サプライ チェーンにおける森林破壊を追跡するディープ ラーニングの概要

Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
サプライ チェーンにおける森林破壊を追跡するディープ ラーニングの概要
はじめに
私の経験上、機械学習でよくあることは、さまざまなアルゴリズムを試行錯誤し、目的の成果が得られるまでテストするプロセスを放棄してしまうことです。Google の同僚と私は ?People and Planet AI(人と地球の AI)という YouTube シリーズで、Google Cloud や Google Earth Engine を使って環境目的でモデルのトレーニングとホストを行う方法について解説しています。私たちの狙いは、ディープ ラーニングの活用を後押しすることです。この動画シリーズに違う名前を付けるとするなら、「AI for Minimalist(最小主義の AI)」とでも呼べそうです。? ユースケースのほとんどで人工ニューラル ネットワークを推奨しているからです。今回のエピソードでは、ディープ ラーニングとは何か、そしてサプライ チェーンにおける森林破壊を追跡するためにどう利用できるかについて概要をご紹介します。また、本ブログでは、2022 年の Geo For Good Summit で発表した誰でも利用できるアーキテクチャとプロダクトの概要にも触れます。コードの詳細にご興味がある方は、エンドツーエンドのサンプルをご覧ください(画面の下部にある [Open in Colab] をクリックすると、ノートブック形式のチュートリアルが表示されます)。
