EvoJAX: Bringing the Power of Neuroevolution to Solve Your Problems
Yujin Tang
Research Software Engineer, Google Research
Kaz Sato
Developer Advocate, Cloud AI
EvoJAX: Bringing the Power of Neuroevolution to Solve Your Problems
JAX is one of the most important machine learning (ML) frameworks at Google these days that allows both simplified user code, large-scale parallelization and orders of magnitude acceleration. The framework used in recent state of the art results include Pathways Language Model (PaLM) for language understanding, Brax and JAX MD for physics and molecular dynamics simulations, and many more.
Based on JAX’s growing popularity, it is no surprise that we shall see more works/tools using it in various areas. In this blog, we introduce EvoJAX, a hardware-accelerated neuroevolution toolkit that can solve complex problems, including those containing non-differentiable modules. The following figure shows some example tasks that users can solve with EvoJAX (see the Examples section for detailed description).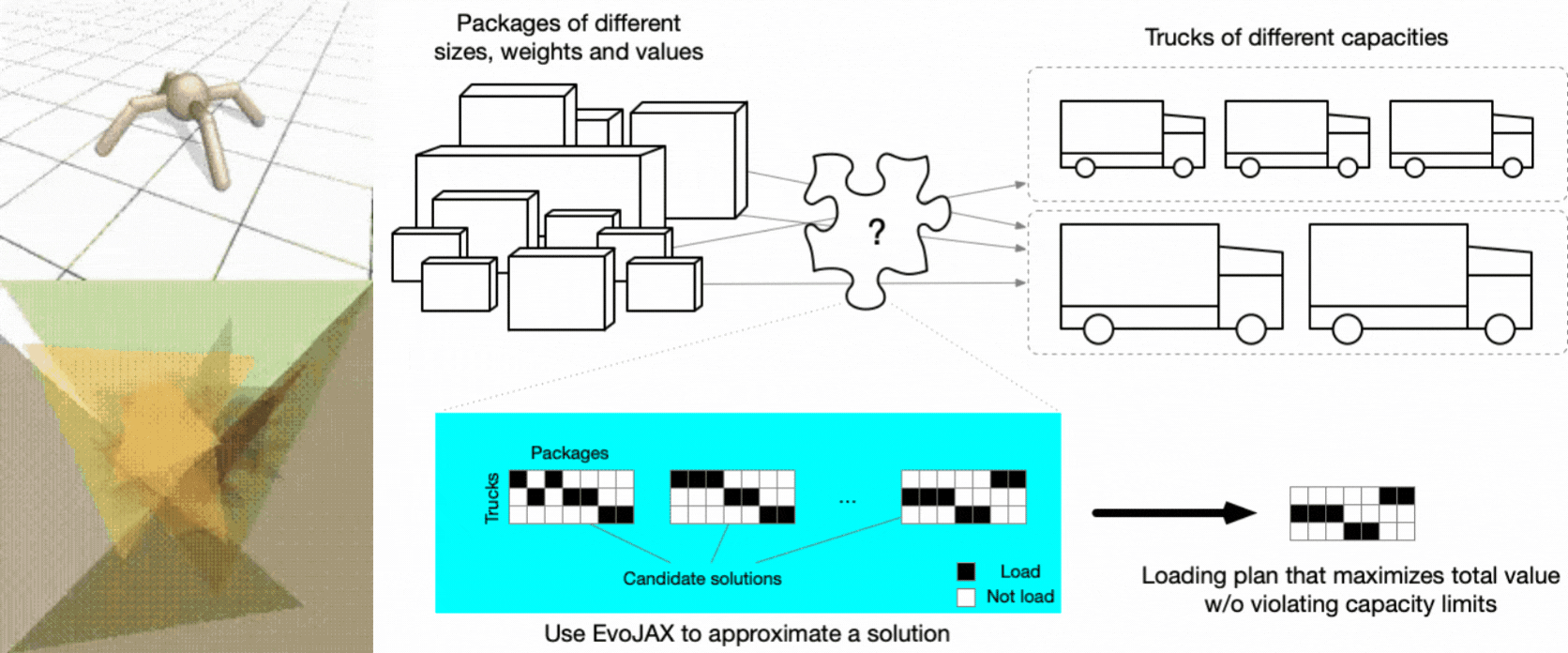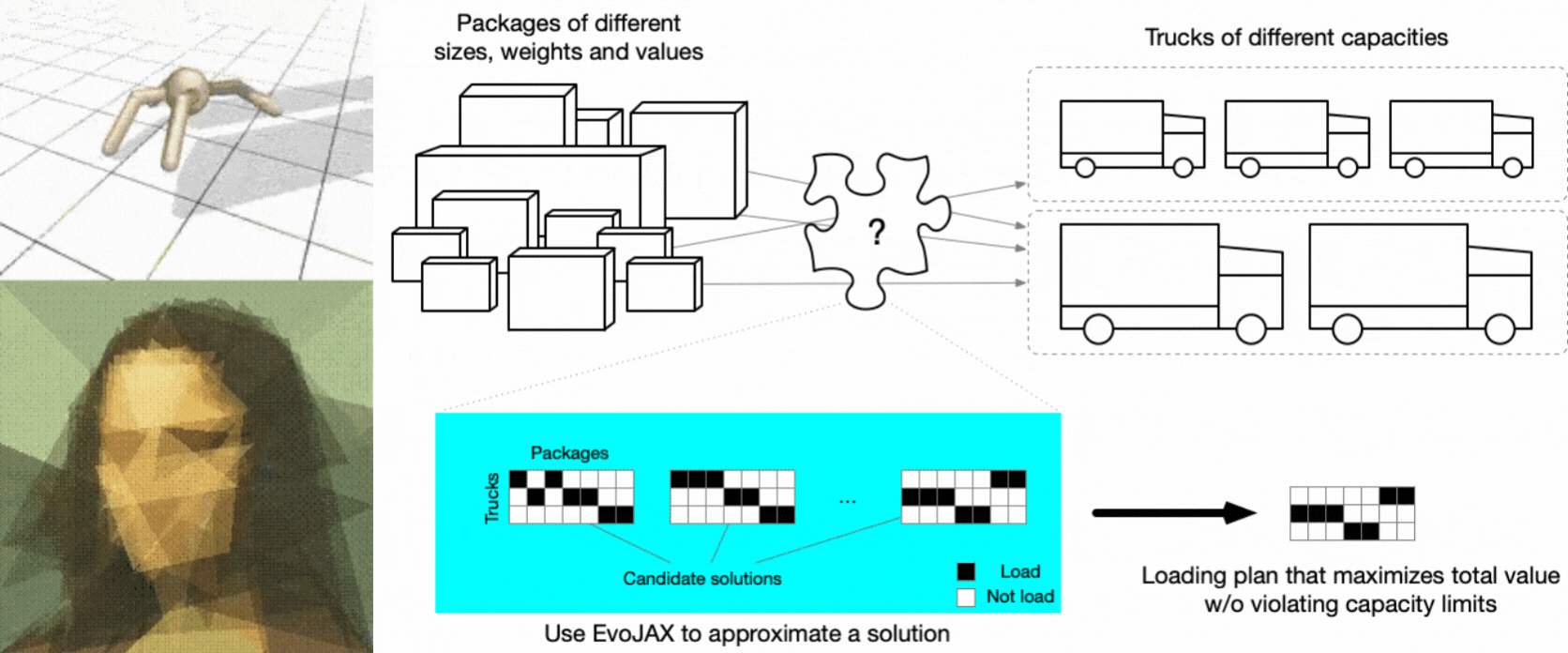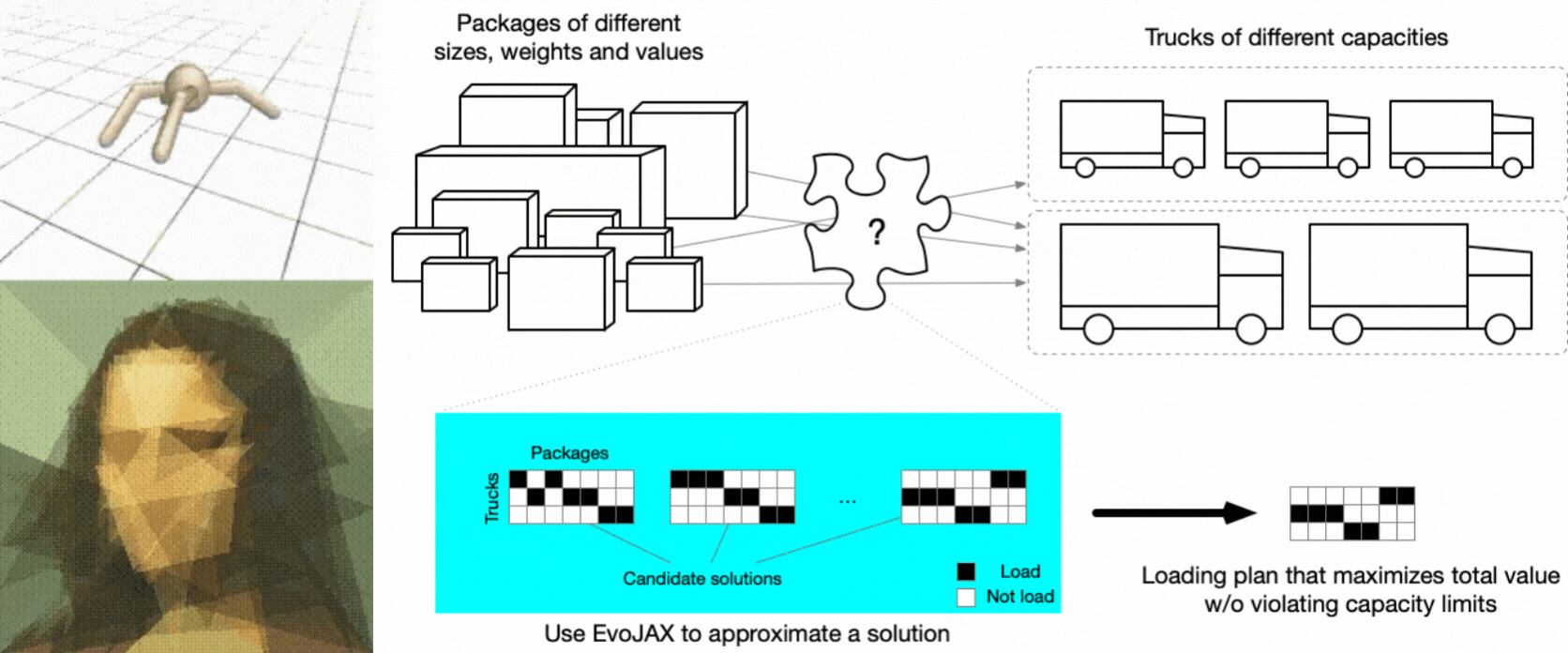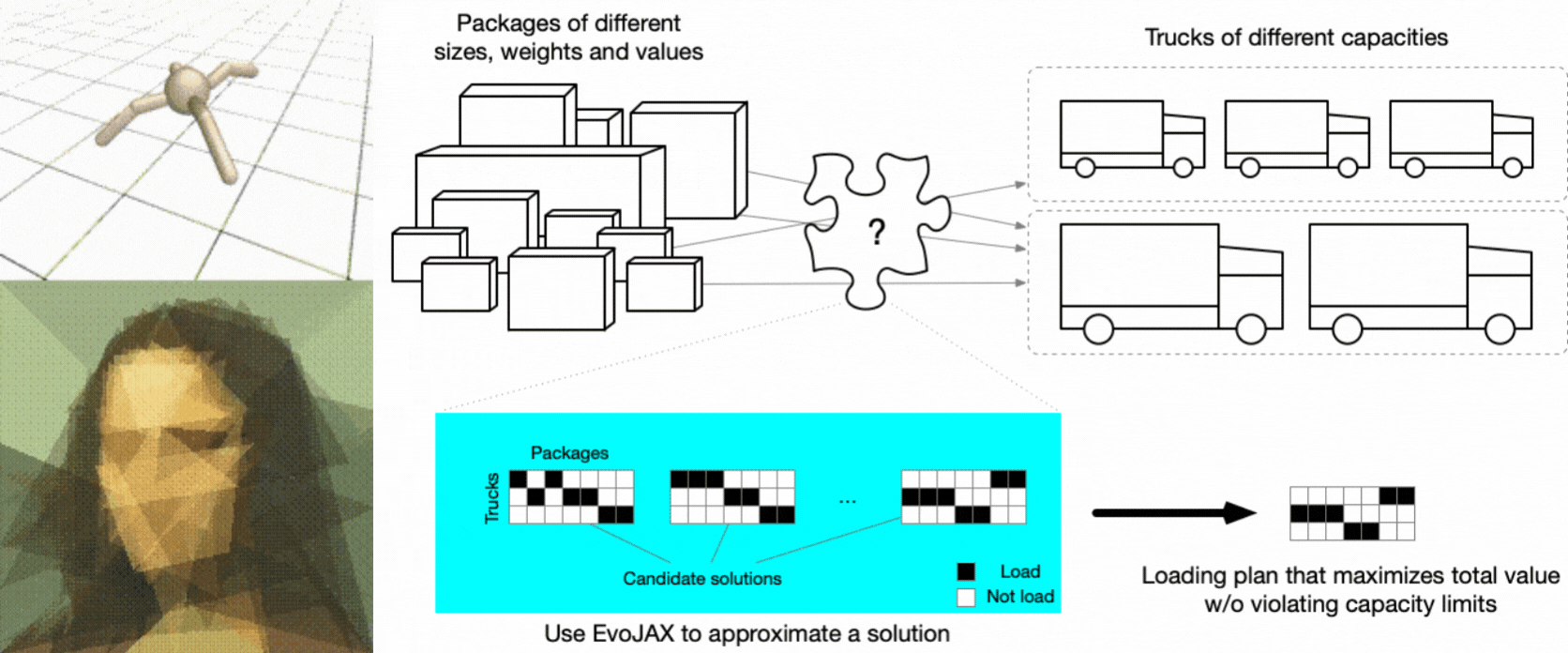
EvoJAX examples. Robotic control & Abstract painting (left) Truck loading (right).
Before we dive into the details, we would like to convince you why neuroevolution is a powerful tool that adds a significant potential to solving many real-world problems with ML methods.
Why Neuroevolution?
The success of deep learning (DL) relies largely on backpropagation, a highly effective method for training deep neural networks (DNN) using gradients, when we have a "well-behaved" system.
What are well-behaved systems? Such systems are often differentiable and thus, their intrinsic behaviors, such as how the input and output interfaces and how the parameters could be optimized, are (at least to some degree) clear to us. In addition, with the widen application of DL, we are also acquiring more experience in solving such systems using gradient-based methods, which is designed to deal with differentiability, and as a result we have a better grasp of their behavior. For these two reasons, we are relatively confident and comfortable handling such problems and we can consider them “well-behaved.”
