学生のうちにデータ分析スキルをレベルアップする

Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
あなたが私と同じ大学生で、これから新卒者として就職活動を始める準備をしている立場の方であれば、どうすれば競争において優位に立ち、同世代の若者の中でも目立つ存在となれるのか考えて(あるいは心配して)いることでしょう。
技術的なスキルの向上や資格の取得について、どの分野が価値の高いターゲットとなり得るか検討したときに、私が常にたどり着くのがデータ分析です。
データ分析を学ぶ理由
テクノロジー主導の社会では、あらゆる形態のデータの価値がますます高まっていますが、これはデータがもたらしてくれるインサイトのためです。私たちの生活の中で生み出されていくデータの量は、あらゆる分野で指数関数的に増加しています。つまり、コンピュータ サイエンスやマーケティング、音楽など、専攻している分野にかかわらず、既存のスキルを補完する目的でデータ分析を学ぶことでメリットを享受できるということであり、学生にとっては喜ばしいニュースです。データを操作、処理、分析し、意味のある形で表現するために必要なスキルを身につければ、バックグラウンドに関係なく、自分自身をさらに高めることができます。
新しいスキルを習得するときに考えること
課題や仕事、インターンシップをこなしながら、新しい技術スキルやツールを学ぶのは大変なことです。私も、その気持ちはよくわかります。だからこそ、私たち学生にとって、学習に最適なリソースを戦略的かつ効率的に見分けることがとても重要なのです。
私が新しいソフトウェアやスキルを学ぶときは、次のような要素を考慮しますが、これは皆様にとっても重要なものだと思います。
どれくらいの費用がかかるのか。
どれくらいの時間がかかるのか。
自分の将来の仕事にどのように応用できるか。
費用
正直に言うと、私が最初に考えるのはこの要素です。財源をどのように配分するかというのは重要なスキルですし、キャリアのための自己研鑽の場合は特にそうです。
時間
そして時間ですが、これもある意味では費用といえます。私たち学生にとって時間は貴重であり、場合によっては、お金よりも大切なものです。課題や勉強、通学時間、課外活動、キャリア形成、そして場合によってはその費用を捻出するための仕事さえもこなさなければなりません。そのため、比較的簡単に学べ、自分にとって都合の良い時間に、柔軟に、自分のペースで学べるスキルがターゲットとなります。
応用性
最後に私が考慮するポイントが、就職活動において有利なスキルやツールかどうかという点です。つまり、履歴書に記載できるもので、応募予定の企業が属する業種に対してアピールできるものを学びたいと思っています。キャリアアップはこのような自己学習の主要な原動力の一つなのですから当然です。ですから私は、業界標準のソフトウェアやサービスを使って直接学べる機会を常に探しています。