この記事の内容
ディープ ラーニングとは
採掘サプライ チェーンにおける森林破壊を ML で測定
Earth Engine 以外でカスタムモデルを構築する状況
Google Cloud と Earth Engine でモデルを構築する方法
試してみる
ディープ ラーニングとは
世の中に数多くある ML アルゴリズムの中で、ディープ ラーニングや人工ニューラル ネットワークがほぼすべての教師あり学習ジョブに使用できる技術であることは知っていただきたいです。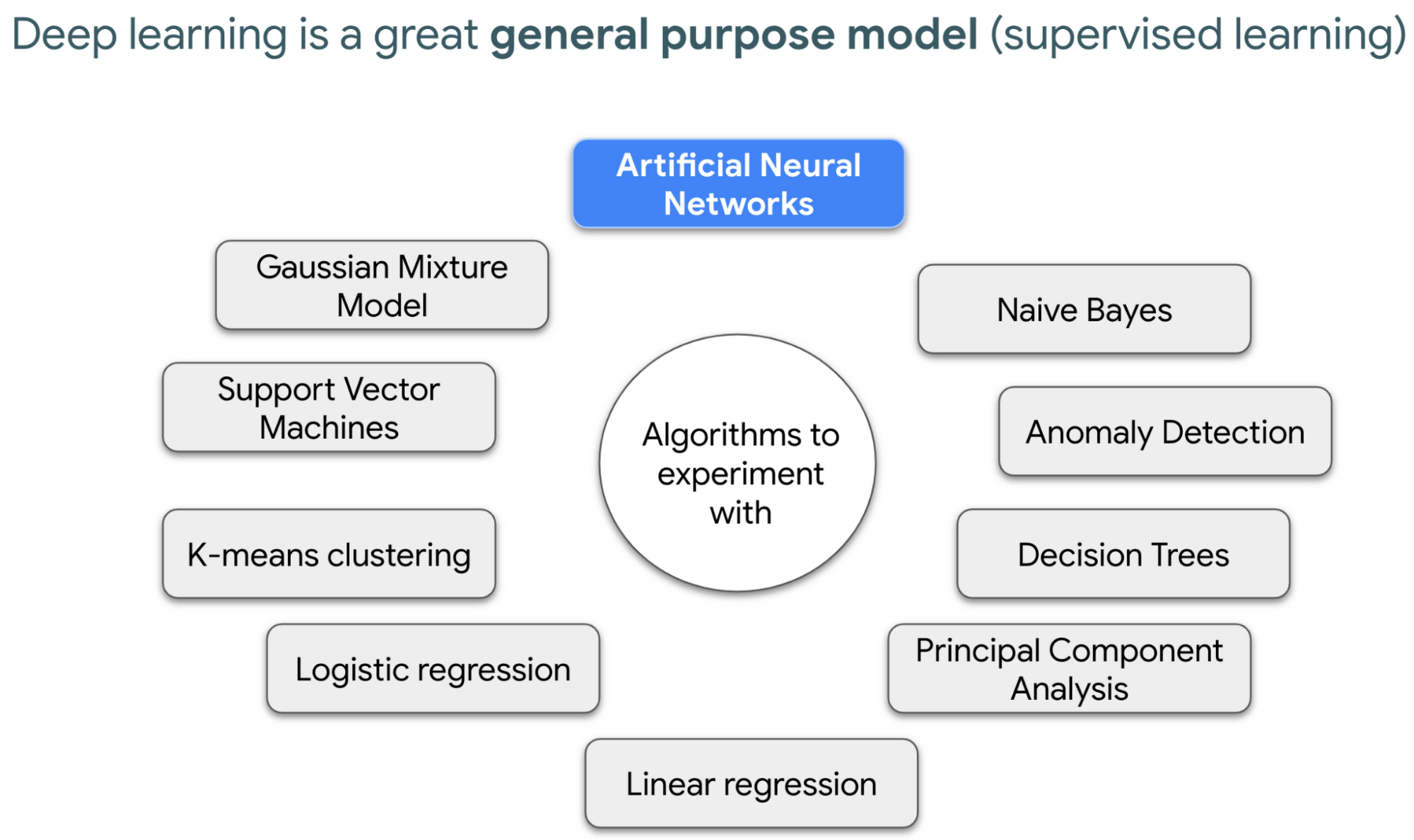
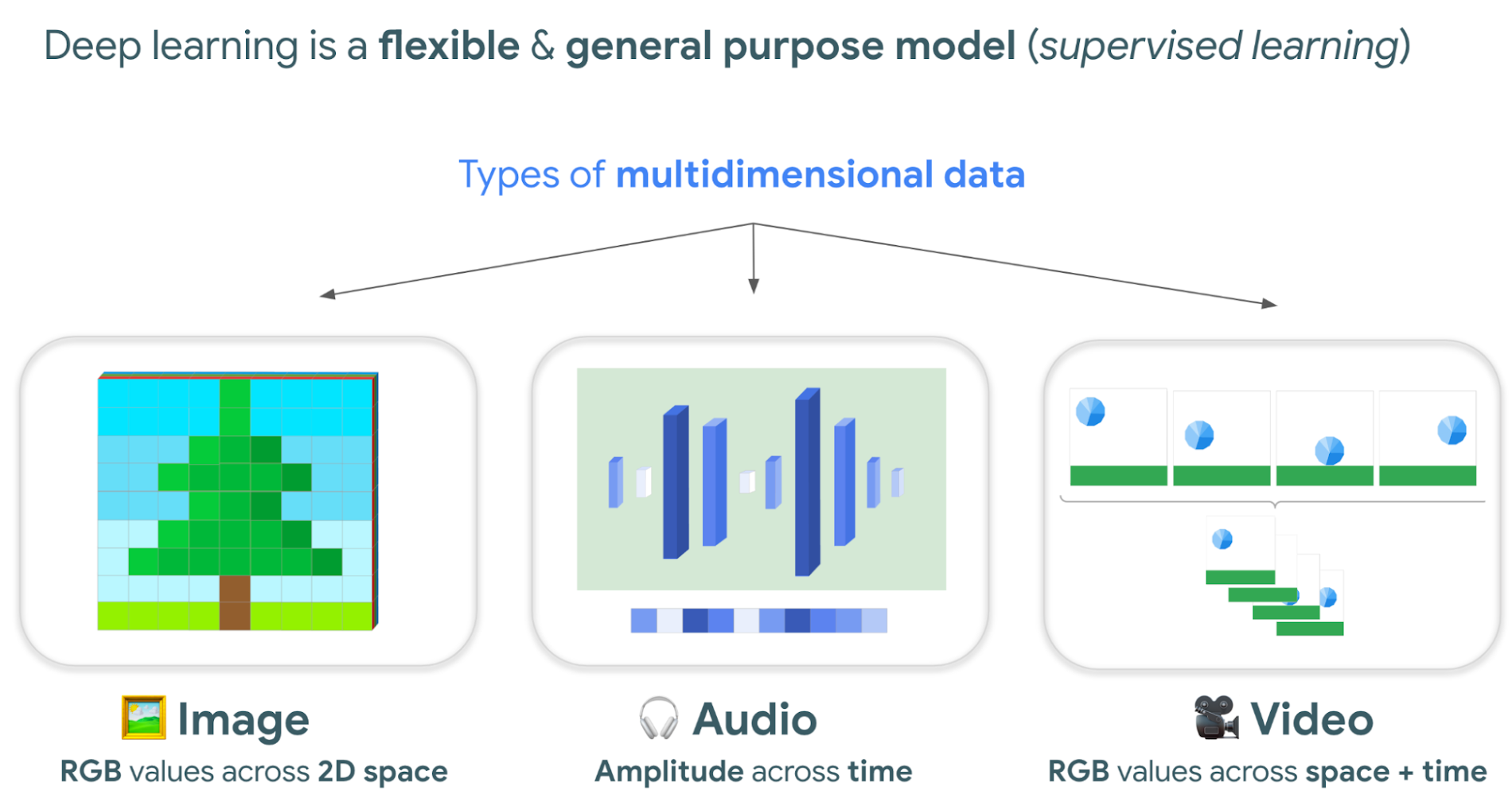
教師あり学習ではサンプルを通じて、求める正解をコンピュータに与えます。ディープ ラーニングは柔軟性に富み、頼りになる優れたアルゴリズムです。特に、多次元データの種類である画像、音声、動画ファイルで真価を発揮します。その理由は、こうしたデータの種類にはそれぞれ、ポイントごとに特定の値を持つディメンションが 1 つ以上含まれるためです。
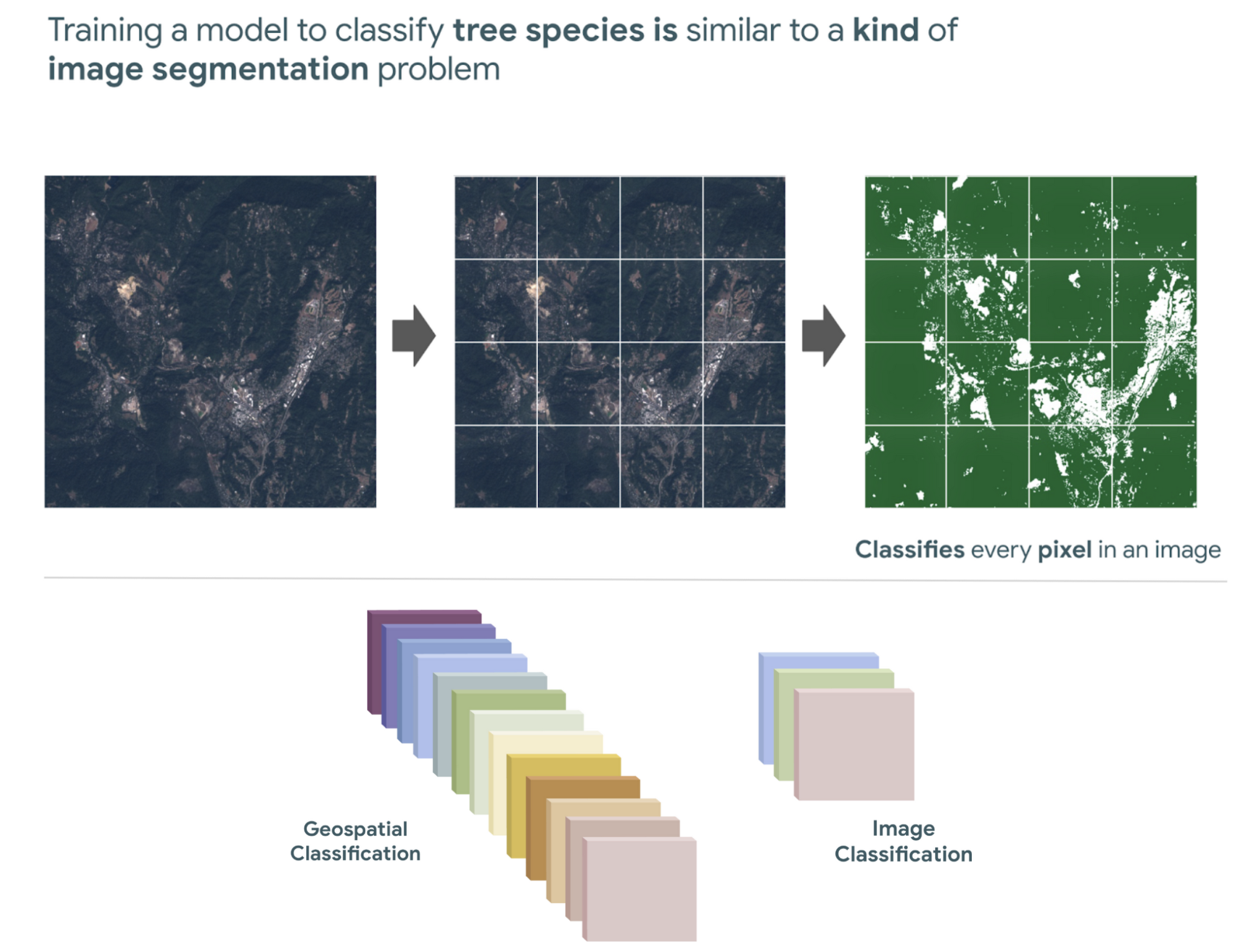
