BigQuery のバックアップと障害復旧の戦略
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
近年、多くのユーザーが BigQuery を Google Cloud 内のデータにとってのランディング ゾーンとして選択しています。BigQuery は、高いデータの耐久性を提供するように設計されています。データは同期的に 2 つのアベイラビリティ ゾーンに書き込まれ、ゾーン内では消失訂正符号化を使用して書き込まれるため、複数のディスク障害でも確実にデータが復元できるようになります。このブログを執筆した 2022 年 10 月時点で BigQuery は、99.99% の可用性と非常に高い耐久性を持ち、ゾーンレベルの致命的な障害から自動で復旧できるように構築されています。
多くのデータ アプリケーションが、BigQuery でネイティブに提供している水準を超えた障害復旧要件を有するようになってきています。たとえば、一部の業界の規制要件は、高いデータ耐久性の要件を義務付けています。こうした要件に対応するためには、データ用に堅牢なバックアップと復元の戦略を立て、リージョン内の BigQuery データセットに永続的なデータ損失が発生するような場合に備えて、アプリケーションが耐久性および可用性の要件を満たせるようにする必要があります。
このドキュメントでは、異なる障害モードとそれらの障害が BigQuery 内のデータに及ぼす影響について説明します。加えて、障害発生時もデータやワークロードの可用性を維持するための、さまざまなバックアップ戦略と障害復旧戦略についても説明していきます。
異なる障害とその障害による BigQuery のデータへの影響
まずは、データ損失につながるような障害と、無害な障害の違いを理解することが重要です。一般にソフト障害とは、停電やネットワーク損失イベントなどのような、ハードウェアに実際の破損が生じない障害と定義されており、ソフト障害ではデータ損失は発生しません。ハード障害とは、ハードウェアに実際に障害や破損が生じてデータ損失イベントにつながる可能性がある状況です。
その他にも、ソフトウェアのバグという潜在的な障害のタイプもあります。こうした障害には、エンドユーザーによって書かれた SQL コード内のバグか、プロダクト コード自体にあるバグが含まれます。BigQuery 内のデータは変更不可です。つまり、一度書かれたデータは修正されません。変更が行われると、新しいバージョンのデータが書き出されます。BigQuery では、過去 7 日間に追加、更新、削除されたすべてのデータを保持しています。つまり、BigQuery では 7 日間のタイムトラベルが可能だということです。この機能があれば、ユーザーが行った操作によるデータ損失またはソフトウェア レベルのエラーからの復元が可能です。
ゾーンレベルおよび下位レベルの障害
BigQuery では、データスロットとコンピューティング スロットの両方で、ゾーンレベルの冗長性を提供しています。つまり、BigQuery は、マシンレベルの障害やディスクレベルの障害が発生したときに、ユーザーの目に見えるサービスの可用性の低下やデータの損失がないように設計されているのです。
短いゾーンレベルの途絶は、頻繁には起こりませんが発生します。しかし、BigQuery の自動化により、重大な中断が発生してから 1~2 分以内で、クエリは別のゾーンにフェイルオーバーされます。すでに処理中のクエリは、すぐには復元されないかもしれませんが、新しく発行されたクエリは復元されます。これは、新しく発行されるクエリが想定どおり完了する一方で、処理中のクエリは完了までに長時間を要することから表面化することになります。
たとえ 1 つのゾーンが長期間にわたって利用できないか、致命的な事態によって 1 つのゾーンでハード障害が発生するといった事態になったとしても、BigQuery では同期的に 2 つのゾーンにデータを書き込むため、データ損失が起こらないと考えられます。また、十分なコンピューティングの冗長性を確保することで、ゾーンレベルの障害もカバーしています。そのため、ゾーン損失に直面したとしても、ユーザー側のサービス障害には陥らないと考えられます。
リージョン障害
他のレベルのソフト障害と同様に、通常、リージョン レベルのソフト障害ではデータ損失は発生しません。しかしながら、リージョン全体でインフラストラクチャが損失するような致命的な事態が生じたときには、データ損失が発生する可能性もあります。そういった場合に発生するいかなるサービス障害やデータ障害にも対応できるように、サービスの一部としてネイティブに提供されているソリューションの他にも、バックアップと障害復旧のソリューションをニーズに応じて構築しておく必要があります。
障害復旧用の設計を始める前の留意点
戦略を選ぶ前に RPO、RTO を定義する
RPO - 目標復旧時点を意味します。データが失われる可能性のある最大の範囲を定義します。
