Cloud Run ワーカープールで Kafka ワークロードのスケーリングを簡単に
Aniruddh Chaturvedi
Engineering Manager
Adam Kane
Senior Engineering Manager
【Next Tokyo ’25】
【Next Tokyo】120 以上のセッションをアーカイブ公開中。話題の Gemini、生成 AI、AI エージェントなどの Google Cloud のアップデートや顧客事例をチェックしましょう。
視聴はこちら※この投稿は米国時間 2025 年 6 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Kafka は、多くのイベント ドリブン アーキテクチャとストリーミング データ パイプラインに不可欠です。しかし、Kafka トピックからのデータを処理するアプリケーションである Kafka コンシューマーを効果的にスケールするのは容易ではありません。
今回は、Cloud Run で Kafka コンシューマー ワークロードを自動スケールする際の効率と費用対効果を高める 2 つの機能、Cloud Run ワーカープール(公開プレビュー版)とオープンソースの Cloud Run Kafka オートスケーラーについてご紹介します。この 2 つの機能は、Google Cloud Next ’25 で発表されました。
課題: pull ベースのワークロードのスケーリング
Kafka コンシューマーは「pull」モデルで動作し、Kafka ブローカーからデータを能動的に取得します。このアーキテクチャは、データをコンシューマーに送信する「push」システムとは根本的に異なります。そのため、CPU 使用率や受信 HTTP リクエストのスループットなどの指標は、処理需要の判断材料としては不十分です。Kafka コンシューマーのワークロードの真の指標となるのは「オフセットラグ」です。これは、トピック パーティションで利用可能な最新メッセージのオフセットと、そのパーティションのコンシューマー グループによってコミットされた最後のオフセットの差です。
オフセットラグ(Kafka ブローカーに存在)などのキュー対応の指標を自動スケーリングの入力として組み込むことで、メッセージのバックログを最小限に抑え、リソース使用率を最適化できます。
pull ベースのワークロード向けの Cloud Run ワーカープール
スケーリングの課題を解決するには、まず、これらの pull ベースのワークロードを効率的に実行するように設計された環境が必要です。そこで役立つのが Cloud Run ワーカープールです。これは、Cloud Run ではこれまで困難だった Kafka コンシューマーやその他のバックグラウンド プロセッサの実行のための専用の基盤を提供します。

Cloud Run の 3 つの主なリソースタイプ
Cloud Run サービスはリクエスト ドリブン型の HTTP ワークロード向けに、Cloud Run ジョブは完了まで実行されるバッチタスク向けに調整されていますが、ワーカープールは、HTTP 以外の継続的な pull ベースのバックグラウンド処理に最適な、独自のリソースタイプです。ワーカープールは、Kafka コンシューマーに最適な固有の機能を提供します。
-
バックグラウンド処理向けに設計: サービスとは異なり、ワーカープールはパブリック HTTP エンドポイントを必要としません。ヘルスチェックのポートを管理する必要がなくなるため、ネットワークの攻撃対象領域が縮小され、アプリケーション コードが簡素化されます。
-
