Cloud Run サービスの信頼性をヘルスチェックで向上
Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
マイクロサービスを使ってアプリケーションを構築する場合、管理と信頼性はますます重大な課題になり得ます。システムでは、アプリケーションの異常を検出して、即時かつ自動的に修復することが求められます。この作業を自動化するには、インフラストラクチャの異なるレイヤが相互にやりとりし、連携する必要があります。ヘルスチェックは、設計のなかの単一レイヤが上位レベルのオーケストレーションまたはルーティング レイヤに情報を伝達するためのわかりやすい方法です。たとえば Kubernetes チェックは、コンテナを再起動する必要があるかどうかをクラスタ スケジューラに伝えます。また、バックエンドをチェックする Google Cloud Load Balancing ヘルスチェックは、トラフィックの送信先をフロントエンドに伝達します。Google は Cloud Run にヘルスチェックを導入し、サービスのレジリエンスを自動化するにあたってユーザーがより細かく制御できるようにしました。
Cloud Run のヘルスチェックでは次のことが可能です。
コンテナがリクエストを受信する準備が整うタイミングをカスタマイズする
コンテナの異常な状態を判断する基準をカスタマイズする
デフォルトでは、新しいコンテナを起動する際に、Cloud Run はコンテナがポートをリッスンするのを待機してからトラフィックを送信します。こうしたデフォルトの動作は大半のワークロードには有効ですが、動作をカスタマイズしたい場合もあるでしょう。さらに、Cloud Run は現在カスタムの「ライブネス」ヘルスチェックに対応しており、コンテナが異常だと判断された場合は再起動を行います。
ヘルスチェックの種類
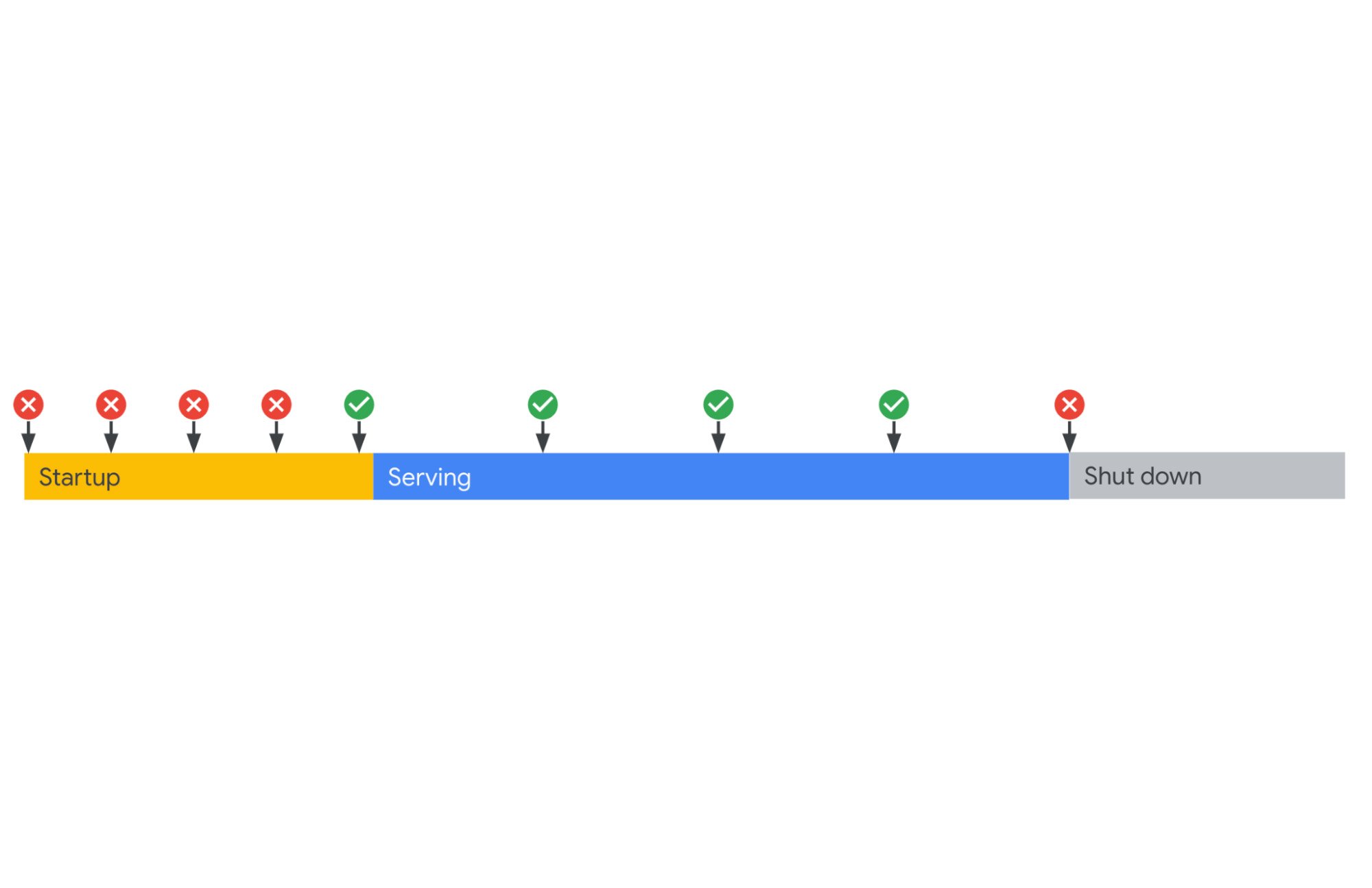
Cloud Run は、起動チェックとライブネス チェックの 2 種類のカスタム ヘルスチェックを提供します。この 2 種類のヘルスチェックの違いと、どのような場合に役立つかについてご説明します。
起動
ユーザーは startupProbe を構成して、コンテナが起動してリクエスト処理の準備が完了するタイミングを定義できます。このようなプローブが構成されている場合、プローブが成功するまでライブネス チェックが無効になり、それらのプローブがアプリケーションの起動を妨げないようにします。
初期構成の読み込みと起動に数分間かかるアプリケーションがあると仮定します。このアプリケーションは、起動処理を完了する必要があるため、プロセスが実行されていても利用開始できる状態にありません。また、アプリケーションがコンテナの新しいインスタンスをスケールするたびに、この問題が発生します。これが意味するのは、アプリケーションはコンテナ自体の準備が完了して正常に機能するようになるまで、いかなるトラフィックも受信すべきではないということです。startupProbe を使えば、Cloud Run からリクエストが送信された時点で、コンテナのリクエスト処理の準備が整っているようにできます。
ライブネス
Cloud Run を使うと、ユーザーはコンテナを再起動するタイミングがわかるように、ライブネス チェック プローブを構成できます。たとえば livenessProbe は、アプリケーションが実行されているが進行できないデッドロックの状態をとらえることができます。このような状態でコンテナを再起動することで、バグがあってもアプリケーションの可用性を高めるのに役立ちます。
アプリケーションにデッドロックが発生したことにより、無期限に停止してしまいリクエストが処理されなくなる状況について考えてみましょう。通常であれば Cloud Run は、プロセスが実行されていてコンテナも稼働しているため、アプリケーションは問題なくトラフィックを処理できると想定します。Cloud Run は不具合のあるアプリにトラフィックを送信し続けるため、複数のリクエストが失敗する結果となります。Cloud Run の livenessProbe を使うと、障害発生時に Cloud Run アプリケーションのコンテナ インスタンスを強制終了して、次のリクエスト到着で再起動するよう構成できます。
プローブの種類
