Spanner と BigQuery を連携させてトランザクションと分析のワークロードを処理する方法
Google Cloud Japan Team
※この投稿は米国時間 2022 年 3 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
お客様のニーズに合わせてビジネスの規模が拡大するにつれ、ビジネス目標を達成するためにデータを収集、管理、分析する効率的なプロダクトに対するニーズも高まります。マルチプレーヤー ゲームを構築する場合でも、グローバルな e コマース プラットフォームを構築する場合でも、強整合性を持たせて大規模にデータの保存とクエリを行い、分析のために処理することで、リアルタイムの分析情報が得られるようにすることが重要です。
このブログでは、Cloud Spanner と BigQuery がいかに理想的な組み合わせであるかということと、併用することでトランザクションを大規模に処理し、リアルタイムの分析情報を生成して、優れたカスタマー エクスペリエンスを実現できるということについて説明します。また Cloud Spanner と BigQuery の使用で、お客様は、比類のないスピード、スケール、セキュリティを備えた、データドリブンの変革へのオープンな統合アプローチである Google Cloud を使用して、データクラウドを構築することができます。
業界屈指のスピード、スケーラビリティ、信頼性
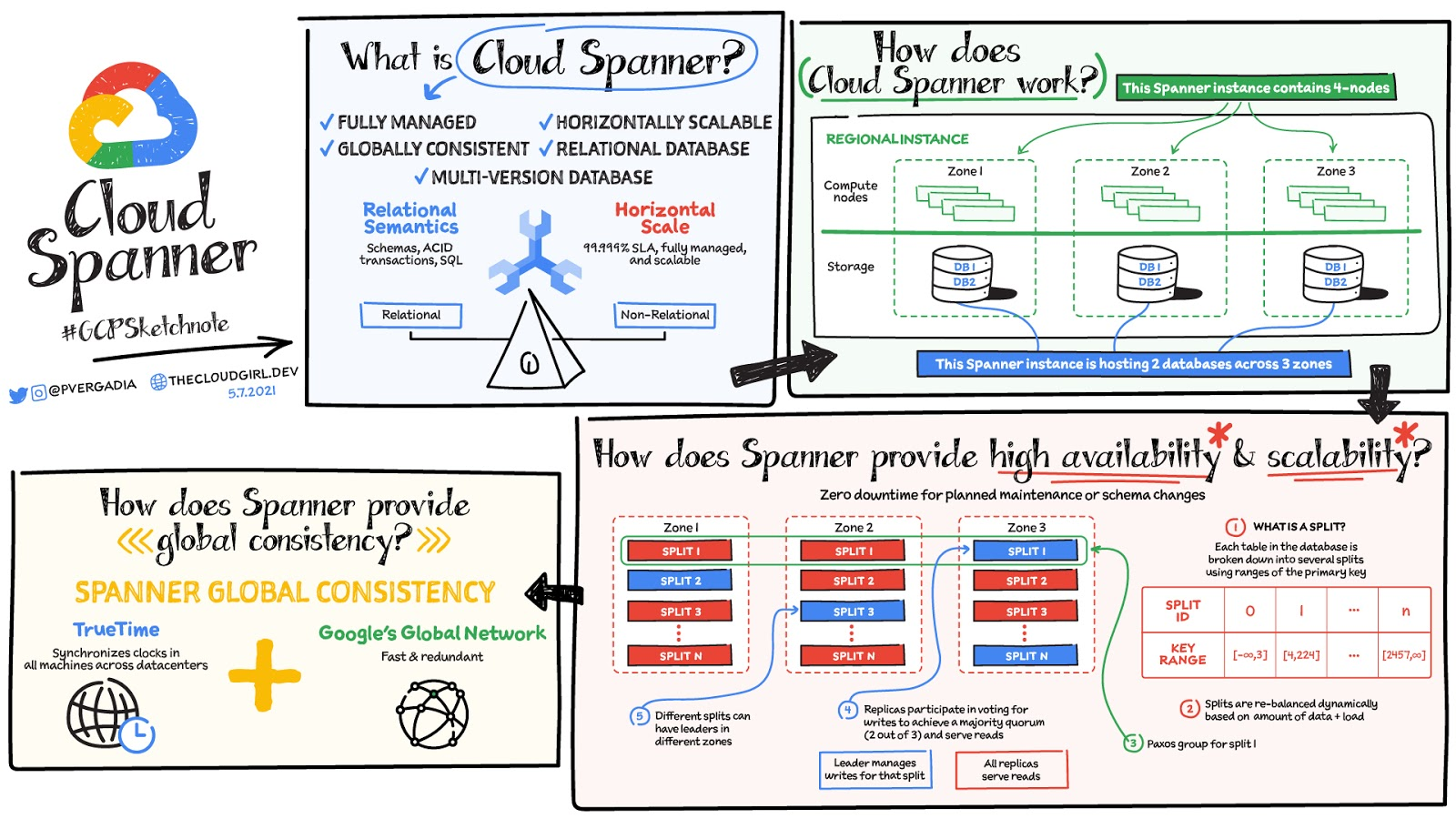
Spanner は、トランザクション ワークロード向けに最適化された、Google Cloud のフルマネージド リレーショナル データベースです。Spanner では、Google Cloud のリージョン間でシームレスな複製を行うことができます。また、外部との強整合性や無制限のスケーリングを備え、最大で毎秒 10 億件を超えるリクエストを処理できます。お客様は月額 $65 で 100 処理ユニットから Spanner の利用を始めることができ、たとえビジネスが 100 倍に成長しても、データベースのスケーラビリティを心配する必要はありません。
BigQuery は、ビジネスのアジリティを高めるように設計された、スケーラビリティと費用対効果に優れたサーバーレスのマルチクラウド データ ウェアハウスです。
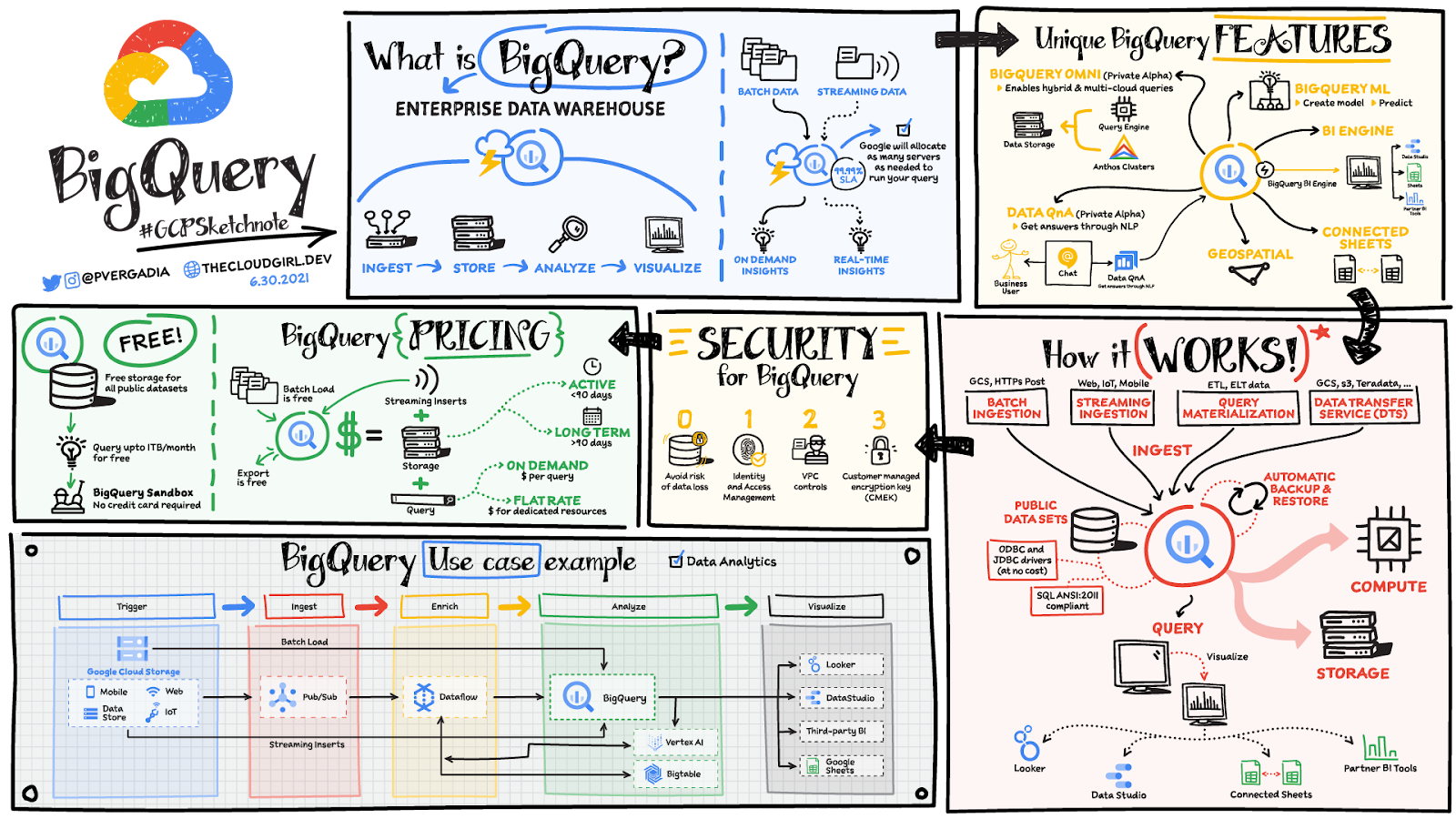
アドホック分析やレポートの制限をなくすよう最適化されており、組織の分析情報を得る場合に最も適しています。BigQuery のお客様は、1 秒間に 110 テラバイト(TB)のデータを分析しています。BigQuery と Spanner はそれぞれがパワフルなツールですが、シームレスに連携することでトランザクションと分析のワークロードを実行し、高スループットのニーズに応えます。
実績あるインフラストラクチャ上に構築
