Vertex AI でカスタムモデルを強化
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
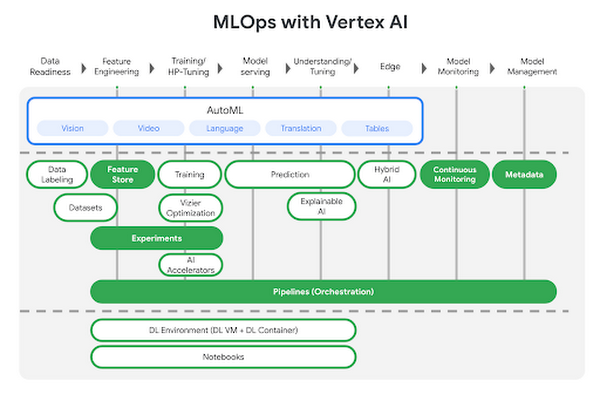
5 月に発表した新しい統合型 AI Platform である Vertex AI では、事前トレーニング済みモデルの活用からさまざまなフレームワークを使用したモデルの構築まで、あらゆる選択肢をご提供します。本投稿では、Vertex AI でのカスタムモデルのトレーニングとデプロイについて詳しくご説明します。次の図に示すように、Vertex AI にはさまざまなツールが用意されています。今回のシナリオでは、緑色でハイライト表示されたプロダクトを使用します。
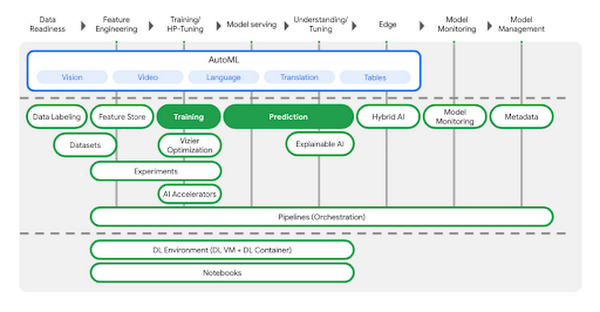
モデルコードを自分で記述したくない場合には AutoML が最適ですが、多くの組織では、TensorFlow、XGBoost、PyTorch などのオープンソースの ML フレームワークを使用してカスタムモデルを構築しなければならないケースがあります。この例では、Kaggle の Auto MPG データセットを使用して、自動車の燃料効率を予測するカスタム TensorFlow モデル(このチュートリアルに基づいて構築)を構築します。
すぐに開始されたい場合は、Codelab をご覧いただくか、以下の 2 分間の動画でデモシナリオの概要についてご確認ください。

環境設定
これらのトレーニングと予測のステップを実行するための環境を設定するには、さまざまな方法があります。上のリンク先のラボでは、Cloud Shell の IDE を使用してモデルのトレーニング アプリケーションを構築し、トレーニング コードを Docker コンテナとして Vertex AI に渡します。IDE にはご自身が最も快適に作業できるものを使用できます。また、トレーニング コードをコンテナ化したくない場合は、Vertex AI がサポートするビルド済みコンテナの一つで実行される Python パッケージを作成できます。
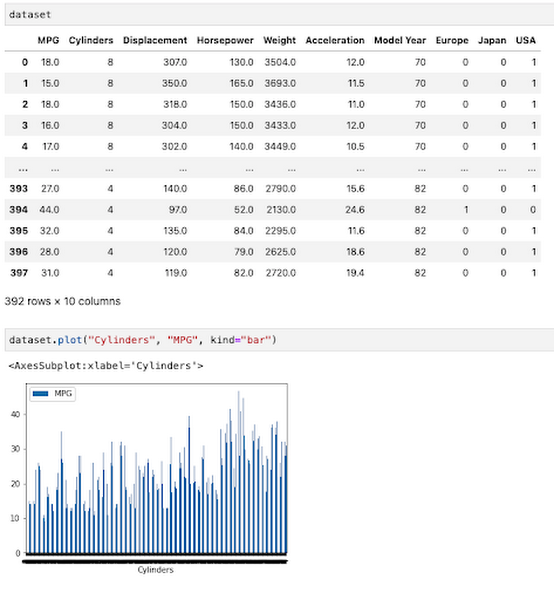
Pandas や別のデータ サイエンス ライブラリを使用して探索的データ分析を行う場合は、Vertex AI でホストされている Jupyter ノートブックを IDE として使用できます。たとえば、ここではデータ属性の一つである「シリンダー」と燃料効率との相関関係を調べることを目的とします。Pandas を使用して、この関係をノートブックに直接プロットします。
まず、関連するサービスを有効にした Google Cloud プロジェクトがあることを確認する必要があります。gcloud SDK を使用すると、これから使用するすべてのプロダクトを 1 つのコマンドで有効にできます。
次に、保存したモデルアセットを保存するための Cloud Storage バケットを作成します。これで、モデルのトレーニング コードの開発を開始する準備が整いました。
トレーニング コードのコンテナ化