種類の異なるヘルスチェックがどのように機能するかが理解できたところで、次はプローブ メカニズムを構成してみましょう。現在、Cloud Run での起動時のチェックでは HTTP Probe、TCP Probe、gRPC Probe、ライブネス チェックでは HTTP Probe と gRPC Probe がサポートされています。これらのプローブは Kubernetes ヘルスチェックと同じように互換性のある API を使って構成でき、以下のサンプルで示すように、プラットフォーム間でワークロードのポータビリティを確保できます。
TCP
TCP Probe では、Cloud Run はコンテナ上の指定された TCP ポートへの TCP 接続を試みます。正常な接続を確立できれば、コンテナとサービスは正常としてマークされ、トラフィックの処理を開始します。それ以外の場合は、異常ということです。TCP Probe は起動チェックでのみサポートされており、ライブネス チェックは対象外です。デフォルトでは、Cloud Run は新しいコンテナの起動時に TCP Probe を使って、コンテナがポートをリッスンするのを待機してからトラフィックを送信します。
HTTP
これは、起動とライブネス チェックで最も一般的に使われる種類のプローブです。HTTP Probe では、Cloud Run は指定されたパスに HTTP GET リクエストを送信してチェックを実行します。こちらの説明にある構成では、起動時に HTTP エンドポイント パスでリクエストが送信された後にコンテナが成功を返したら、コンテナを準備完了としてマークできます。アプリケーション内で、独自のヘルスチェック エンドポイント(例: /startz)を構成する必要があります。
同様に、こちらで説明されているように livenessProbe の HTTP エンドポイントを構成する場合、Cloud Run はサービスのヘルスチェック エンドポイントに HTTP GET リクエストを送信します。HTTP livenessProbe が制限時間内に成功しなかった場合、サービスは停止され、次のリクエスト受信で再起動されます。
上述の例は、一般的な HTTP startupProbe の構成を示しています。アプリケーションは起動プロセスを完了するまでに、20 x 10 = 200 秒与えられます。一度 startupProbe が成功すると、アプリケーションはトラフィック処理の準備完了としてマークされます。一度も成功しなかった場合、コンテナは 200 秒後に強制終了されます。
gRPC
Cloud Run は、gRPC プロトコルを使って通信するマイクロサービスのデプロイをサポートします。このようなサービスには、gRPC ヘルスチェックのプローブ メカニズムを使用できます。他の種類のプローブと原理は同じですが、アプリケーション内での gRPC Probe の構成は、gRPC ヘルスチェック プロトコルのガイドラインに従う必要があります。アプリケーションに gRPC サービス エンドポイントを実装したら、こちらで説明されているとおり、gRPC で起動チェックとライブネス チェックを使用するよう Cloud Run サービスを構成できます。
Service Health
この種類のチェックは Cloud Run 内のコンテナをより適切に管理するために使われ、コンテナが Cloud Run 自体と通信できるようになります。サービスが全体的に正常かどうかを示すためのロードバランサ レイヤでの「サービスレベル」のヘルスチェックは提供しません。代わりに、Cloud Run が稼働しているコンテナが利用可能な状態にあり、リクエストされたタスクを確実に実行できるようにすることで、サービス全体を高品質に保つことに注力して、潜在的なエラー率を低減します。
まとめ
サーバーレス環境で大規模なマイクロサービスのプールを管理することには、固有の課題が伴います。Cloud Run によってサーバーレス アプリケーションのホストと実行が非常に簡単になりますが、ヘルスチェックを活用することで、アプリをより詳細に制御して堅牢性と信頼性を高められるようになります。
Cloud Run サービスでヘルスチェックを設定する方法については、こちらをご覧ください。
- Google Cloud サーバーレス担当プロダクト マネージャー Sagar Randive