RTO - 目標復旧時間を意味します。システムが復旧し、ユーザーが利用開始できるようになるまでに見込まれる最低限の時間を定義します。
どのようなアプリケーションでも、データ利用者と連携して、許容できる RPO と RTO を定義するようにします。厳格な要件であればあるほど、設定や管理に費用がかかります。これはトレードオフですので、規制要件に合うように構築するのであれば、システムを設計する前に明確にする必要があります。
バックアップ コピーをホストするリージョンを選択するときは、データに基づいた意思決定を行う
データのプライマリ コピーの配置場所に応じて、地理的に離れた場所にデータのバックアップをホストするリージョンを選ぶようにします。たとえば、プライマリ データセットが us-west1 にある場合は、northamerica-northeast2 または us-east1 を選択して、データのコピーをホストします。
BigQuery のマルチリージョン データセットの場合は、マルチリージョンの範囲内にあるリージョンにはバックアップしないようにします。たとえば、プライマリ データセットが multiregion US にある場合は、データのバックアップ先に us-central1 は選択しないようにします。このリージョンとマルチリージョンは障害発生ドメインを共有し、災害時の運命を共有している可能性があります。その代わりに、northamerica-northeast1 のような、米国以外のリージョンにバックアップするようにしましょう。
仮にデータを米国内に物理的に保存しなければならないといったデータ所在地に関する要件がある場合は、us-central1 と us-east1 のような 2 つのリージョン データセットを選択して、プライマリ データとバックアップ データをホストする方法が最適です。
障害復旧のセットアップが予定したとおりに進むように、定期的なドライランを計画する
このブログでは、データのバックアップと障害復旧に向けた設計のための戦略をいくつか提案しています。また、障害に備えて、コンピューティングとトラフィックのリダイレクトについて検討することもおすすめしています。コンピューティングの場合は、データのバックアップ コピーが保存されている地理的に離れた別のリージョンに、プロビジョニング済みのスロットを確保する必要があります。ドライランを数か月ごとに計画して、1 つのリージョンが完全に停止したとしても、1 つのリージョンから別のリージョンにトラフィックを送信できるようにします。
データをバックアップする
データを定期的にバックアップすることでビジネスの要件を満たすことができる場合は、ニーズに応じて以下のアプローチのうちの 1 つを実行するようにします。
7 日間のタイムトラベル
BigQuery では、過去 7 日間に変更または削除されたデータを BigQuery 内に保存し、アクセスを可能にすることで、タイムトラベルを提供しています。タイムトラベルを使用すると、更新または削除されたデータをクエリで取得し、削除されたテーブルや期限切れのテーブルを復元できます。タイムトラベルでは、7 日前までの過去のデータにのみアクセスできます。それより前のデータにアクセスする場合は、テーブル スナップショットを使用します。
スナップショット
BigQuery テーブル スナップショットでは、特定の時点でのテーブルのデータが保持されます。現在のテーブルのスナップショットを保存することや、過去 7 日間の任意の時点におけるテーブルのスナップショットを作成することが可能です。テーブル スナップショットには、有効期限を設定できます。テーブル スナップショットを作成した後、構成した時間が経過すると、そのスナップショットは、BigQuery により削除されます。テーブル スナップショットでは、標準のテーブルと同じようにクエリを実行できます。テーブル スナップショットは読み取り専用ですが、テーブル スナップショットから標準テーブルを作成し、復元したテーブルを変更できます。
注意: テーブルの暗号化に CMEK を使用している場合は、スナップショットでも同じ CMEK キーを使用します。なんらかの理由で CMEK キーが無効になってしまった場合は、スナップショットへのアクセスも失われることになりますのでご注意ください。
データセットをコピーする
BigQuery のデータセットのコピー機能を使用すると、BigQuery にデータを移動する必要も、再読み込みする必要もなく、リージョン内でのデータセットのコピー、または 1 つのリージョンから別のリージョンへのデータセットのコピーが可能です。この機能は、データセットを一度コピーする場合、または繰り返しのスケジュールをカスタマイズする場合に便利です。ただし、これはすべてのデータのコピーで、増分ではない点にご注意ください。詳細についてはこちらを参照してください。
GCS にエクスポートする