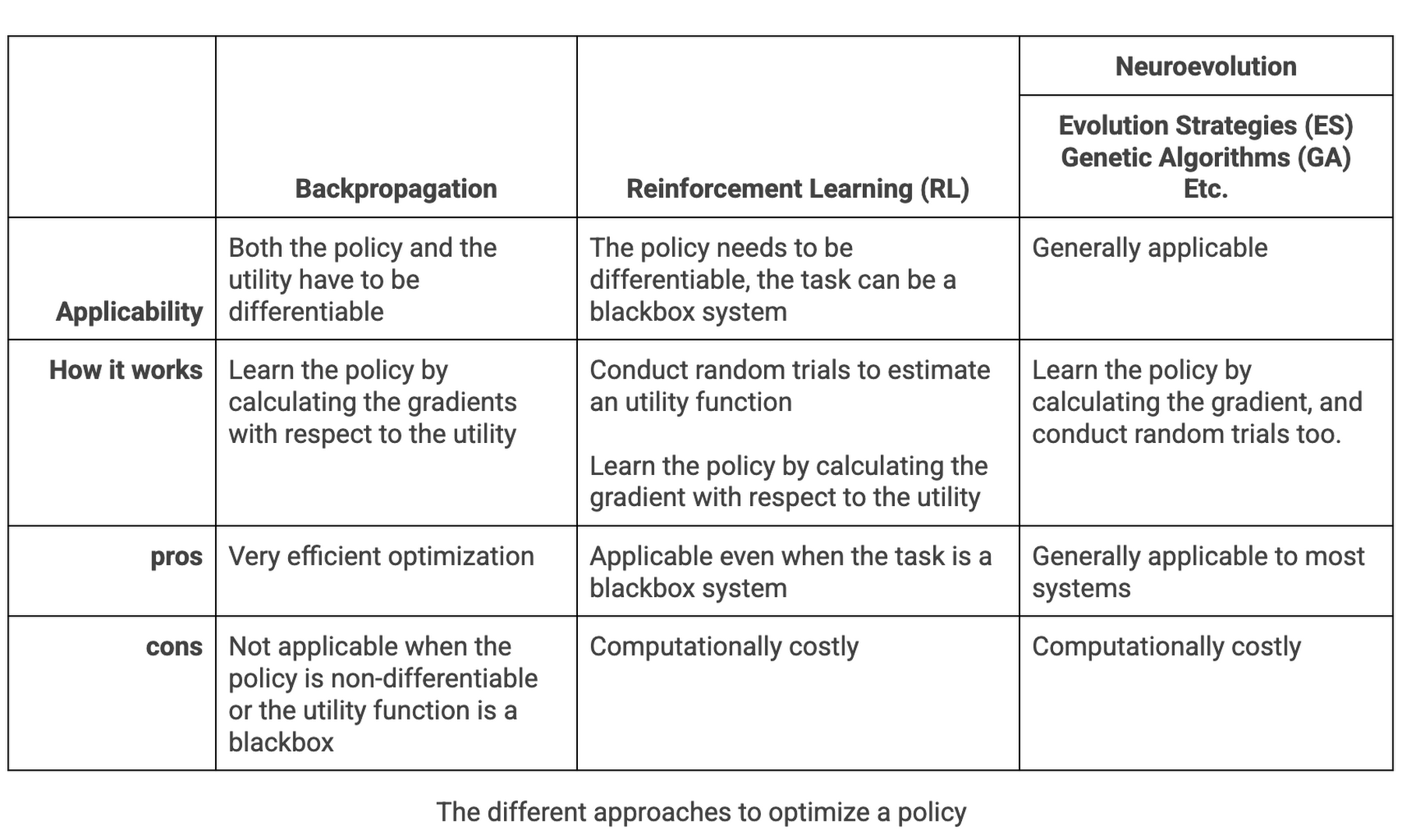
But in reality, many real-world cases are not ideal. For starters, the fact that many of us need to tune hyper-parameters of your models heavily so that the system eventually learns is an example. Moveover, backpropagation can face difficulties if the system is not differentiable or has some black-box parts. That is the reason why many real-world applications such as neural architecture search (NAS), datacenter cooling and plasma control adopt reinforcement learning (RL) or evolution strategies (ES) algorithms to solve the problems.
To better understand what is a "not well-behaved" system, we would like to introduce the concepts of Policy, Task and Utility:
Policy is the component we wish to develop to solve the task. For example, a deep model is an example of a policy if you are using DNN to solve your problem. In general, users have the design freedom and a policy can be of any form. For example, you could use a rule-based or symbolic system as well.
Task represents the problem we want to solve, it provides inputs to the policy and gives Utilities for policy evaluation. Utility is a metric to measure how well your Policy works on the task. You can define the utility for each task. For example, in supervised learning or RL tasks, we use the loss or the rewards as the utilities.
Based on these concepts, let's take a look at three examples: 1) Image classification, 2) Robotic manipulation and 3) Neural Architecture Search (NAS):
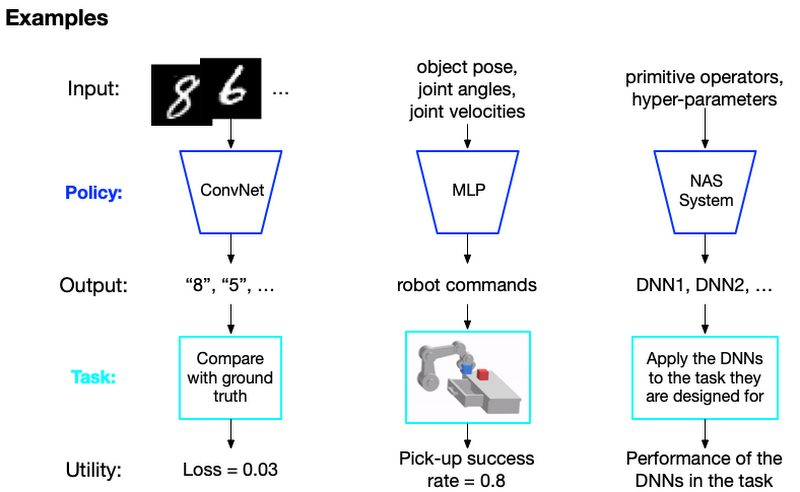
The non well-behaved system
In a well-behaved system such as the image classification case, the relationship between the policy and utility is well-known and easily calculable, you can use off-the-shelf DNN models and optimization methods. But some problems such as robotic manipulation don't have a clear computational relationship between the policy’s output and the utility. We denote such a task as a blackbox system.