ここでは、トレーニング コードを Docker コンテナとして開発し、そのコンテナを Google Container Registry(GCR)にデプロイします。これを行うには、ルートに Dockerfile を含むディレクトリと train.py ファイルを含む trainer サブディレクトリを作成します。ここで、トレーニング コードの大部分を記述します。
このモデルをトレーニングするには、Keras Sequential Model API を使用してディープ ニューラル ネットワークを構築します。
ここではモデルのトレーニング コード全体を掲載しませんが、Codelab のこちらのステップでご確認いただけます。トレーニング コードが完成したら、コンテナをローカルで構築してテストできます。以下のスニペットの IMAGE_URI は、GCR でコンテナ イメージをデプロイする場所に相当します。以下の $GOOGLE_CLOUD_PROJECT をクラウド プロジェクトの名前に置き換えます。
あとは、docker push $IMAGE_URI を実行して、コンテナを GCR に push します。これで、コンソールの GCR セクションに新しくデプロイされたコンテナが表示されます。
トレーニング ジョブの実行
モデルをトレーニングする準備が整いました。プラットフォームのモデル セクションで、上で作成したコンテナを選択できます。必要に応じて、トレーニング方法、コンピューティング設定(GPU、RAM など)、ハイパーパラメータ調整などの重要な詳細を指定することも可能です。
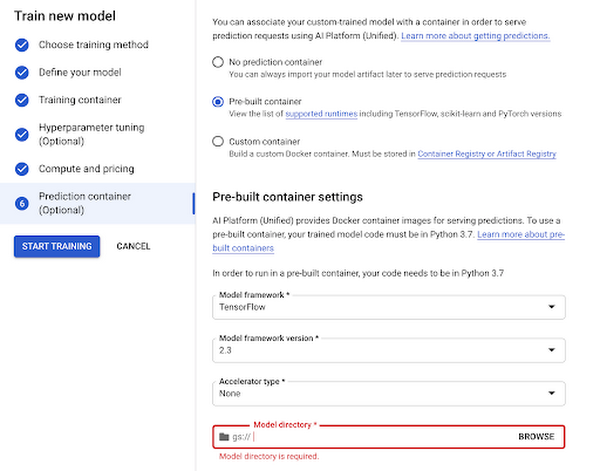
これで、モデルのトレーニングという手間のかかる作業を Vertex に任せることができるようになりました。
エンドポイントへのデプロイ
次に、新しいモデルをアプリやサービスに組み込んでいきましょう。モデルのトレーニングが完了すると、新しいエンドポイントを作成するオプションが表示されます。開発プロセス中に、コンソールでエンドポイントをテストできます。クライアント ライブラリを使用すると、1 行のコードで簡単にエンドポイントへの参照を作成し、予測を取得できます。
今すぐ開発に着手
Vertex AI を使い始める準備はできましたか?事前トレーニング済みモデルの使用からカスタムモデルのライフサイクルの各ステップに至るまで、すべてのユースケースをカバーしています。
テキスト、コード、データを組み合わせた開発エクスペリエンスに Jupyter ノートブックを使用する
カスタムモデルの作成に必要なコードの行数を削減する
MLOps を使用して、信頼性とスケーラビリティを備えたデータ管理を実現する
この Codelab をご自身でお試しいただくか、この 1 時間のワークショップをご覧いただき、ぜひ実際にご利用ください。
-Google Cloud Developer Relations シニア エンジニア Sara Robinson
-Google Cloud Developer Relations シニア エンジニア Anu Srivastava