Vertex AI で TensorFlow Profiler を使用してトレーニングのパフォーマンスを最適化する方法
Google Cloud Japan Team
Vertex AI で TensorFlow Profiler を使用してボトルネックをデバッグし、トレーニング ジョブを迅速に実行する 5 つの方法
※この投稿は米国時間 2023 年 1 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
ML モデルをトレーニングする場合、計算費用が高額になることがあります。大規模なデータセットでモデルをトレーニングしている方は、モデルのトレーニングに数時間、数日、場合によっては数週間もかかるという状況に慣れているかもしれません。しかし、トレーニングにかかる時間を増加させる要因は大量のデータだけではありません。非効率的な入力パイプラインや使用率の低い GPU など、処理の環境が最適化されていない場合、トレーニングにかかる時間が大幅に増加することがあります。
迅速にトレーニングを行うには、ボトルネックのない状態でプログラムが効率的に実行されるようにすることが重要です。また、迅速なトレーニングによって反復処理を高速化することで、モデリングの目標を達成できます。そこで今回ご紹介するのが、Vertex AI で TensorFlow Profiler を使用する手法です。モデルのトレーニングにかかる時間を最適化するための分析情報を取得する 5 つの方法も共有します。オープンソースの TensorFlow Profiler に基づくこの機能により、Vertex AI Training サービスのジョブを簡単にプロファイリングできます。
早速、この機能の設定方法と、プロファイリング セッションを確認することで取得できる分析情報について見ていきましょう。
TensorFlow Profiler の設定
