AI による気候変動と土地の変化の測定
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。

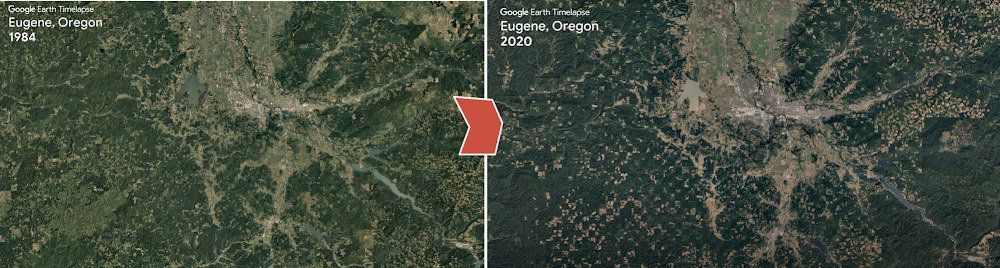
もし仮に地球が 1 週間前、1 か月前、1 年前からどのように変化しているかを自動的にほぼリアルタイムで示すことができるデータセットがあれば何ができるか、想像してみてください。そうなれば、数日前に起こった洪水、火災、大吹雪などの最近の出来事を俯瞰的に見る目が得られ、地球表面の季節的変化を世界的規模で特定し、再生ソリューションによる修復を実現できるでしょう。
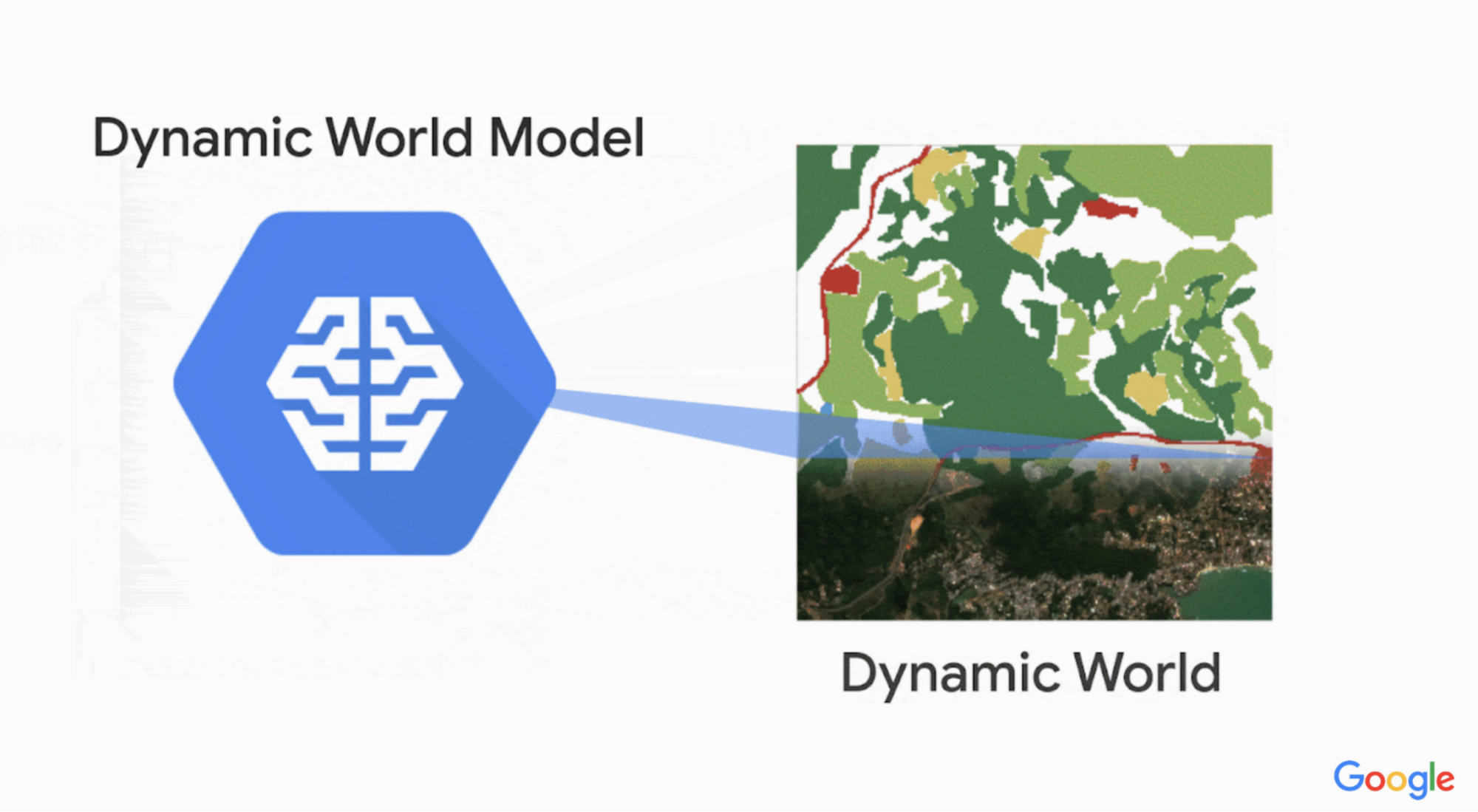
これを可能にする Dynamic World というプロジェクトがあります。このプロジェクトは、自由に使用可能な 10 m 四方の土地被覆データセットをほぼリアルタイムで提供するもので、毎日 5,000 点以上の画像を生成しています。これは、今日までに作成された地球規模の土地被覆データセットとしては最大級のもののひとつで、雲被覆率が 35% 以下の Sentinel-2 シーンについて、ピクセルに基づく確度を提供します。
歴史的に見て、地球表面に現在存在するもの(土地被覆とも呼ばれます)の最新状態をタイムリーに反映するグローバルに一貫したデータセットは存在していませんでした。衛星画像の登場で人々は地球の変化を観察できるようになり、土地被覆データは地表面で起こっている変化を定量化する手段となりました。Dynamic World で使用されている土地被覆の種別は、木、作物、市街地、水生植物、裸地、雪 / 氷、低木 / 低灌木、水、草地です。

