Colossus の舞台裏: HDD の価格で SSD のパフォーマンスを実現する方法
Larry Greenfield
Storage Tech Lead
Seth Pollen
Software Engineer, Storage
※この投稿は米国時間 2025 年 3 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
YouTube、Gmail から BigQuery、Cloud Storage まで、Google のほぼすべてのプロダクトは、基盤となる分散ストレージ システム Colossus に支えられています。Google のユニバーサル ストレージ プラットフォームである Colossus は、最高水準の並列ファイル システムと同等以上のスループットを実現し、オブジェクト ストレージ システムの管理とスケーリング、すべての Google チームが使用している使いやすいプログラミング モデルを備えています。さらに、スケーリング、コスト、スループット、レイテンシなど、非常に多様な要件を持つプロダクトのニーズに対応しながら、これらすべてを実現しています。
Colossus の柔軟性は、一般提供されている多くの Google Cloud プロダクトに現れています。Hyperdisk ML は Colossus ソリッド ステート ディスク(SSD)を利用し、2,500 ノードによる 1.2 TB/秒の読み取りを可能にすることで、高いスケーラビリティを実現しています。Spanner は Colossus を活用し、同一のファイル システム上で安価な HDD ストレージと超高速の SSD ストレージを連携させることで、階層型ストレージ機能の基盤としての役割を果たしています。Cloud Storage は Colossus の SSD キャッシュを利用することで、最も安価なストレージを提供しつつ、高負荷な AI / ML アプリケーションの集中的な I/O にも対応しています。さらに、Colossus を基盤とした BigQuery のストレージは、超大規模クエリに対して超高速な I/O を実現しています。
以前に Colossus について投稿して以来しばらく経ちましたが、今回はその機能が Google Cloud の変化の絶えないビジネスをどう支えているか、特に SSD への対応に関する新たな機能についてご紹介したいと思います。
Colossus の背景
