Django ORM での Cloud Spanner サポートの一般提供を開始
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
本日は、Django ORM での Google Cloud Spanner の一般提供サポートの開始をお知らせします。django-google-spanner パッケージは Cloud Spanner Python クライアント ライブラリを使用した、Cloud Spanner 用のサードパーティ製データベース バックエンドです。Django ORM は、リレーショナル データに Python オブジェクトをマップする、Django ウェブ フレームワークの強力なスタンドアロン コンポーネントです。基礎となるデータベースに対する優れた Python インターフェースを提供し、スキーマ変更を自動生成するツールと、スキーマのバージョン履歴を管理するツールが含まれています。この統合によって、Django アプリケーションで Cloud Spanner の大規模環境に対応した高可用性と整合性を利用できるようになりました。
ここでは以下の Django チュートリアルに沿って、新しいプロジェクトを作成し、Cloud Spanner へのデータ書き込みを開始します。この記事は、ベータ版のリリース時に公開した「Django ORM の Cloud Spanner サポートのご紹介」のブログ投稿の続編です。Django 3.2 ライブラリの使用に合わせチュートリアルを更新しました。
別のデータベース バックエンドですでに Django をお使いの場合は、Cloud Spanner への切り替えを説明した「既存の Django プロジェクトの Cloud Spanner への移行」までスキップしてください。こちらのドキュメントの確認後に、こちらのリポジトリを利用することもできます。
ベータ版リリース後の変更点
このライブラリは、Django バージョン 2.2.x および 3.2.x に対応しています。どちらのバージョンも Django プロジェクトの長期サポート(LTS)リリースとなります。必要な Python の最小バージョンは 3.6 です。
NUMERIC データ型に対応しました。Django 3.2.x サポートでは新たに JSON オブジェクトの保存と取得にも対応しましたが、現行の django-google-spanner リリースでは、JSONField 内のクエリには対応していません。この機能は開発中です。こちらで進行状況を確認できます。
また、PositiveBigIntegerField、PositiveIntegerField、PositiveSmallIntegerField のサポートを関連チェック制約と併せて追加しました。
インストール
django-google-spanner を使用するには、Python が正常にインストールされていることと、Django プロジェクトが必要です。このライブラリには、Django 2.2 系、または Django 3.2 系および Python 3.6 以降が必要です。Django を始めたばかりの場合は、ご利用のバージョンの Django スタートガイドをご覧ください。以下のチュートリアルでは、Djang 3.2 系を使用していますが、プロセスは Django 2.2 系と同様です。
Cloud Spanner API が有効になったアクティブな Google Cloud プロジェクトも必要です。Cloud Spanner の開始方法の詳細については、Cloud Spanner スタートガイドをご覧ください。
通常、Django アプリケーションは単一のデータベースを使用するよう構成されています。既存の Cloud Spanner のお客様は、Django アプリケーションでの使用に適したデータベースをすでにお持ちのはずです。まだ Cloud Spanner データベースをお持ちでない場合や、新しい Django アプリケーションを新規に開始する場合は、Google Cloud SDK を使用して新しいインスタンスの作成とデータベースの作成を行ってください。Cloud Spanner データベース バックエンド パッケージをインストールします。
