GKE 運用の問題を解決: アラートから解決までの 5 つのステップ
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
アプリケーションがモノリシック アーキテクチャからマイクロサービスベースのアーキテクチャに移行するにあたり、DevOps チームとサイト信頼性エンジニアリング(SRE)チームは新しい運用の課題に直面します。マイクロサービスは新機能で絶えず更新され、リソース マネージャーやスケジューラ(Kubernetes や GKE など)ではワークロードの変化に応じてコンテナを追加または削除する場合があります。モノリシック アプリケーションについて学習した動作に基づいてアラートを作成するというこれまでのやり方は、マイクロサービス アプリケーションには通用しません。
そのため、マイクロサービスを運用しているチームは、問題を特定してトラブルシューティングを行うために指標、ログ、トレースにますます依存するようになります。さらに、より効率的に問題を診断するためには、豊富なコンテキスト(メタデータや、エンティティ間の関係)が必要とされます。こうしたさまざまな情報を 1 か所でまとめて可視化できれば、生産性が高まり、サービスの平均復元時間(MTTR)を短縮できます。これにより、新しいビジネス機能に集中することが可能になります。
GKE ダッシュボードでは、オブザーバビリティ データと関連する豊富なコンテキストが、使いやすく、ナビゲートしやすく、わかりやすい形で自動的に表示されます。本日は、ダッシュボードを使用して、簡単な 5 つのステップでアラート発生から解決まで導く方法をご紹介します。
まず、ダッシュボードでデータがどのように編成されているかを知り、多くのクラスタや多数の Kubernetes オブジェクトを扱っているときでも効率的に作業できる強力なフィルタ機能の活用方法を理解することが重要です。
GKE ダッシュボードについて
