EvoJAX: あなたの課題を Neuroevolution の力で解く
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
JAX はユーザーコードの簡略化や大規模な並列化・何桁もの高速化を可能にする、最近のGoogleで最も重要な機械学習 (ML) フレームワークの一つです。このフレームワークは、言語理解におけるPathways Language Model (PaLM) 、物理学・分子動力学シミュレーションにおける Brax や JAX MD などをはじめとして、近年に最先端(State-of-the-Art) の成果を示した研究でも利用されています。
JAX の人気が高まっていることは、今後様々な分野において JAX を利用した研究やツールが登場することに繋がります。この記事では、JAX 上で構築された EvoJAX について紹介します。これは、ハードウェア・アクセラレーション技術により高速化されたNeuroevolution のツールキットであり、微分可能でない要素を含むような複雑な問題の解決に利用できます。下図では、ユーザーが EvoJAX によって解くことができるタスクの例が示されています。(各タスクの詳細については、「応用例」のセクションを見てください。)
EvoJAX の詳細について取り上げる前に、Neuroevolution が現実世界における多くの問題の解決に繋がりうる強力なツールであると言っても過言ではない理由について説明します。
なぜ Neuroevolution なのか?
ディープラーニング (DL) の成功は、微分によって得られる勾配を利用してディープニューラルネットワーク (DNN) を学習する非常に有効な手法である「バックプロパゲーション (backpropagation) 」に大きく依存しています。しかし、バックプロパゲーションが効果を発揮できるのは、対象となるシステムが “well-behaved” な(スムーズな振る舞いをする)場合に限られます。