TensorFlow Profiler を使用する前に、カスタム トレーニング ジョブを処理できるように Vertex AI TensorBoard を構成する必要があります。その詳細な設定手順については、こちらをご覧ください。TensorBoard を設定したら、トレーニング コードとトレーニング ジョブの構成にいくつかの変更を加えます。
トレーニング コードの変更
まず、cloud_profiler プラグインをトレーニング コードの依存関係とし、Vertex AI Python SDK をインストールします。プラグインをインストールしたら、トレーニングのアプリケーション コードに 3 つの変更を加えます。
まず、cloud_profiler をトレーニングのスクリプトにインポートします。
続けて、以下のように cloud_profiler.init() を使用してプロファイラを初期化します。
最後に TensorBoard コールバックをトレーニングのループに追加します。すでに Vertex AI TensorBoard をお使いの場合、この手順には馴染みがあるでしょう。
トレーニング スクリプトの例については、こちらのドキュメントをご覧ください。
カスタムジョブの構成
トレーニング コードを更新したら、Vertex AI Python SDK でカスタムジョブを作成できます。
続けて、サービス アカウントと TensorBoard インスタンスを指定してジョブを実行します。
プロファイルのキャプチャ
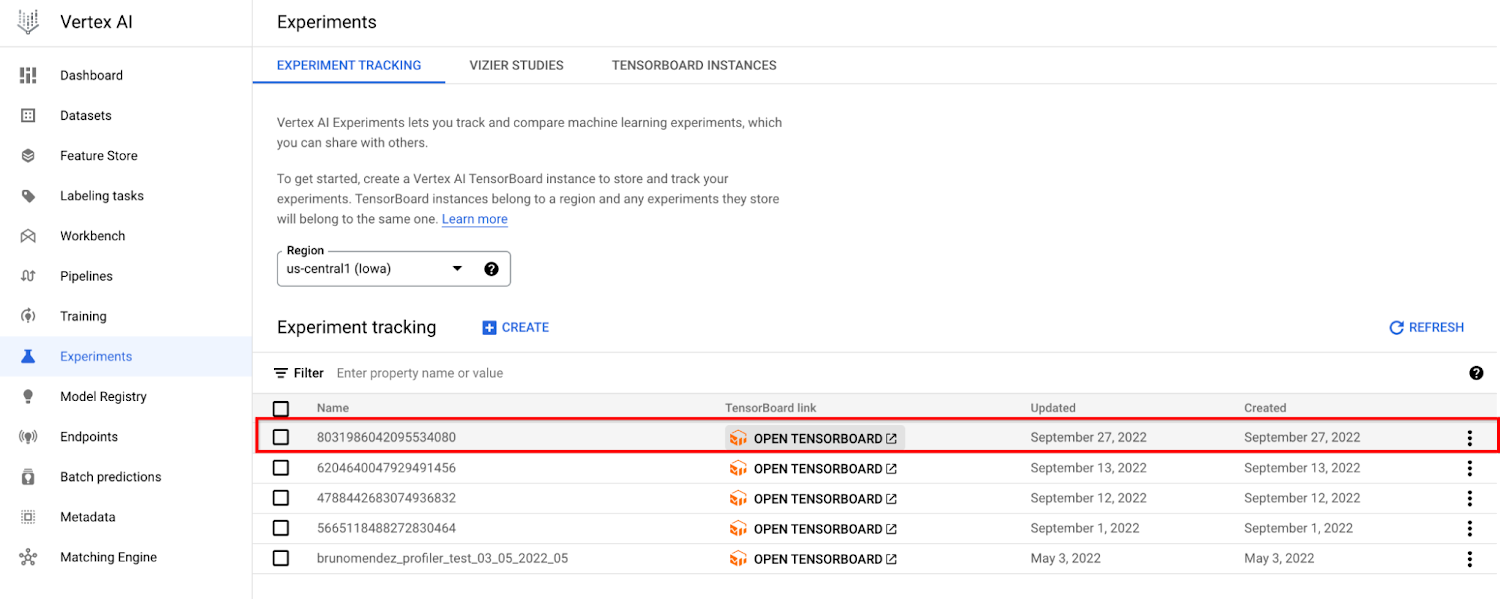
開始したカスタムジョブは、[トレーニング] ページの [CUSTOM JOBS] タブに表示されます。
トレーニング ジョブがトレーニングまたは実行中の状態にある場合、新しいテストがテストのページに表示されます。それをクリックして TensorBoard インスタンスを開きます。