Spanner と BigQuery は、ワークロードの需要変化に応じて、コンピューティングとストレージの両方のリソースで互いに独立してスケーリングできます。これまでデータベースはストレージとコンピューティングを密結合して設計されてきましたが、Spanner と BigQuery はコンピューティングとストレージを分離して設計されています。どちらのプロダクトも、YouTube、検索、マップ、Gmail など、有名かつ世界中で利用されている Google プロダクトを支えている Google の分散ストレージ システムである Colossus 上に構築されています。
Colossus は、その上に構築されたサービスに対して、優れた耐久性、可用性、パフォーマンス、スケーラビリティをグローバルに提供するため、繁忙期にも何の心配もいりません。たとえば、大規模なデータセットに対して多数の複雑なクエリを行う年末の財務計画や予測、またはサイバー マンデー中の膨大な小売トランザクションは、すべて両方のサービスで処理できます。
Spanner と BigQuery は、ユーザーの必要に応じ、独立して、または一緒に、スケールアップやスケールダウンを行えます。また、どちらのプロダクトも、Borg(Google の社内クラスタ管理システム)と Jupiter(Google のデータセンターにあるすべてのサーバーを接続する社内のカスタム ネットワークのハードウェアとソフトウェア)の上に構築されています。

リアルタイムの分析を簡単に
ユーザーは長い間、独自のスクリプトや外部の ETL / ELT ツールを使用して、OLTP データベースから分析(OLAP)システムに必要なデータを抽出することで、トランザクション データに対する分析を実施してきました。これは長年にわたってうまく機能しましたが、毎秒数十トランザクションだったワークロードが毎秒数百万トランザクションにまで増加し、週次や日次の静的レポートだった分析も最新のトランザクション データに対するアドホック クエリを含むように拡大されたため、これらのシステムの統合を維持するのにチーム全体で対応する必要が出てきました。Spanner と BigQuery は、データ ライフサイクルを統合し、Cloud Spanner からの最新のトランザクション データを使用して BigQuery で素早く分析できるように設計されています。
ユースケースに応じて、ユーザーは最初に物理テーブルとして BigQuery にデータを取り込むか、必要なときに Spanner で直接データをクエリするかを選択できます。どちらの場合も、ユーザーはクエリの連携を活用して簡単にセットアップできます。ユーザーは目的の Spanner インスタンスを指す BigQuery の外部データソースを設定し、適切なクエリを記述するだけです。そうしたクエリは、オンデマンドで BigQuery テーブルに入力するために使用したり、必要に応じて実行するようにスケジュール設定したりできます。あるいは、別の BigQuery の結果セットと動的に結合することもできます。BigQuery ユーザーが Spanner から最新かつ優れた OLTP データを利用できるようにするために、追加のメンテナンスや他のコンポーネントへの依存は必要ありません。また、より複雑な変換や外部依存がある場合は、DataFlow のようなサービスを使用して Spanner データを BigQuery に取り込むこともできます。