まずは Colossus の背景について簡単にご紹介します。
-
Colossus は Google File System(GFS)を進化させたものです。
-
従来の Colossus ファイル システムは、単一のデータセンター内で運用されていました。
-
Colossus は、GFS のプログラミング モデルを簡素化し、ファイル システムの使い慣れたプログラミング インターフェースとオブジェクト ストレージのスケーラビリティを兼ね備えた、追加専用のストレージ システムに進化させました。
-
Colossus のメタデータ サービスは、ファイルの作成や削除などのインタラクティブな管理操作を担当する「キュレーター」と、データの耐久性と可用性、ディスク容量のバランスを維持する「カストディアン」で構成されています。
-
Colossus のクライアントは、メタデータについてキュレーターとやり取りし、その後、HDD または SSD をホストする「D サーバー」にデータを直接保存します。
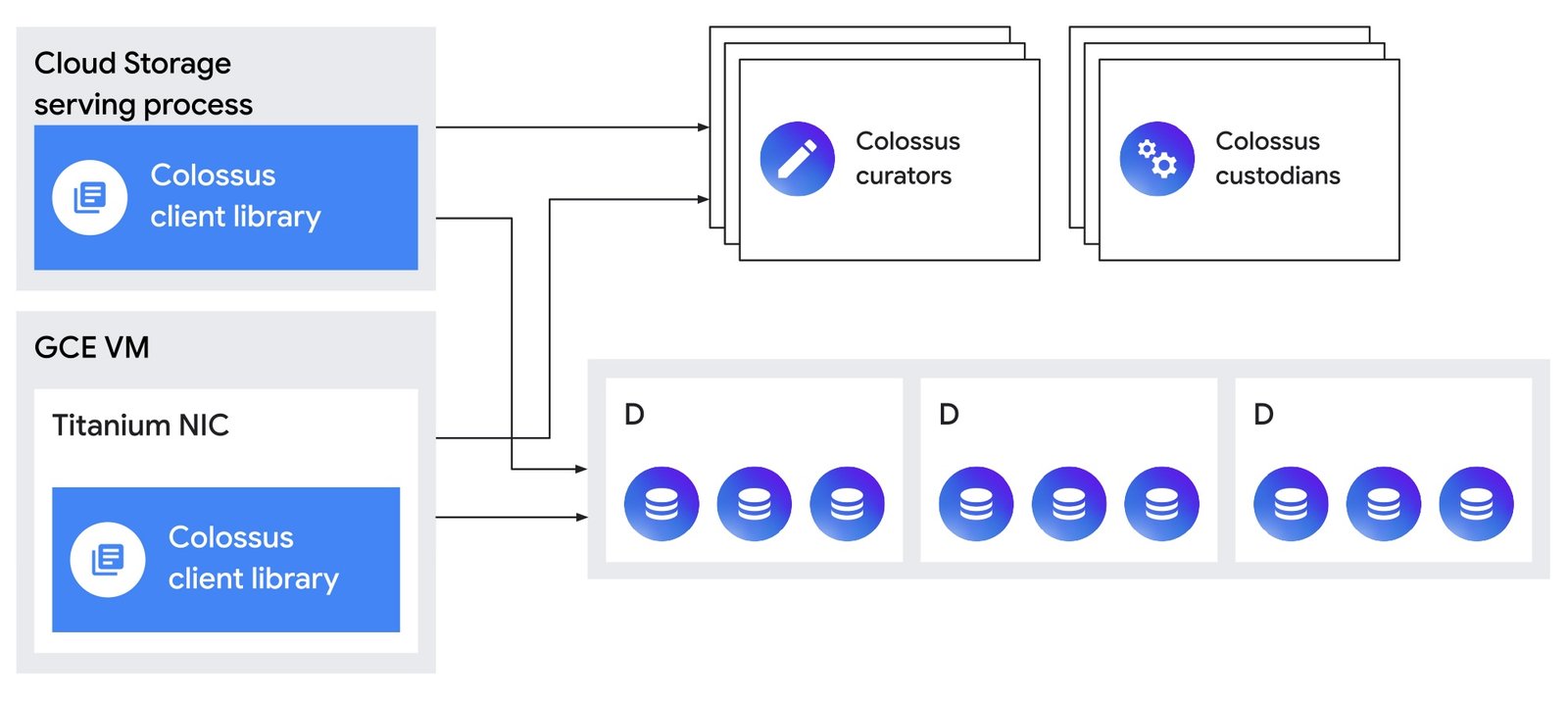
Colossus がゾーン単位のプロダクトであることも重要なポイントです。Colossus ファイル システムはクラスタごとに 1 つ構築しています。クラスタは Google Cloud ゾーン内の基本構成要素です。ほとんどのデータセンターには、クラスタ内で実行されるワークロード数に関係なく、1 つのクラスタ、つまり 1 つの Colossus ファイル システムが存在します。Colossus ファイル システムの多くは数エクサバイト規模のストレージを持ち、その中には 10 エクサバイトを超えるものが 2 つも存在します。このように大規模なスケーリングが可能であるため、最も要求の厳しいアプリケーションであっても、ゾーン内のクラスタ コンピューティング リソースの近くでディスク容量が不足することはありません。
こうした高負荷のアプリケーションは、大量の IOPS とスループットも必要とします。実際、Google 最大級のファイル システムの中には、読み取りスループットが 50 TB/秒、書き込みスループットが 25 TB/秒を超えるものもあります。これは、8K の長編映画を 1 秒間に 100 本以上送信できるほどのスループットです。
また、Colossus は大規模なストリーミング I/O だけに使われているわけではありません。多くのアプリケーションでは、小さなログの追記や小規模なランダム読み取りを行っています。最も高負荷な単一クラスタでは、読み書きを合わせて 6 億 IOPS を超える性能を発揮しています。
