遅延が発生していた Cloud Run サービスを修正した方法のご紹介
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
ストレステスト中に、アプリに遅延が発生して応答にかかる時間が長くなり、ほとんど応答しない状態になったとします。その理由を考えてみましょう。
私は、Nexuzhealth を支援し、Cloud Run 上の Go アプリのパフォーマンスの問題をデバッグしました。Nexuzhealth は、あらゆる人が医療記録の管理をより適切に、より効率良く行えるようにしているベルギーのヘルスケア IT 企業です。これは、複数の医療機関を受診する患者にとって非常に役に立ちます。
事前にストレステストを実施したのは実に効果的でした。おかげで本番環境に入る前に異常を検出して、修正することができました。根本原因が明らかではなかったので、私は Nexuzhealth とともに調査を開始しました。Google Cloud のサーバーレス サービスを活用してお客様が成功できるよう喜んでお手伝いさせていただきました。
問題は簡単に再現でき、数百件のリクエストで負荷テストを開始すると、そのたびに応答時間の低下が観察されました。アプリは自動スケーリングを使用しており、新しいサーバー インスタンスが起動するたびサービスが低速になり、数十秒間応答しなくなりました。リクエストの処理に、予想よりもはるかに長い時間がかかっていました。いったい何が起きていたのでしょうか?
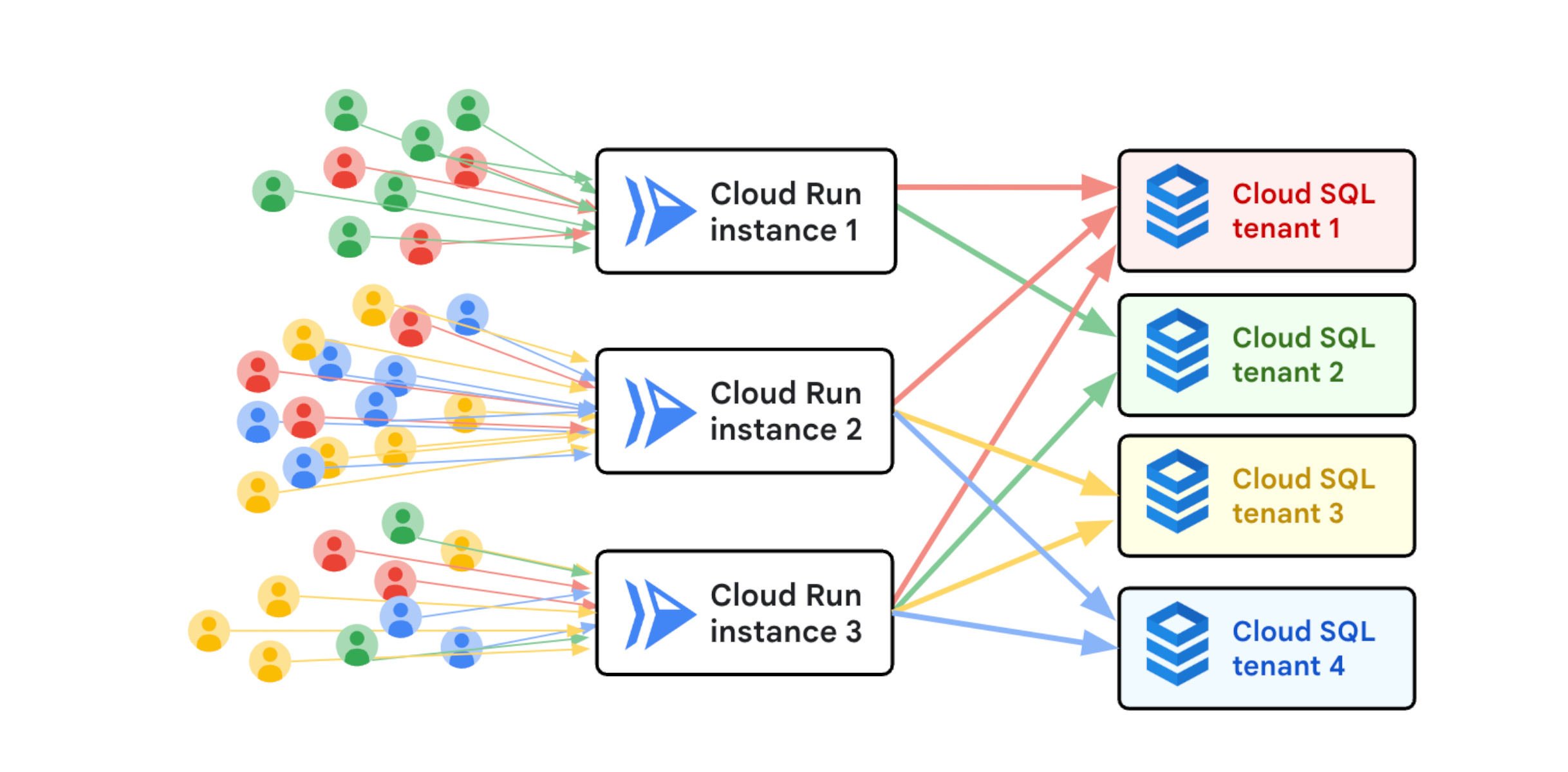
パフォーマンスの問題を調査するために、サーバーのログと指標、アプリケーションのソースコードが必要でした。サーバーログには、タイムスタンプ付きのすべてのリクエストと、各リクエストにつき適切なデータベースへの接続に関する情報が含まれていました。そこから、アプリがさまざまなデータベースへの接続を確立するのに多くの時間を費やしていることがわかりました。マルチテナントであるため、データベース インスタンスはリクエストごとに異なる可能性があります。