Another case of a non well-behaved system is the NAS case where you can't easily learn the policy with usual differentiation. For example, NAS has to find the best combination of the possible operations used in a NN model and the combination can't be found by differentiation.
Let's summarize those cases in the table below:

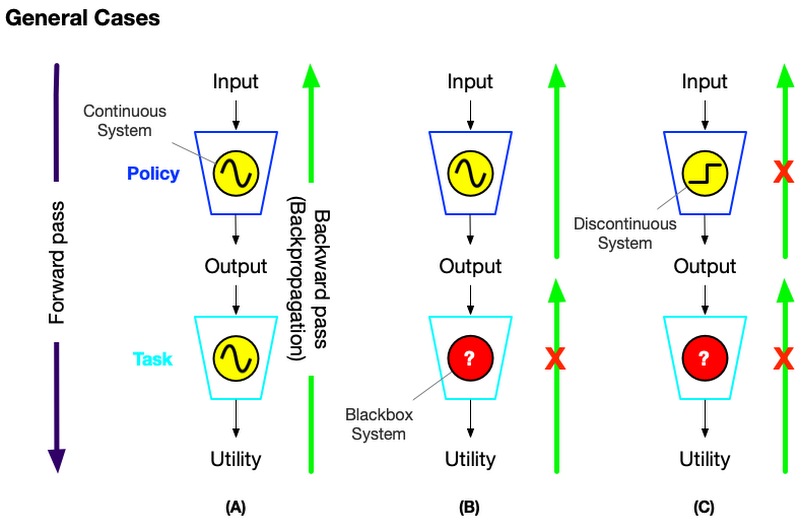
So what to do about these non good behaving systems? We resort to RL or Neuroevolution methods to handle those cases. The following table compares the difference between those methodologies.
Neuroevolution can solve many "non well-behaved" problems
As stated in the table above, neuroevolution can remove these restrictions of backpropagation. Moreover, in addition to optimizing the policy parameters, neuroevolution is a form of artificial intelligence that can also generate neural networks, topology and rules. With evolutionary algorithms, you can explore different combinations of neural network designs and hyper-parameters with random trials to find an optimal solution even in the discontinuous/non-differentiable space. The following animation/blog gives a brief idea of how neuroevolution (ES to be specific) finds a solution:
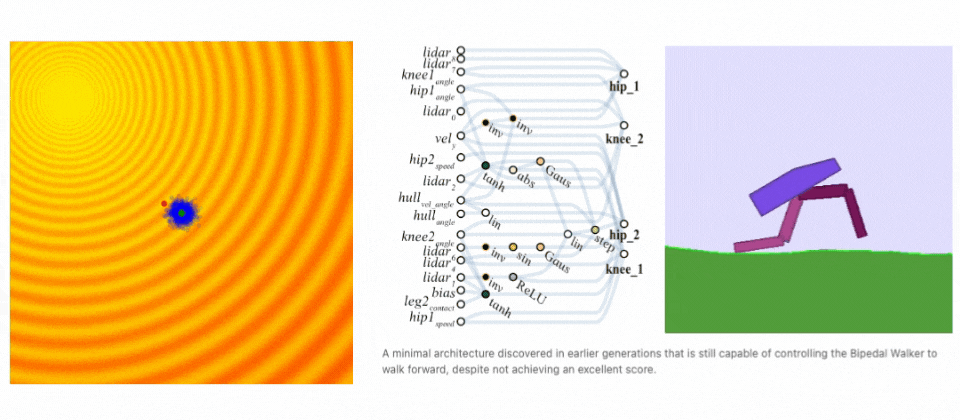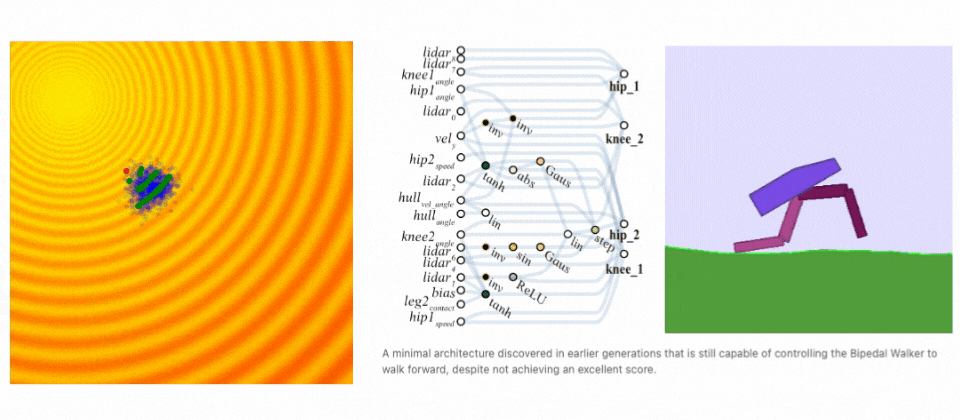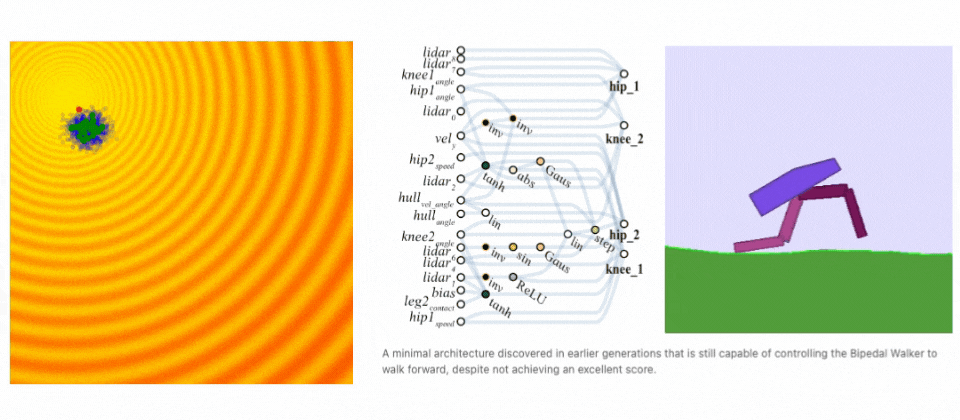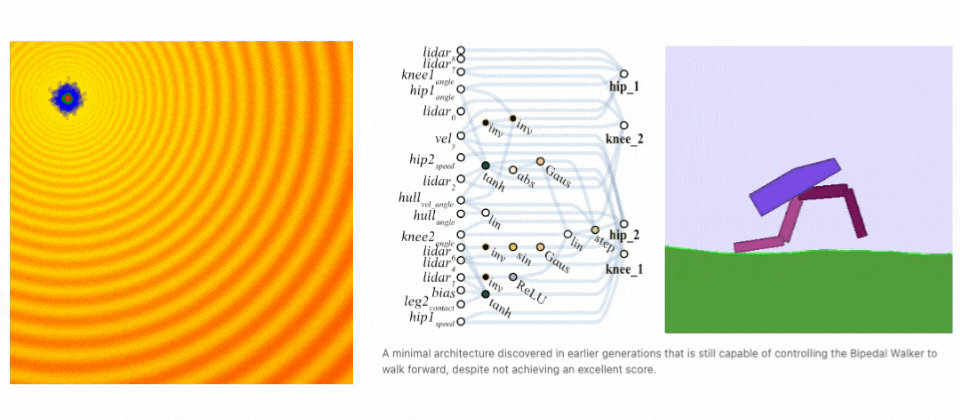
Neuroevolution finds a solution. Left: Demonstration of evolution steps. Right: Evolving network architecture for the Bipedal Walker task. (sources: A Visual Guide to Evolution Strategies & Weight Agnostic Neural Networks by David Ha)
