階層名前空間によって Cloud Storage にファイル システム最適化をもたらす
Vivek Saraswat
Group Product Manager, Storage
Zhihong Yao
Staff Software Engineer, Cloud Storage
※この投稿は米国時間 2024 年 6 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
データ集約型アプリケーションやファイル指向アプリケーションは、Cloud Storage で最も急速に成長しているワークロードの一部です。ただし、これらのワークロードで通常求められている特定のフォルダ セマンティクスは、既存のバケットの「フラット」構造では最適化されません。Google は最近、Cloud Storage の階層名前空間(HNS)を発表しました。これは、フォルダ構造、リソース、オペレーションを最適化する新しいバケット作成オプションです。現在プレビュー段階にある HNS は、Cloud Storage バケットのパフォーマンス、一貫性、管理性を向上させます。
バケット構造とそれが重要である理由
既存の Cloud Storage バケットはフラットな名前空間で構成されており、そこではすべてのオブジェクトが 1 つの論理階層に保存されます。フォルダは、UI と CLI では「/」プレフィックスによってシミュレートされますが、Cloud Storage リソースによってフォルダはサポートされておらず、API を介してフォルダに明示的にアクセスすることはできません。これは、Hadoop / Spark 分析や AI / ML ワークロードなどのファイル指向セマンティクスが求められるアプリケーションにおいて、パフォーマンスや一貫性の問題につながる可能性があります。階層名前空間では、従来のファイル システムと同様に、他のフォルダやオブジェクトを格納可能なフォルダを含むツリー状の構造にバケットが編成されます。
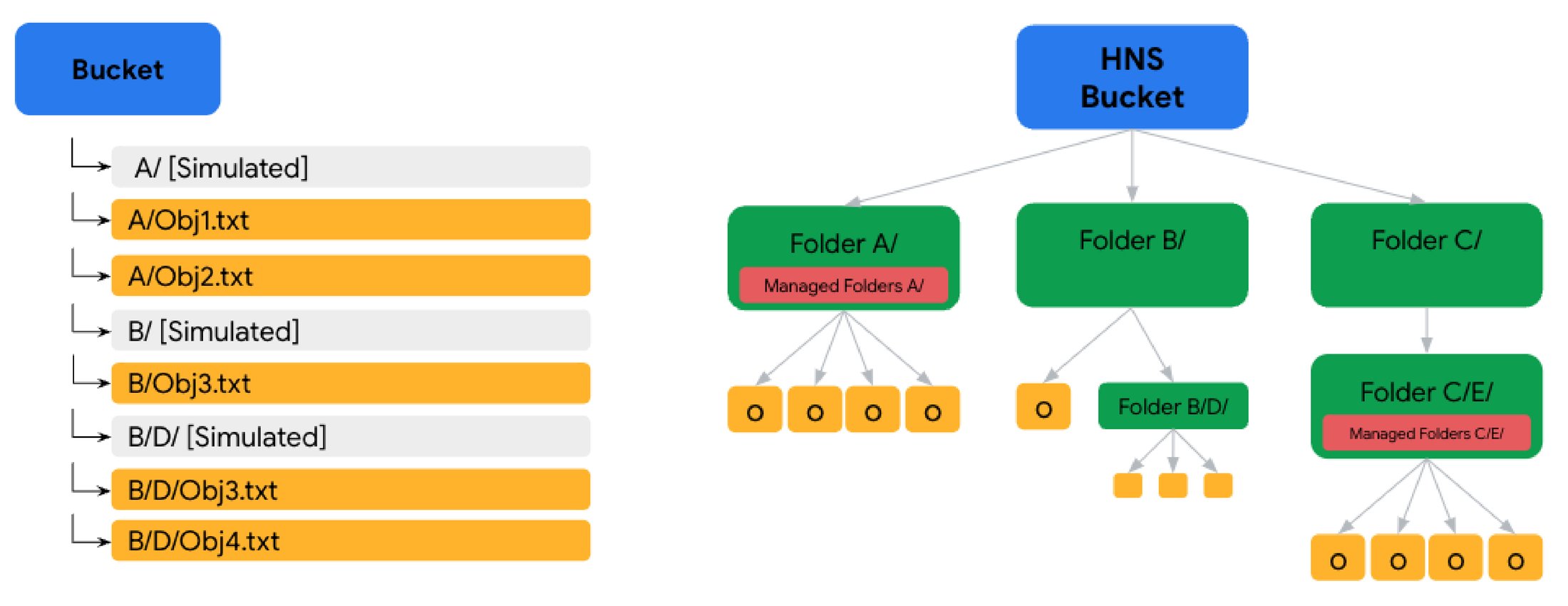
左: 「フラット」な階層とシミュレートされたフォルダを持つ既存の Cloud Storage バケット
右: フォルダやオブジェクトを含むツリー状の構造に編成された階層名前空間バケット
これがなぜ重要なのでしょうか。たとえば、フォルダのパス名を変更してフォルダを別の場所に「移動」したいとします。従来のファイル システムでは通常、このオペレーションはすぐに完了し、その結果はアトミックです。つまり、名前の変更が成功してフォルダのすべての内容のパス名が変更されるか、変更が失敗してすべての内容のパス名が元のままになるかのどちらかです。
それに対して、既存の Cloud Storage バケットでは、シミュレートされたフォルダの下にある各オブジェクトを一つずつコピーして削除する必要があります。フォルダに数百または数千のオブジェクトが含まれている場合、この方法は非効率的で時間がかかります。また、結果が非アトミックでもあります。つまり、プロセスが途中で失敗すると、同じフォルダが 2 か所に存在し、オブジェクトの一部のみが移動した不完全な状態になる可能性があります。これは、数百または数千単位の大量のフォルダの名前をプログラムで定期的に変更するようなデータ集約型ワークロードにとっては大きな問題となります。
