Cloud TPU を使用した大規模レコメンダーの構築
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
パーソナライズされたレコメンデーション システムは、適切なユーザーに適切な製品やコンテンツを提示するために広く使用されています。たとえば、YouTube のおすすめ動画(「あなたへのおすすめ」)、Google Play ストアのおすすめアプリ、その他のアプリストアやコンテンツ サービスで提供されている同様のサービスがレコメンデーション システムの例として挙げられます。レコメンデーション システムとは本質的に、大量の選択肢の中から製品やコンテンツを絞り込んでユーザーに提示するものです。この記事では、TPU 埋め込み API を使用してレコメンデーション システムのトレーニング、その中でも特に大きな埋め込みテーブルを備えたモデルのトレーニングを高速化する方法を詳しく紹介します。
埋め込みルックアップ演算は、大規模レコメンデーション システム(例: ワイド&ディープ、DLRM、ディープ&クロス ネットワーク)の重要な要素であり、特に大きなテーブルが複数のアクセラレータに分散している場合には、容易にパフォーマンスのボトルネックになる可能性があります。TPUEmbedding API はこのボトルネックを解消します。TPUEmbedding API を使用すると、非常に大きなテーブルを、使用可能なすべての TPU コアの間で自動的にシャーディングまたはパーティショニングできるため、大きなテーブルの処理が効率的になります。この API と超高速なチップ間相互接続の組み合わせは、最小の TPU 構成(8 個の TPU デバイス)から TPU Pod スライス(32 個以上の TPU デバイス)へのシームレスなスケーリングを可能にします。これにより、埋め込みモデルを単一の TPU v4-8 上の約 200 GB から TPU Pod スライス上のマルチ TB にまでスケールできます。
最近投稿された大規模レコメンデーション モデルのトレーニングに関する記事によると、Snap は v3-32 システムで TPU 埋め込み API とその他の最適化手法を使用することで、4xA100 システムと比較して約 3 倍のスループット向上と 30% の費用削減を達成しました。専用のチップ間高速相互接続と最適化された TPU ソフトウェア スタックにより、他の企業も同じようにレコメンデーション モデルのトレーニング速度を向上させ、同時にトレーニング費用も削減することができます。この目標達成をお手伝いすべく、この記事では TPUEmbedding API の概要とさまざまなパフォーマンス最適化手法について説明します。
簡素化されたレコメンデーション パイプライン
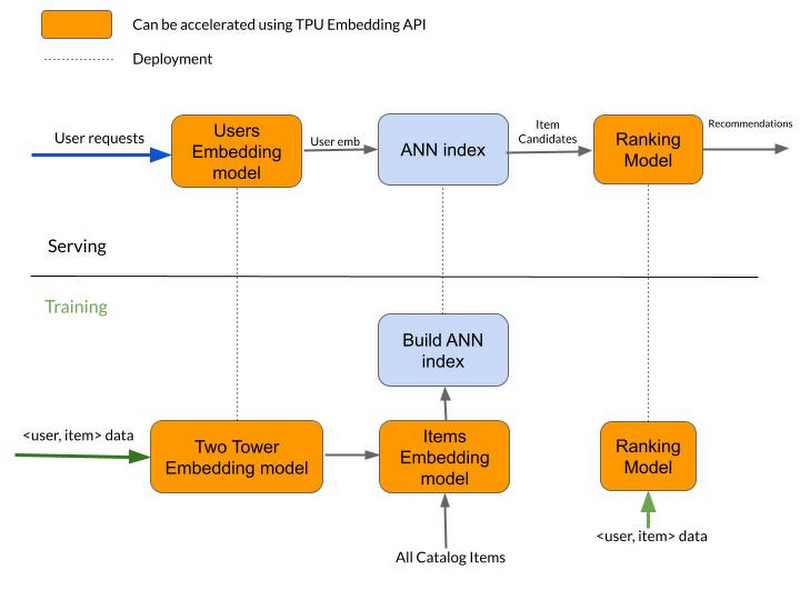
上記のパイプラインでは、TPUEmbedding API を使用して取得モデル(Two-Tower モデルなど)とランキング モデル(DLRM など)の両方のトレーニングを高速化できます。
一般的な目安として、TPUEmbedding API によってパフォーマンス上のメリットが得られるのは、テーブルの行数が 10 万行を超える場合です。
TPUEmbedding API
TPUEmbedding API を使用するには、モデル内のテーブルごとに 1 つの TPUEmbedding TableConfig(tf.tpu.experimental.embedding.TableConfig 型)を定義する必要があります。
次のことに注意してください。
vocabulary_sizeは、テーブルの語彙のサイズ(行数)です。dimは、テーブルの埋め込みディメンション(列数)です。optimizerは、テーブル単位のオプティマイザーです。これを設定すると、グローバル オプティマイザーがオーバーライドされます。combinerは、マルチホット埋め込みルックアップに適用されるアグリゲータです(スパース テンソル / 不規則なテンソルの場合、これは最後のディメンションに適用されます)。これは、ワンホットまたは密埋め込みルックアップでは無視されます。
次に、モデル内の埋め込み特徴量ごとに TPUEmbedding FeatureConfig(tf.tpu.experimental.embedding.FeatureConfig 型)を定義します。
次のことに注意してください。