もちろん、こうした高パフォーマンスを実現するには、適切なデータを適切な場所に配置する必要があります。すべてのデータが低速のディスク ドライブに置かれていては、50 TB/秒で読み取るのは困難です。そこで登場するのが、Colossus における 2 つの重要な新機能、SSD キャッシュと SSD データ配置です。どちらも「L4」と呼ばれるシステムによって実現されています。
Colossus SSD 配置の最新情報
以前の Colossus に関するブログ投稿では、最もホットなデータを SSD に配置し、残りのデータをクラスタ内のすべてのデバイスに分散する方法について説明しました。SSD の価格が年々下がり、データセンターでの存在感が増している現在では、この考え方はますます重要になっています。いまどき、HDD だけで構成されたシステムを設計に組み込むストレージ設計者はいないでしょう。
ただし、SSD のみのストレージは、今でも SSD と HDD が混在したストレージ フリートよりも大幅に費用が高くなります。課題は、データの大部分を HDD に保持しながら、適切なデータ(I/O が特に多いデータや、特に低いレイテンシを必要とするデータ)を SSD に配置することです。
これを踏まえ、Colossus が最もホットなデータをどのように特定するかを見てみましょう。
Colossus には、SSD に配置するデータを選択する方法がいくつかあります。
-
データを SSD に配置するようシステムに強制する: この方法では、内部の Colossus ユーザーの操作により、データを SSD に配置するよう強制します。ユーザーは、/cns/ex/home/leg/partition=ssd/myfile というパスを使用してこれを実行できます。これは最も簡単な方法であり、ファイルが SSD に完全に保存されます。同時に、最も費用のかかるオプションでもあります。
-
ハイブリッド配置を活用する: より高度なユーザーは、「ハイブリッド配置」を活用して、SSD に 1 つのレプリカのみを配置するよう Colossus システムに指示できます(/cns/ex/home/leg/partition=ssd.1/myfile)。これはより手頃なアプローチですが、SSD コピーを持つ D サーバーが利用できない場合、HDD のレイテンシによってアクセスが遅くなります。