Well-behaved なシステムとは何を示しているのでしょうか?このようなシステムは、多くの場合で微分可能であり、入出力のインターフェースがどのようになっているか、パラメータはどのように最適化できるかといった本質的な挙動が(少なくともある程度)明らかになっており、解決しやすい問題であると言えます。また、DLが広い範囲に応用されるようになるにつれ、微分可能な問題を扱うための勾配を利用した手法(backpropagation) でこのようなシステムを解く経験が増加した結果、その挙動がさらに明らかとなっていきました。これら二つの理由により、比較的自信と余裕を持って取り組むことができるようになった問題が “well-behaved” であるとみなすことができます。
しかし実際のところ、現実世界のケースの多くはそう理想的ではありません。まず一例として、システムの学習が成功するためには、モデルのハイパーパラメータのチューニングに大きな労力を割く必要がある場合が多いです。また、バックプロパゲーションは、システムが微分不可能であったりブラックボックスである場合、適用が困難になる場合があります。 こうした理由により、ニューラルアーキテクチャ探索 (NAS:Neural Architecture Search) やデータセンターの冷却 (datacenter cooling) 、プラズマ制御 (plasma control) などの実世界におけるアプリケーションでは、問題解決のために強化学習 (RL:Reinforcement Learning) や進化戦略 (ES:Evolution Strategies) アルゴリズムが多く用いられています。
ここで、どのようなシステムが "not well-behaved" と言えるのか理解を深めるため、ポリシー (Policy) 、タスク (Task) 、ユーティリティ (Utility) という概念について紹介します。
- ポリシー:タスクを解決するために開発するコンポーネントのことを指します。例えば、DNN を用いて問題を解くならば、ディープモデルがポリシーの一例となります。一般にはユーザーの設計は自由で、ポリシーはどのような形でも構いません。例えば、ルールベースの手法やシンボリックシステムを使うこともできます。