GKE ダッシュボードには、次の 3 つの主要な機能があります。
すべての関連データが 1 か所に: あらゆる指標とログ、関連するメタデータ(ラベル)、アラート、インシデント、Kubernetes イベント、すべての GKE エンティティの SLO が 1 つのダッシュボードにまとめられています。
強力なフィルタと集約: ダッシュボードは、GKE オブジェクト間のすべてのインフラストラクチャ関係を管理するコンテキストグラフをバックグラウンドで維持します。こうした関係は、Pod 内のコンテナのアカウント、Deployment 内の Pod、Namespace 内の Deployment、クラスタに関連付けられているノード、このような多くの関連付けを保持します。このコンテキストグラフにより、ダッシュボードのフィルタ メカニズムが提供され、ユーザーは関心のあるデータをすばやく絞り込むことが可能です。また、集約エンジンは、これらの関係に基づいて複合オブジェクトの指標を計算します。たとえば、サービスが 10 個の Pod を実行している場合、集約エンジンはサービスの全体的なリソース使用率を計算します。
データ探索ツールへの移動: ダッシュボードでは多くのトラブルシューティングが可能ですが、必要に応じて、簡単かつ適切にダッシュボードからログ エクスプローラ、Metrics Explorer、SLO モニタリングの詳細に移動して分析を深めることができます。
GKE ダッシュボードの使い方の例を見てみましょう。
ステップ 1: Kubernetes エンティティに関連付けられたアクティブなアラートを確認する
ダッシュボードを起動すると、最初にアラートの概要とタイムラインが表示されます。タイムラインにカーソルを合わせると、各アラートの詳細が記載されたイベントカードがポップアップ表示されます。この詳細情報には発生時間、アラートのトリガーとなったポリシー、アラートがトリガーされたリソース、このアラートにおける対応待ちのインシデントの有無などが含まれます。