階層名前空間を持つバケットは、API によってサポートされているストレージ フォルダ リソースを持っており、新しい「フォルダ名変更」オペレーションは、メタデータのみのオペレーションとしてフォルダとその内容の名前を再帰的に変更します。これにより、名前変更プロセスが高速かつアトミックになり、既存のバケットと比較してフォルダ関連オペレーションのパフォーマンスと一貫性が向上します。
主な利点
パフォーマンスの向上: HNS バケットの最適化されたストレージ レイアウトにより、初期バケットの秒間クエリ数(QPS)が高くなります。既存のバケットの場合、Cloud Storage のリクエスト レート ガイドラインでは、書き込み QPS は 1,000 オブジェクト、読み取り QPS は 5,000 オブジェクトと規定されています。HNS バケットでは、オブジェクトの読み取り / 書き込みオペレーションの 1 秒間の初期バケット リクエスト量が最大 8 倍高くなるため、データ集約型ワークロードのスケーリングがより簡単かつ迅速になります。
ファイル指向の機能強化: HNS は、Hadoop エコシステム ツールや AI / ML ワークロードといったファイル指向ストレージに最適化されたアプリケーションに役立つ新しい API を多数サポートしています。これらの変更により、ファイル指向ワークロードのパフォーマンス、復元力、利便性が向上します。具体的には、次のような点が変更されています。
-
オブジェクトや他のフォルダのコンテナとして機能する新しいリソース(フォルダ)と専用の管理 API(CreateFolder / DeleteFolder / GetFolder)
-
フォルダとその配下にあるすべてのフォルダおよびオブジェクトのパス名をアトミックに変更する新しい RenameFolder API
-
バケット内または特定のフォルダの配下にあるすべてのフォルダを一覧表示する新しい ListFolders API。フラット バケットでは、プレフィックスをフォルダとして一覧表示するには、ListObjects API を複数回呼び出して階層の各レベルのすべてのオブジェクトを一覧表示する必要がありました。
-
既存のマネージド フォルダ機能を利用し、それらをフォルダに「添付」することによってきめ細かい IAM セキュリティを提供する機能。フォルダ名を変更するとマネージド フォルダも一緒に移動し、IAM 権限も確実に移動します。
プラットフォームのサポート: HNS バケットは、既存の Cloud Storage オブジェクト API とほとんどの Cloud Storage 機能をサポートしています。HNS バケットは、Hadoop / Spark(Dataproc サービスを含む)ワークロード用の Cloud Storage コネクタや、クライアントを介してファイル システムのようにバケットにアクセスするための Cloud Storage FUSE とも統合されています。HNS はバケットの作成時にのみ有効にできるため、Storage Transfer Service を使用して HNS バケットにデータを転送することで、Cloud Storage にすでにプロビジョニングされているオブジェクトでこれらの利点を活用できます。
主なユースケース
ファイル システムのような階層とセマンティクスが必要なアプリケーションを使用する場合は、バケットに対して階層名前空間を有効にすることを検討してください。例を以下に示します。