- タスク:解決したい問題のことを指し、ポリシーへの入力とポリシー評価のためのユーティリティを提供します。ここでユーティリティとは、タスクに対してポリシーがどれだけ有効であるかを測るための指標のことを指します。ユーティリティはタスクごとに定義することが可能で、例えば教師あり学習やRLタスクでは損失や報酬がユーティリティとして用いられます。
これらの概念を踏まえて、1) 画像分類 (Image classification)、 2) ロボット操作 (Robotic manipulation )、3) ニューラルアーキテクチャ探索 (NAS:Neural Architecture Search) の三つの例について見ていきましょう。
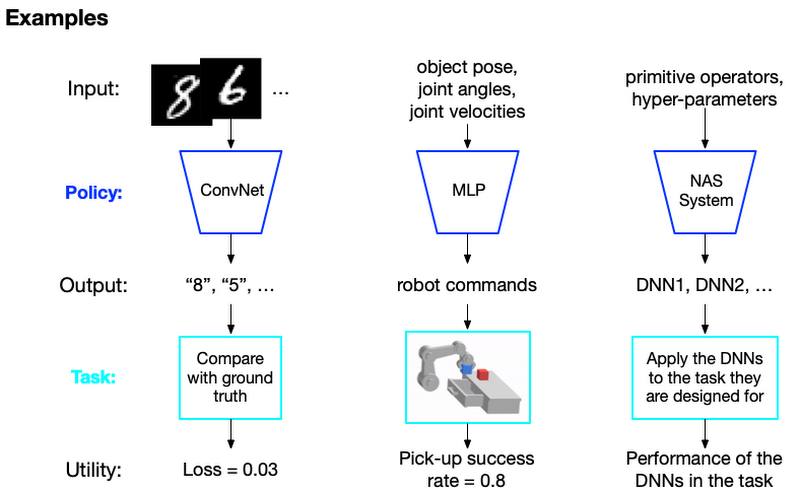
Non well-behaved なシステム
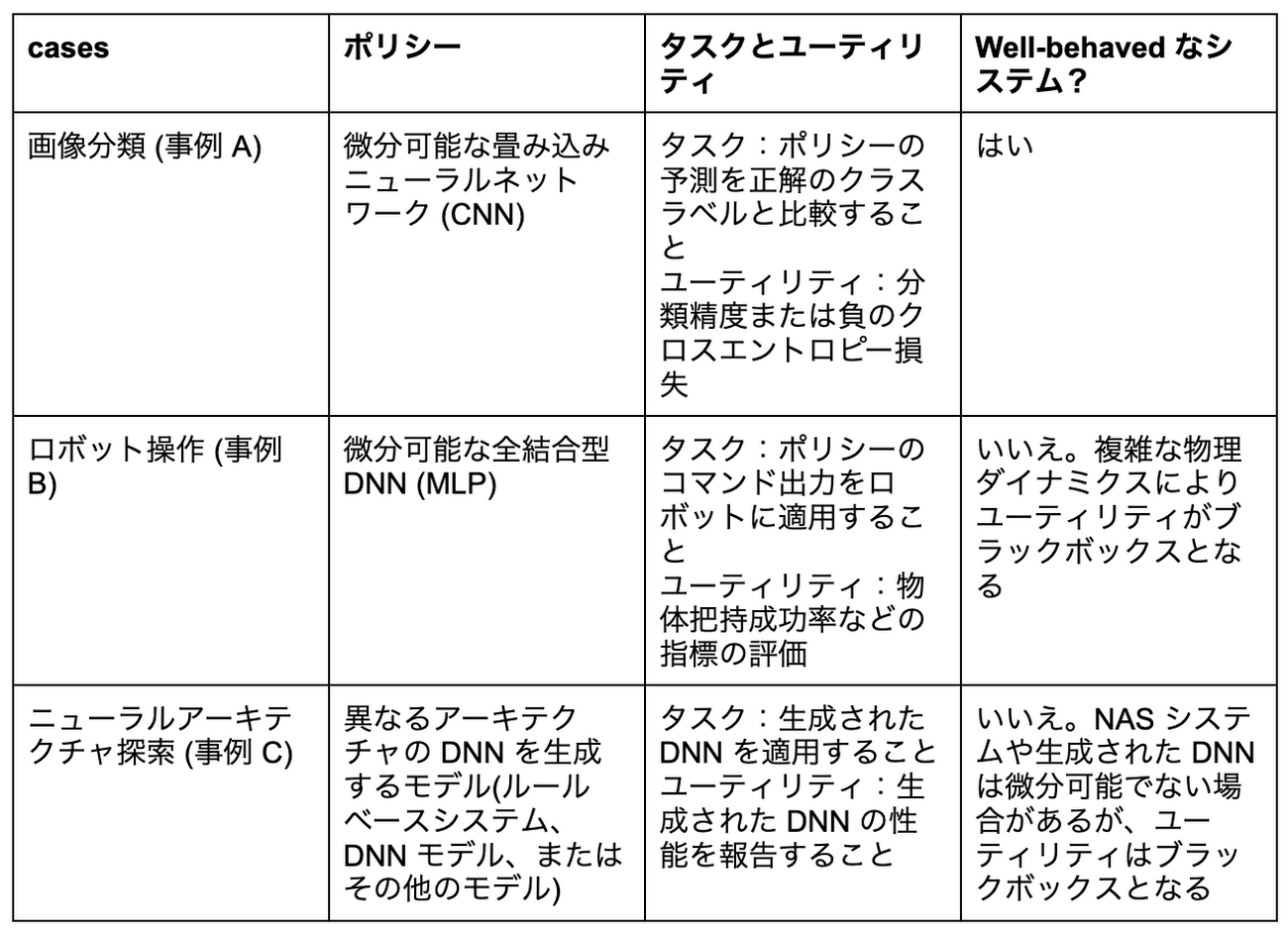
先述した三つの例のうち、画像分類は well-behaved なシステムです。ポリシーとユーティリティの間の関係はよく知られており、簡単に計算することができます。そのため、既存の DNN モデルや最適化手法を使うことができるでしょう。一方、ロボット操作のように、ポリシーの出力とユーティリティの間の数理的な関係が明確でない問題もあります。このようなタスクをブラックボックスシステムと呼び、これは well-behaved でないシステムの一例です。
Well-behaved でないシステムのさらなる例として、NAS のように、通常の微分を利用する手法ではポリシーの学習が難しいケースもあります。 例えば NAS では、NN モデルで使用可能な演算のうち最適な組み合わせを見つけることが目標ですが、これは微分を利用する手法では見つけることができません(同時に NAS はブラックボックスシステムにもあたります)