Google Cloud でデータ分析を学ぶ
Google でのインターンシップでは、Google Cloud の各種サービスを使ってデータ分析のスキルを身につける機会に多く恵まれました。このブログ投稿では、その中でも特に BigQuery とデータポータルという 2 つのサービスに焦点を当てます。
BigQuery とは
BigQuery はクラウド データ ウェアハウスであり、企業が大規模なデータセットに対して分析を行う目的で使用します。また、SQL(データ分析に使用する言語)の学習や練習にも最適です。BigQuery の「使い始め」はスムーズに進められるため、学生の貴重な時間を大幅に節約してくれます。データベース ソフトウェアをダウンロードしてインストールし、データを用意してテーブルに読み込む必要はありません。BigQuery サンドボックスにログインすれば、すぐに SQL クエリを記述して(またはサンプルのクエリをコピーして)、Google Cloud 一般公開データセット プログラムの一環として提供されているデータの分析を始めることができます(これについては後ほどさらに紹介します)。
データポータルとは
データポータルはオンラインのビジネス インテリジェンス ツールです(BigQuery に統合されています)。カスタマイズ可能な見やすい表やダッシュボード、レポートを使ってデータを可視化できます。SQL クエリの結果を可視化する目的でも使用できます。また、SQL を使用せずにデータを分析したり、技術者以外のユーザーと分析情報を共有したりするのにも最適です。
データポータルは Google Cloud の一部として提供されているため、クエリ後の処理済みデータを外部ツールにエクスポートする必要はありません。BigQuery 環境に直接接続してデータを可視化できるため、データファイルの互換性やサイズなどを気にする必要がなく、多くの時間と労力が軽減されます。
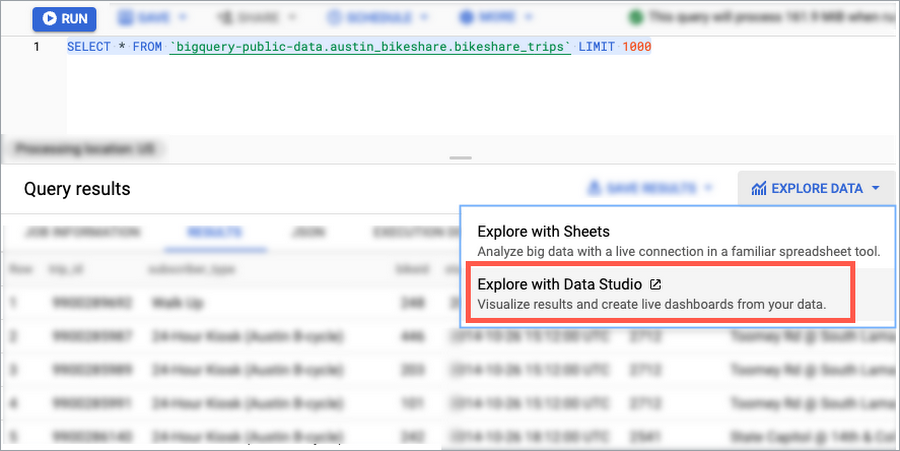
BigQuery コンソールからワンクリックするだけで、データポータルでクエリ結果を可視化できます。
BigQuery とデータポータルのどちらも、Google Cloud の無料枠内で、ほとんど費用をかけずに利用できます。無料枠では初期容量のデータ ストレージが割り当てられ(自分のデータをアップロードする場合)、毎月一定量のバイト数まで、クエリ目的の処理を行うことができます。また、この無料枠の範囲内でも BigQuery の「サンドボックス」環境をセットアップすることが可能で、クレジット カードは必要ありません(セットアップの方法は後ほど説明します)。
つまり BigQuery もデータポータルも無料ですぐに使い始めることができるのです。そしてその応用性についてですが、BigQuery とデータポータルは、現在多くの業界で本番環境のワークロードに使用されています。BigQuery やデータポータルを LinkedIn で検索すれば、それを実感していただけるはずです。