医療研究所や薬局などの多くのテナントも、データへのアクセスに同じ Nexuzhealth アプリを使用しています。次に示すように、各テナントのデータは、独自のデータベース内で他のテナントから厳密に分離されています。
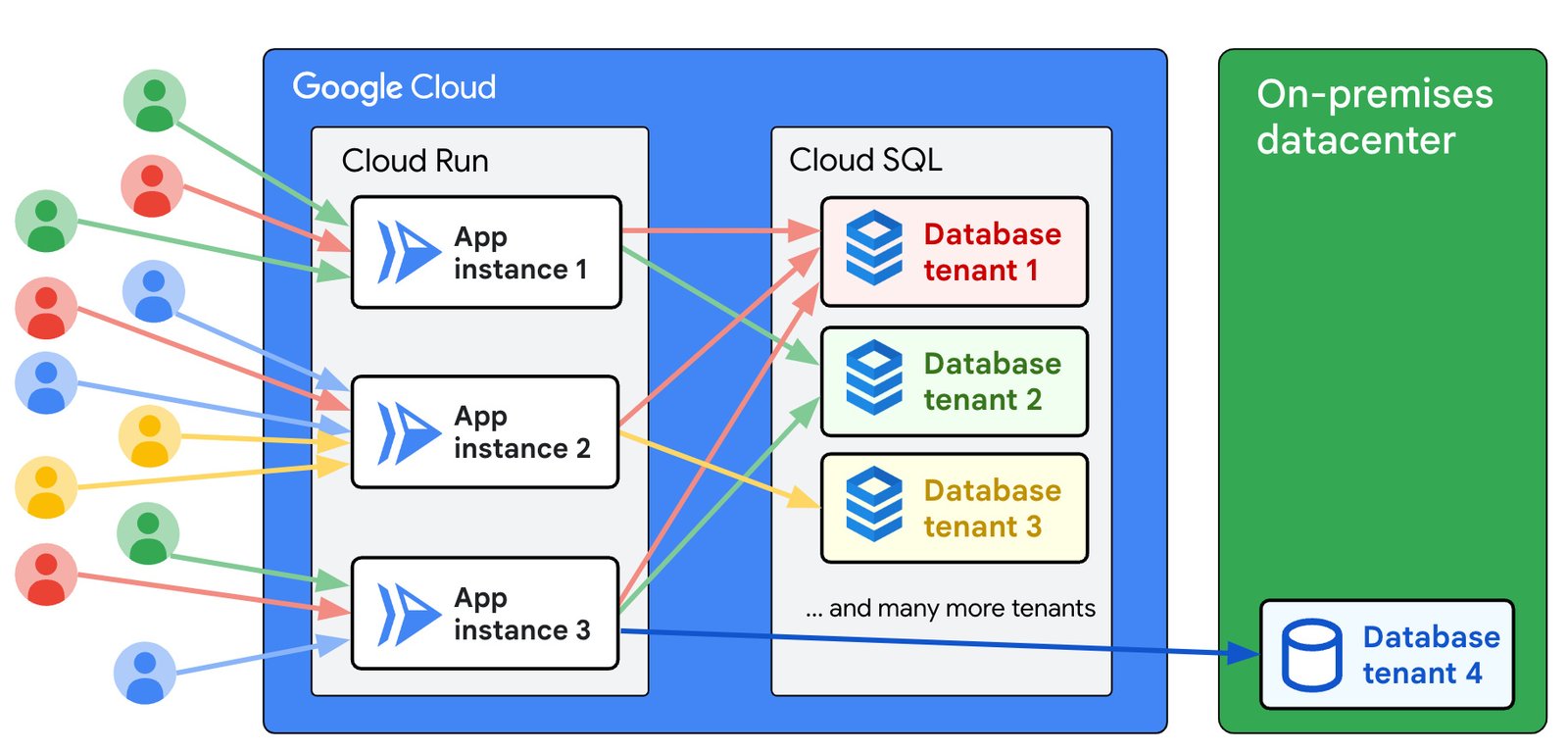
マルチテナント アプリケーション
Cloud Run は、オンデマンドでコンテナを起動して受信トラフィックを処理するフルマネージド プラットフォームです。アプリ インスタンスは、数多くのデータベース インスタンスに接続する必要があります。
そこで、リクエスト ハンドラーが新しいデータベース接続を確立するか、ローカル インスタンスの状態に保存されている既存の接続を再利用するかを決定する領域のソースコードを確認してみました。

ユーザー リクエストごとに、コードは現在のアプリ インスタンスが適切なテナント データベースにすでに接続されているかどうかを確認します。そうでない場合は、新しい接続が作成されます。これは遅延初期化と呼ばれます。
アプリケーションは起動時に、すぐにデータベースに接続するか(積極的な初期化)、最初に受信するユーザー リクエストを待つか(遅延初期化)という選択に直面します。アプリが Cloud Run または Google Kubernetes Engine(GKE)で自動スケーリングを使用する場合、新しいインスタンスが頻繁に起動されるため、この問題は重要です。
応答性が向上するため、私は通常は積極的な初期化を好んで使用します。最初のリクエストが処理されるとき、データベースがすでに接続された状態になっているため、最初のリクエストの応答時間が数百ミリ秒節約されます。
マルチテナントを使用する Nexuzhealth の場合は、遅延初期化の方が適しています。サーバーをオンデマンドでデータベースに接続し、自動スケーリングの速度に大きく影響する起動の待ち時間を節約することは理にかなっています。