これら三つのケースをまとめると以下の表の通りになります。
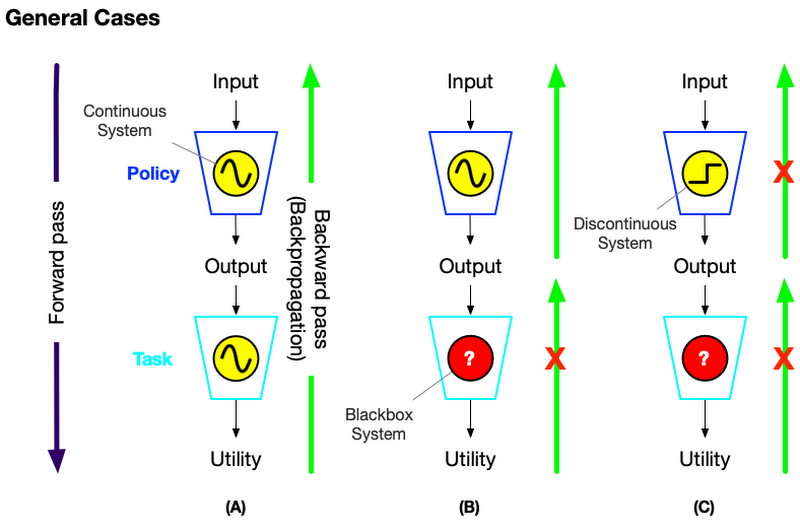
では、well-behaved ではないこれらのようなシステムに対してどのように取り組むべきでしょうか? こうしたケースでは、RL や Neuroevolution 等の手法に頼ることになります。以下の表は、これらの方法論の違いを比較したものとなります。
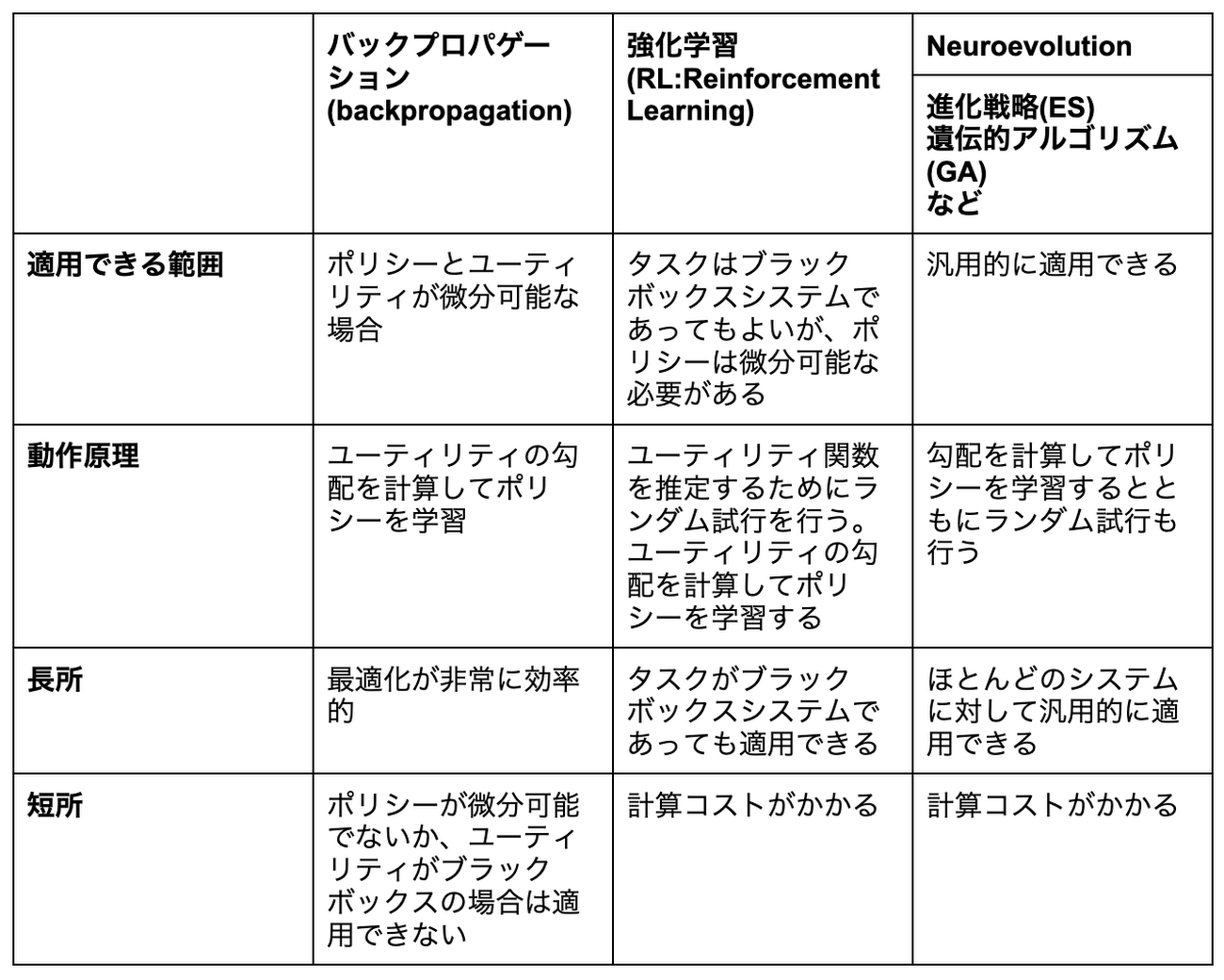
Neuroevolutionは多くの"non well-behaved"な問題を解決
上の表にある通り、Neuroevolution はバックプロパゲーションにおける制約(微分可能でない、もしくはブラックボックスなシステムに適用できない点)を取り除くことができます。 さらに、Neuroevolution はポリシーパラメータの最適化のみならず、ニューラルネットワーク・トポロジー・ルールの生成も可能な AI 技術です。進化的アルゴリズムを利用すれば、ニューラルネットワークの設計とハイパーパラメータの組み合わせをランダムな試行で探索し、不連続または微分不可能な空間でさえも最適解を見つけることができます。次のアニメーションやブログでは、Neuroevolution (具体的には ES )がどのように解を発見するかをわかりやすく示しています。
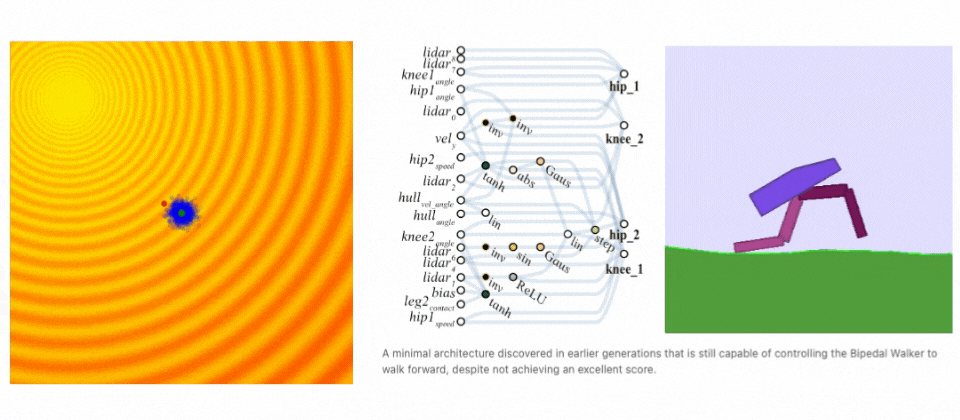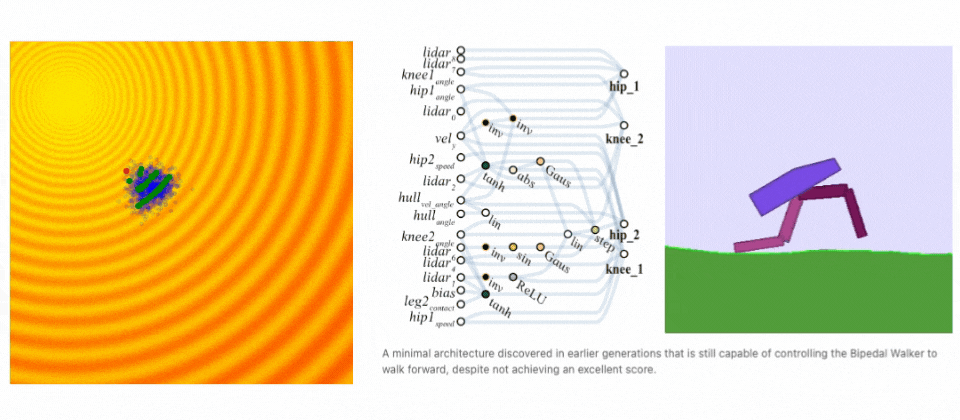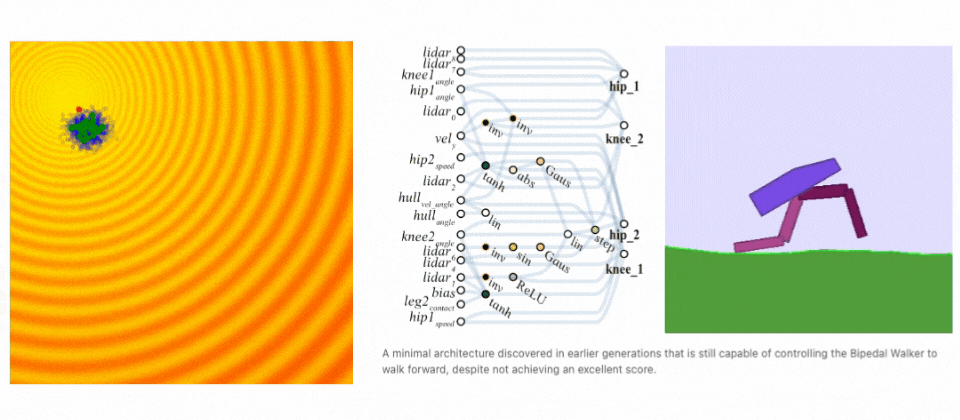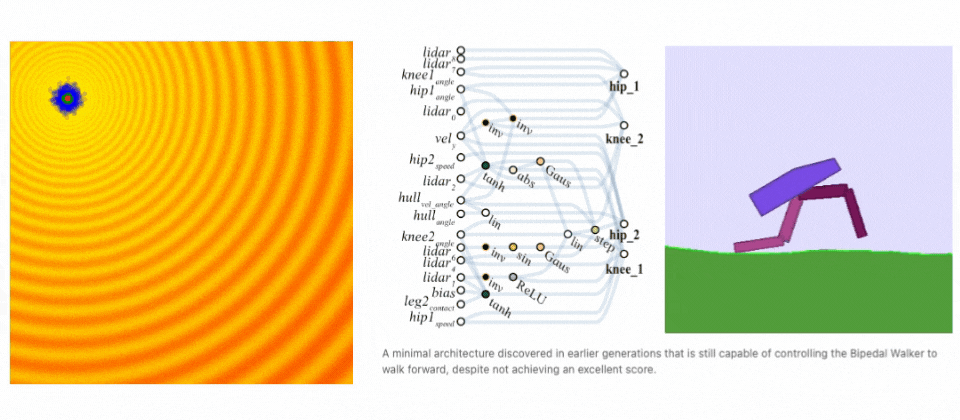
Neuroevolutionが解を発見する例. (左) 進化ステップを示すデモ。(右)二足歩行タスクにて進化するネットワークアーキテクチャ。(出典: A Visual Guide to Evolution Strategies & Weight Agnostic Neural Networks by David Ha)