また、衛星画像を使って樹種を分類するモデルをトレーニングすることは、画像のすべてのピクセルを分類する画像セグメンテーションの問題のようなものです。
ディープ ラーニングは異なる方法で問題に取り組む
デベロッパー プログラム エンジニア、David Cavazos
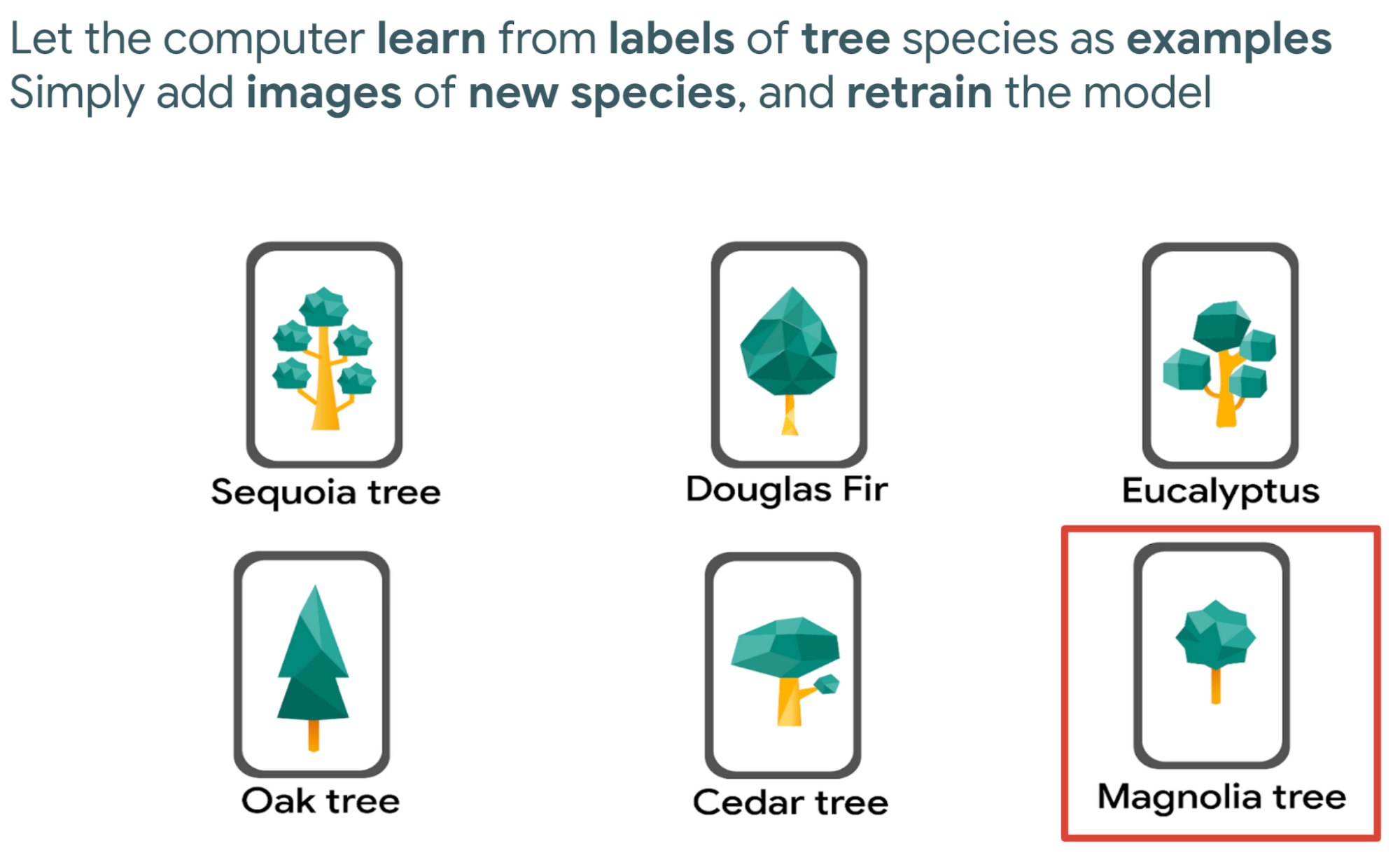
従来のソフトウェア開発のように、あらゆる画像のすべてのピクセルを 1 つずつ確認する明示的で逐次的なステップで機能を作成する必要はありません。樹種を分類するモデルを構築するとします。すべての命令をコーディングするのに時間をかけず、樹種のラベルを付けた画像のサンプルをコンピュータに与え、サンプルからコンピュータに学習させます。さらに樹種を追加したい場合は、その樹種の新しい画像を追加してモデルを再トレーニングするだけです。
採掘サプライ チェーンにおける森林破壊を ML で測定
たとえば、ディープ ラーニングを使用して森林破壊を測定するとします。モデルの構築を開始するには、まず衛星画像を含むデータセットと、樹木がある場所とない場所を示す同じ数のラベルが必要です。次に、目標を選びます。ここでは、一般的な目標をいくつか紹介します。今回の例では、ピクセルごとに樹木があるかどうかを把握したいだけなので、バイナリ セマンティック セグメンテーションの問題になります。
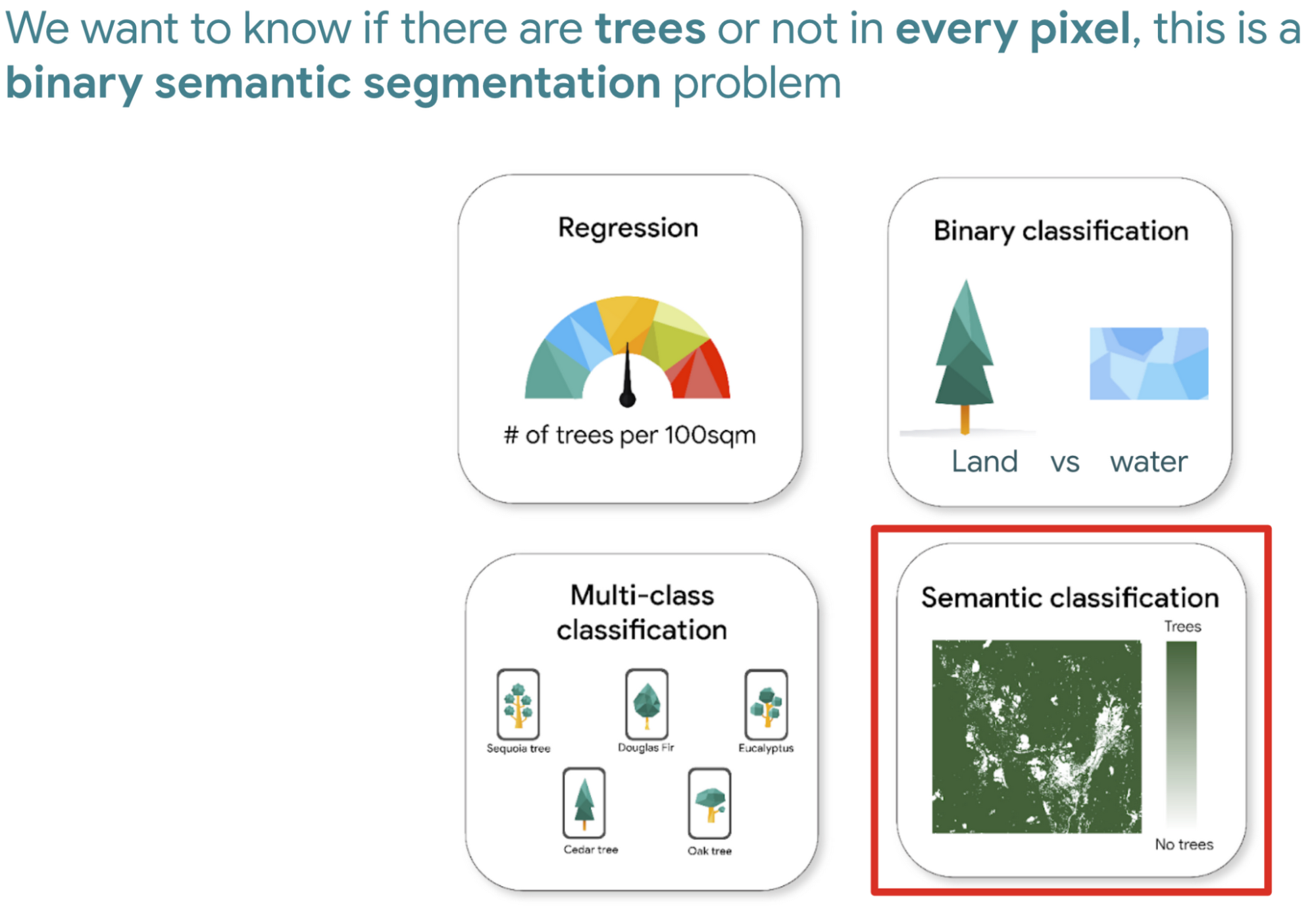