インスタンス分割による段階的なデプロイ: ワーカープールでは、pull ベースのワークロードに合わせて調整されたデプロイ戦略が使用されます。これらのワークロードは HTTP トラフィックを処理しないため、トラフィックを分割するのではなく、リビジョン間でインスタンスを分割することでロールアウトを管理します。たとえば、4 つのインスタンスを持つワーカープールの場合、25%(1 つのインスタンス)を新しいカナリア リビジョンに、75%(3 つのインスタンス)を現在の安定したリビジョンに割り当てることができます。
-
大幅な費用削減: ワーカープールでは、インスタンス課金の Cloud Run サービスと比較して、CPU とメモリの料金が最大 40% 削減されます。
ワーカープールは、Google Cloud CLI(gcloud beta run worker-pools)で、公式の Terraform リソースとして、または再編成された Google Cloud コンソール インターフェースで利用できます。

新しいワーカープール リソースが表示された Cloud Run ユーザー インターフェース
Kafka オートスケーラーを使用したキュー対応の自動スケーリング
ワーカープールは適切な環境を提供しますが、それでもオフセットラグに基づいてスケールするメカニズムは必要です。オープンソースの Cloud Run Kafka オートスケーラーは、お客様がデプロイするツールで、ワーカープール(またはインスタンス課金サービス)と連携して、リアルタイムの需要に基づいてコンシューマー インスタンスを動的に調整します。
これは Google Cloud Platform のマネージド機能ではなく、お客様がご自身のプロジェクトで制御、デプロイするオープンソース ツールであることにご注意ください。
主な利点:
-
実際の Kafka 指標に基づくスケーリング: オートスケーラーは Kafka クラスタに直接接続して、コンシューマー グループのパーティション全体の合計オフセットラグをモニタリングします。また、コンシューマーの CPU 使用率を考慮に入れることもできます。
-
コンシューマーを自動的にゼロにスケールダウン: これにより、アイドル期間中は費用がからなくなります。
-
費用対効果: リクエスト課金型の Cloud Run サービスとしてデプロイされるため、オートスケーラー自体は非常に安価に実行できます(月額 1 ドル未満)。これは、スケーリング チェック中の短い期間のみアクティブになるためです。
-
スケーリング動作をきめ細かく構成可能: オートスケーラーは、Kubernetes HorizontalPodAutoscaler(HPA)と同様に、スケーリング ポリシーをきめ細かく制御できるため、具体的な費用やパフォーマンスの目標に合わせてスケーリング動作を調整できます。次のような構成可能な手段がいくつか用意されています。
-
目標ラグと CPU 使用率のしきい値
-
インスタンス数の急激な変動を防ぐ安定化ウィンドウ
-
1 回のスケーリング アクションでどの程度のインスタンスを追加または削除するかを制御するスケーリング増減制限
構成オプションの完全なリストについては、プロジェクトのドキュメントをご覧ください。
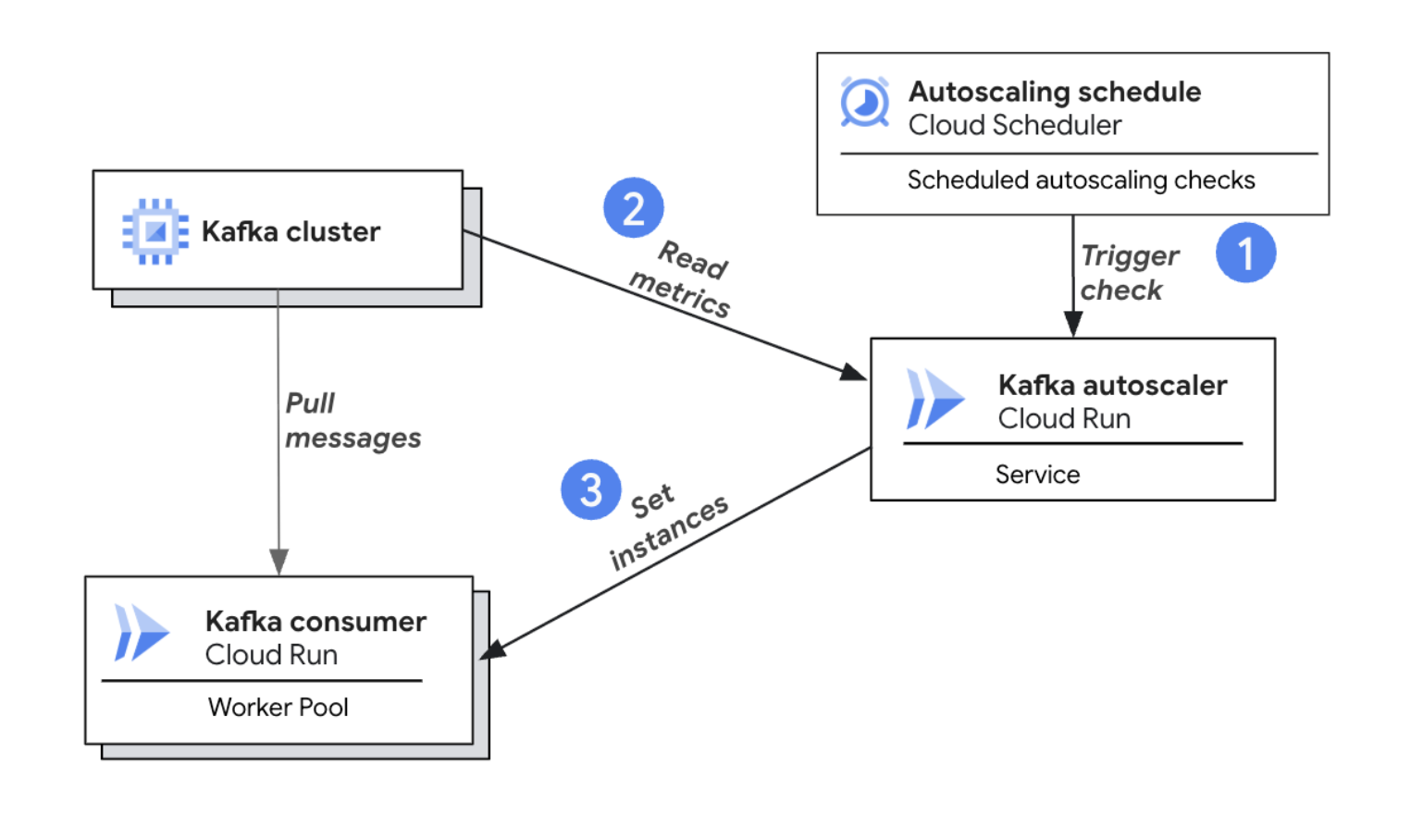
Cloud Run Kafka オートスケーラーのアーキテクチャ図
仕組みは次のとおりです。
-
自動スケーリングのチェックの実行: Cloud Scheduler がオートスケーラーを定期的にトリガーして、スケーリング評価を開始します。
-
Kafka オフセットラグの読み取り: オートスケーラーは、トリガーされると Kafka クラスタに接続してオフセットラグを読み取り、(必要に応じて)Cloud Monitoring に接続してコンシューマーの CPU 使用率を読み取ります。