BigQuery とデータポータルを使ってみる
それでは実際に使ってみましょう。どちらのツールも容易に使い始められることを説明するために、ここでは BigQuery とデータポータルを一般公開データセットに対して実際に使用する簡単なチュートリアルを紹介したいと思います。
BigQuery が問題の解決に役立つことを示すため、次のようなサンプルのシナリオを用意しました。
ここでは、あなたが Pistach.io に最近採用された新しいインターンであるという設定でシナリオを進めます。Pistach.io は新規採用者に対して、最初の数週間はトレーニング プログラムを受けるために出社するというルールを定めています。ですから、必ず時間どおりに出社する必要があります。Pistach.io はニューヨーク市にあり、近隣に利用できる駐車場はありません。ニューヨーク市では公共のシェアサイクル プログラムを導入しています。そのため、このシェアサイクルを利用して出勤することにしました。
時間どおりに出社しなければならないため、以下の点を重要な要素として検討する必要があります。
朝から利用できる自転車が用意されている最寄りのシェアサイクル ステーションはどこか。
会社から一番近い自転車の返却場所はどこか。
混雑しているので避けた方がいいのはどのステーションか。
一般公開データセットを使って、このような疑問の回答を導き出せないでしょうか。幸いなことに、BigQuery には多数のデータセットが用意されており、無料で利用できます。この例で分析するデータは、ニューヨーク市のシェアサイクル(Citi Bike)に関する一般公開データセット(new_york_citibike)に含まれています。
セットアップ方法
まず、BigQuery のサンドボックスを作成します。基本的には、これが作業環境になります。次の手順に沿ってセットアップしてください(https://cloud.google.com/bigquery/docs/sandbox)。
Google Cloud コンソールで BigQuery ページに移動します(関連ドキュメント)。
[エクスプローラ] ペインで、[データを追加] > [プロジェクトを固定] > [プロジェクト名を入力] の順にクリックします。
「bigquery-public-data」と入力して [固定] をクリックします。このプロジェクトには、一般公開データセット プログラムで利用可能なすべてのデータセットが含まれています。
基礎となるデータセットを確認するには、[エクスプローラ] ペインで bigquery-public-data プロジェクトを開き、スクロールして「new_york_citibike」を見つけます。