-
L4 を使用する: Google では、データの大半においてほとんどの開発者が新しい L4 分散 SSD キャッシュ テクノロジーを使用しており、このテクノロジーが SSD に最適なデータを動的に選択しています。
L4 読み取りキャッシュ
L4 分散 SSD キャッシュは、アプリケーションのアクセス パターンを分析し、SSD に最も適したデータを自動的に配置します。
読み取りキャッシュとして機能する場合、L4 インデックス サーバーが分散型の読み取りキャッシュを管理します。
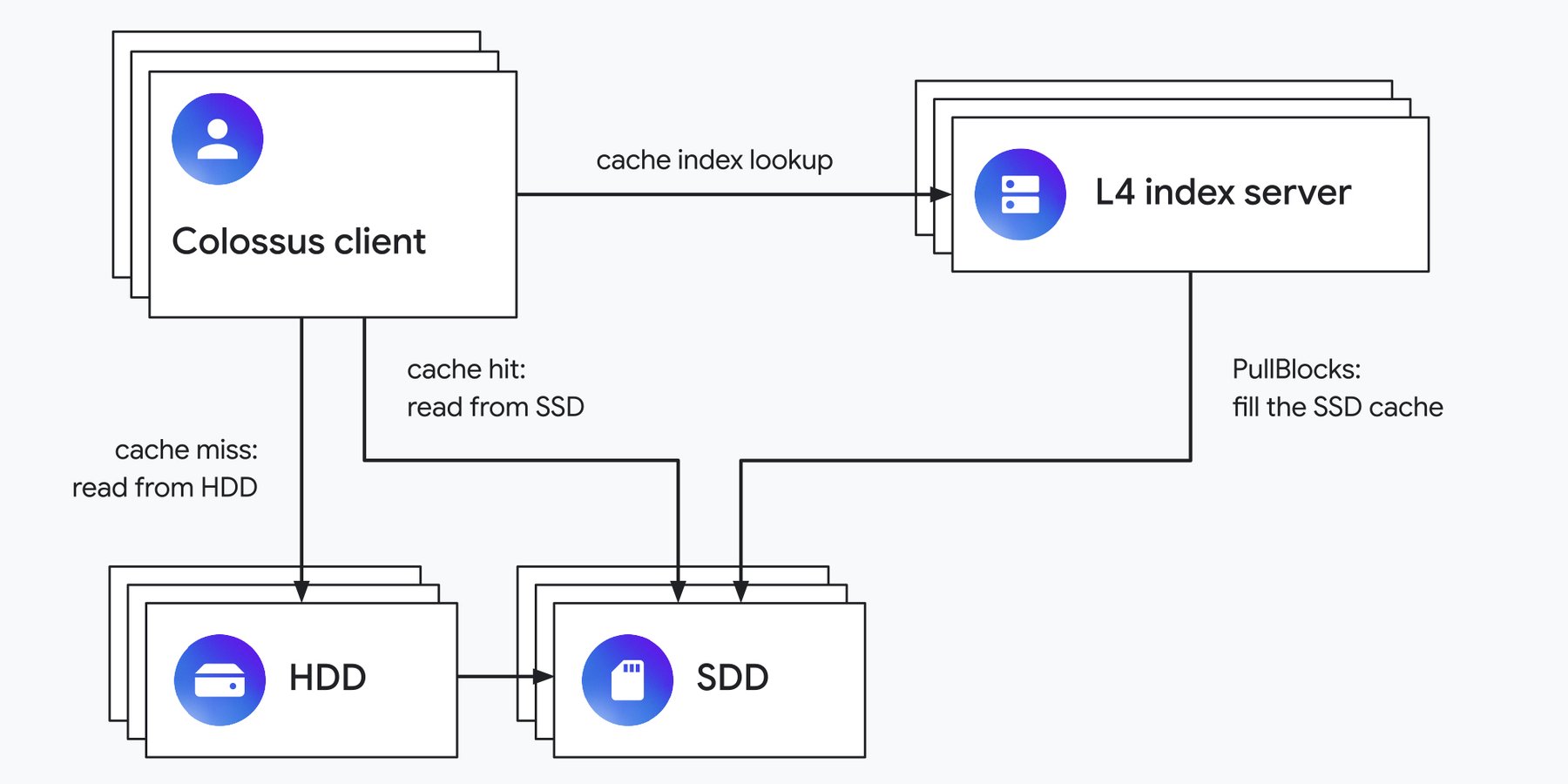
つまり、アプリケーションがデータを読み取る際には、まず L4 インデックス サーバーに問い合わせます。そのインデックスは、対象のデータがキャッシュにあるかどうかをクライアントに伝えます。キャッシュにある場合は、クライアントは 1 つ以上の SSD からデータを読み取り、なければキャッシュミスと判断して、Colossus がデータを配置しているディスクからデータを取得します。
キャッシュミスが発生した場合は、アクセスされたデータを SSD キャッシュに挿入することを L4 が決定できます。その際には、データを HDD サーバーから転送するよう SSD ストレージ サーバーに伝えます。キャッシュがいっぱいになると、L4 はキャッシュから一部の項目を削除し、新たに挿入するための容量を空けます。
L4 は、SSD にどの程度データを配置するかについて、より積極的または控えめな方針を取ることができます。ワークロードごとに、書き込み時、初回読み取り後、または短時間内の 2 回目の読み取り後のいずれかのタイミングで L4 キャッシュに挿入するといったポリシーを、ML ベースのアルゴリズムで決定しています。その仕組みの詳細については、CacheSack に関する論文をご覧ください。
このアプローチは、同じデータを頻繁に読み取るアプリケーションに適しており、IOPS とスループットを大幅に向上させました。ただし、大きな弱点もあります。新しいデータは依然として HDD に書き込まれているのです。また、L4 読み取りキャッシュが思ったほどリソースの節約につながらない重要な種類のデータも存在することがわかっています。たとえば、大規模なバッチ処理ジョブの中間結果のように、書き込み、読み取り、削除が短時間で行われるデータや、データベース トランザクション ログなど多数の小さな追記が発生するファイルがその例です。これらのワークロードはいずれも HDD に不向きであるため、SSD に直接書き込み、HDD を経由しないことが推奨されます。