?️ 土地被覆分類の自動化
Dynamic World では、Google Earth Engine、AI、Google クラウド コンピューティングを使用して地球の画像を土地カテゴリに分類しています。その結果得られる土地被覆データセットは、ピクセルに基づくさまざまな土地被覆種別の確度を示し、これは現実世界をより正確に表現します。過去の土地被覆データセットでは、1 ピクセルに対して割り当てられる土地被覆分類は 1 つだけでした。今日では、情報の詳細度がはるかに向上し、それを基に最終的な地図が作成されています。
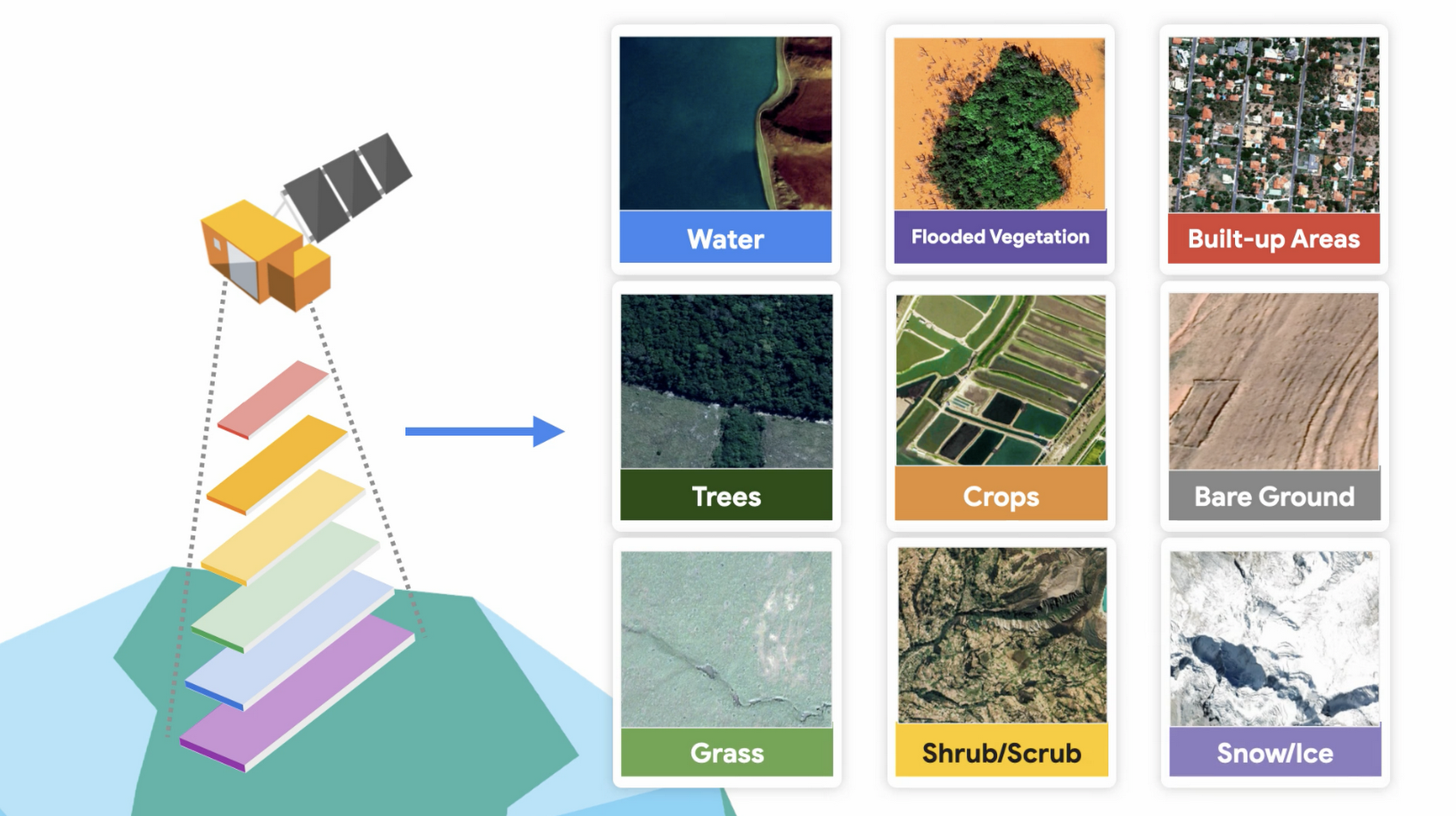
Copernicus Sentinel 2(欧州宇宙機関の人工衛星群)のデータを自由に使用できるおかげで、1 ピクセルは 10 m × 10 m という驚くほど細かい範囲を示します。Dynamic World は、Google と World Resource Institute のパートナーシップによって生まれました。
Google Earth Engine ユーザーの方は、dynamicworld.app で Dynamic World を探索できます。画像コレクションを Earth Engine のコードエディタで GOOGLE/DYNAMICWORLD/V1 として読み込んでみてください。非商用ユーザーの場合、Earth Engine アカウントの作成に料金はかかりません。
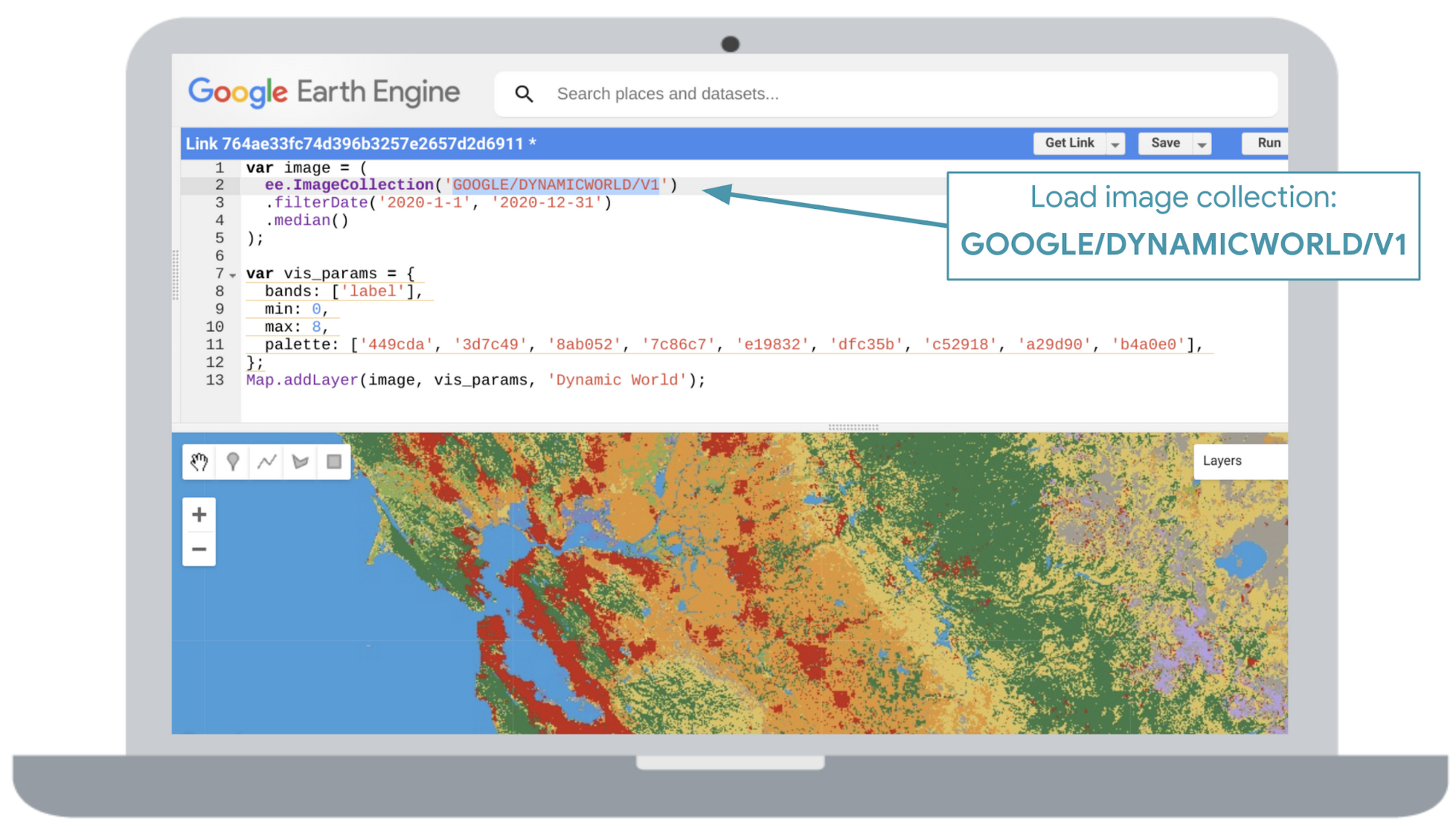