EvoJAX:Hardware-Accelerated Neuroevolution ツールキット
さて、Neuroevolution はとても素晴らしいソリューションのように思えます。ではなぜ、この技術の現場での導入事例がまだあまり見当たらないのでしょうか? それは、進化戦略があまりにも多大な計算能力を必要とするという、最大の障壁の存在に起因します。
実際の Neuroevolution システムでは、効率化のためにはパラメータ評価ステップの並列化が必要となります。このプロセスは通常、パラメータを評価するためのワーカーを別個のプロセスで実行するマシンクラスタ上で行われます。このとき、各ワーカーはパラメータの候補を受け取り、そのパラメータを用いてポリシー (例:ニューラルネットワーク) をインスタンス化し、それをもとにタスクを解き、受け取ったパラメータ候補の適応度 (fitness) を Neuroevolution アルゴリズムに報告します。
このような従来の構成では、少なくとも二つの問題が生じます。一つは、多くの ML エンジニアにとって、このような評価ワーカーのためのマシンクラスタの構築と維持が容易ではないことです。二つ目はさらに残念なことに、計算がCPUに依存しているため、GPU や Cloud TPU のようなハードウェアアクセラレータのブレークスルーの恩恵を受けられないことです。
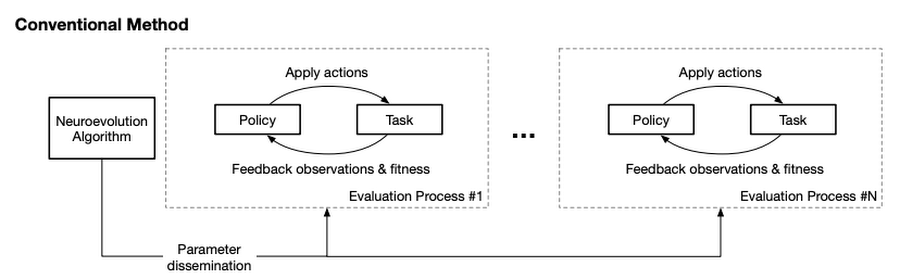
従来の Neuroevolution システムは非常に多くの CPU パワーを消費します。
こうした問題に対処して開発されたのが、スケーラブルで汎用的な Neuroevolution ツールキットである EvoJAX です。JAX 上で構築された EvoJAX では、従来のようなマシンクラスタの構成は不要となり、Neuroevolution アルゴリズムを単一または複数のTPU / GPU 上で並列に動作するニューラルネットワークと連携して動作させることが可能です。いくつかの一般的なタスクにおいて、EvoJAX は 10〜20 倍の学習速度向上を実証しています。