Colossus の L4 ライトバック
ある内部の Colossus ユーザーが、データの一部を SSD に配置したいと考えているとしましょう。その場合、どのファイルを SSD に保存するか、そしてワークロードにどれだけの SSD 割り当てを購入すべきかを慎重に見極める必要があります。また、アクセスされなくなった古いファイルがある場合は、そのデータを SSD から HDD に移行したほうがよいかもしれません。しかし、実際のユーザーの使い方を見ていると、こうした判断がいかに難しいかがよくわかります。この作業を支援するために、Google は L4 サービスを強化して作業を自動化しました。
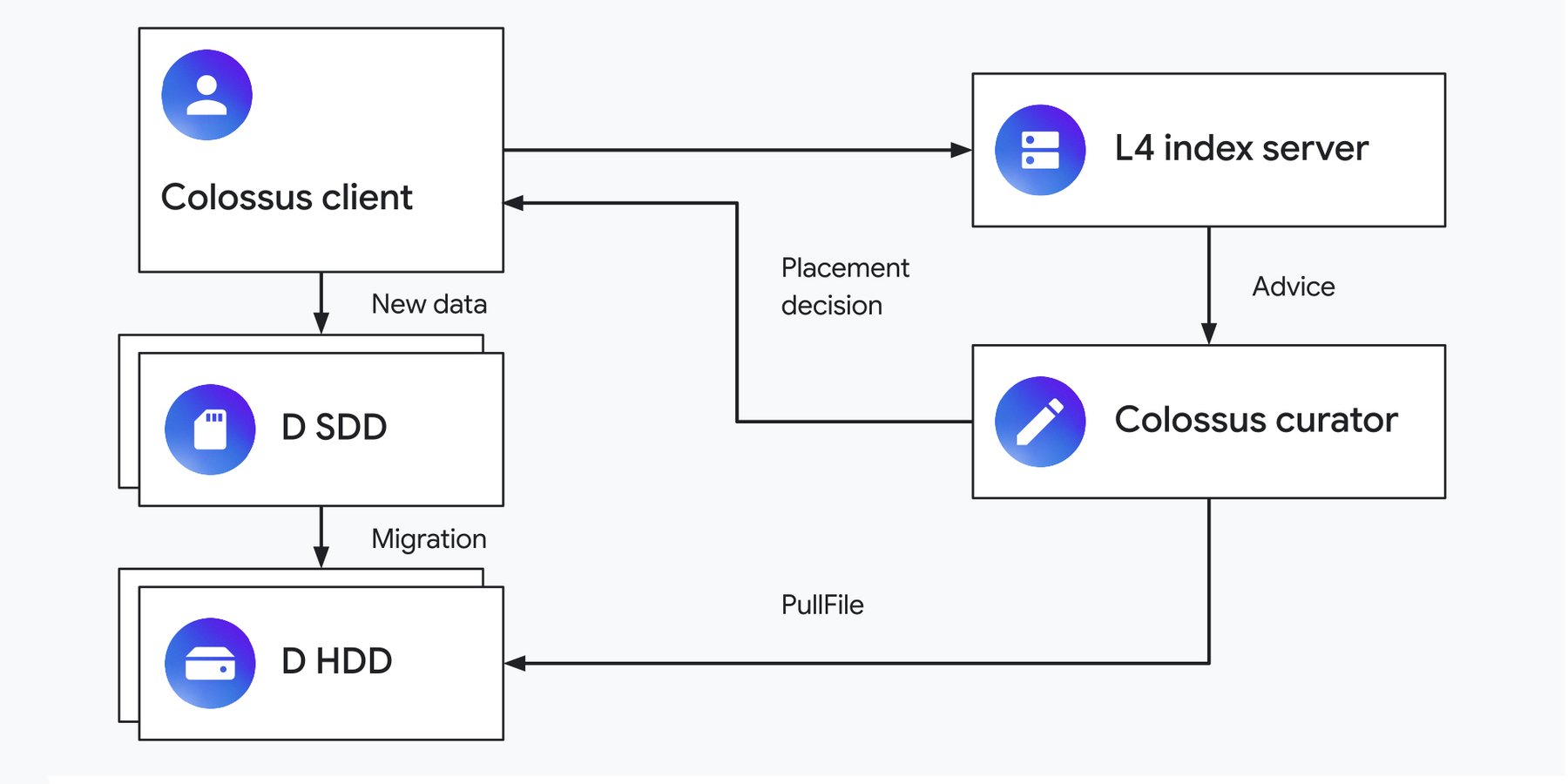
ライトバック キャッシュとして使用される場合、L4 サービスは、新しいファイルを SSD に配置するかどうか、また配置する期間はどのくらいかについて Colossus キュレーターにアドバイスします。これは、なかなか厄介な課題です。ファイルの作成時に Colossus が確認できるのは、ファイルを作成しているアプリケーションとファイル名のみです。ファイルがどのように使用されるかはわかりません。
この問題を解決するために、前述の CacheSack の論文で説明されている L4 読み取りキャッシュと同じアプローチを使用します。アプリケーションは、ファイル形式や、データが保存されているデータベース列に関するメタデータなどの特徴を L4 に渡します。L4 はこれらの特徴を使用してファイルを「カテゴリ」に分類し、各カテゴリの I/O パターンを経時的に観察します。これらの I/O パターンに基づいて、「1 時間だけ SSD に置く」、「2 時間 SSD に置く」、「SSD に置かない」といった複数の配置ポリシーをオンラインでシミュレーションします。そして L4 は、その結果に基づき、各カテゴリに最適なポリシーを選択します。
これらのオンライン シミュレーションには、もう 1 つの重要な目的があります。それは、SSD 容量が増減した場合に、L4 がどの配置を選択するかを予測することです。これにより、SSD の容量に応じて、HDD からどの程度の I/O をオフロードできるかを予測できます。こうしたシグナルは、新たな SSD ハードウェアの購入判断に役立つだけでなく、SSD 容量をアプリケーション間で柔軟に再配分し、効率を最大化するための指針としても活用されます。