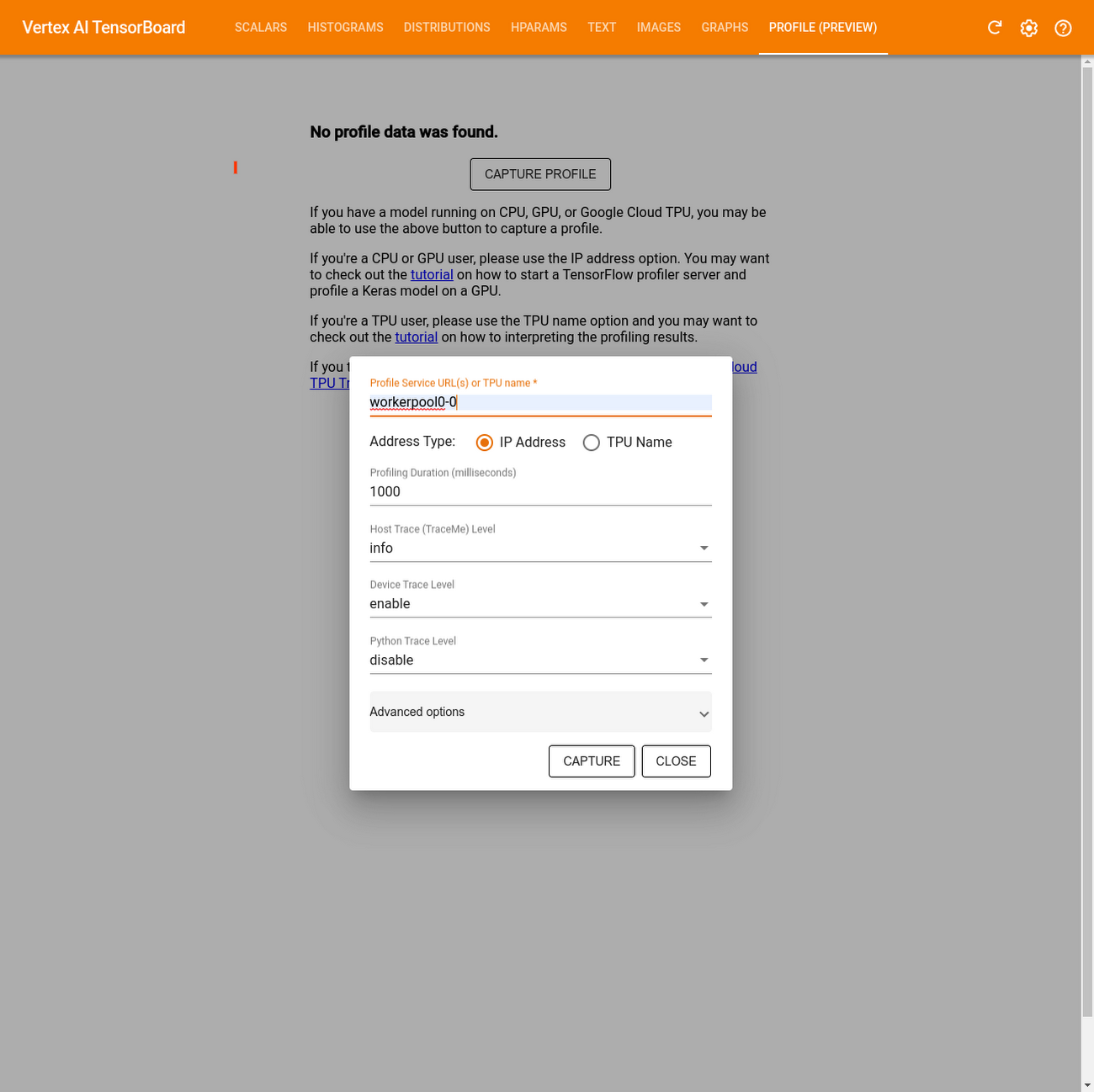
TensorBoard を開いたら、[Profiler] タブで [Capture profile] をクリックします
[Profile Service URL(s) or TPU name] フィールドに「
workerpool0-0」と入力します[Address Type] で [IP Address] を選択します
[CAPTURE] をクリックします
前述の手順を行えるのは、ジョブがトレーニングまたは実行中の状態にある場合のみです。
TensorBoard Profiler を使用したパフォーマンスの分析
プロファイルをキャプチャしたら、モデル内のさまざまなオペレーションのハードウェア リソース使用率を分析することで多くの情報を取得できます。これらの分析情報を利用してパフォーマンスのボトルネックを解消し、最終的にはモデルの実行速度を高めることができます。
TensorFlow Profiler は多くの情報を提供するため、どこから手を付けるべきかを判断するのが難しいことがあります。そこで、TensorFlow Profiler を初めて使用する方が、トレーニング ジョブをより的確に理解するうえで役立つ 5 つの方法の概要をご紹介します。
概要ページでパフォーマンスを大まかに理解する
TensorFlow Profiler には、トレーニング ジョブのパフォーマンスの概要を示すページがあります。
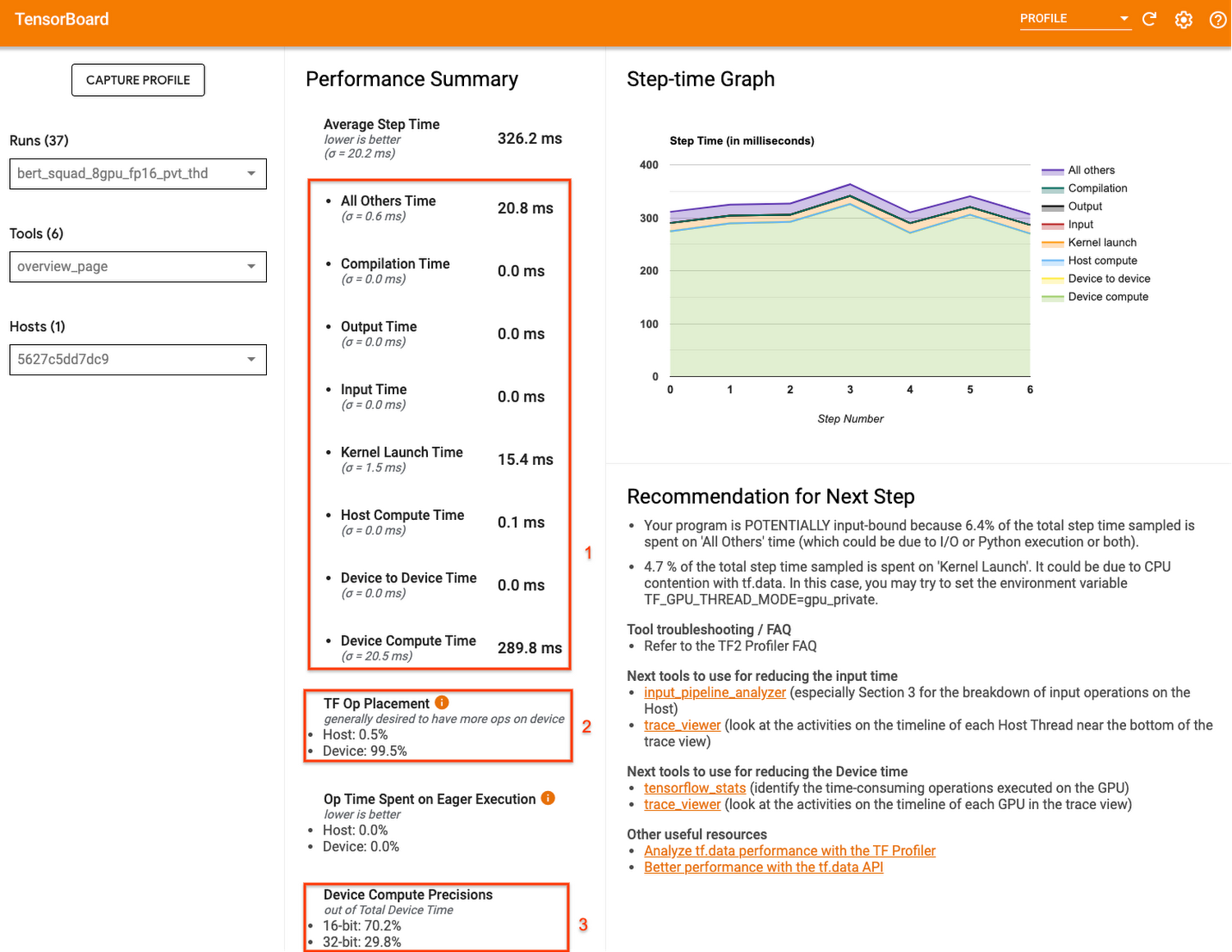
このページではさまざまな情報が提供されていますが、「デバイスの計算時間(Device Compute Time)」、「TF オペレーションの配置(TF Op Placement)」、「デバイスの計算精度(Device Compute Precisions)」の 3 つの数値に注目すると多くのことがわかります。