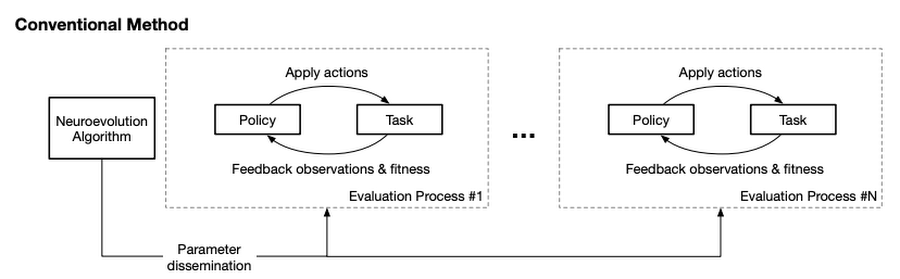
EvoJAX は TPU/GPU を利用し、Neuroevolution を 10〜20 倍高速化します。
上図の通り、EvoJAX は Neuroevolution アルゴリズム、ニューラルネットワーク、タスクの全てを、アクセラレータ上で動作するようジャストインタイムでコンパイルされるNumpy で実装することで、これらの改善を実現しました。具体的には、JAX が提供する SPMD (Single-Program, Multiple-Data) 技術を利用することで、従来のように評価プロセスごとに一つのポリシーとタスクを維持するのではなく、グローバルなポリシーとタスクのインスタンスを維持することが可能になりました。
10〜20 倍の学習速度とインフラ簡略化を実現
EvoJAX のブレークスルーにより、neuroevolution を実用的かつ効率的な最適化ソリューションとしてビジネスの課題に導入する準備は整いました。EvoJAX のサンプルコードでは、次のような興味深い例が紹介されています。
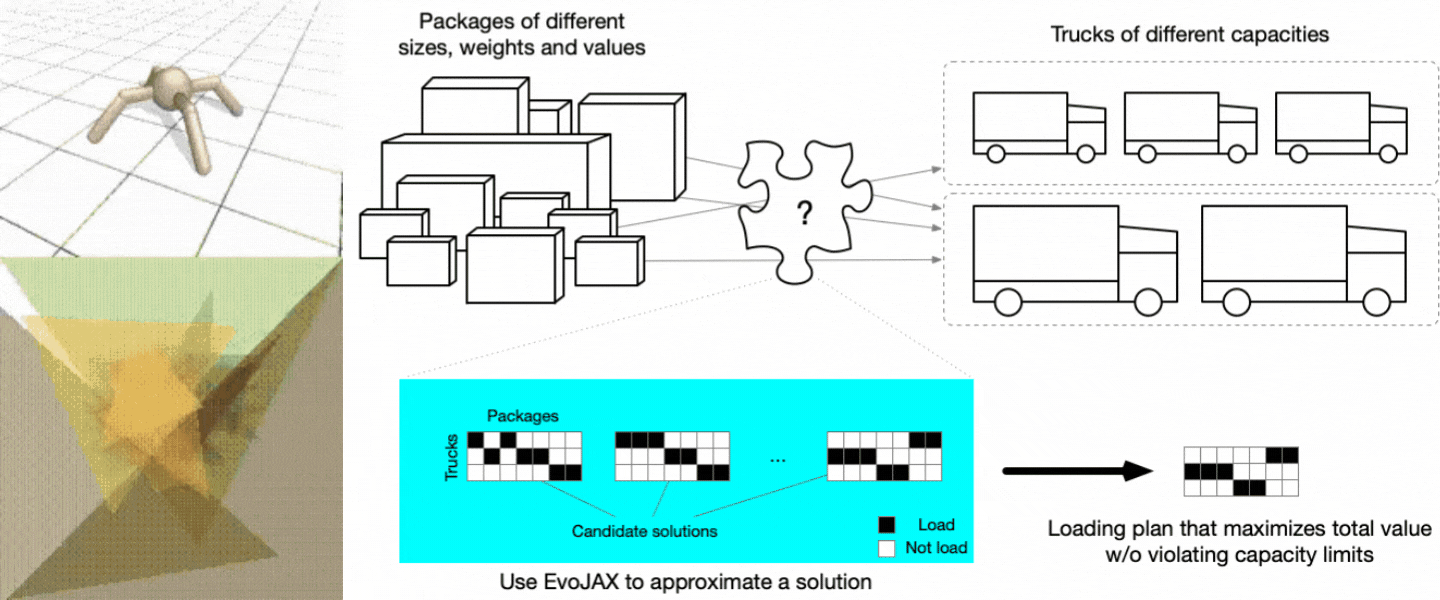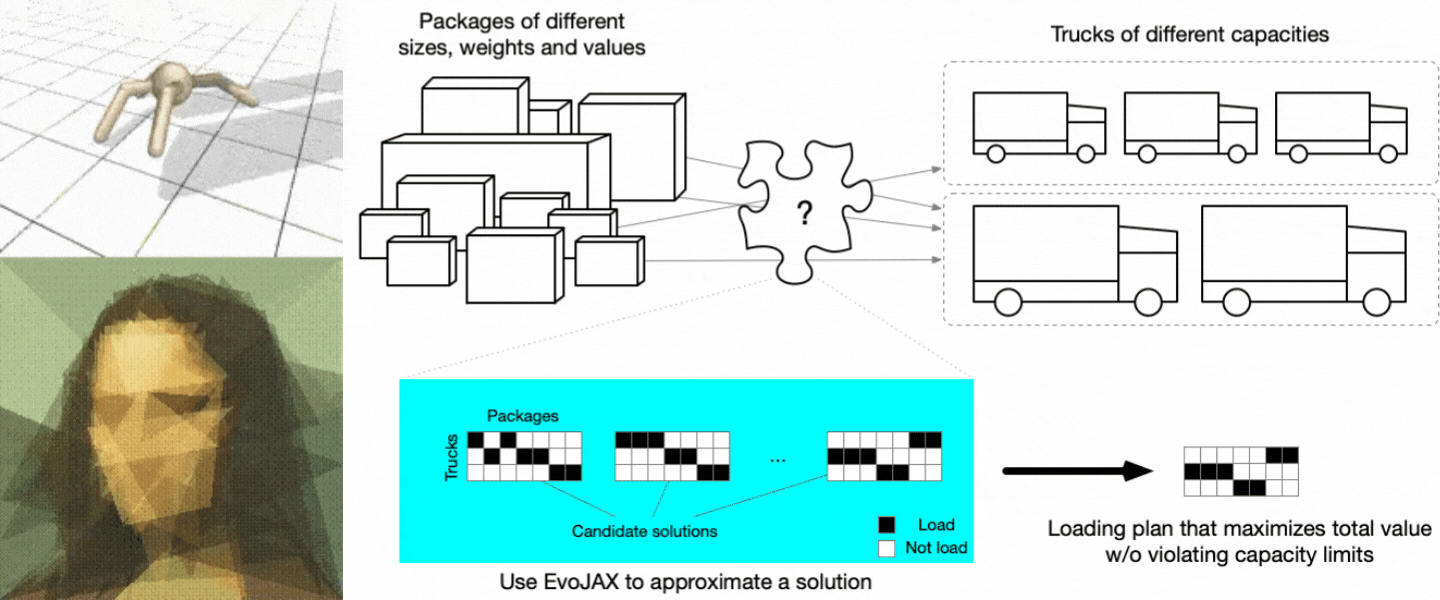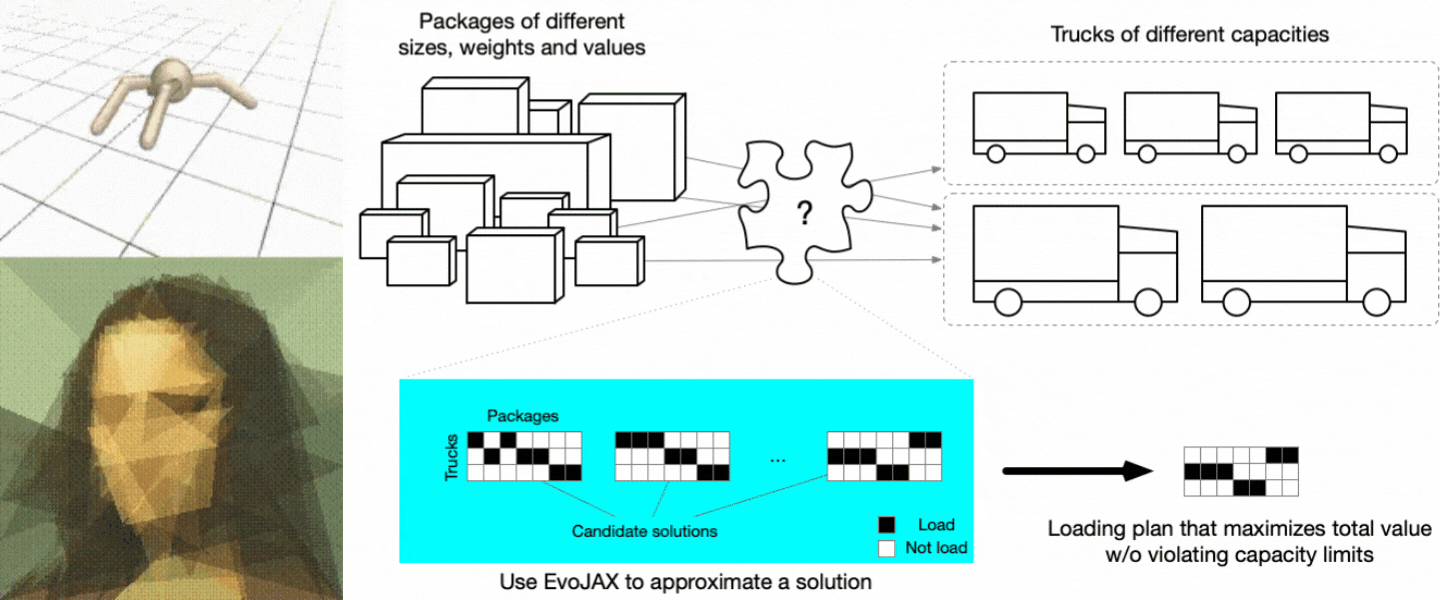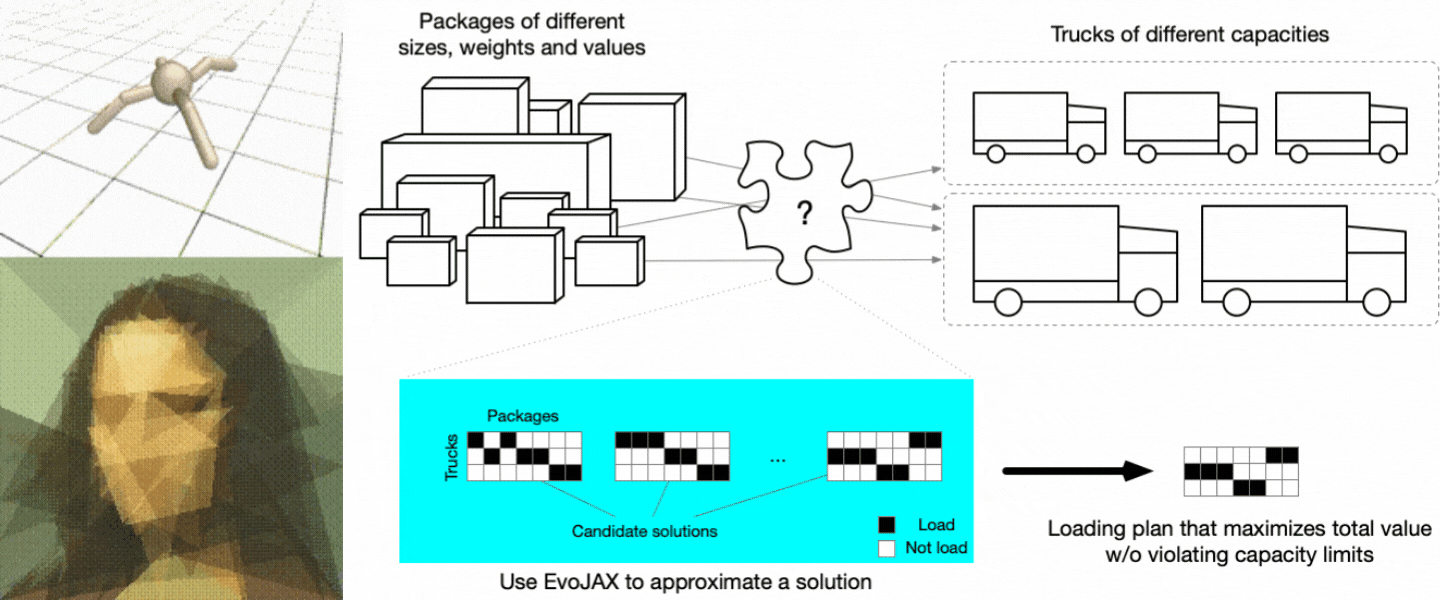
ロボット制御の問題を数分で解決できます。このタスクでは、Brax 物理シミュレータにおけるロボット移動制御を学習します。前述の通り、Brax は JAX で実装された物理エンジンであり、剛体・関節・アクチュエータで構成される環境をシミュレートします。EvoJAX を使えば、Brax を組み込んだ移動訓練タスクの作成も容易に行えます。TPU にて移動制御学習を行った結果、通常は数時間を要するところを数分で完了(冒頭の図左上)し、20 倍もの高速化を実現しました。