指示があれば、キュレーターは新しいファイルをデフォルトの HDD ではなく SSD に転送できます。一定時間が経過してもファイルがまだ存在する場合、キュレーターはデータを SSD から HDD に移行します。
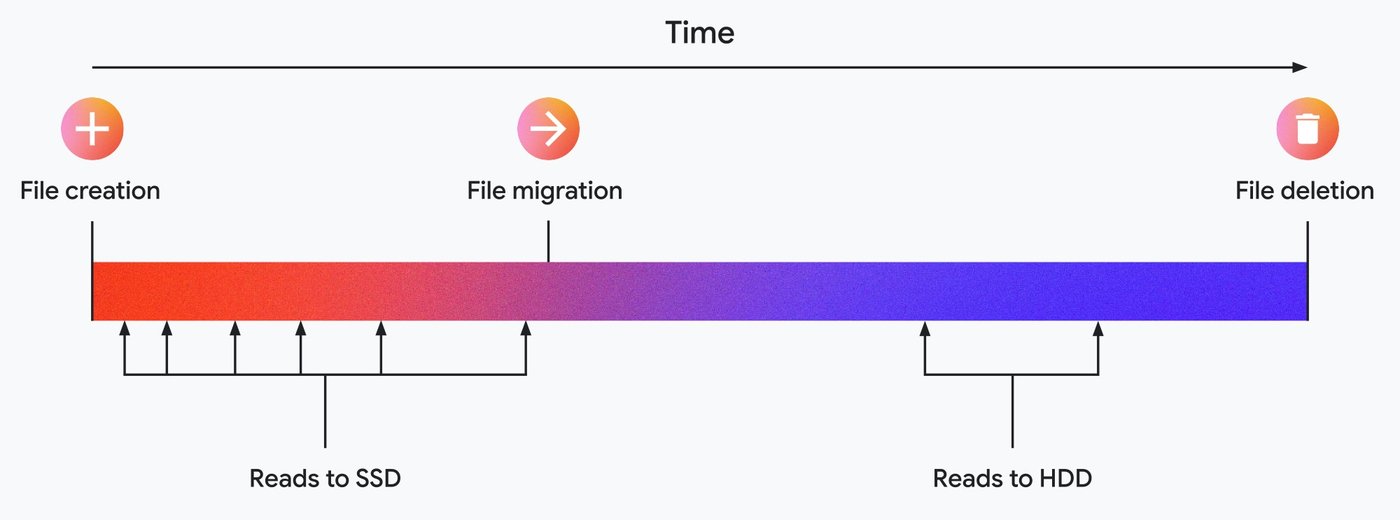
L4 システムのシミュレーションがファイル アクセス パターンを正確に予測すると、データのごく一部を SSD に配置するだけで、新規作成されたファイルに集中しがちな読み取り要求の大半を吸収できます。その後、データをより安価なストレージに移行することで、全体のコストを抑えられます。最良のシナリオでは、HDD に移行する前にファイルが削除され、HDD の I/O がすべて回避されます。
Colossus SSD と Google Cloud
Colossus は、Google および Google Cloud 全体を支える基盤であり、数十億のユーザーに信頼性の高いサービスを提供するうえで欠かせないものです。その高度な SSD 配置機能により、ワークロードの変化に自動的に適応しつつ、コストを抑えながら高いパフォーマンスを実現しています。
Google の最終的な目標は、HDD や SSD、そして Colossus の複雑な仕組みに精通していないエンドユーザーであっても、ストレージの効率性とパフォーマンスを最大限に引き出せる環境を提供することにあります。Google は、これまでに築いてきたこのシステムに誇りを持っています。そして今後も、さらなるスケーリング、洗練性、パフォーマンスの向上に取り組み続けていきます。詳しくは、Google Cloud Next ‘25 のブレイクアウト セッション「What’s new with Google Cloud’s Storage(Google Cloud のストレージに関する最新情報)」(BRK2-025)と「AI Hypercomputer: Mastering your Storage Infrastructure(AI Hypercomputer: ストレージ インフラストラクチャをマスターする)」(BRK2-020)にご参加ください。
-ストレージ テクニカル リーダー Larry Greenfield
-ストレージ担当ソフトウェア エンジニア Seth Pollen



