるシャードで 500 人の参加者をホストし、フロントエンドが何十もの動くアバターをレンダリングしているときでも、アニメーションがスムーズに動作することを確認できました。
結果
テストでは、40 ストーリーに対する計 4000 のトリガーと、Cloud Run インスタンスにつき最大同時実行数 40 のリクエストで 100 以上のインスタンスを使用して、16 万人の同時アクティブ参加者の追加に成功しました。この負荷テストのスクリプトを数日かけて数回実行した結果、総費用は約 100 ドルでした。このテストでは、GKE クラスタで使用するすべてのサーバー CPU コアを、割り当てられた容量で最大限活用しました。ミッション完了
結果として、以下を私たちは以下の結論を得ました。
負荷テストの費用は許容範囲内だった。
増やすべき割り当ては、特定の CPU コアの数と外部 IPv4 アドレスの数だった。
私たちのプラットフォームは、16 万人の参加者という負荷目標を維持できた。
実際のイベントでは、ピーク時のトラフィックは最大許容負荷を下回ることが明らかになりました(結果として、実装したキューで参加者が待機することはありませんでした)。テストの結果、バックエンドは大きな問題なく目標負荷に対応できたことが確認されました。
もちろん、Cloud Run と Cloud Run Jobs は、ウェブサイトのバックエンドや負荷テストに限らず、さまざまなワークロードを処理できます。詳細をご確認のうえ、皆様のワークフローにどのように活かせるかぜひご検討ください。
- Google Cloud、デベロッパー アドボケイト Valentin Deleplace