デバイスの計算時間からは、実際のデバイスの実行時間に占める、デバイスの計算ステップの時間がわかります。つまり、デバイスがバッチデータの準備を待機してアイドル状態であった時間ではなく、フォワードパスおよびバックワード パスの計算に費やした時間がどの程度あったかがわかります。ステップ時間の大部分が、待機ではなくトレーニング計算の実行に費やされていることが理想的です。
TF オペレーションの配置からは、デバイス(GPU など)とホスト(CPU)に配置されたオペレーションの割合がわかります。一般に、デバイスに多くのオペレーションを配置した方が高速になります。
最後に、デバイスの計算精度からは、16 ビットと 32 ビットの計算の割合がわかります。現代のほとんどのモデルは、32 ビットのメモリを消費する float32 dtype を使用しています。ただし、16 ビットのメモリを消費する 2 つの低精度の dtype(float16 と bfloat16)もあります。最新のアクセラレータは、16 ビットの dtype でオペレーションを迅速に実行できます。ご自身のユースケースで精度を低くしても問題がない場合は、混合精度を採用して 32 ビットのオペレーションの一部を 16 ビットのオペレーションで置き換え、トレーニングにかかる時間を短縮することもできます。
概要セクションには、今後のための推奨事項も提示されます。このため、以降のセクションでは、デバッグに役立つプロファイラのより専門的な機能の一部について取り上げます。
入力パイプラインのパフォーマンスの詳細を把握する
概要ページを確認したら、次は入力パイプラインのパフォーマンスを評価するとよいでしょう。入力パイプラインでは一般に、データの読み取りとデータの前処理を行った後、ホスト(CPU)からデバイス(GPU / TPU)にデータを転送します。