次に、この目標に基づいて、出力はそれぞれのピクセルの樹木の割合(0~1 の数値)になると想定されます。0 は樹木がないことを示し、1 は樹木がある可能性が高いことを示します。

ところで、入力画像から樹木の可能性に移行するにはどうすればよいでしょうか。次のように考えてみたらどうでしょう。この問題にはさまざまなアプローチがありますが、一般的な 3 つの方法を紹介します。同僚と私は ML 予測でマップを構築するとき、完全畳み込みネットワークを優先して使用します。
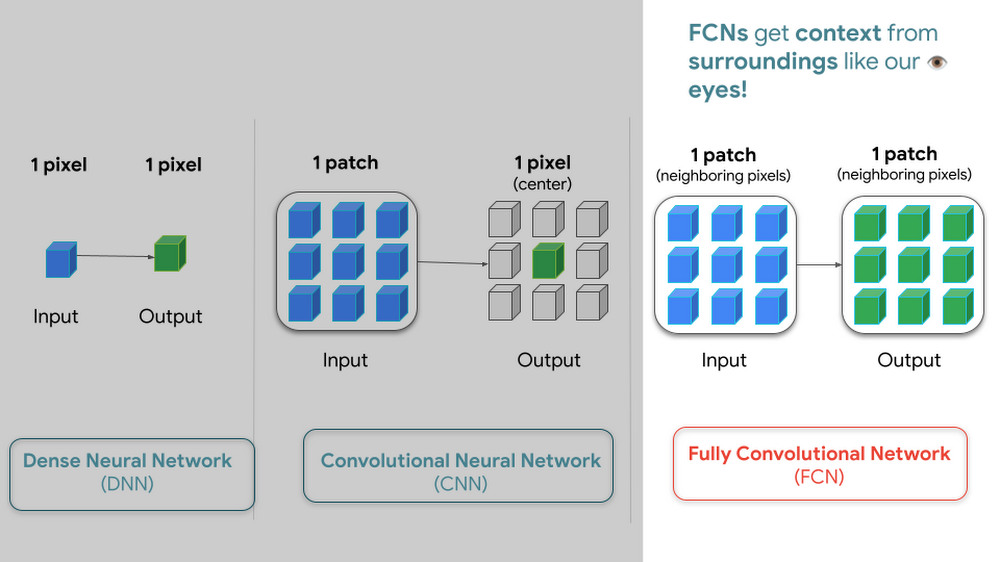
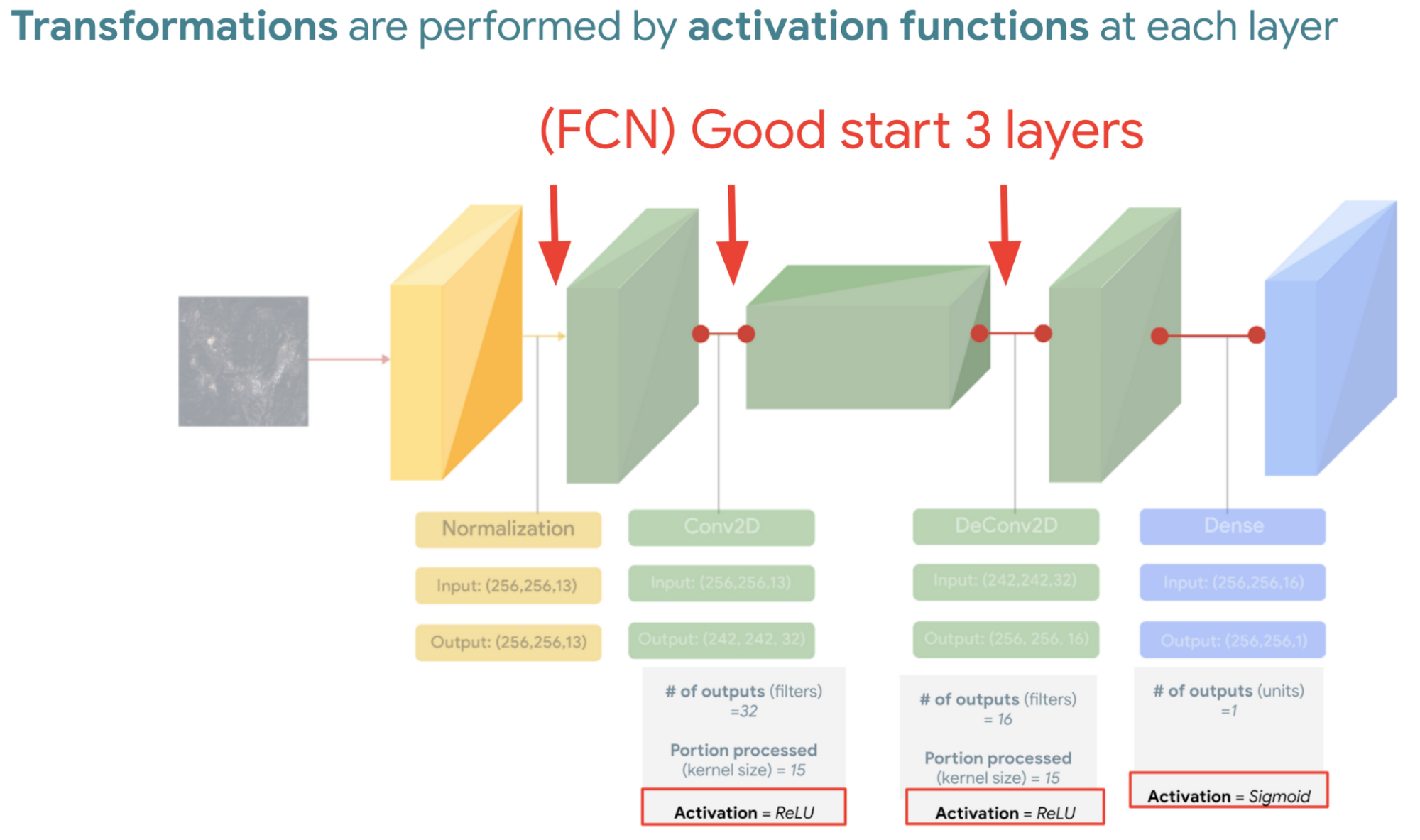
また、モデルは相互接続されたレイヤのコレクションであるため、目的の出力に基づいてデータ入力を変換するレイヤの配置を用意する必要があります。なお、各レイヤには活性化関数というものがあります。この関数は各レイヤの変換を実行してから次のレイヤに渡します。
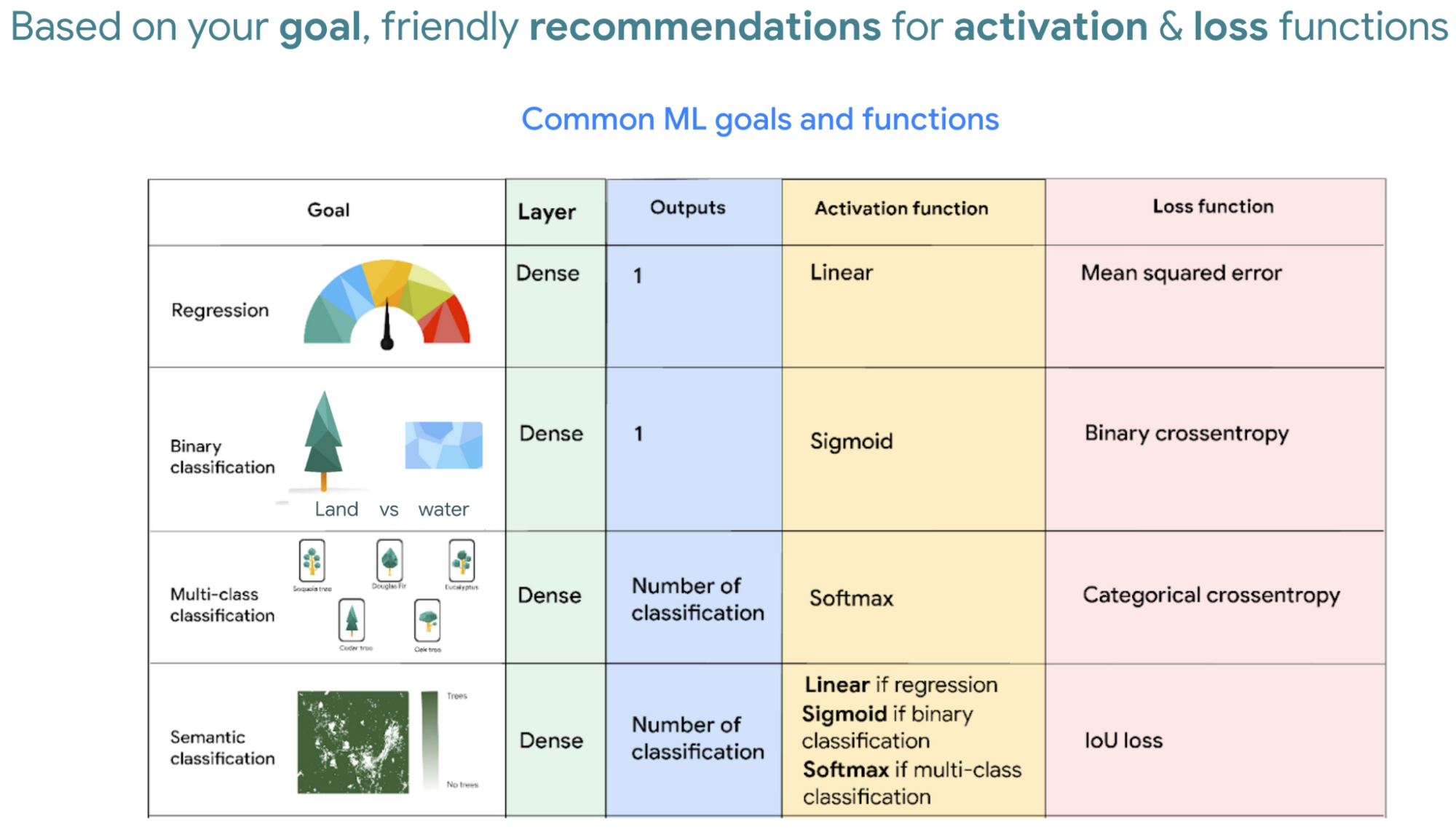
ご参考までに、推奨される活性化関数と損失関数を記載した便利な早見表を以下に示します。目標に応じて選択してください。時間の節約になれば幸いです。
次に、4 番目にして最後のレイヤの説明に入ります。最初の目標に応じて適切な損失関数も選択し、トレーニング時のモデルの効果をスコアリングしましょう。