次に、Django プロジェクトを新規に開始します。
django-google-spanner には django_spanner という Django アプリケーションが用意されています。Cloud Spanner データベース バックエンドを使用するには、作成するアプリケーションの settings.py ファイルで、このアプリケーションを INSTALLED_APPS の最初のエントリにする必要があります。
この django_spanner アプリケーションは Django の AutoField のデフォルト動作を変更して、(自動的に増分される連番ではなく)乱数を生成するようにします。このようにするのは、Cloud Spanner の使用における一般的なアンチパターンを回避するためです。
プロジェクト、インスタンス、データベース名を設定して、データベース エンジンを構成します。
開発中およびテスト中にコードをローカルで実行するには、アプリケーションのデフォルト認証情報を使用して認証するか、GOOGLE_APPLICATION_CREDENTIALS 環境変数を設定し、サービスアカウントを使用して認証する必要があります。このライブラリは、認証を Cloud Spanner Python クライアント ライブラリに委任します。このライブラリや他のクライアント ライブラリをすでに正しく使用できている場合は、Django アプリケーションでの認証のために新たにすべきことは何もありません。詳細については、クライアント ライブラリのドキュメントで認証の設定をご覧ください。
django-google-spanner の操作
django-google-spanner の内部では gRPC API を介して Cloud Spanner と通信する Cloud Spanner Python クライアント ライブラリを使用します。このクライアント ライブラリは、Cloud Spanner セッションのライフタイム管理も行い、正常なリクエストのタイムアウトと再試行のデフォルトを提供します。
Django ORM をサポートするため、Google は google.cloud.spanner_dbapi パッケージのクライアント ライブラリに、Python Database API 仕様(DB-API)の実装を追加しました。このパッケージは Cloud Spanner データベースの接続を処理し、ストリーミング結果の反復処理のための標準カーソルを提供して、中断されたトランザクションのクエリと DML ステートメントをシームレスに再試行します。将来はこのパッケージを使用して、SQLAlchemy など、DB-API と互換性のある他のライブラリおよび ORM をサポートできるようになることでしょう。
Django は マイグレーションと呼ばれる強力なスキーマ バージョン管理システムを提供しています。それぞれのマイグレーションには、スキーマ変更につながる Django モデルの変更が記述されます。Django では、django_migrations という内部テーブルでマイグレーションが追跡されます。また、スキーマ バージョン間でデータを移行し、アプリのモデルから自動的にマイグレーションを生成するツールが含まれています。django-google-spanner では、Django マイグレーションが DDL ステートメント(具体的には、CREATE TABLE と ALTER TABLE)に変換され、移行時に実行されることで、Cloud Spanner へのバックエンド サポートが提供されます。
Django チュートリアルに沿って、クライアント ライブラリと Cloud Spanner API のインタラクションを見ていきましょう。以下の例は、チュートリアル 2 の「データベース設定」ステップから始まり、チュートリアルの前半で mysite および polls アプリを作成済みであることを前提としています。