また、カスタム ウェブアプリでデータを可視化することもできます。このアプリのインターフェースを使用して場所で検索し、目的の日付範囲を選択します。特定のエリアをクリックすると、そのエリアのモデルの分類信頼度がグラフで示されます。グラフのいずれかのポイントをクリックすると、そのポイントに対応する、その日の土地被覆分類の推測に使用された Sentinel-2 の画像が表示されます。また、地図のレイヤを衛星、地形、Google マップの基本地図などの間で切り替えることもできます。
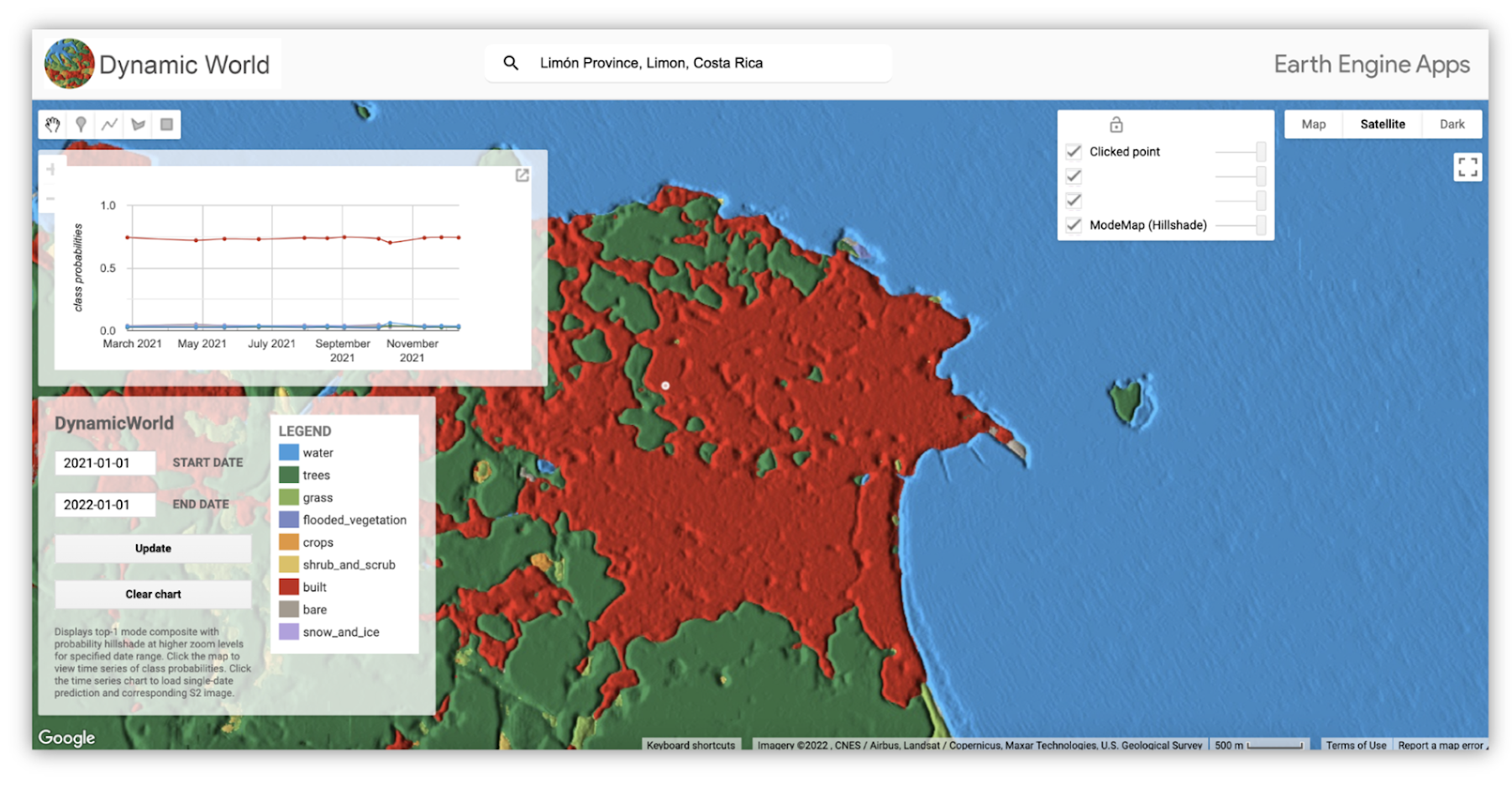
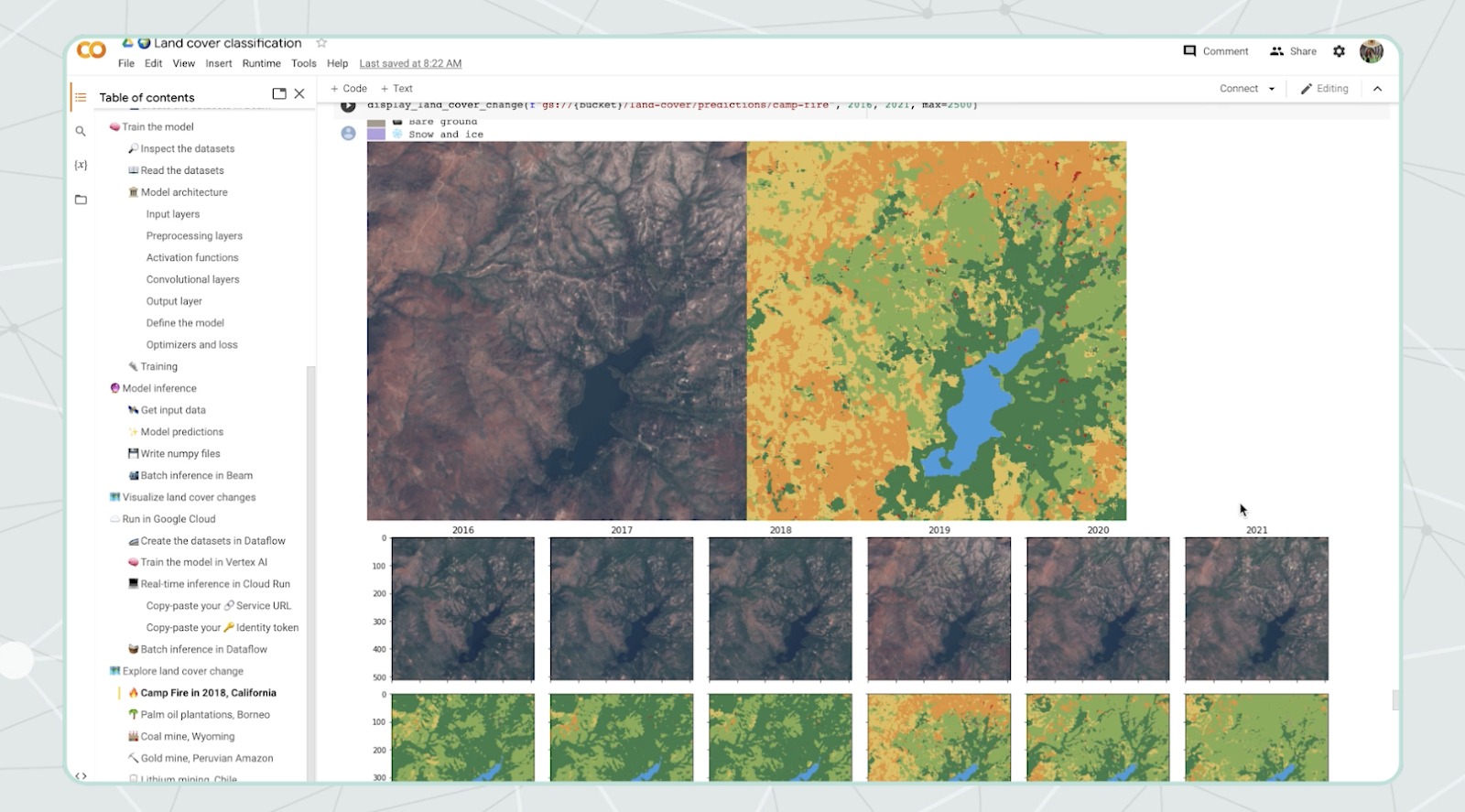
次に、山火事の後の森林損失を見る方法の例を示します。カリフォルニア州チコの東部にある 300,000 エーカーの美しい森林が焼失し、ほんの数日で分類が「灌木地」に変わった様子を可視化します。
これは、Google Cloud と Earth Engine で構築されたパワフルなサステナビリティ プラットフォームです。毎年手作業のキュレーションによって作成されている静的な地図よりも柔軟性が高く、分析情報がよりタイムリーに得られます。このほぼリアルタイムの土地被覆データセットの中核的な目的は、自然生態系を保護、管理、復元するより賢明な方法を見出すために、組織に派生的な地図を作るよう促すことにあります。
本プロジェクトのチームは、このデータが NGO、学会、企業部門、既存の土地被覆データセットのユーザーによって農業、土地利用計画、環境保護などの気候関連の研究に使用されることを期待しています。このデータセットは、公的領域でのモニタリング、予測、意思決定を支援するために生成されています。