-
スケーリングの決定と実行: オートスケーラーは、収集された指標とユーザー定義のスケーリング ポリシーに基づいて、最適なコンシューマー インスタンス数を計算し、Cloud Run の手動スケーリング API を使用して、新しいデプロイなしでインスタンス数を動的に調整します。
パターンの一般化
Kafka オートスケーラーのコア アーキテクチャ パターンはシンプルです。Cloud Run サービスが定期的にトリガーされ、カスタム指標を読み取ってインスタンス数を調整します。この柔軟なモデルは、pull ベースのあらゆるワークロードに適応でき、アプリケーションにとって最も重要な指標に基づいて Cloud Run ワーカープールをスケールできます。
アプリケーションがワーカープールを別のメッセージ キューから使用する場合や、ビジネス指標に基づいてスケールする必要がある場合は、同様の専用オートスケーラーを構築できます。いくつか例を挙げましょう。
-
セルフホスト型 GitHub ランナーの自動スケーリング: CI / CD キュー内の保留中のジョブ数に基づいて、セルフホスト型ランナーのプールを動的にスケールします。これにより、ランナーがアイドル状態のときにスケールダウン(ゼロまで)することでコストを最小限に抑えながら、ビルドを遅延なく実行できます。
-
カスタムの Prometheus 指標に基づくスケーリング: 処理キュー内のアイテム数やアクティブなユーザー セッション数など、Prometheus で公開済みのカスタムのビジネス指標に基づいてワーカープールをスケールします。これにより、インフラストラクチャの費用をリアルタイムのアプリケーション需要に直接結び付けることができます。
-
Pub/Sub バックログの処理: Pub/Sub サブスクリプションの未配信メッセージ数に基づいてワーカー数を調整します。これにより、トラフィックの急増時でもメッセージをタイムリーに処理でき、トラフィックが少ない期間は費用を節約できます。
Cloud Run ワーカープールと Kafka オートスケーラーにより、Kafka の実行に新たなレベルの柔軟性と使いやすさがもたらされます。お客様がこれらをどのように活用されるか、今から楽しみです。詳細とご利用開始方法は次のとおりです。
-
オープンソースの Cloud Run Kafka オートスケーラーを試す:
-
Cloud Run ワーカープールの詳細(ドキュメント)
-
オートスケーラーに関するフィードバックやご質問は、run-oss-autoscaler-feedback@google.com までお寄せください。
Apache Kafka のマネージド サービスをお探しの場合は、Google Cloud が提供する Managed Service for Apache Kafka もご検討ください。このサービスは、自動化されたクラスタ管理、Kafka Connect、スキーマ レジストリ(プレビュー版)を備えており、Google Cloud のモニタリング、ロギング、IAM が組み込まれているため、運用が簡素化されます。
このブログ投稿に協力してくれた Google Cloud チームメンバー、Andrew Manalo(サーバーレス スケーリング担当ソフトウェア エンジニア)、Sagar Randive(サーバーレス担当プロダクト マネージャー)、Matt Larkin(サーバーレス担当プロダクト マネージャー)に感謝します。
ー エンジニアリング マネージャー、Aniruddh Chaturvedi
ー シニア エンジニアリング マネージャー、Adam Kane