前述のとおりデータベース バックエンドを構成すると、プロジェクトの初期移行を実行できるようになります。
移行すると、Django が作成したテーブルとインデックスが GCP Cloud Console に表示されます。
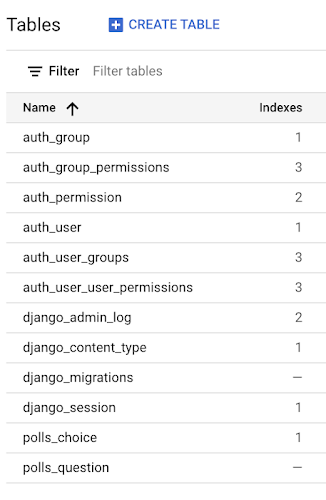
または、information_schema.tables を調べると、Django が Google Cloud SDK を使用して作成したテーブルを確認できます。
これには SPANNER_SYS および INFORMATION_SCHEMA テーブルなど、Spanner 内部のテーブルも表示されます。前述の例ではこれらを省略しています。
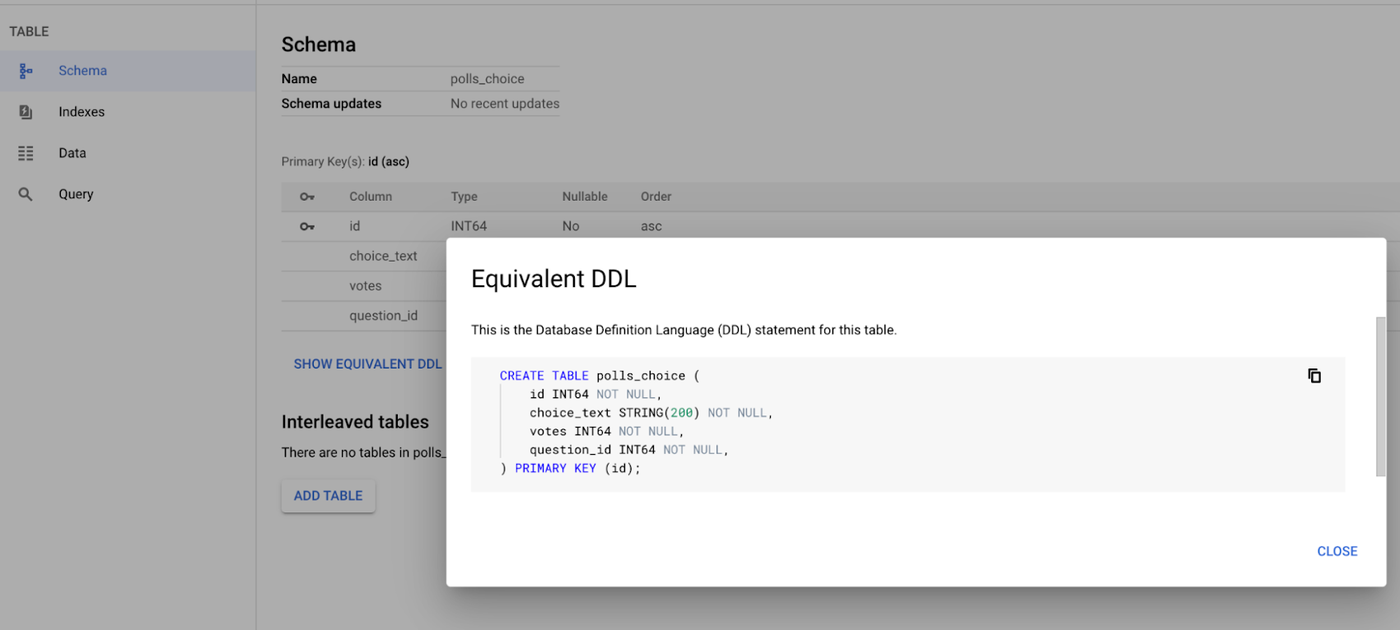
GCP Cloud Console のテーブル詳細ページの [同等な DDL を表示] をクリックして、GCP Cloud Console の各テーブルのテーブル スキーマをチェックします。
今度は、チュートリアルの「API の利用」セクションに沿って、polls アプリでいくつかのオブジェクトを作成および修正して、変更が Cloud Spanner 内で維持される様子を見てみましょう。以下の例では、チュートリアルの各コード セグメントの後ろに、Django で実行される SQL ステートメント、および得られた Cloud Spanner API リクエストのリストの一部と引数が続いています。
生成された SQL ステートメントを自分で確認するには、django.db.backends ロガーを有効にします。
空の Question テーブルのクエリ
このコードによって SQL ステートメントが得られます。
内部 Cloud Spanner API の呼び出しについては省略します。呼び出しの詳細は、前回のブログ投稿でご確認いただけます。
新しい Question オブジェクトの作成と保存
このコードによって SQL ステートメントが得られます。
既存の Question の修正
このコードによって SQL ステートメントが得られます。
既存の Django プロジェクトの Cloud Spanner への移行
Django プロジェクトを別のデータベースから Cloud Spanner に移行するには、複数のデータベース接続に対する Django の組み込みサポートを使用できます。この機能を使用すると、一度に 2 つのデータベースに接続し、一方から読み取ってもう一方に書き込むことができます。
アプリケーションのデータを SQLite から Cloud Spanner に移動する場合を考えてみましょう。既存のデータベース接続は「default」として構成済みであると仮定すると、Cloud Spanner への第 2 のデータベース接続を追加できます。この接続の名前は「spanner」です。
チュートリアルのとおり、python manage.py migrate を実行するとプロジェクト内のすべてのモデル用のテーブルとインデックスが作成されます。デフォルトでは、構成済みのすべてのデータベース接続に対して migrate が実行され、それぞれのデータベース バックエンドに固有の DDL が生成されます。migrate の実行後は両方のデータベースが同等のスキーマを持ちますが、新しい Cloud Spanner データベースは空のままです。
Django はプロジェクトのモデルから自動的にスキーマを生成するので、生成された DDL が Cloud Spanner のベスト プラクティスに沿っているのを確認することをおすすめします。Cloud Spanner にデータをコピーした後、別のマイグレーションでプロジェクトのモデルを調整できます。