レイヤと関数を選択したら、データをトレーニング データセットと検証データセットに分割します。この作業はすべて、目的の結果が得られるまで繰り返しテストすることが大切であると覚えておいてください。詳細については、8 分間のエピソードをご視聴ください。
Earth Engine 以外でカスタムモデルを構築する状況
ディープ ラーニングの概要について理解できたところで、今度は森林破壊モデルの構築で使用するツールについて説明します。まず、ここで重要な点を挙げると、Google Earth Engine は優れたツールで、あらゆる規模の組織が気候にプラスの影響を与えるために、地球上の変化に関する分析情報を見つけられることです。Google Earth Engine には機械学習アルゴリズム(分類器)が組み込まれており、ユーザーは機械学習の基礎知識さえあれば、すばやくこれらのアルゴリズムを起動できます。地理空間データで ML を使用する場合、手始めには Earth Engine が最適ですが、次のようなカスタムモデルの構築が必要な状況は複数存在します。
TensorFlow Keras などのよく使用されている ML ライブラリを使用したい。
最先端のモデルを構築して、Google の Dynamic World のようなグローバルで正確な土地被覆地図プロダクトを作成したい。
処理するデータがほとんどの場合に多すぎて、Earth Engine の 1 つのタスクだけでは実行できないため、データをエクスポートする解決法を見つけたい。