この素晴らしいプロジェクトに触発された私たちデベロッパーリレーションズは、People and Planet AI シリーズにおいて、このデータ分析と AI の問題にアプローチする方法を探りました。このプロジェクトでは、さまざまなソースから入手した数多くのデータセットを組み合わせ、地球全体のラベルを計算する必要があります。読者の皆様には Dynamic World のデータセットとアプリを使用することをおすすめしますが、Dynamic World のような軽量なモデルの構築に着手する方法を知りたい場合は、この記事をさらに読み進めてください。地理空間マルチクラス分類モデルとは、「衛星画像からさまざまなものを分類するモデル」を専門的に言い換えたものです。この技術について理解を深めるには、こちらの 10 分の YouTube 動画を視聴し、さらにこちらのインタラクティブ ノートブックですべてのコードを読むこともおすすめします。また、Dynamic World の GitHub も参考になります。
?️ 地理空間マルチクラス分類モデルの構築
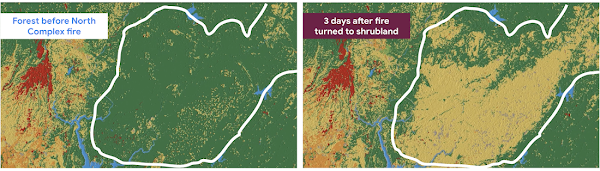
以下にアーキテクチャ図を示します。このソリューションを実行する費用は(この英語版投稿が掲載された時点で)わずか $1 です。
まず、地球を分類するモデルのトレーニングに使用する土地被覆データセットを特定します。Earth Engine のカタログを見ると、すでにいくつかのデータセットがホストされています。私たちが選んだのは European Space Agency World Cover でした。このデータセットは、カタログの検索バーで「land cover」を検索して見つけました。このデータセットに含まれる土地カテゴリは 11 種類ありますが、Dynamic World と同様にそのうち 9 種類だけを使用します。その他に、Dynamic World のトレーニング データを使用する方法もあります。このデータにはこちらから自由にアクセスできます。また、この LUCAS データセットから EU トレーニング データセットを抽出することも可能です。