GPU と TPU は 1 つのトレーニング ステップの実行に必要な時間を短縮できます。しかし、アクセラレータの利用率を増加させるには、現在のステップが完了する前に次のステップのデータを提供する効率的な入力パイプラインが必要です。ホストがバッチデータを準備している間、アクセラレータをアイドル状態にしておくべきではありません。
TensorFlow Profiler には、プログラムが入力に縛られているかどうかを判断するうえで役立つ入力パイプライン分析ツールが用意されています。たとえば、以下に示すプロファイルは、トレーニング ジョブが入力に大幅に縛られていることを示しています。ステップ時間の 80% 以上がトレーニング データの待機に費やされています。次のステップが終了する前にバッチデータを準備することで、各ステップに必要な時間を短縮できるため、トレーニング時間全体が減少します。
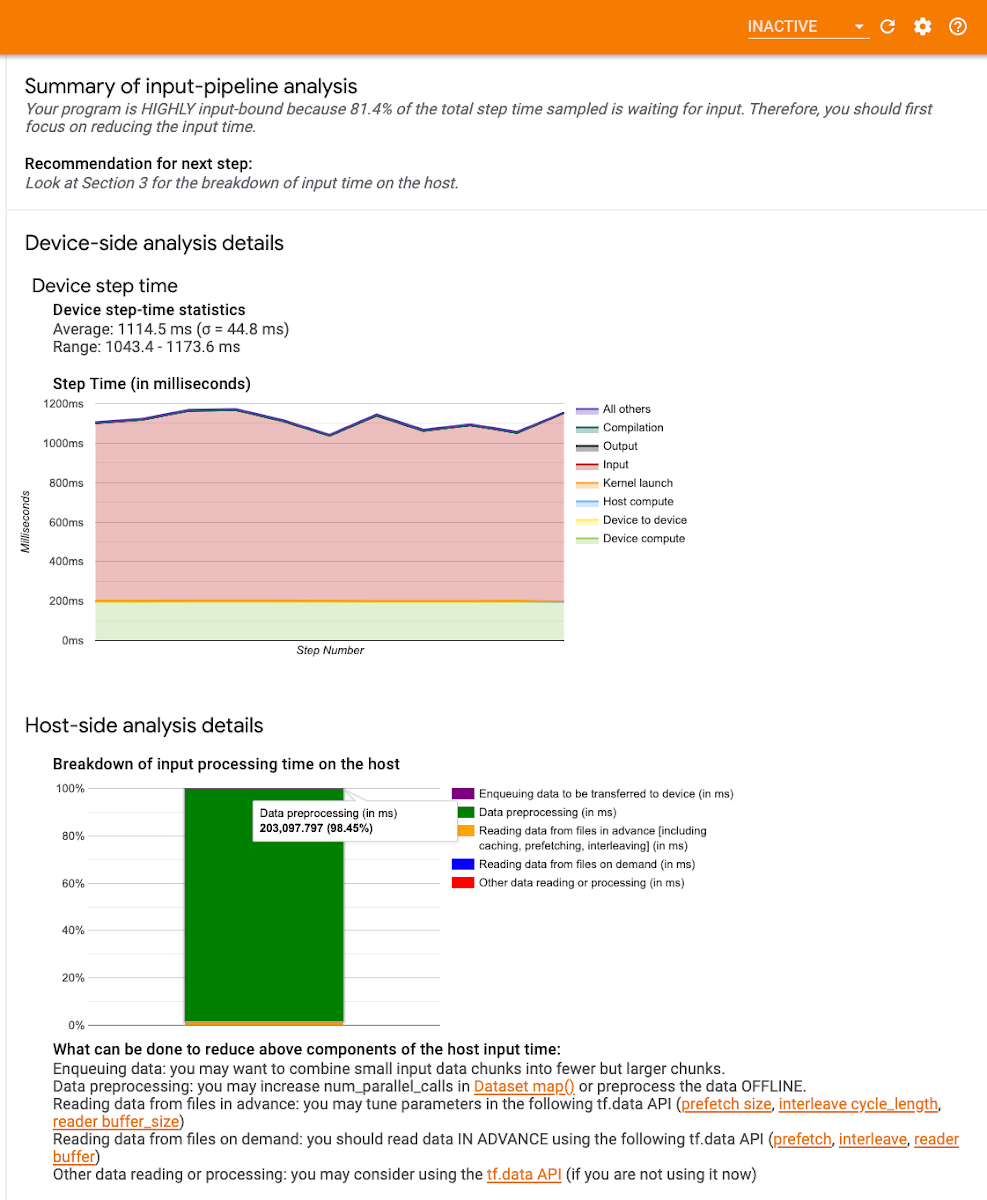
プロファイラのこのセクションには、デバイスとホスト両方のステップ時間の内訳も示されます。
デバイス側のグラフの赤色の領域は、ステップ時間のうち、デバイスがホストからの入力データを待機してアイドル状態であった時間を示します。緑色の領域は、デバイスが実際に動作していた時間を示します。つまり、赤色の領域が多くなってきたら、入力パイプラインをデバッグすべきタイミングであるということです。
ホスト側の分析グラフは CPU での処理時間の内訳を示します。たとえば、ここに示しているグラフの大部分は緑色です。このことは、データの前処理に非常に多くの時間が費やされていることを示します。この場合、これらのオペレーションを並行して実行するか、場合によってはデータをオフラインで前処理することを検討するとよいでしょう。
入力パイプライン分析ツールでは、具体的な推奨事項も提示されます。入力パイプラインを最適化する方法の詳細については、こちらのガイドまたは tf.data のベスト プラクティスに関するドキュメントを参照してください。