抽象絵画の生成を簡略化されたプラットフォームで行う例もあります。この例では、「猫」などのテキストプロンプトの内容を三角形のみで表現するcomputational creativity work の結果を再現します。元の研究では実装に複数のCPU や GPU が必要でしたが、EvoJAX を使うことで単一 GPU で効率的に高速化を行うという、これまで不可能であったことが可能になりました。さらにEvoJAXならば、複数の GPU を使用することで、この作業をリニアに高速化できます。
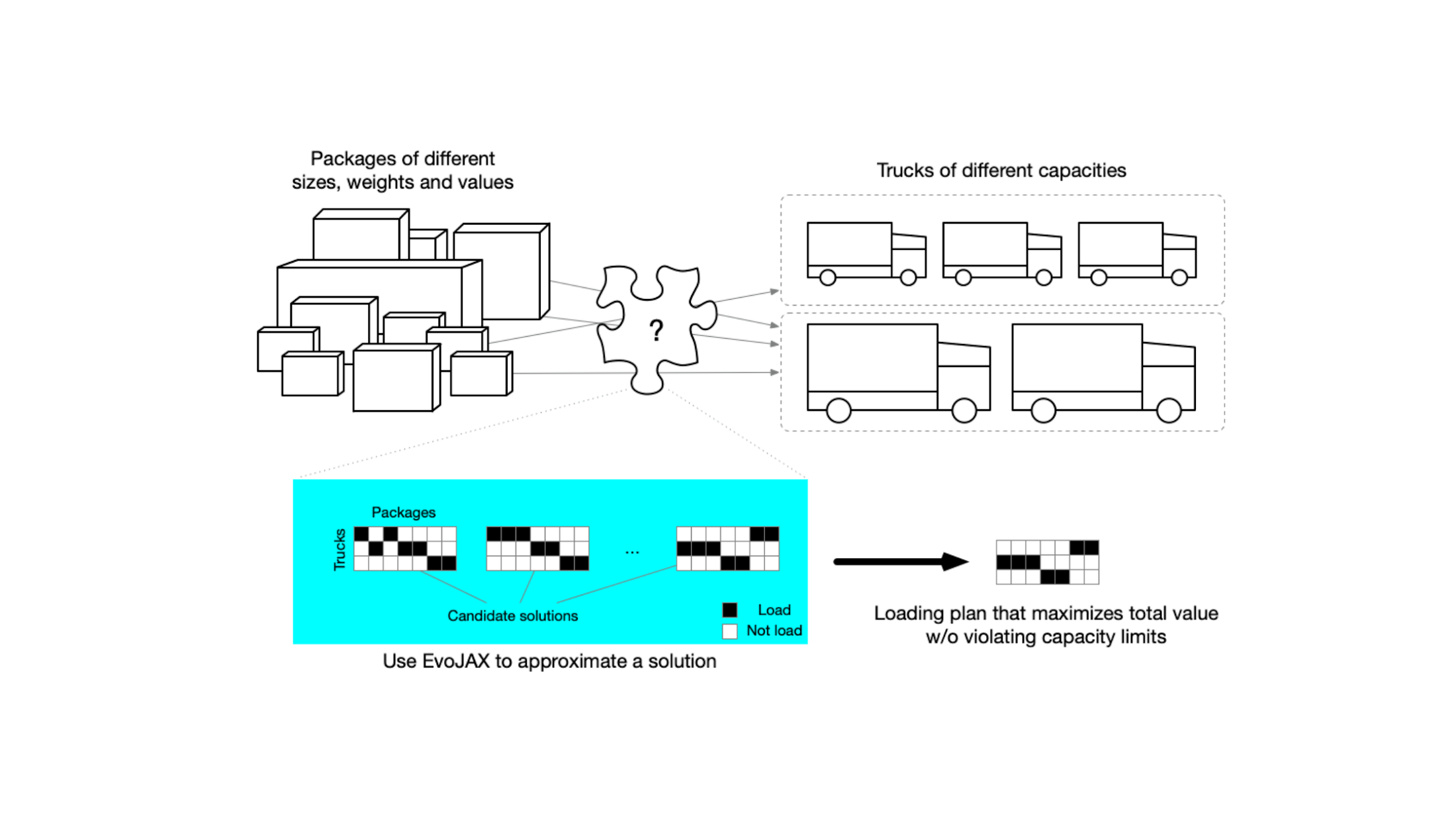
ビジネスへの適用例:トラック積み込みの問題
EvoJAX のビジネス向けの興味深いユースケースとして、「さまざまな大きさや個数の荷物をどのようにトラックに積むのが最適か」を決定するような、いわゆる多次元ナップサック問題 (Multi-Dimensional Knapsack Problem) (MDKP) への適用例を紹介します。世界的なパンデミックによる予測不可能な影響に直面している現在の状態では、こうした問題の解決は、運送会社と消費者の双方にとって大きな価値があります。
トラック積載方法の最適化、作業者へのタスクの割当、予算配分など、ビジネスで扱われる多くの課題は、それが数値最適化ではなく離散最適化である場合、それぞれに異なる文脈に現れた MDKP であるとみなせます。MDKP は、様々な価値と属性 (サイズや重量など) をもつ N 個の品目のうち K 個 (K <= N)を選択してナップサックに入れる問題です。目標は、何らかの制約条件(例えば、サイズと重量の合計がナップサックの制限を超えないこと)を満たしながら、K 個の品目の価値の合計値を最大化することです。解空間は 2^N (それぞれの品目を含むか含まないか)であり、全ての候補を総当たりして評価することは、N が大きい場合は非現実的になります。