max_sequence_lengthは、"max_sequence_length" > 0 かつ対象がシーケンス特徴量の場合のみ使用されます。シーケンスがこれより長い場合は切り捨てられます。output_shapeは、特徴量活性化の出力シェイプを構成するオプションの引数です。指定されていない場合は、シェイプは TPUEmbedding.build に提供されるか、ランタイム時に自動検出されます。
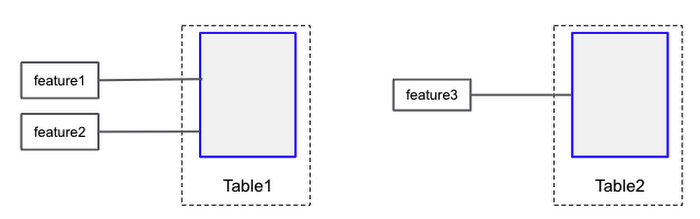
各特徴量は table 引数を通じて埋め込み table に割り当てられ、複数の埋め込み特徴量が同じ TableConfig インスタンスを使用できます。2 つ以上の特徴量が同じ TableConfig インスタンスを共有する場合、特徴量ルックアップ用の共有テーブルが作成されます。
コンパイル時にレイヤが入力のシェイプを決定できない場合は、output_shape 引数を設定できます。必要な出力シェイプを埋め込みディメンションなしで設定してください。たとえば密入力をフィードする場合、コンバイナは密入力に適用されないため、この引数は密シェイプと同じディメンションに設定できます。疎入力の場合(SparseTensor や RaggedTensor など)、この引数は必要な入力シェイプから最後のディメンションを除いたものに設定できます(コンバイナは最後のディメンションに作用するため)。
上記の構成には、2 つのテーブルと 3 つの特徴量が含まれます。最初の 2 つの特徴量は最初のテーブルでルックアップされ、3 つ目の特徴量は 2 つ目のテーブルでルックアップされます。
この後、TPU による埋め込みルックアップ用の TF2 Keras レイヤを定義します。
このレイヤは、密レイヤが適用される前にカテゴリ入力に適用する必要があります。pipeline_execution_with_tensor_core=True に設定すると、TPU 埋め込みルックアップ計算を密計算とオーバーラップさせることでトレーニング パフォーマンスが向上します。これにより、一部の重みが最新でなくなる場合がありますが、実際には正確さに対する影響は軽微です。
optimizer 引数は、テーブルレベルのオプティマイザーを持たない各埋め込みテーブル用のグローバル オプティマイザーとして使用されます。ほとんどのユースケースでは、すべての埋め込みテーブルに対して 1 つのオプティマイザーがあれば十分ですが、高度なユースケースではテーブルレベルのオプティマイザー / 学習率が必要となる場合があります。
次のコード スニペットは、関数スタイルの Keras モデルを作成します。
注: TPUStrategy の下で作成できる TPUEmbedding レイヤは 1 つのみであり、それを呼び出すことができる回数はトレーニング関数ごとに 1 回のみです。Two-Tower ネットワークの場合は、両方のタワーで同じ TPUEmbedding 呼び出しを使用する必要があります。
詳細については、TPUEmbedding のモデル作成に関するドキュメントをご覧ください。
また、TensorFlow 2 TPUEmbeddingLayer: Quick Start Colab に従い、MovieLens 100K データセットと TPUEmbedding レイヤを使用してシンプルなランキング モデルを構築することもできます。
パフォーマンスを最適化する方法
埋め込みルックアップと密計算のパイプライン化
TPUEmbedding API の実装は、パフォーマンスの向上のため、埋め込みルックアップを密計算と並列に実行することができるようになっています。レイヤ コンストラクタで pipeline_execution_with_tensor_core=True に設定すると、ステップ n+1 の埋め込みルックアップをステップ n の密計算と並列に実行できます。より具体的には、ステップ n+1 のルックアップは、ステップ n の埋め込みテーブルの更新より前に行われます。これは一般には数学的に不正確ですが、ステップ n とステップ n+1 で使用される ID はほとんど重複しないため、ほとんどのモデルでこの手法は安全であることがわかっています。
テーブルのサイズに基づいてシャーディングするテーブルを選択する