EvoJAX: Hardware-Accelerated Neuroevolution Toolkit
OK, neuroevolution sounds cool. But why don't we see many use cases of the technology in the industry yet? The largest blocker was that the evolution strategies take too much computing power.
In real systems, the parameter evaluation step requires parallelization for efficiency. This is usually carried out on a cluster of machines where the evaluation workers run in separate processes, each of which accepts a candidate parameter, instantiates a policy (e.g., a neural network) with the parameter, uses the policy to solve the task and reports the fitness of the candidate to the neuroevolution algorithm. This conventional setup invites at least two problems: first, creating and maintaining a machine cluster is non-trivial for most ML engineers; and more regrettably, the computation relies on CPUs and does not leverage the breakthroughs in hardware accelerators such as GPUs and Cloud TPUs.
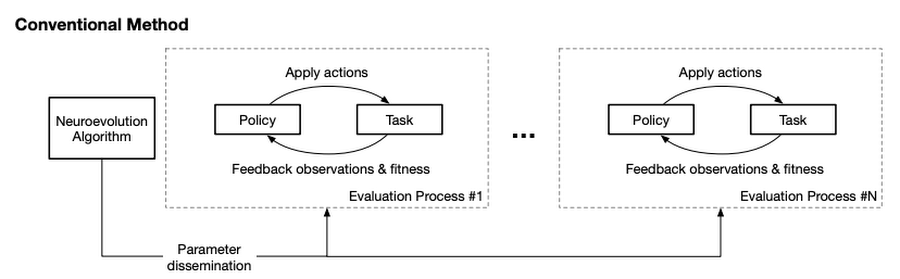
The conventional Neuroevolution system consumes too much CPU power
To address these issues, we developed EvoJAX, a scalable, general purpose, neuroevolution toolkit. Built on top of JAX, EvoJAX eliminates the need of setting up a machine cluster and enables neuroevolution algorithms to work with neural networks on a single accelerator or parallelly across multiple TPU/GPUs. On some popular tasks, EvoJAX demonstrates 10-20x training speedup.