トラック積載 (Truck loading) 問題は、倉庫 A から倉庫 B に複数のトラックで荷物を輸送するための積載計画を作成する MDKP とみなすことができます。荷物は異なるサイズ、重量、価値(金額や緊急性によって測定できる)をもち、トラックの容量も異なります。目標は、どのトラックの積載制限にも違反することなく、価値の合計が最大となる積載計画を作成することです。
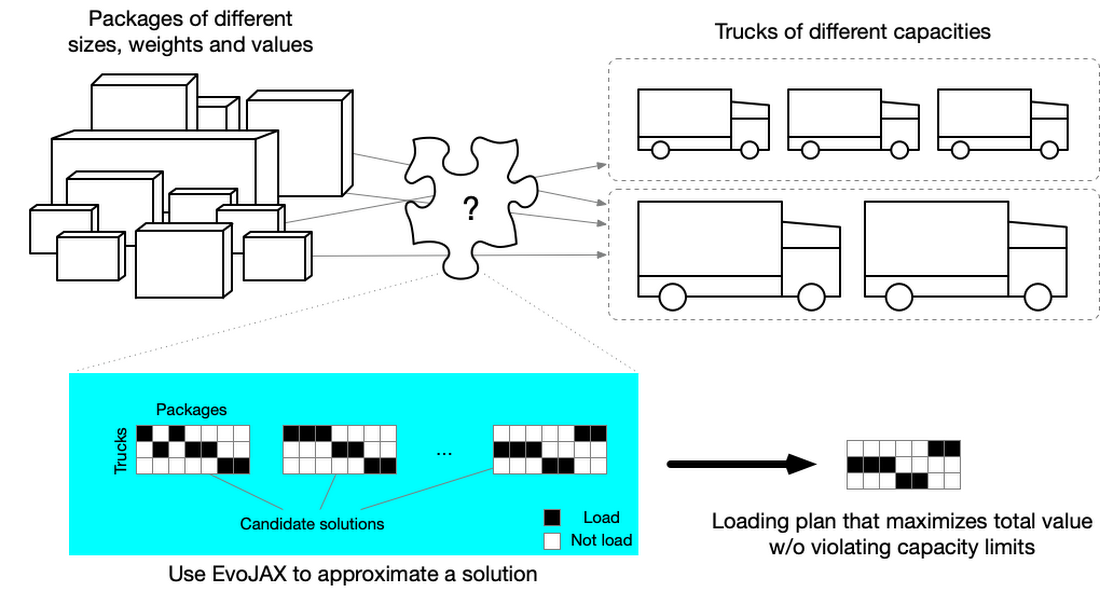
この例では、輸送する荷物が品目に、トラックがナップサックに対応します(ナップサックは複数個あります)。
MDKP は数十年にわたり、学術界・産業界の双方で研究されてきました。この問題はNP 完全 であることが証明されており、厳密解を求めることはコンピュータサイエンスにおける最も困難な問題の一つです。そのため、大抵の場合において、ユーザーは実用上の理由から近似解に頼ることになります。EvoJAX を利用すれば、従来の実装では非常に長い時間がかかるような設定(品目数が数千、数十万にわたる場合)であっても、MDKP の近似解を高速に求められます。
MDKP 問題を解くための EvoJAX サンプルコードは GitHubリポジトリで公開されています。 GPU を搭載した Google Compute Engine に EvoJAX をインストールした後、以下のコマンドでこのサンプルを実行できます。
ご興味をお持ちいただけましたか? さらに他の EvoJAX サンプルも試すことで、Neuroevolution が今やビジネスやサイエンスのさまざまな課題に対する現実的なソリューションであり、DNNや機械学習の性能を将来的にさらに高める可能性があることを実感いただけるはずです。
- Research Software Engineer, Google Research, Yujin Tang
- Developer Advocate, Google Cloud, Kaz Sato
- Research Software Engineer, Google Research, Yingtao Tian