上述のいずれかに共感したのであれば、専門知識や複数のプロダクトでの作業が必要だとしても、気合を入れてカスタムモデルの構築に飛び込みたくなるでしょう。ここで朗報です。ディープ ラーニングの使用は、頼りになる優れたアルゴリズムになります。
Google Cloud と Earth Engine でモデルを構築する方法
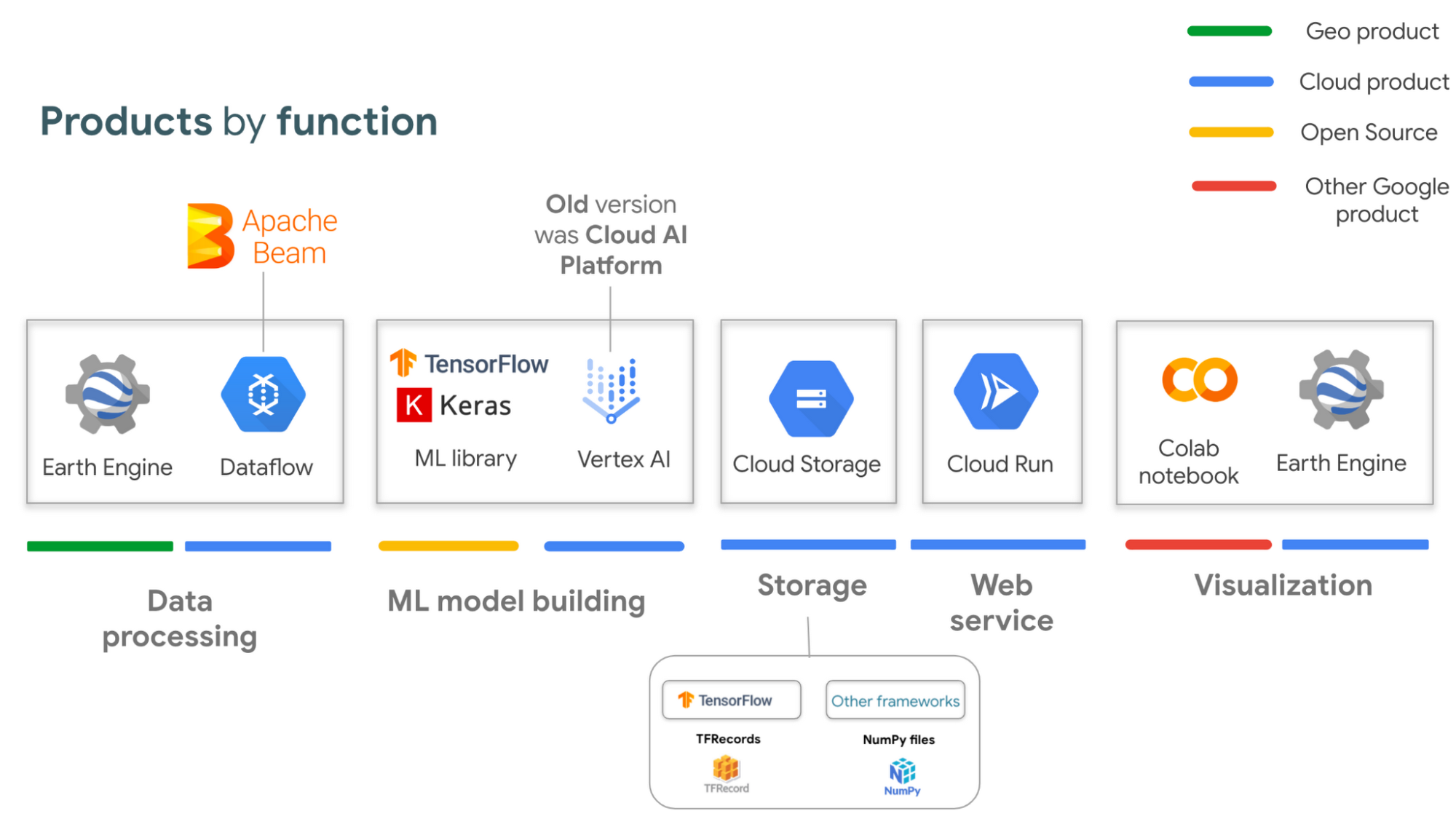
ご利用を開始するには、Google Earth Engine のアカウント(非営利団体の場合は無料)と、Google Cloud アカウント(ご利用を開始する場合、すべてのユーザーに無料枠あり)が必要です。使用するプロダクトを機能別に分けました。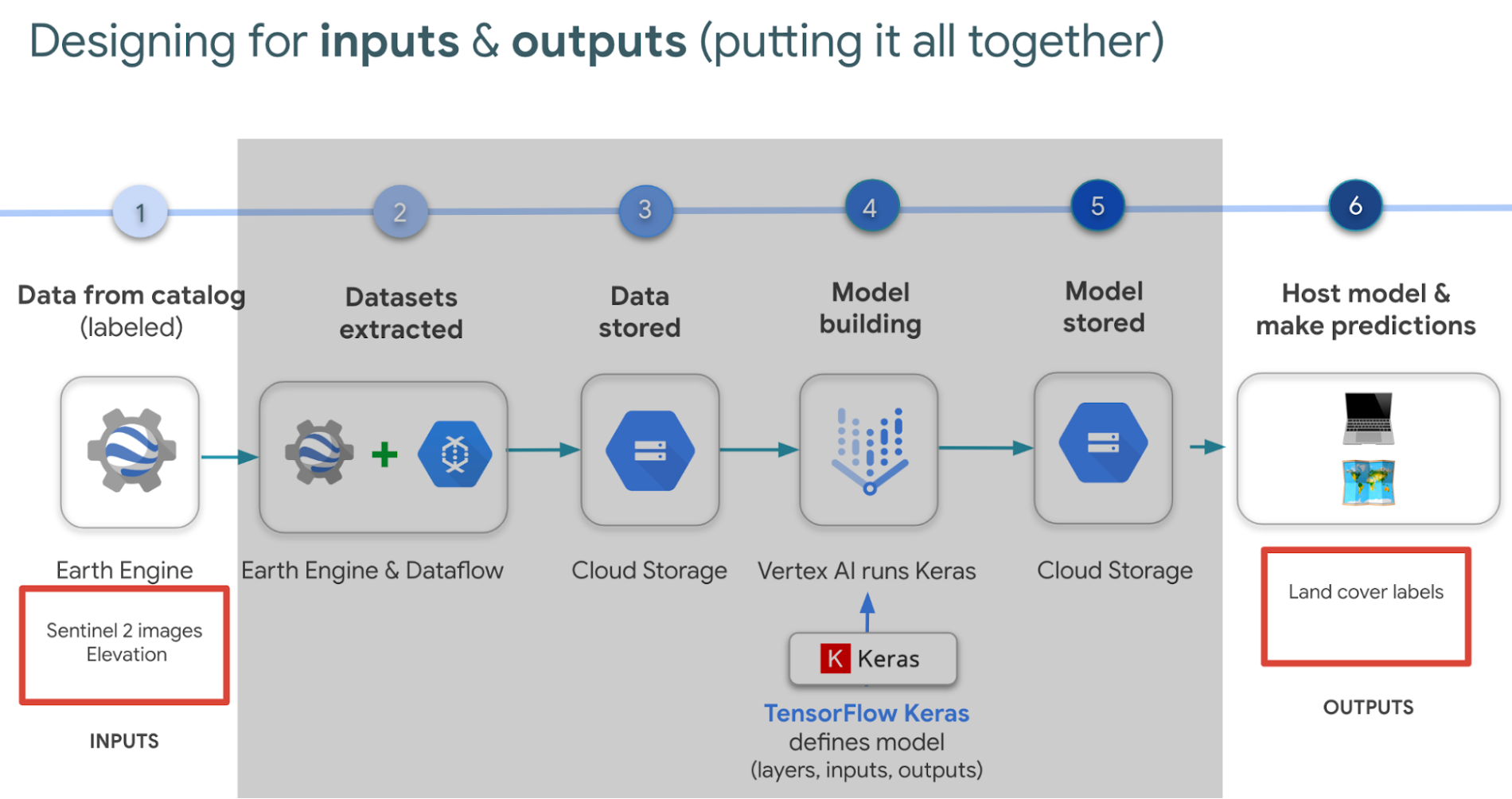
この概要の詳細についてご興味がある場合は、こちらのプレゼンテーションにアクセスし、スライド 53 からスピーカー ノートも含めてご確認ください。また、コードサンプルでは、こういったすべてのプロジェクトをエンドツーエンドで統合する方法についても説明しています(下へスクロールして [Open in Colab] をクリックするだけです)。ここでは、簡単な図解サマリーを紹介します。どれが入力でどれが出力かを識別することが先決です。
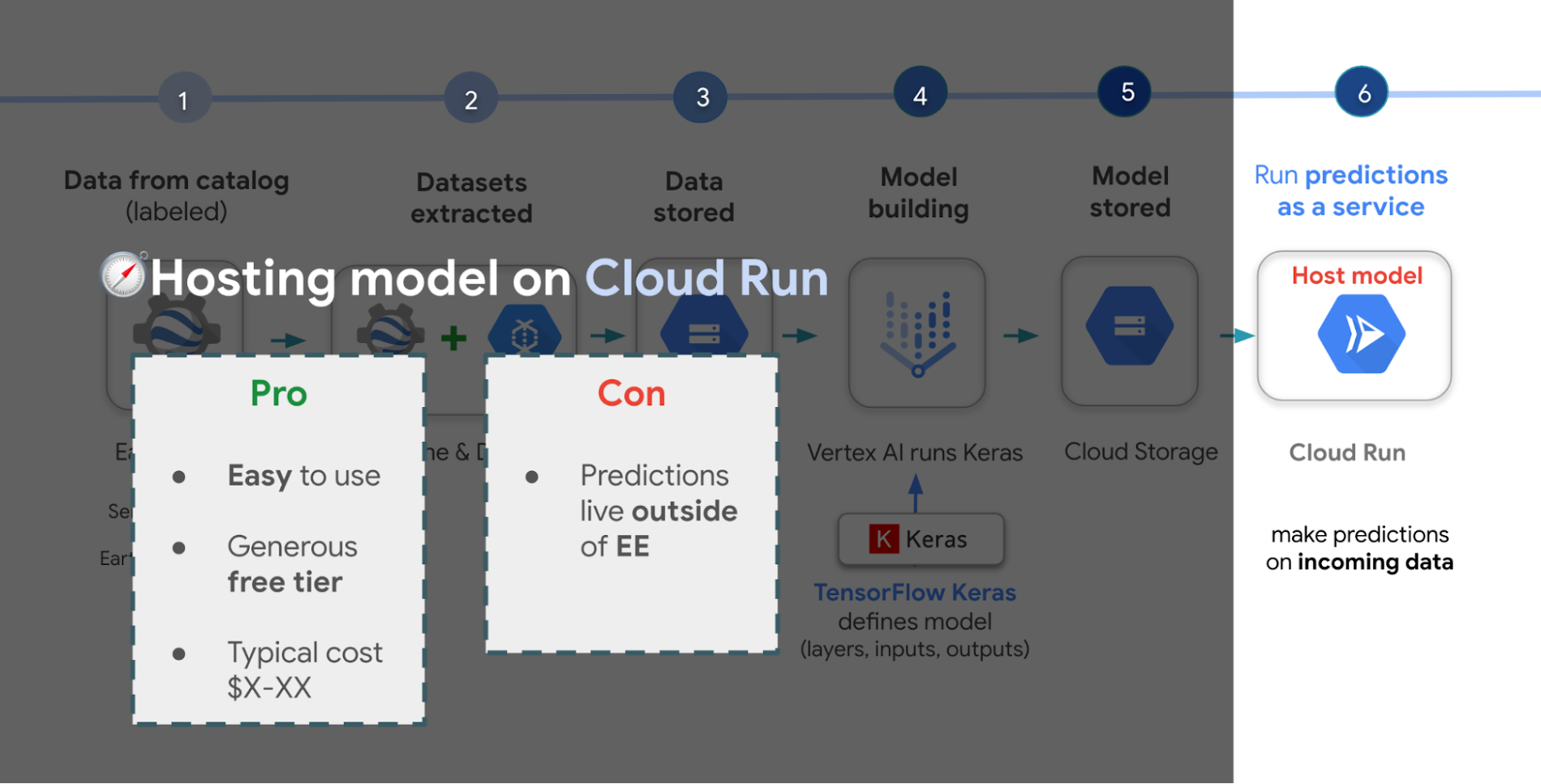