Cloud Spanner へのデータのコピーには、HarbourBridge を使用してデータを PostgreSQL または MySQL データベースからインポートする、Dataflow を使用して Avro ファイルをインポートするなど、いくつかのオプションがあります。インポートしたデータが新しいスキーマと一致している限り、どのオプションも使用できますが、データベース間でデータをコピーする最も簡単でおそらく最も迅速な方法は Django 自体を使用することです。
チュートリアルで作成したモデルについて考えてみましょう。このコード スニペットでは、SQLite データベースからすべての Question と Choice を読み取ってから、それらを Cloud Spanner に書き込みます。
既存のデータベースの各テーブルの各行で、以下を行います。
行を読み取り、それを Django モデル オブジェクトとしてメモリに格納します。
主キーを設定解除します。
それを新しいデータベースに書き戻すと、新しい主キーが割り当てられます。
新たに生成された主キーを使用するには、外部キーも更新する必要があります。また、Question の主キーを変更する前に question.choice_set.all() を呼び出します。そうしないと、そのまま間違ったキーを使用して QuerySet が評価されてしまいます。
これはネイティブな例であり、理解しやすく作られていますが、必ずしも高速ではありません。Question ごとに個別に SELECT … FROM polls_choice クエリを行います。データベースですべての Choice を読み取ることがあらかじめわかっているため、Choice.objects.all().select_related('question')で 1 つのクエリに減らせます。一般的には、個別のリクエストで各行に書き込む代わりに、bulk_update を使用するなどの方法で、プロジェクトのスキーマをうまく利用したマイグレーション ロジックを書き込めます。このロジックは、Django シェルで実行するコード スニペット(たとえば前述のもの)、独立したスクリプト、Django のデータのマイグレーションの形式にできます。
以前のデータベースから Cloud Spanner に移行した後は、以前のデータベース接続用の構成を削除し、Cloud Spanner 接続の名前を「default」に変更できます。
制限事項
Cloud Spanner API と互換性がないため、Django データベース機能の一部は無効化されています。Django には総合テストスイートが付属しています。python-spanner-django でまだサポートされていない Django の機能の詳細なリストは、スキップした Django テストのリストをご覧ください。
Cloud Spanner エミュレータをお使いのお客様は、特にエミュレータは同時実行トランザクションをサポートしていないことから、Cloud Spanner サービスとは異なった動作となることがあります。制限事項および Cloud Spanner サービスとの違いのリストについては、Cloud Spanner エミュレータのドキュメントをご覧ください。
このライブラリを使用してプロジェクトをデプロイする前に、Spanner と django-google-spanner の両方のその他の制限事項のリストを事前に確認しておくことをおすすめします。制限事項は、こちらに掲載されています。
ご意見をお寄せください
お客様からのご意見をお待ちしております。特に、現在 Django アプリケーションで Cloud Spanner Python クライアント ライブラリをお使いの場合、または既存の Cloud Spanner のお客様で、新しいプロジェクトのために Django の使用をお考えの場合は、ぜひご意見をお寄せください。このプロジェクトはオープンソースです。GitHub でコメント、バグレポート、pull リクエストを行うことができます。
関連情報
- GCP データベース担当ソフトウェア エンジニア Vikash Singh