さらに、標高データなどの多くのデータセットをデータ入力として使用する必要があります。簡単にするため、私たちは Sentinel 2 の大気圏上部データセットから取得した地球の画像のみを使用しました。検出された雲を除去する関数も必要です。幸いなことに、雲を消すための汎用的なソリューションがあるため、多くの人がそれらの関数をコピーして使っています。私たちは簡易版を作成しました。
People and Planet AI シリーズで衛星画像データを扱う際は、畳み込みニューラル ネットワーク(CNN)を主要な ML 手法として使用しています。その理由は、CNN は人間の目のように働き、画像を分析して周囲から自動的にパターンを検出するからです。
次に、入力と出力の形状を理解する必要があります。衛星は、電磁スペクトルからさまざまな波長(周波数帯)を観測します。この例での入力は、幅、高さ、周波数帯の数の 3 つの次元を持ちます。
出力は、各ピクセルパッチの分類の確度です。この例では 9 つの分類ラベルを使用するため、値は 9 つあります。それぞれの値が、地球上のある特定の表面種別である確度を示します。出力された確度のうち最も高いものを最終ラベルとして選択します。
次に、Dataflow(Google Cloud のデータ処理サービス)と Earth Engine の ee.image.getDownloadURL 関数を使用します。これらを連携させることで、ランダムにシャッフルされたバランスの取れたデータセットが作成されます。これにより、モデルのバイアスが最小限に抑えられます。