BigQuery と Spanner の利用シナリオ例
BigQuery と Spanner を組み合わせて使用する方法について理解しやすくするために、世界中に 100 万人を超えるプレーヤーがいるオンライン ゲームのスタートアップ企業 Cymbal のシナリオを例にとって説明します。

この会社は架空ですが、シナリオは本物です。Cymbal は、ユーザー プロフィール、インベントリ アイテム、カスタマイズ、アクション、その他のゲーム アクティビティを含め、ゲームデータを Spanner に格納します。この情報は、効率性と拡張性を考慮して設計された Spanner のファイル形式で物理的に Colossus に配置されます。ゲームプレイ データをサポートするトランザクション レートの高さに加え、Cymbal は他のプレーヤー、装備、さらにはプレーヤー以外のキャラクターとの関わりを含め、プレーヤーの行動に関する分析も行います。Cymbal のアナリストは日常的に、すでに BigQuery にある競技データを Spanner のデータと組み合わせる必要があります。Cymbal がこれを実現する方法は 2 つあります。Spanner から BigQuery にデータを複製し、ローカルデータに対して分析を行うか、連携クエリを使用して Spanner からオンデマンドでデータを取得します。
データの複製
前述したように、ユーザーは連携クエリを活用して Spanner からデータを読み込み、ネイティブ BigQuery テーブルに書き込むことができます。これは、分析するためのデータの複製が頻繁には必要でなく、データが数分から数日前のものでもよい場合によく使用されます。また、Cymbal の一部のアナリストに役立ちます。次のセクションでは、セットアップの詳しい手順を含め、連携クエリについて深く掘り下げます。他の Cymbal アナリストは Spanner からのデータを毎日更新する必要があり、これを自分で管理することは望んでいません。この場合 Cymbal の管理者は、連携クエリ、Google DataFlow のようなサービス、または Google Cloud パートナーが提供する数多くのソリューションの一つを使用して、Spanner から BigQuery にデータを複製するために繰り返し実行されるジョブを設定できます。
連携クエリ
BigQuery ユーザーは、Spanner に存在するデータに対してオンデマンドで簡単に連携クエリを実行できます。データは、さらに大きい分析クエリの一部としてリアルタイムに使用できます。連携クエリのオンデマンド性により、ユーザーはデータの更新頻度を柔軟にコントロールできます。データ移動(ETL / ELT)ジョブの次のスケジュール実行が終わるまで待つ必要はありません。