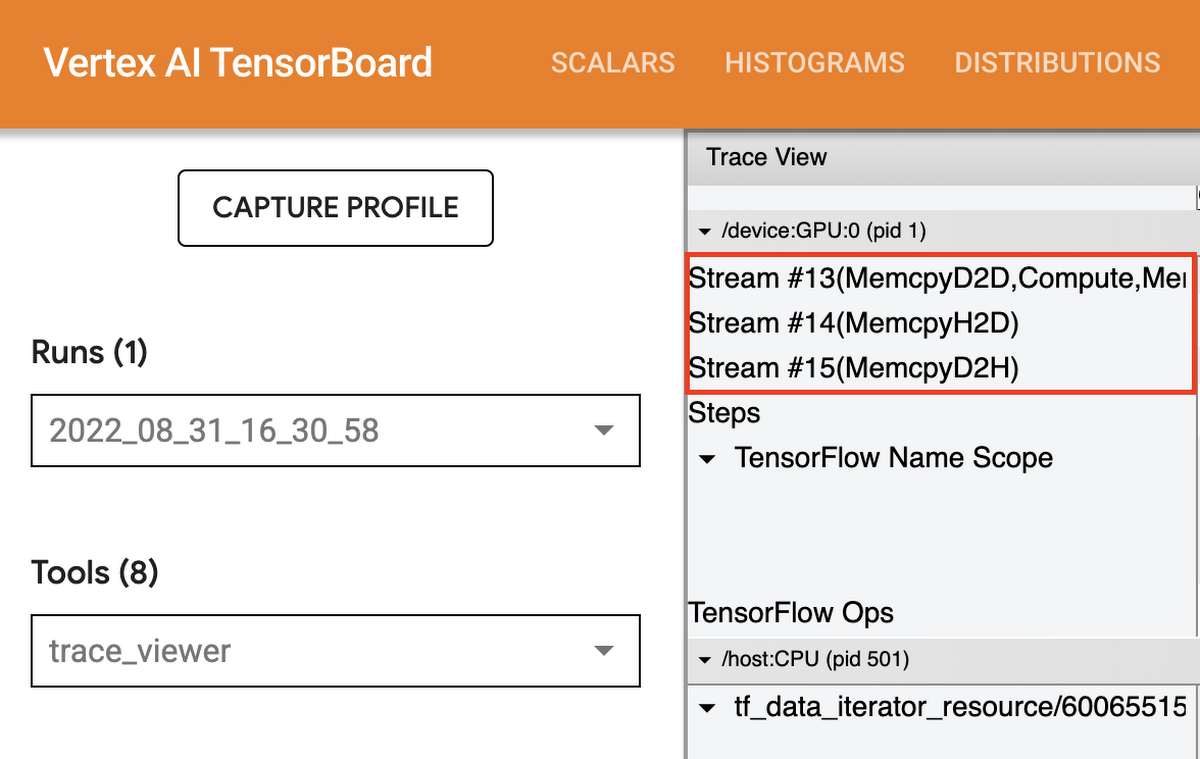
Trace Viewer を使用して GPU の利用率を最大化する
プロファイラに用意されている Trace Viewer には、モデルによって実行されたオペレーションの実行時間を示すタイムラインと、オペレーションが実行されたシステムの場所(ホストまたはデバイス)が表示されます。トレースの読み取りに慣れるまでには多少の時間がかかりますが、慣れてしまえば、プログラムの詳細を把握するうえで非常に有用なツールであることがわかるでしょう。
Trace Viewer を開くと、CPU と各デバイスのトレースが表示されます。一般的には、トレーニング データの前処理やデバイスへの転送など、ホストが実行する入力オペレーションを確認するとよいでしょう。デバイスでは、実際のモデルのトレーニングに関連するオペレーションを確認します。
デバイスでは、以下の 3 つのストリームのタイムラインが表示されます。
- Stream 13: 計算カーネルの開始とデバイス間コピーに使用されます
- Stream 14: ホストからデバイスへのコピーに使用されます
- Stream 15: デバイスからホストへのコピーに使用されます
タイムラインにはトレーニング ステップの実行時間が表示されます。プログラムが最適に実行されていない場合、トレーニング ステップの間にギャップが発生することがよくあります。以下の Trace Viewer の図では、ステップ間に小さなギャップがあります。
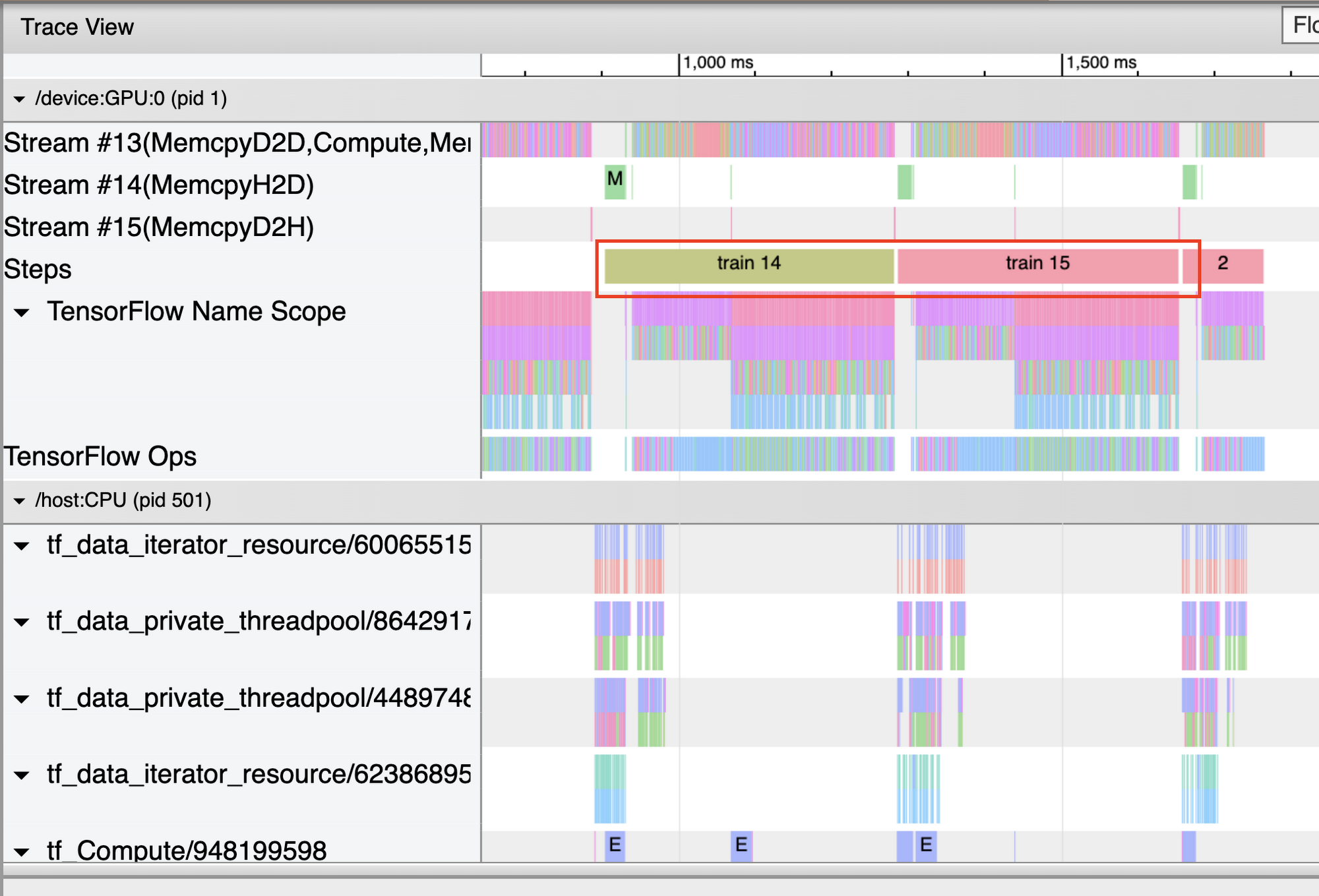
しかし、以下の図のように大きなギャップがある場合、その間 GPU がアイドル状態であったことを示します。この場合、入力パイプラインを再確認するか、各ステップの最後に不要な計算(コールバックの実行など)を行っていないか確認する必要があります。