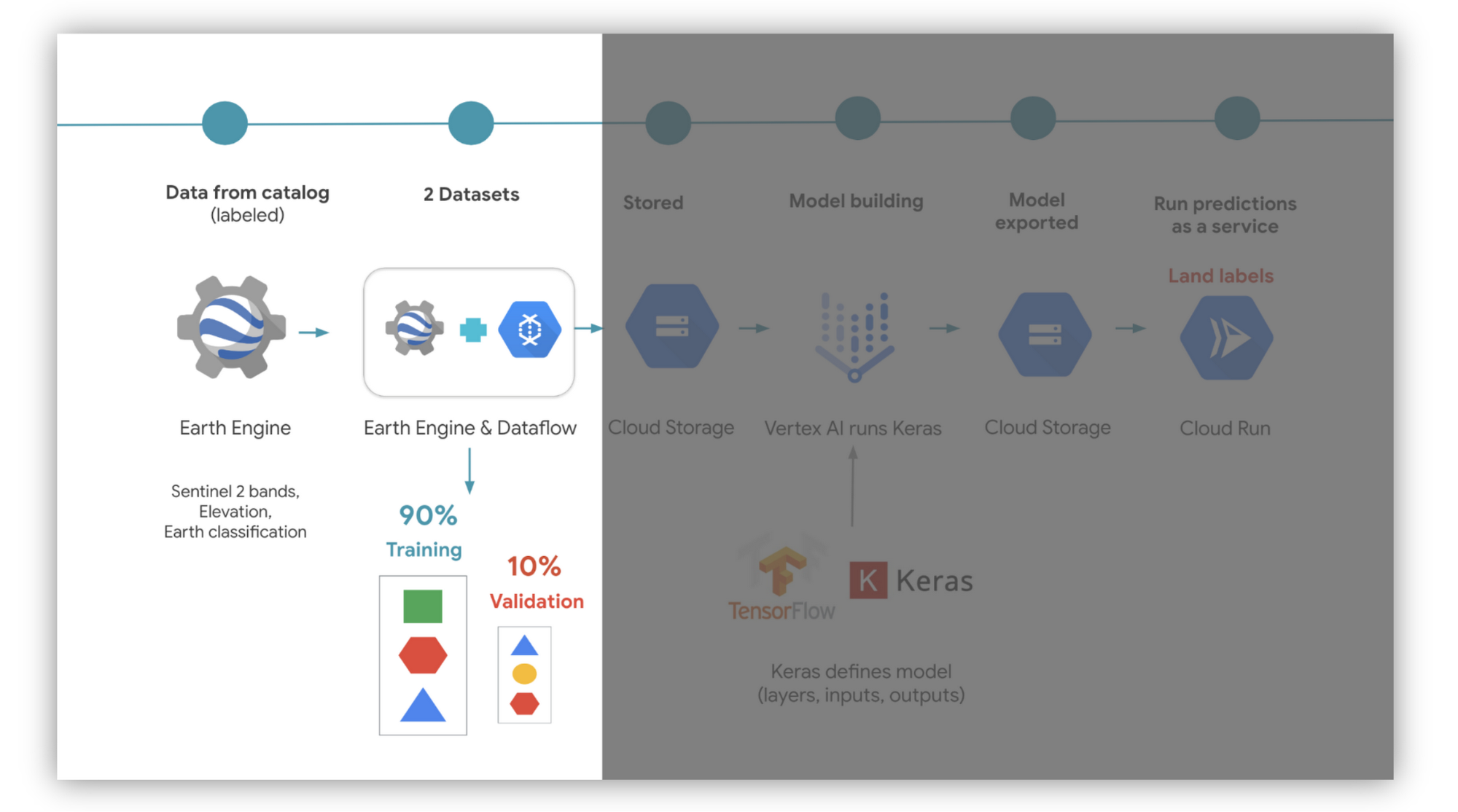
このデータをどのように配分して 2 つのデータセットを構築するかを決めます。ひとつはトレーニング用、もうひとつは検証用です。私たちの例では、データをそれぞれ 90:10 の比率で分割し、両方のデータセットで同じデータポイントが共有されないようにしました。Earth Engine は、データセットを TFRecords という形式で Google Cloud Storage にエクスポートします。これは TensorFlow(ML ライブラリ)向けに最適化されたファイル形式です。
この段階で、TensorFlow を使用してモデルをトレーニングする準備はできました。次に、Cloud Storage からトレーニング データセットを読み取るステップに進みます。モデルの定義は、Tensorflow Keras(TensorFlow に対する高レベル API またはインターフェース)を使用して Python で行いました。検証データセットは、モデルがそれまでに遭遇したことがないデータに対する予測を確認するために使用します。モデルのトレーニングには、Vertex AI のカスタムモデル用に事前にビルドされたコンテナを使用しました。このコンテナには TensorFlow が含まれており、トレーニングを高速化するために GPU を使用できます。
この部分では、トレーニング データセットを何度も繰り返し再トレーニングする必要があります(シャッフルされているため、順序のバイアスはありません)。モデルは毎回トレーニング データセット全体のトレーニングを行います(これをエポックと呼びます)。10 回のエポックを試した後、精度スコアがどう変化しているか(つまり、表面種別がどれだけ的確に分類されるようになったか)を確認します。また、どれだけの期間モデルをトレーニングするかも検討します。