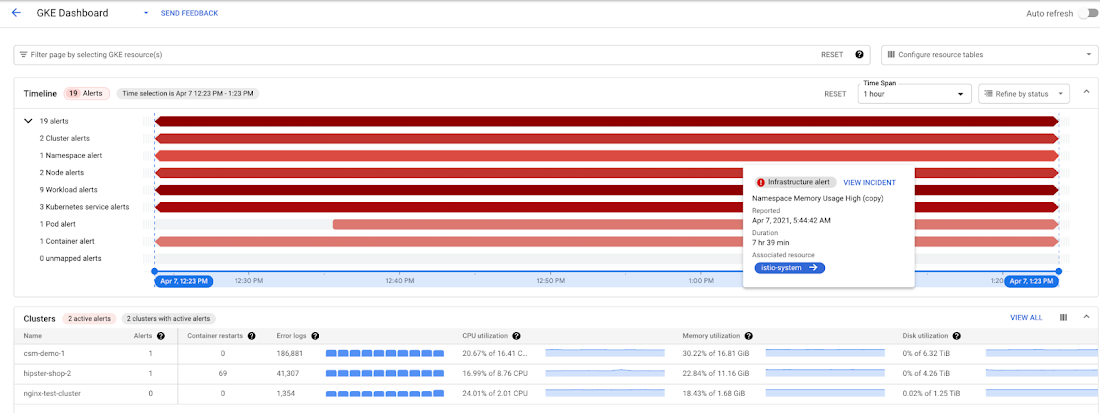
ステップ 2: ヘルス状態で並べ替えられた Kubernetes エンティティごとに詳細の概要を確認する
各 Kubernetes オブジェクトの指標とログデータの概要が、この表のグループに表示されます。それぞれのカテゴリ内のオブジェクトは、ヘルス状態に基づいて優先順位付けされます。インシデント数の多いオブジェクトが上部に表示されます。アラート数の隣には、次の概要が表示されます。
コンテナの再起動回数
SLO のステータス
エラーログ数の推移
主なリソースの使用率の指標(CPU、メモリ、ディスク)
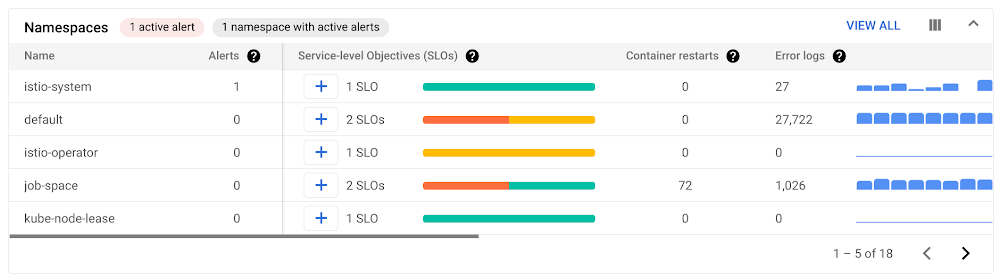
各表に表示されるオブジェクトは 5 個のみですが、[すべて表示] をクリックすると、その他のオブジェクトをすべて表示できます。
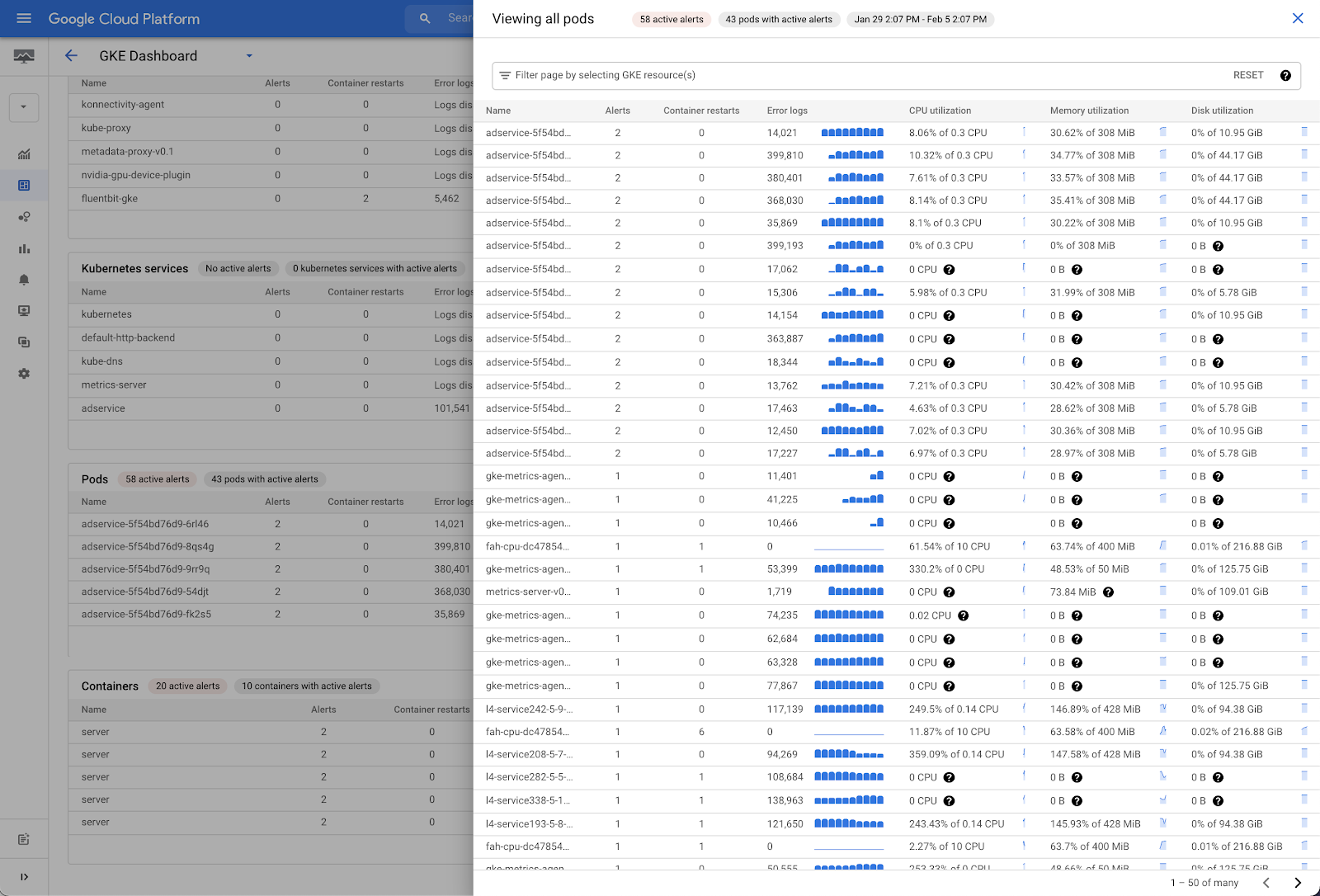
作業対象のアラートを決めたら、ダッシュボード内ですべてのデータをフィルタして、そのアラートに関連付けられたリソースだけに絞り込むことができます。このフィルタは、文字列一致のみのフィルタではなく、コンテキストグラフを使用します。そのため、特定のリソースを使用してダッシュボードにフィルタをかけると、それに応じて、このリソースに関連するその他のすべてのオブジェクトもフィルタされます。
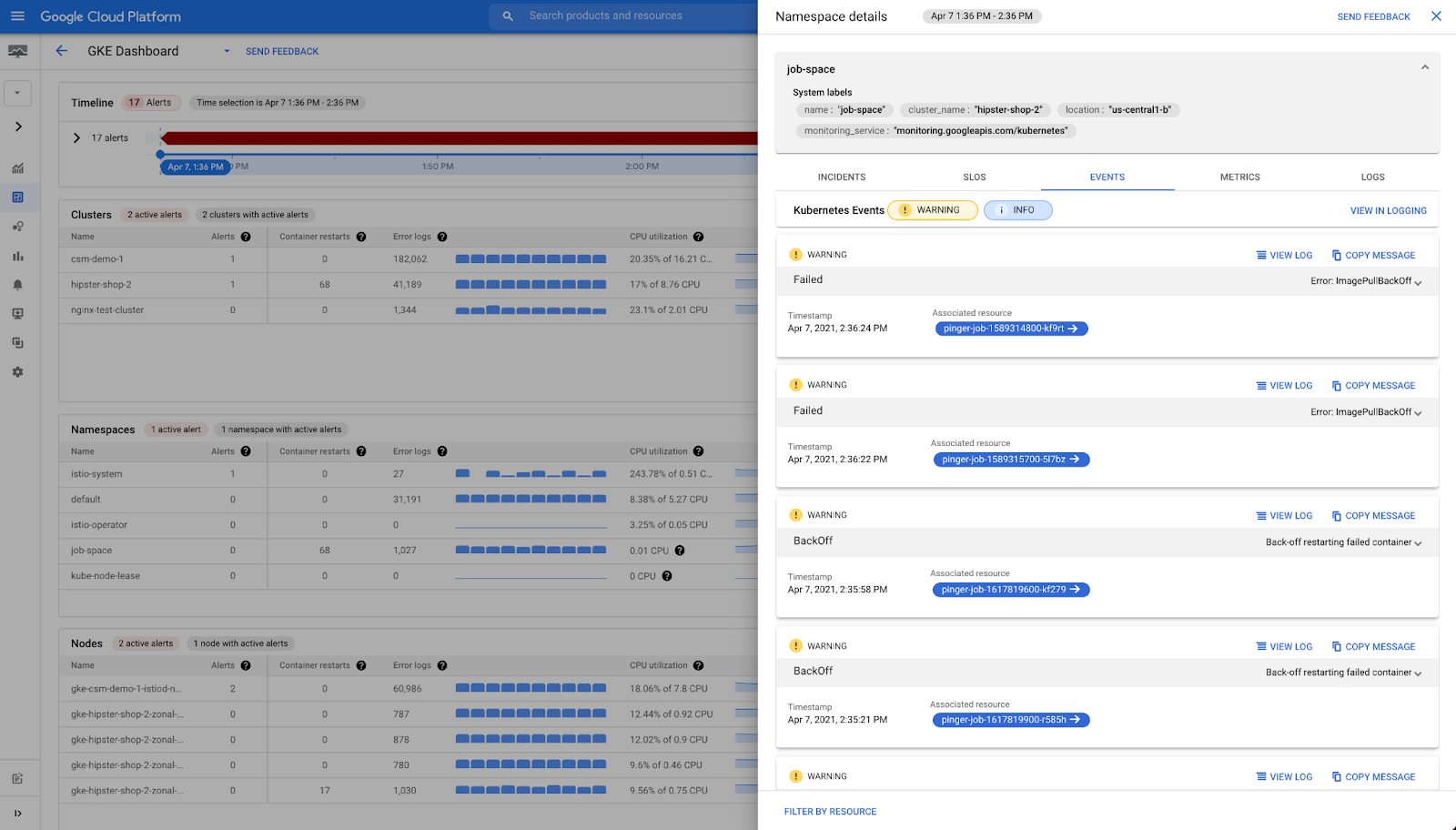
ステップ 3: 関連性のある Kubernetes イベントを特定する
必要なリソースをフィルタしたら、リソースの名前をクリックするだけで、ログから抽出された関連する Kubernetes イベントを確認できます。これは考えられる原因の絞り込みに役立ち、それによって GKE エンティティの異常な特性の理由がわかる場合があります。