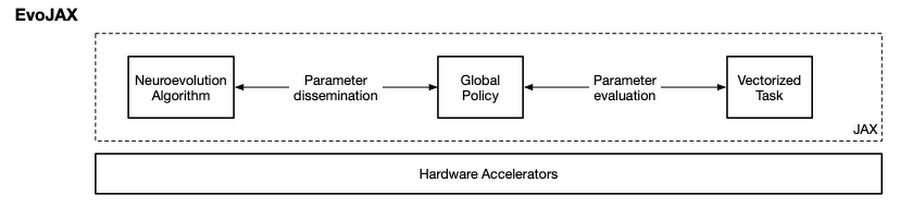
EvoJAX utilizes TPU/GPUs to accelerate Neuroevolution for 10-20x
As the figure above shows, EvoJAX achieves these by implementing the neuroevolution algorithm, neural network and task all in NumPy, which is then compiled just-in-time to run on accelerators. Specifically, the single-program, multiple-data (SPMD) technique provided by JAX allows us to maintain a global instance of policy and task instead of one for each evaluation process in the conventional setup.
Allowing 10-20x faster training and simplified infrastructure
With the breakthrough of EvoJAX, now you are ready to bring neuroevolution to your business problems as a practical and effective optimization solution. There is a suite of interesting examples in EvoJAX including the followings:
Solving robotic control problems in minutes. In this task, we learn robotic locomotion controllers in the Brax physics simulator. As we mentioned earlier, Brax is a physics engine implemented in JAX that simulates environments made up of rigid bodies, joints, and actuators. It is easy to incorporate Brax and create a locomotion training task in EvoJAX. And it takes only minutes to train a locomotion controller on TPUs (Figure 1, top left) instead of hours as is usually reported, achieving a 20x speed-up.
Abstracting painting on a simplified platform. In this example, we reproduce the results from this computational creativity work where the system expresses a text prompt (such as “cat”) by plotting with only triangles (Figure 1, bottom left). We show how the original work, whose implementation requires multiple CPUs and GPUs, could be accelerated on a single GPU efficiently using EvoJAX, which was impossible before. Moreover, with multiple GPUs/TPUs, EvoJAX can further speed up the mentioned work almost linearly.
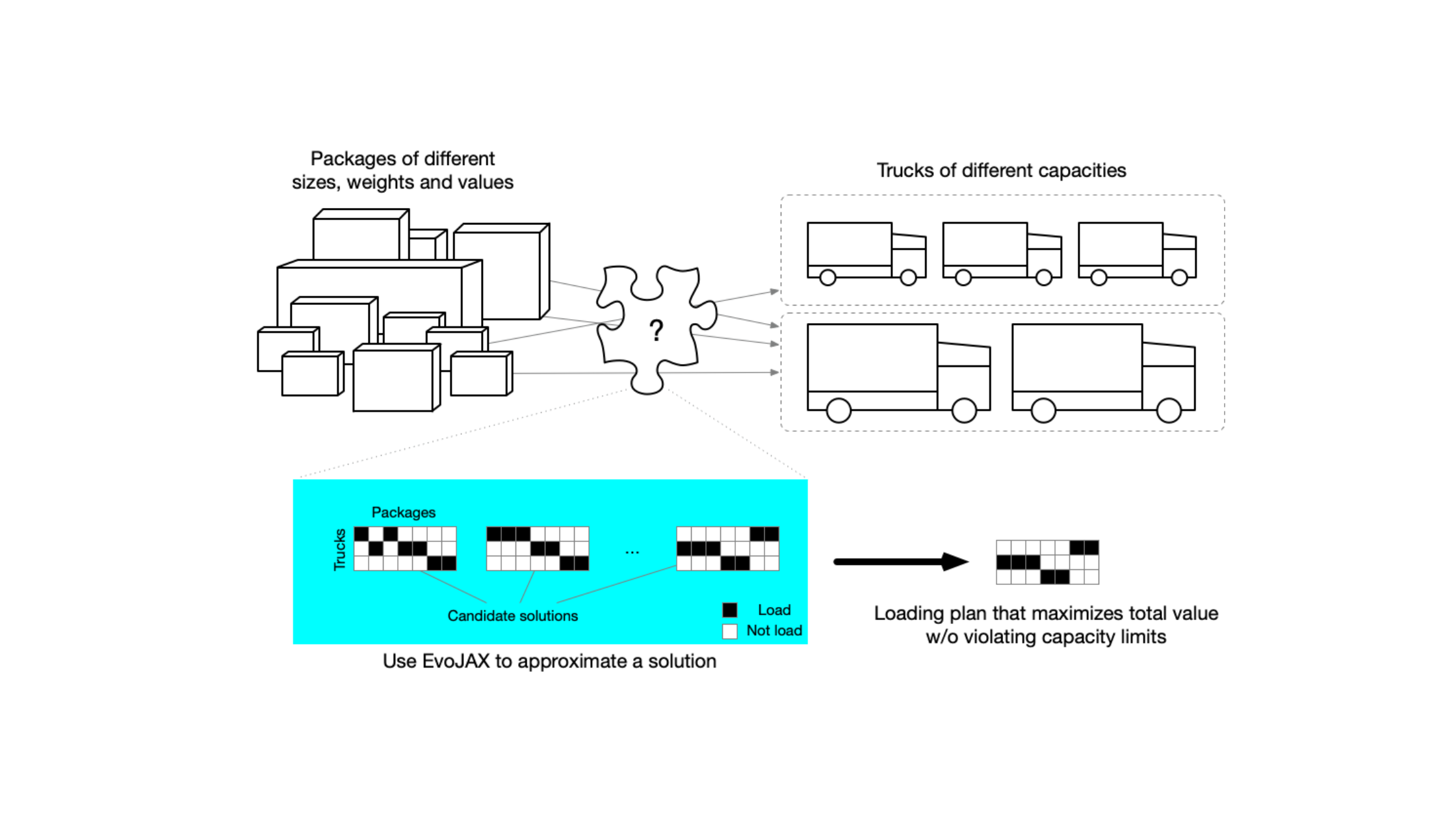
Business use case: How to fill trucks with packages?