クリックしてデータセットをハイライト表示するか、開いて citibike_stations テーブルと citibike_trips テーブルを表示します。テーブルをハイライト表示すると、スキーマやデータのプレビューなど、より詳細な情報を確認できます。
クエリを実行する
それでは分析に入ります。どのシェアサイクル ステーションが自宅に一番近いか解明しましょう。このチュートリアルでは、ニューヨーク市の Port Authority バスターミナルを「自宅」として使用します。

このクエリは、各 Citi Bike ステーションと「自宅」の間の距離を計算し、近い順でステーションをリストアップした結果を返します。ST_DISTANCE 関数は、2 点間の最短距離を計算します。自転車通勤というより鳥の直線飛行に近いですが、今回のケースでは十分に有効です。
次に、会社から最も近いステーションを特定します。ここではニューヨーク市チェルシー マーケットの Google オフィスの座標を使いましょう。ここは、私が今年の夏に勤務していたオフィスです。基本的には、先ほどと同じクエリを使用できます。

最後に、混雑するステーションの利用を避けるため、会社周辺の Citi Bike ステーションの中で最も混雑しているところを特定します。

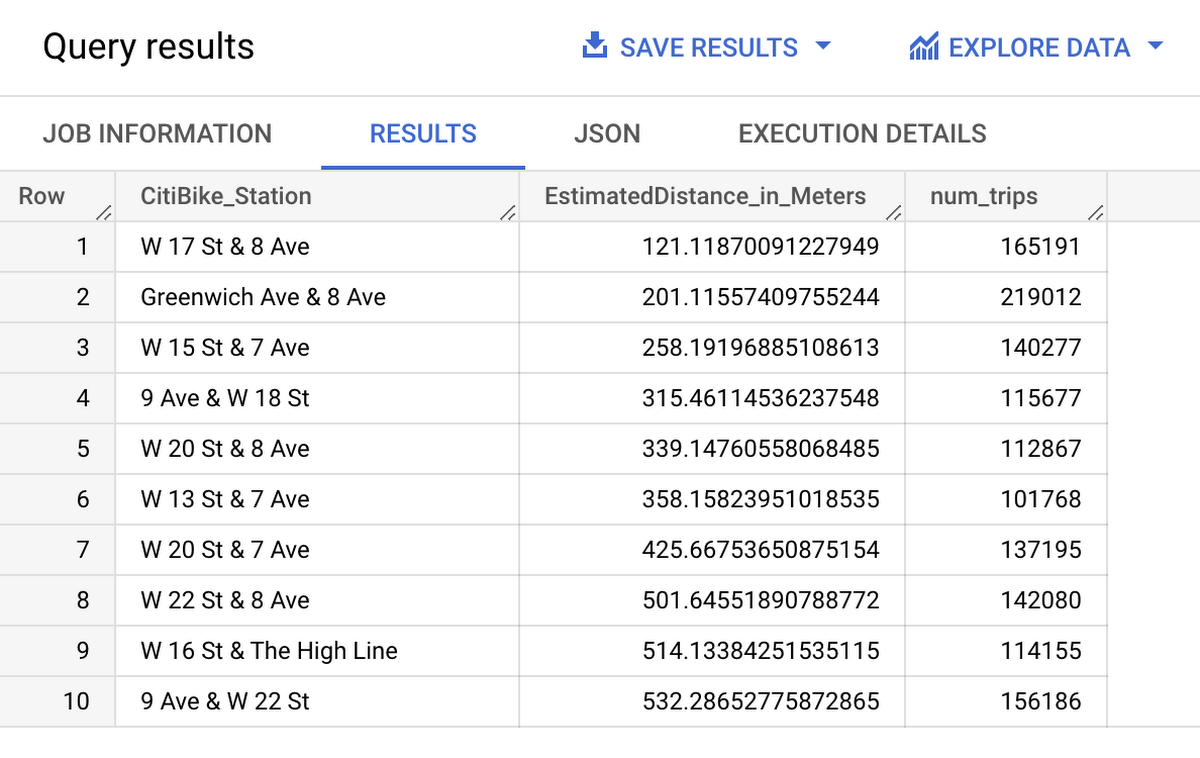
結果を可視化する
BigQuery の優れた点の一つとして、データポータルで結果を簡単に可視化できることが挙げられます(クエリ結果ページで [データを探索] ボタンを押すだけです)。これにより、クエリから得られた情報をより正確に把握できます。
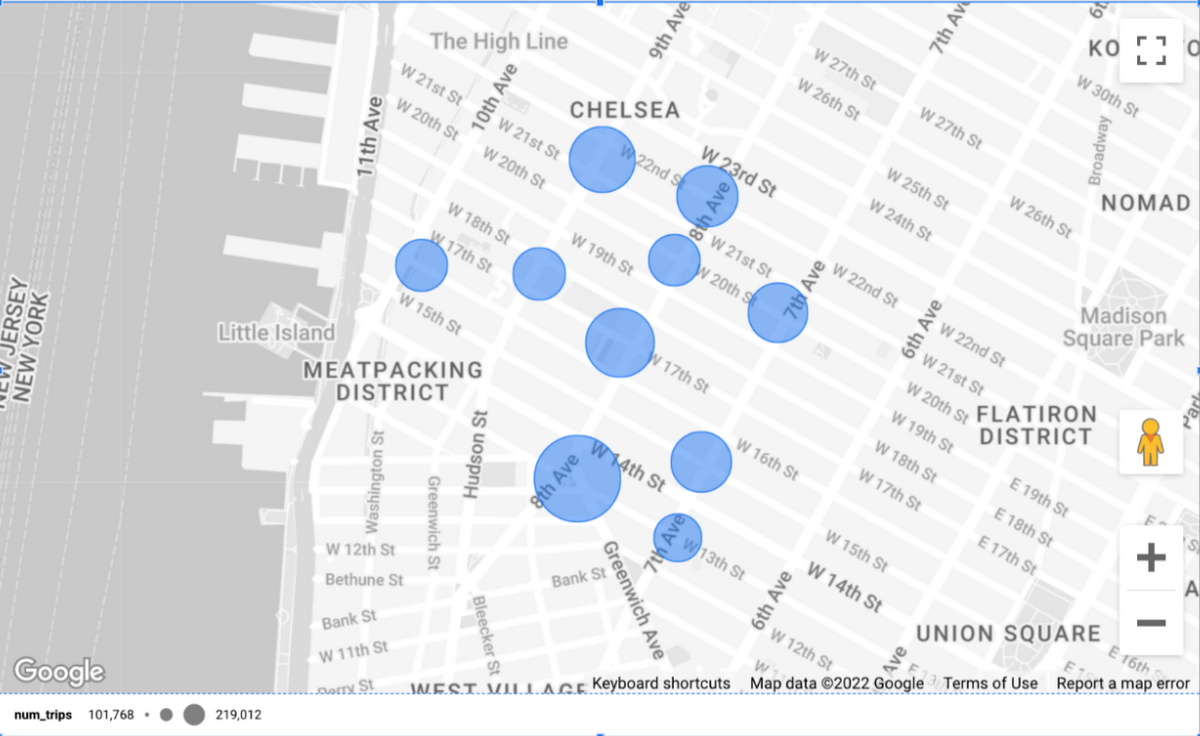
データポータルを自分で使ってみたいという方は、こちらのチュートリアルを参考にすることをおすすめします(同じくシェアサイクルを取り上げていますが、場所はテキサス州オースティンです)。
次のステップ
手順はこれだけです。Google Cloud は習得も使用も簡単なので、「使い始める」ための準備ではなく、データ分析や可視化の設計に時間をかけることができます。個人的な用途だけでなく、プロフェッショナルな技術開発においても、このようなツールの使用には可能性を感じられることでしょう。BigQuery などの Google Cloud ツールを使って、データ サイエンスのスキルや初期のキャリアを構築する方法はたくさんあります。
この投稿記事で学習した内容は、Coursera の From Data to Insights with Google Cloud 専門講座を受講して補完することもできます。
今回の内容は以上で終了です。このブログ投稿が役に立つと感じたら、ぜひ共有してください。Google Cloud Platform ブログでは、さらに役立つコンテンツをご覧いただけます。
- デベロッパーリレーションズ エンジニア インターン Kelci Mensah