Trace Viewer を使用して GPU のパフォーマンスを把握するその他の方法については、TensorFlow 公式ドキュメントのガイドを参照してください。
OOM の問題をデバッグする
トレーニング ジョブにメモリリークがあることが疑われる場合は、メモリ プロファイルのページで診断できます。内訳を示す表で、プロファイリング間隔のメモリ使用量がピーク時点にあったときのアクティブなメモリ割り当てを確認できます。
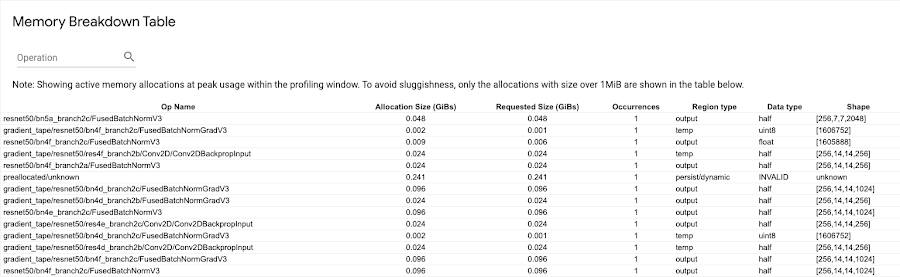
これは一般に、デバイスの利用率の増加につながるバッチサイズの最大化に役立ちます。また、分散トレーニングを実行している場合は、複数の GPU 間で通信費用を分割できます。メモリ プロファイラを使用すると、プログラムがメモリ利用率のピークにどの程度近づいているかをおおむね把握できます。
分散トレーニング ジョブの勾配の AllReduce を最適化する
分散トレーニング ジョブを実行し、データの並列処理アルゴリズムを使用している場合、Trace Viewer を使用して AllReduce オペレーションを最適化できます。同期データ並列戦略を採用している場合、各 GPU がモデルを使用して、入力データの異なるスライスのフォワードパスとバックワード パスを計算します。これらのスライスから計算された勾配はすべての GPU に集約され、AllReduce と呼ばれるプロセスで平均化されます。モデル パラメータは、これらの平均勾配を使用して更新されます。
同じホストでトレーニングに使用する GPU を 1 個から複数に切り替える場合、勾配の通信オーバーヘッドのみが追加された状態でパフォーマンスが拡張され、ホストスレッドの利用率が増加することが理想的です。このオーバーヘッドがあるため、たとえば GPU を 1 個から 2 個に増やした場合も、速度が 2 倍ちょうどにはなりません。
