BigQuery イベントで Cloud Run アクションをトリガーする方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
多くの BigQuery ユーザーは、データベース トリガー、つまり特定の BigQuery テーブル、モデル、データセットのイベントに応答して手続き型コードを実行する方法を求めています。新しいテーブル パーティションが作成されるたびに ELT ジョブを実行する場合や、新しい行がテーブルに挿入されるたびに ML モデルを再トレーニングする場合があるかもしれません。
この記事では、「クラウドが簡単になる」という一般的なカテゴリにおいて、BigQuery と Cloud Run を簡単かつ適切に連携させる方法をご紹介します。BigQuery も Cloud Run もよく使うようであれば、一緒に使用することでさらに便利になるでしょう。
Cloud Run は、BigQuery が監査ログに書き込むときにトリガーされます。BigQuery のすべてのデータアクセスはログに記録されるため(オフにする方法はありません)、必要なのは、探している正確なログメッセージを見つけることだけです。
以下にその方法を説明していきます。
BigQuery イベントを探す
実際のデータセットが台無しになるのを恐れる方が多いと思いますので、ここでは、BigQuery のプロジェクトに cloud_run_tmp という名前の一時ファイルを作成します。
このプロジェクトで、テーブルを作成し、いくつかの行を挿入して試してみましょう。BigQuery パブリック データセットからいくつかの行を取得して、以下のようにテーブルを作成します。
次に、データベース トリガーを作成する挿入クエリを実行します。
次に、別の Chrome タブで、このリンクをクリックして、Cloud Logging のBigQuery 監査イベントをフィルタリングします。
以下のイベントを発見しました。
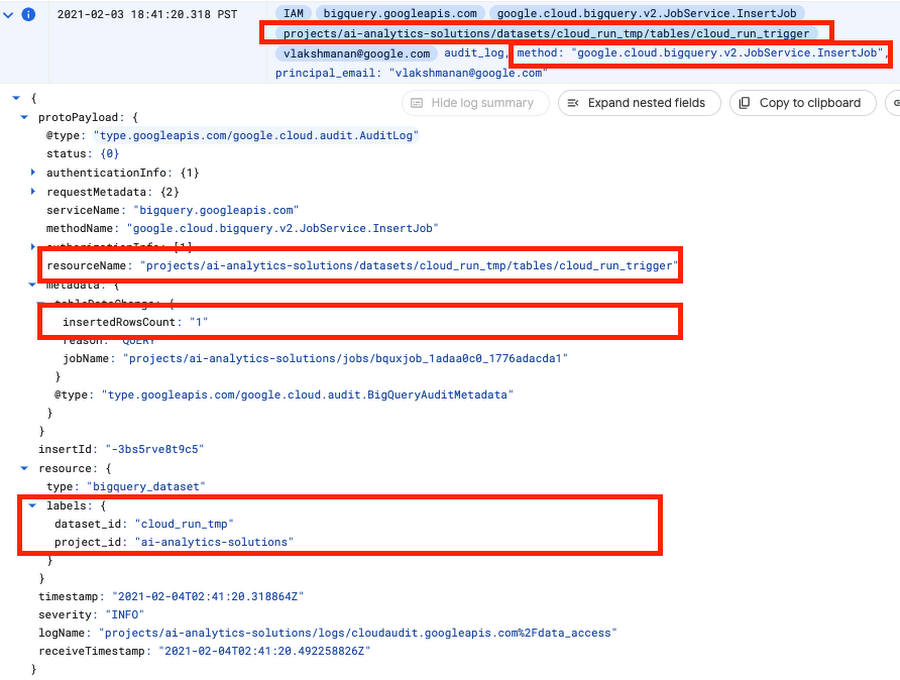
特定の BigQuery アクションには監査ログが複数あるので注意してください。たとえばこのケースでは、クエリを送信すると、すぐにログが生成されます。しかし、BigQuery はクエリが解析された後でのみインタラクションを行うテーブルを認識するため、初期ログにはテーブル名がありません。古い監査ログは不要です。アクションを明確に識別する一意の属性セットを確実に探してください。
行を挿入する場合の組み合わせは以下のとおりです。
●メソッドは google.cloud.bigquery.v2.JobService.InsertJob です
●挿入先のテーブルの名前は protoPayload.resourceName です
●データセット ID は resource.labels.dataset_id として利用できます
●挿入される行の数は protoPayload.metadata.tableDataChanged.insertedRowsCount です
Cloud Run アクションを記述する
求めているペイロードがわかったら、Cloud Run アクションを記述できます。Python で Flask アプリとして作成しましょう(完全なコードは GitHub にあります)。
まず、これが処理するイベントであることを確認します。
これが目的のイベントであることが確認できたら、実行するアクションを実行します。ここで、集計を行って新しいテーブルを書き出しましょう。
コンテナの Dockerfile は、Flask と BigQuery クライアント ライブラリをインストールする基本的な Python コンテナです。
Cloud Run をデプロイする
コンテナをビルドして、いくつかの gcloud コマンドを使用してデプロイします。
イベント トリガーをセットアップする
トリガーが機能するためには、Cloud Run のサービス アカウントにいくつかの権限が必要です。
最後に、イベント トリガーを作成します。
ここで重要なのは、BigQuery が作成した挿入ログによってトリガーしているということです。そのためアクションでは、ペイロードに基づいてこれらのイベントをフィルタリングする必要がありました。
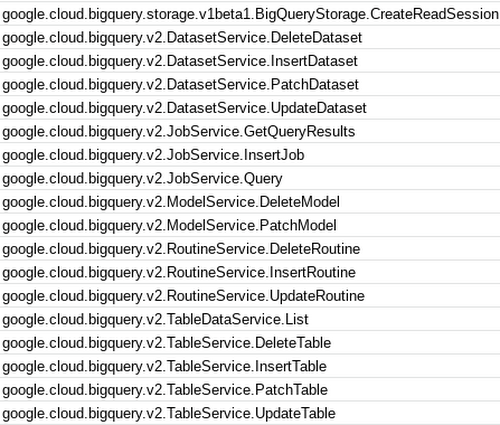
どのイベントがサポートされているのでしょうか?Cloud Run のウェブ コンソールを確認するのが簡単です。以下に、その一部をご紹介します。
お試しください
ここでは BigQuery -> Cloud Run のトリガーとアクションを試します。BigQuery コンソールに移動し、1、2 行挿入します。
created_by_trigger という新しいテーブルが作成されます。これで BigQuery のデータベース イベントで Cloud Run アクションを正常にトリガーできました。
ぜひお試しください。
リソース
すべてのコードは、手順付きの README とともに GitHub に掲載されています。
本ブログ投稿は、『BigQuery: The Definitive Guide』を更新したものです。私は、この本の内容を年に 1 回程度更新し、このようなブログの形で最新情報をお知らせすることを目標としています。
以前に投稿したこのような更新ブログは、この本の GitHub リポジトリからリンクされています。
Prashant Gulati に感謝します。
-Google Cloud 分析および AI ソリューション部門責任者 Lak Lakshmanan