小さな埋め込みテーブル(10,000 行以下)を TPU コア間でシャーディングすると、各 TPU コアの HBM メモリがあまり節約されずに TPU コア間のネットワーク通信が増加するため、最適ではない可能性があります。PartialTPUEmbedding API を使用すれば、大きなテーブルを通常の TPUEmbedding API によってシャーディングしながら、小さなテーブルは各 TPU コア上でミラーリングできます。
PartialTPUEmbedding API は tfrs.layers.embedding.TPUEmbedding API によく似ていますが、size_threshold 引数が追加されています。語彙サイズが size_threshold より小さいテーブルはシャーディングされず(すべての TPU コアに複製される)、語彙サイズが size_threshold より大きいテーブルはシャーディングされます。
入力パイプラインの最適化によるさらなるパフォーマンスの向上
これで、TPU 上の埋め込みテーブル ルックアップは TPUEmbedding API によってかなり高速になりました。次は、入力パイプラインがボトルネックになる可能性があります。入力データ パイプラインの最適化の詳細については、tf.data API によるパフォーマンスの改善ガイドと TensorFlow Profiler による tf.data パフォーマンスの分析ガイドをご覧ください。
サービング用にモデルをエクスポートする
サービングのためにモデルをエクスポートする方法は複数あります。最も簡単な方法は、次のようにすでにトレーニング済みのチェックポイントから始めることです。
TPUEmbedding レイヤはテーブルのサブセットのサービングをサポートしており、これは共同トレーニングされたモデルの一部をエクスポートする場合に役立ちます。
上記のメソッドを使用して SavedModel を作成する際は、モデル全体を読み込んで保存する十分な容量がある単一の VM が必要です。TPUEmbedding レイヤはマルチ TB の埋め込みテーブルをサポートしているため、これは難しい場合があります。そのような場合は、代わりに次の方法を使用できます。
次のステップ
この記事では、TPUEmbedding API と、この API を利用して取得モデルやランキング モデルのトレーニングを高速化する方法を見てきました。取得モデルをトレーニングした後、そのモデルを介してトレーニングされた埋め込みを使用して近似最近傍探索(ANN)インデックスを作成できます(Vertex AI のマッチング エンジンを使用した低レイテンシの ANN ルックアップをデプロイできます)。最後に、エンドユーザーへの最終的なレコメンデーションの生成に使用されるランキング モデルをエクスポートする方法をいくつか紹介しました。
TPUEmbedding API は、TensorFlow Recommenders ライブラリでオープンソース化されています。また、TensorFlow 2 では、よりきめ細かい埋め込み構成を作成できるミッドレベル TPU Embedding API も提供されています。DLRM および DCN v2 ランキング モデルのオープンソース実装の例は、TensorFlow Model Garden で探すことができます。これらのモデルを Cloud TPU でトレーニングするための詳細なチュートリアルについては、Cloud TPU ユーザーガイドをご覧ください。
この記事で示したレコメンデーション パイプラインは簡素化されたバージョンです。実際には、どの実装を選択するかは複数の要因によって決まります。こちらの記事は Google Cloud Platform でレコメンデーション モデルを構築してサービスを提供するためのさまざまな方法をまとめたもので、実装の参考になります。
独自のアーキテクチャと専用のチップ間高速相互接続を備えた TPU は、カスタム レコメンデーション モデルをトレーニングしてレコメンデーション サービスを提供するための理想的なプラットフォームです。さらに、これらのモデルのトレーニングや推論を大幅に高速化するため、ここで紹介した TPUEmbedding API を使用することを強くおすすめします。
皆様の仕事にぜひお役立てください。


- Cloud TPU 担当ソフトウェア エンジニア Gagik Amirkhanyan
- TensorFlow TPU 担当ソフトウェア エンジニア Bruce Fontaine