すべてのデバイスで同期されてしまうため、不要な AllReduce 呼び出しがないか、プログラムのトレース ビューの GPU タイムラインで確認できます。ただし、Trace Viewer を使用して、分散トレーニング ジョブ実行のオーバーヘッドが予測どおりか、またはパフォーマンスのデバッグをさらに実行する必要があるかどうかを簡単に確認することもできます。
AllReduce の時間は以下のようになります。
(パラメータ数 x 4 バイト)÷(通信帯域幅)
TensorFlow では勾配の通信に fp32(float32)を使用するため、各モデル パラメータのサイズは 4 バイトです。fp16 を有効にしている場合も、NCCL AllReduce は fp32 パラメータを利用します。モデルのパラメータ数は Model.summary で確認できます。
AllReduce の時間がこの計算よりもかなり長かったことがトレースから判明した場合、おそらく不要な、追加のオーバーヘッドが発生していたことを意味します。
次のステップ
TensorFlow Profiler は、パフォーマンスのボトルネックの診断とデバッグを可能にし、モデルのトレーニングを高速にするパワフルなツールです。今回は、このツールを使用してトレーニングのパフォーマンスを把握する 5 つの方法をご紹介しました。TensorFlow Profiler の使い方の詳細については、TensorFlow 公式ドキュメントの GPU ガイドとデータガイドを参照してください。ぜひご自身のトレーニング ジョブのプロファイリングをお試しください。
- デベロッパー アドボケイト Nikita Namjoshi
- GCP Cloud AI および業種別ソリューション担当ソフトウェア エンジニア Bruno Mendez