As another interesting business use case of EvoJAX, we describe how to use the tool for solving a multi-dimensional knapsack problem (MDKP) so that we can find a solution for business problems like "how to fill trucks with different packages". Given the current context that we are facing the unpredictable impacts from the global pandemic, finding a solution for this problem is of great value for both transportation companies and the consumers.
Many business problems such as the truck loading, task assignment and budget management – problems that require discrete, rather than continuous optimization – are considered as MDKPs in different contexts. MDKP takes the selection of K out of N items (K<=N) of various values and attributes (e.g., sizes and weights), and puts them into a knapsack. The goal is to maximize the total value of the K items without violating the constraints (e.g., total size and weight do not exceed the knapsack’s limits). The solution space contains 2N possibilities (i.e., include or exclude each of the N items), evaluating every candidate in a brute-force fashion is impractical if N is large.
Truck loading problem can be viewed as an MDKP wherein a specialist is asked to generate a loading plan to transport packages from warehouse A to warehouse B with trucks. The packages have different sizes, weights and values (values can be measured in money, urgency, etc), and the trucks have different capacities. The goal is to generate a loading plan so that the total value is maximized without violating any truck’s loading limit.
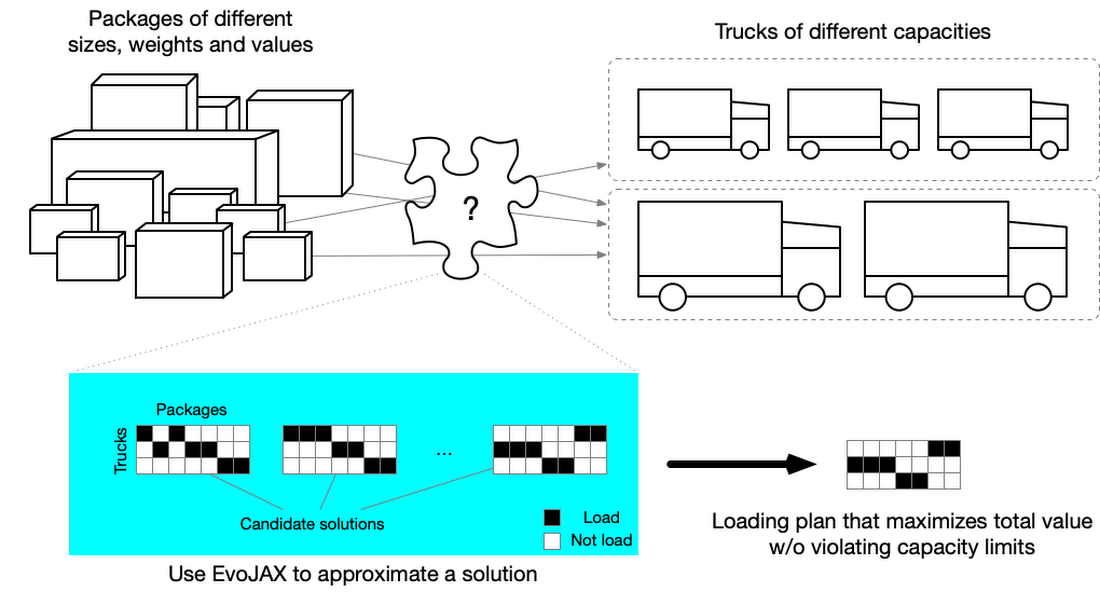
Using EvoJAX to solve a MDKP to fill trucks with packages
In this example, the packages to be transported are the items and the trucks are the knapsacks (we have multiple knapsacks). Finding a solution for this problem is of great value for both transportation companies and the consumers, especially when we are facing the unpredictable impacts from the global pandemic.
MDKP has been studied for decades in both academia and industry. It is proved to be NP complete which means finding the exact, best solution is among the hardest problems ever considered in computer science. Therefore, users often resort to approximate solutions for practical reasons. EvoJAX can approximate MDKP solutions quickly, even with thousands or hundreds of thousands items while conventional implementations take much longer time.
The EvoJAX sample code for solving the MDKP problem is available on the GitHub repository. After installing EvoJAX on your Google Compute Engine instance with GPUs, you run our example with the following command.
Interested? Please try out more EvoJAX samples so you will see Neuroevolution is now a real-world solution for businesses and may extend the ability of DNN and machine learning much more in the future.