各テナント データベースへの接続がすべてのアプリ インスタンスを通じて 1 回だけ作成され、同じテナントに対する後続のリクエストに再利用されることを私たちは期待していました。ログにはエラーや異常なメッセージは見られませんでした。
このアルゴリズムを使用すると、アプリは正しく動作しますが、新しいインスタンスが開始されるたびにパフォーマンスが大きく低下します。どうなっているのでしょうか?コード スニペットをもう一度詳しく見てみましょう。
dbmap データ構造は、リクエストを処理する多くのスレッドによって共有されます。多くのリクエストを同時に処理するアプリ インスタンスで共有状態を扱うときは、データ競合を避けるために同期が適切に行われるようにする必要があります。このコードは RW ロックを使用しますが、上記の疑似コードには 2 つの問題があります。
まず、最も遅いオペレーションは createConnection() で、200 ミリ秒以上かかる場合があります。このオペレーションは、書き込みモードで RW ロックを保持したまま実行されます。つまり、サーバーによって同時に作成できるデータベース接続は 1 つだけです。これは最適ではないかもしれませんが、パフォーマンスの問題の根本的な原因ではありませんでした。
次に、より重要なことですが、上記のコードには TOCTOU の問題があります。マップを読み取って接続を作成する間に、接続が別のリクエストによってすでに作成されている可能性があります。これは競合状態です。
競合状態の発生はまれである可能性があり、再現が困難です。今回のケースでは、不運にも次のようなイベントが続いたため、問題が毎回発生していました。
- アプリケーションがラフィックを処理している。
- より多くのトラフィックが到着し、サーバー インスタンスの負荷が増加している。
- オートスケーラーが、新しいインスタンスの作成をトリガーする。