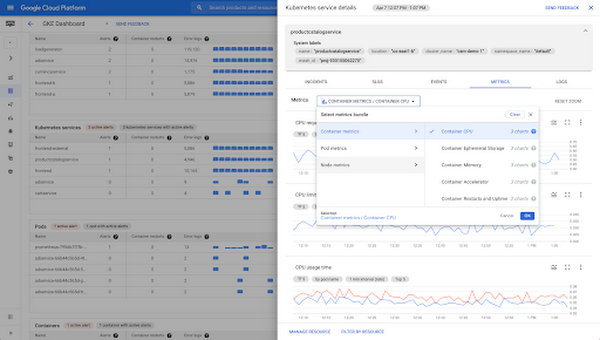
ステップ 4: 影響を受けている Kubernetes エンティティの指標をドリルダウンする
[指標] タブでは、スライドアウト パネルですぐに利用できる 44 の Kubernetes の指標を確認できます。Metrics Explorer に(コンテキスト内で)簡単に移動して、指標をさらに調べることも可能です。
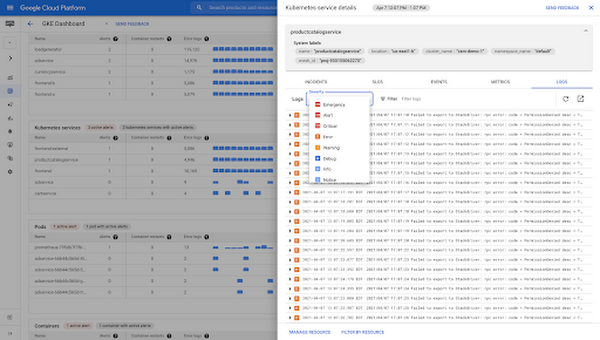
ステップ 5: Kubernetes エンティティのフィルタされたログを調査する
特定のオブジェクトのログのみを確認する場合は、[ログ] タブをクリックするとログを表示できます。このタブでログデータを調べることも可能です。ログを重大度でフィルタするか、フィルタバーに検索式を入力して、このリソースに関連性のあるログを絞り込めます。
まとめ
前述の 5 つのステップは、GKE ダッシュボードを使用して、GKE で実行されているアプリケーションに発生する可能性のある問題をトラブルシューティングする方法のフレームワークになります。すぐに使用できるダッシュボードは、デベロッパー、DevOps、SRE の各チームに、1 か所に集約されたオブザーバビリティ データとコンテキストを提供します。別のツールに移動することなく、情報をフィルタ、可視化、検索できます。これにより、MTTR を短縮して、コーディングや新しい機能の構築に専念することが可能になります。
使用を開始するには、Cloud Monitoring の GKE ダッシュボードに直接アクセスするか、こちらのドキュメントのページで詳しい情報をご確認ください。
-アウトバウンド プロダクト管理担当ディレクター Rakesh Dhoopar
-プロダクト マーケティング マネージャー John Day