連携クエリはパワフルですが、多少の制限もあります。連携クエリは、ローカルの BigQuery テーブルをクエリするほど高速ではない可能性があります。ソース データベースが外部クエリを実行して結果のセットを Spanner から BigQuery に移動するまで若干の待ち時間が発生するため、レイテンシが大きくなる可能性があります。連携クエリは Spanner インスタンスでコンピューティング リソースを消費する別のワークロードに過ぎないため、ユーザーは既存の OLTP ワークロードに悪影響を与えないようにする必要があります。
連携クエリの実行方法
連携クエリを実行する手順は簡単です。
1)まず BigQuery を起動し、必要なデータベースを含む Spanner インスタンスが含まれる Google Cloud プロジェクトを選択します。
2)次に、外部データソースの設定を BigQuery で Spanner データベースに対して行います。この設定には、bigquery.admin 権限が必要です。
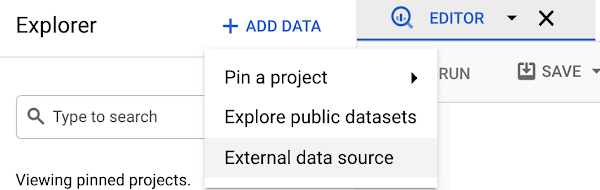

注: [データを同時に読み込む] のチェックボックスをオンにすると、Spanner は連携クエリをさらに小さいパーティションに分割して並列実行できるようになります。ただし、このオプションは、実行プランの最初の演算子が分散ユニオン演算子であるクエリに限定されます。その他のクエリではエラーが返されます。詳細については、Cloud Spanner によるクエリの実行方法を理解するをご覧ください。
3)最後に、Spanner データソース内のデータにアクセスするクエリを BigQuery で作成します。他のユーザーも BigQuery からこの外部データソースにアクセスできるようにするには、作成した接続リソースを使用するための権限を付与します。

使用する場面
BigQuery で使用する Spanner データの範囲が明確、データの更新頻度要件が固定的(15 分、1 日など)、同じデータセットのユーザーが多い、または特定のデータセットのみを共有する(データベース全体ではない)といったユースケースの場合、ローカルの BigQuery テーブルにデータを複製するアプローチの方が適切ということもあります。その場合は、BigQuery の分析ワークロードのセキュリティとリソースが、Spanner の OLTP ワークロードから分離されます。クエリが実行される可能性があり、許可された BigQuery ユーザーがすべての Spanner データにアクセスできる場合、取得するデータの大部分が予測できないアドホック クエリであるユースケースでは、連携クエリの方が適切である可能性があります。このブログ投稿のトピックについて詳しくは、以下のリンク先をご覧ください。
詳細
Spanner の利用を開始するには、インスタンスを作成するか、Spanner Qwiklabでお試しください。
BigQuery での Spanner 連携クエリの使用の詳細については、こちらのチュートリアルをご覧ください。
Spanner から BigQuery にデータを複製する方法の詳細については、こちらのブログ投稿をご覧ください。
BigQuery の詳細については、こちらのトレーニングとチュートリアルをご覧ください。
- デベロッパー アドボケイト Bukola Ayodele