YouTube シリーズの People and Planet AI の最新エピソードでは、モデルをトレーニングし、Cloud Run という比較的低価格なウェブ ホスティング プラットフォームでホストする方法を説明しています(視聴時間は 10 分未満)。
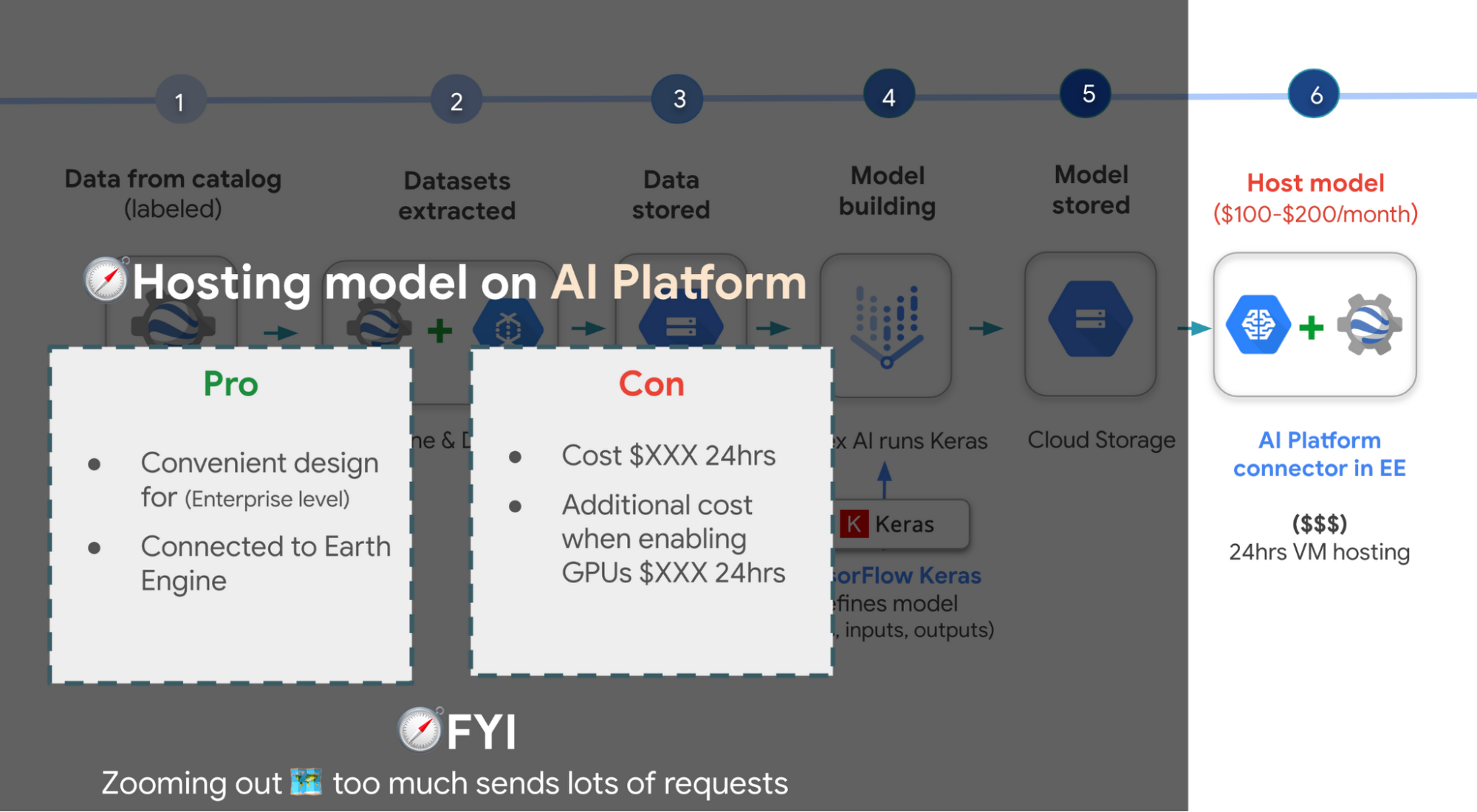
こちらのスライドには選択肢がいくつか示されているものの、現在のベスト プラクティスは Vertex AI を利用してモデルをトレーニングすることです。ただし、Google Earth Engine は現在 Vertex AI と統合されていませんが(統合に向けて取り組み中です)、以前のプロダクトである Cloud AI Platform(前身の ML、今後使用が推奨される ML プラットフォーム)とは統合されています。このため、Vertex AI などでトレーニングした後、森林破壊を検出するモデルを Earth Engine にインポートし直す場合、Cloud AI Platform でモデルをホストして予測を取得できます。これは 24 時間の有料サービスであるため、モデルをホストして予測をストリーミングするには、毎月 100 ドル以上の費用がかかる可能性があることにご注意ください。TensorFlow を使用しない場合は、次のモデル構築プラットフォームもご利用いただけます。