- インスタンスが HTTP リクエストを処理できる状態になると、すぐに多くのリクエストが新しいインスタンスにルーティングされる。まるで thundering herd 問題のようです。
- いくつかのリクエストは空のマップを読み取り、データベース接続を作成する。
- 書き込みモードでロックを取得できるのは 1 つのリクエストだけであり、データベース接続を作成して再びロックを解放するまでに約 200 ミリ秒かかる。
- その間、他のすべてのリクエストはブロックされ、ロックの取得を待機する。
- 2 番目(後続)のリクエストが書き込みモードでロックを取得するとき、マップが変更されたことは認識されず(マップが空であることはすでにチェックされている)、独自の新しい冗長接続を作成する。
すべてのリクエストは長いオペレーションを実行しており、実質的に相互に待機している状態となることが、高いレイテンシが確認された原因となっていました。最悪の場合、アプリが非常に多くの接続を開いているため、データベース サーバーが接続を拒否し始める可能性があります。
解決策
考えられる解決策は、書き込みモードでロックを取得した直後にマップを再度チェックすることであり、これはダブルチェック ロックの方法として使えます。
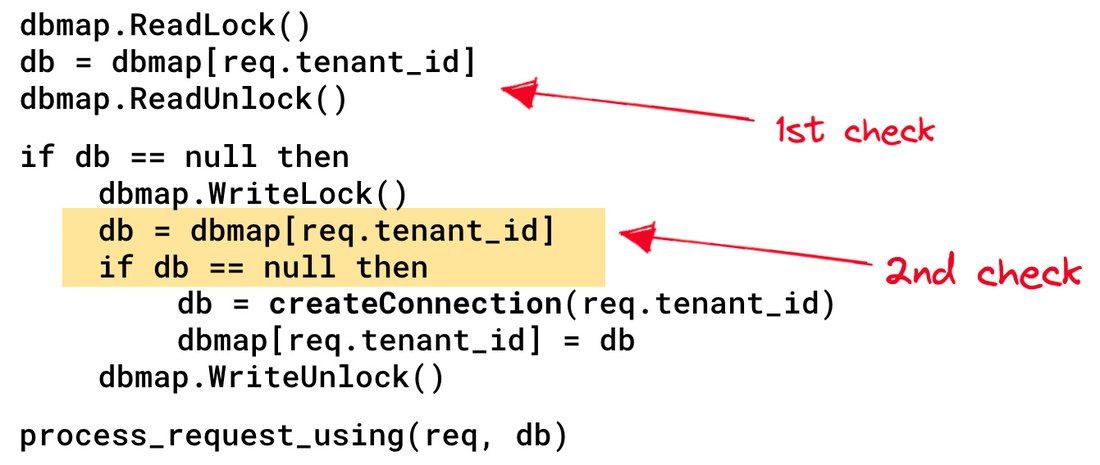
この小さな変更(コードを 2 行追加するのみ)により、同じテナントに対する 2 つのリクエストによってテナントのデータベース接続が上書きされなくなります。ダブルチェックパターンを試してみると、パフォーマンスが劇的に向上しました。
また、複数のテナントの接続を同時に作成して、新しく開始したインスタンスのパフォーマンスをさらに向上させる、より高度なパターンを考えることもできます。Go で書かれたこちらのシミュレーションをご覧ください。
Cloud Run におけるアプリのパフォーマンスの最適化について詳しくは、デベロッパー ガイドのパフォーマンスの最適化セクションをご確認ください。
-デベロッパー アドボケイト Valentin Deleplace