満足の行くトレーニング結果が得られたら、モデルを再び Cloud Storage に保存します。
モデルによる ? 予測の実行
? 新しい画像のオンライン予測サービス
次に、Cloud Run でモデルをホストします。これを使用して、地球の受信画像を分類できます(トリガーを作成します)。Vertex AI でモデルをホストすることもできますが、このユースケースでは Cloud Run のほうが適していました。その理由は、VM を常時稼働させる必要がないからです。(VM を 24 時間稼働し続けるのではなく)必要なときにだけコンピューティング リソースを使用することで、コンピューティング費用が低減し、VM を稼働させる電力による二酸化炭素排出量も削減できます。
? データセット全体に対するバッチ予測
Dataflow を使用して、画像データセット全体に対する予測をバッチで行うこともできます。これは、モデルを更新して過去のすべてのデータを分類し直す場合に役立ちます。その後、Cloud Run を並列で使用して新しい画像に対する分類を行うこともできます。このようにするのは、モデルを変更しない限り、いったん分類した画像を同じモデルで再度分類する必要はないためです。
? 分析情報の可視化
得られた結果を便利で実用的なツールに変えるため、私たちは Google Colab のようなインタラクティブ ノートブックを利用しています(私たちのサンプルがそこでホストされています)。そこで、Python ライブラリを使用して年ごとの地球の変化を示す視覚的な地図を作成できます。ビジュアルは、静的な画像や GIF などにすることができます。