AI Platform のような利便性がないものの費用を抑える別の方法は、モデルの出力(NumPy 配列)を Cloud Optimized GeoTIFF に手動で変換し、Cloud Run を使用して Earth Engine に読み込むことです。このウェブサービス内で NumPy 配列を Cloud Storage バケットに保存します。次に、オープンソースの地理空間ライブラリである GDAL を使用してコンテナ イメージをスピンアップし、Cloud Optimized GeoTIFF ファイルに変換して Cloud Storage に保存します。このようにして、ブラウザまたは Earth Engine から予測を表示できます。
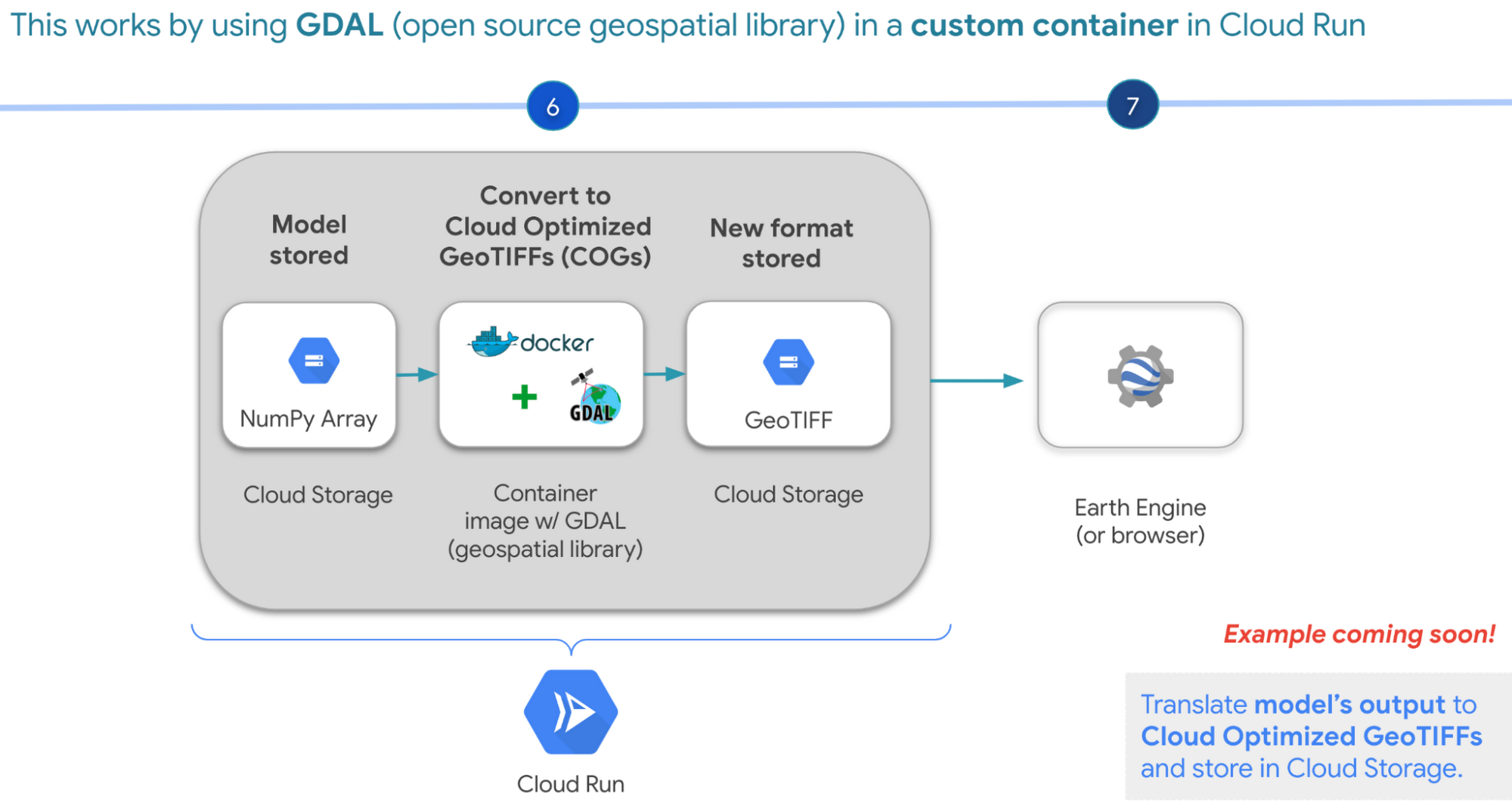
試してみる
今回はディープ ラーニングと、いくつかの Cloud プロダクトについて概要をお伝えしました。上述の Cloud プロダクトは、採掘サプライ チェーンにおける森林破壊の検出など、深刻な環境問題を解決するために使用できます。使用するには、こちらのコードサンプルをご覧ください(画面の下部にある [Open in Colab] をクリックしてノートブック形式のチュートリアルを表示するか、こちらのショートカットをクリックしてください)。
- Geo for Environment 担当デベロッパー アドボケイト Alexandrina Garcia-Verdin