BigQuery では、Google Cloud Storage へのデータのエクスポートが可能です。これは、BigQuery 内のテーブルのバックアップとしての役割を果たしており、元のテーブルが破損したり削除された場合に、エクスポートしたデータを BigQuery に戻して読み込むことができます。ロケーションに関する留意事項をご確認のうえ、Google Cloud Storage のバケットをどのリージョンに配置するかを決定してください。
BigQuery の障害復旧ソリューション
アプローチ 1 - 複数のリージョンにおいて、2 つ以上の BigQuery のデータセットにデータを書き込む
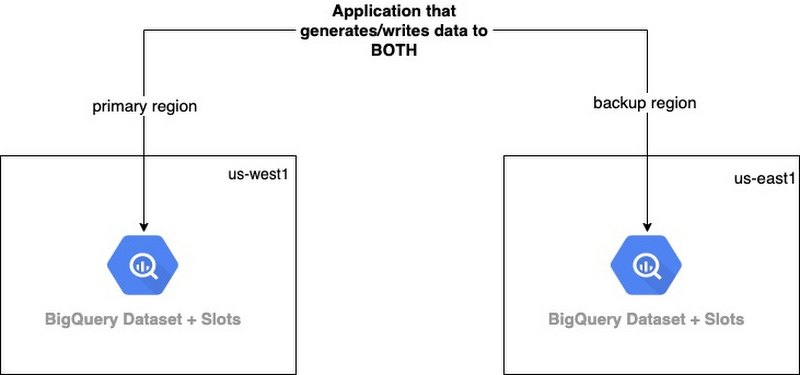
このアプローチでは、更新版のデータの完全なコピーを複数、維持することが目標です。プライマリ リージョンおよびバックアップ リージョン内の 2 つ以上の BigQuery データセットに、データを書き込むようにアプリケーションを設計する必要があります。障害発生時にプライマリ リージョンがダウンした場合でも、データ利用者はバックアップ リージョンからデータを利用することが可能です。
ただし、各リージョンへの書き込みのメカニズムが独立しているために、1 つのリージョンで書き込まれても、別のリージョンでは書き込まれない事態が発生する可能性があります。そのため、書き込みがべき等であり、失敗した場合は書き込みを再試行するように特別な注意を払う必要があります。
2 つ以上のコピーを有するということは、2 倍のストレージを使用するということです。スロットは、ニーズに応じてリモート リージョンでサイズ設定が可能です。通常は、書き込みの容量をプロビジョニングするだけで十分です。障害の発生時は、クエリにオンデマンドを使用するという方法があります。このアプローチでは、リージョン レベルの障害からデータが保護され、BQ がネイティブで提供しているサービスに関して高可用性が発揮されます。
アプローチ 2 - 別のリージョン / デュアルリージョンまたはマルチリージョン バケットの GCS にデータをエクスポートする
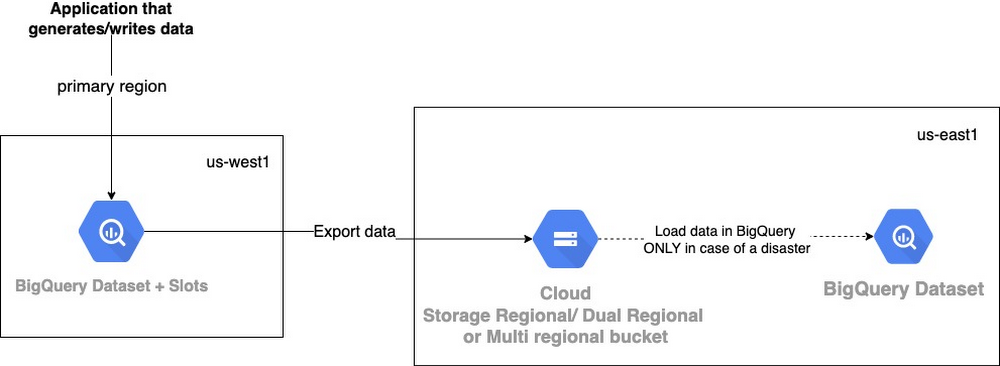
このアプローチでは、BigQuery のデータを GCS のバケットにエクスポートすることが目標です。BigQuery のマルチリージョン バケットを使用している場合は、GCS へのエクスポートもマルチリージョンもしくはデュアルリージョンである必要があります。これにより、バックアップ データの収集が、BigQuery のライブデータ単独で行われることがなくなります。データは RPO に基づいて一定の間隔で GCS にエクスポートされます。障害の発生時は、データは BigQuery に復元されます。
たとえば、リージョン障害への備えとして RPO を 1 週間に設定していた場合、最低でも週 1 回は完全バックアップを取る必要があります。先週の時点でのバックアップが利用可能であれば、ソースシステムから来る過去 1 週間分の増分データのバックアップを維持して、データを最新の状態に復元できるようにする必要があります。代替の方法としては、ソースシステムから RPO 期間内の増分データを確実に取得できるようにすることです。
BigQuery では、GZIP、DEFLATE、SNAPPY の圧縮形式を使用した、Avro、Parquet、CSV、JSON 形式でのエクスポートをサポートしています。データは GCS にエクスポートするときに圧縮されるため、アプローチ 1 に比べてコストを抑えられます。これは増分のエクスポートではなく、完全なエクスポートとなりますので、GCS バケットのバージョニングを適切に設定してください。
RTO に基づいて、バックアップ リージョンにいくつかのスロットを用意しておくことをおすすめします。そうすると、障害に備えてコンピューティング容量を確保できます。
次のステップ
このブログでは、BigQuery がネイティブで提供している高可用性 SLA とデータの耐久性についてと、これを達成している方法について説明しました。また、タイムトラベル、スナップショット、自由なデータ エクスポートといった機能についても説明しました。高可用性要件や障害復旧要件が BigQuery がネイティブで提供しているものよりも厳格であった場合に、こうした機能を使用してバックアップや障害復旧ソリューションを構築することが可能です。今回、二通りのアプローチを提案し、ソリューションが期待したとおりに機能しているかを定期的にテストするようにおすすめしました。
BigQuery のリリースノートに引き続き注目し、皆様の固有の要件に合うかもしれない新しい機能について最新情報をご覧ください。たとえば、Google では最近、BigQuery テーブルからの追加履歴の読み込み機能をリリースしました。追記専用のテーブルでは、この機能を使用して、増分のバックアップ ソリューションの設定が可能となります。
- Analytics、カスタマー エンジニア Sonakshi Pandey
- Google Cloud、カスタマー エンジニア Praveen Kumar Akunuru