自分たちにとって重要な特徴が特定されたら、カスタム ウェブアプリを作成し、影響を受けた総マイルの地図、グラフ、タイムラプス、スコアカードなどを表示できます。また、GIF や画像を Cloud Storage に保存し、そこから定期的に Google スライドを自動生成することも可能です。
✏️ 試してみましょう
ある程度の Python の知識があり、実装に関する注意事項についてもっと詳しく知りたい場合は、こちらのインタラクティブ コードサンプルをご覧ください。ここでは、ML Adam オプティマイザーや Softmax をモデルの信頼度の評価に使用する理由などを取り上げています。また、アカウントをお持ちの場合は、皆様自身の Google Cloud プロジェクトでこれらのリソースをライブで実行することもできます。ただし、リソースを実行した後は、余計な費用がかからないようにするため、これらのリソースを削除することをおすすめします ?。また、Dynamic World の GitHub を見たいときは、こちらをご覧ください。
私たちの他のエピソードにもご興味をお持ちの場合は、Twitter で @open_eco_source をフォローするか、こちらの YouTube プレイリストをご覧ください。
また、2022 年 6 月 28 日午前 9:00~11:40(太平洋標準時)にバーチャルで開催される Google Cloud Sustainability Summit にもぜひご参加ください。これは最新のテクノロジー ムーンショットを発見できるイベントです。
- Cloud デベロッパー アドボケイト Alexandrina Garcia-Verdin