-
Hadoop ベースの処理(Hadoop、Spark、Hive ワークロードなど)では伝統的に、ファイル システムのストレージ構造と時間ベースのファイル パーティショニングが求められています。HNS は、Hadoop ワークロード用の Cloud Storage コネクタと統合されており、多くのデータ処理パイプラインにおいてスループットの向上とアトミックなフォルダ名変更を可能にします。
-
バッチ分析やハイ パフォーマンス コンピューティングのようなファイル指向ワークロードの処理は、多くの場合、多数のファイルを含むフォルダが含まれたパーティションに構造化されます。HNS はフォルダ管理に役立ち、フォルダ名変更オペレーションを高速かつ便利に実行できます。
-
TensorFlow、Pandas、JAX、PyTorch などの AI および ML 処理ツールでは、多くの場合、ファイルのようなセマンティクスが求められます。(クライアント レベルのファイル システム アクセス用の Cloud Storage FUSE と組み合わせて)HNS を使用すると、ML モデルのイテレーションのようなユースケースのパフォーマンスと信頼性を向上させることができます。
その他の考慮事項
Cloud Storage 階層名前空間は、特定の種類のワークロードに多くの利点をもたらしますが、使用環境に応じたトレードオフを考慮してください。HNS はバケットを作成するときに有効にする必要があります。また、オブジェクトのバージョニング、バケットロック、オブジェクト保持ロック、オブジェクトの ACL など、一部の Cloud Storage 機能は HNS ではサポートされていません。
特に HNS の公開プレビュー版では、留意すべき重要な考慮事項がいくつかあります。この段階では、対象は非本番環境のワークロードに限定されており(一般提供になるまで)、削除(復元可能)機能や Autoclass 機能はまだサポートされていません。削除(復元可能)の利点とバケットで削除(復元可能)を無効にする方法について詳しくは、こちらをご覧ください。現在 HNS には、CLI、サポートされているクライアント ライブラリ、Hadoop / Spark ワークロード用の Cloud Storage コネクタ、および Cloud Storage FUSE を介してのみアクセスできます。UI のサポートは、プレビュー中の後期に予定されています。
公開プレビュー版では、HNS について追加料金は発生しません。一般提供後は、階層名前空間が有効になっているバケットとフォルダ関連のオペレーションに対して追加料金が発生します。
使ってみる
HNS はすぐに使用を開始できます。階層名前空間を有効にした Cloud Storage バケットを作成し、上記のサポートされているインターフェースを介して機能をテストしてください。詳細については、HNS のドキュメント ページをご覧ください。
HNS に関する皆様からのフィードバックをお待ちしております。フィードバックを提供するには、Cloud Storage HNS ドキュメント ページにある [フィードバックを送信] ボタンをクリックするか、cloud-storage-hns-contact@google.com 宛てに直接メールでお寄せください。


