ゲスト投稿 : Silicon Therapeutics が GCP 上の Elastifile Cloud File System を創薬に使用した理由
Google Cloud Japan Team
編集部注 : 昨年、Google Cloud Platform(GCP)を創薬向けの大規模仮想スクリーニングに活用している Silicon Therapeutics の投稿を紹介しました。今回の投稿では、Elastifile Cloud File System と CloudConnect から得られるパフォーマンスとデータ管理について同社に解説していただきます。GCP に統合できるハイパフォーマンスのファイル システムを探している企業にとっては、同社が構築した環境はきっと参考になるでしょう。
私たち Silicon Therapeutics は、大規模なスケールアウト コンピューティングのためのプラットフォームとして GCP に注目し、創薬ワークロードの重要なコンポーネントとして使用しています。前回の投稿では、標的タンパク質の柔軟なコンフォメーション アンサンブルに基づき、数百万種の分子化合物の中から薬物分子になりそうなものをスクリーニングするにあたって、GCP をどのように活用しているかを紹介しました。
今回はデータの管理についてお話しします。ハイパフォーマンス コンピューティング(HPC)におけるワークフローの常として、私たちはデータの扱いに苦労しました。私たちが利用するコア アプリケーションの 1 つである、分子系内での原子群の経時的な変化を研究する分子動力学(MD)シミュレーションでは、データの管理とストレージについて考えなければならないことがたくさんあるからです。
原子群の経時的な変化は、ニュートンの運動方程式を解き、分子力学力場で原子間に働く力を計算することによって明らかになります。この種の計算では、それぞれ数万の原子を含む原子座標系のスナップショットが数千個も生成され、かなり大きい軌道ファイルが多数作られます。そのため、大規模なデータセット(たとえばタンパク質構造データ バンク(PDB)の 10 万の分子構造全体)を対象として MD シミュレーションを実行すると、(ペタバイトを超える)大量のデータが生成されます。
疾病に対する治療薬の発見を促進するには科学計算の時間短縮と精度向上がきわめて重要ですが、実際問題として、増加する一方のデータ量、スケーラブルでパフォーマンスの高い共有データ アクセスという要件、複雑なワークフローといった壁が立ちふさがり、その実現は困難をきわめます。インフラストラクチャ、特にファイル ストレージをめぐる難問の解決に時間を取られ、本来なら研究自体に使えたはずの時間がなくなってしまい、重要な科学の発展が遅れてしまうことも少なくありません。
私たちが取り組んでいる物理学ベースのワークフローは、膨大な量のデータを短時間で生み出す並列プロセスを作成します。このようなワークフローをサポートするには、柔軟でパフォーマンスの高い IT インフラストラクチャが必要です。しかも、シミュレーションの結果を分析してパターンを見つけ出し、新しいドラッガブルな分子を見つけるためには、その膨大なデータ全体(この場合は 1 PB 以上)をふるいにかけなければなりません。ところが、そのようなインフラストラクチャを社内で構築しようとすると、非常に高いコストがかかります。
このようなワークフローには、シミュレーションやアナリティクス向けに数千もの並列コンピュート ノードを簡単に用意できるパブリック クラウドが適しています。しかし、スケーラブルでパフォーマンスの高いコンピュート ノードは簡単に手に入っても、補完的にスケーラブルでパフォーマンスの高いストレージをクラウドで手に入れようとすると苦労します。
そこで私たちは、大規模データの格納、管理、処理に適した単純で効率のよい方法を常に模索してきました。そして、GCP と Elastifile のクロスクラウド データ ファブリックの組み合わせなら、私たちが抱えるデータの難問を解決し、研究のペースを上げられることがわかったのです。

ハイパフォーマンスでスケールアウト可能なファイル ストレージが不可欠な理由
爆発的にデータを生成する分子シミュレーションと分析のワークフローを効果的にサポートするには、次の 3 つの要件を満たすストレージ ソリューションが必要でした。- ファイルネイティブなメイン ストレージ : 私たちの分子シミュレーション用の分析ソフトウェアは、多くの科学計算アプリケーションと同様に、厳格な整合性を保証するファイル システムのファイル形式でデータを生成、インジェストする設計になっています。この種のアプリケーションが近い将来、Google Cloud Storage のようなオブジェクト ストレージ システムと直接インターフェースをとるようにリファクタリングされることはないでしょう。したがって、クラウド ベースの POSIX 準拠ファイル システムが必要です。
- スケーラブルなグローバル ネームスペース : 小さなデータセットを対象とする単純な分析であれば、ばらばらなクラウド インスタンスのファイル サーバーをつなぎ合わせるような方法で十分かもしれません。しかし、データセットが大きくなり、複数のアプリケーションでデータを共有しなければならない場合(たとえばマルチステージのワークフロー)には DIY 的な方法では対応できません。そのため、スケーラブルなグローバル ネームスペースを提供できる、完全に分散化された共有ファイル システムが必要です。
- 高いコスト効率 : 爆発的にデータを生成する大規模なワークロードを管理する場合に、固定容量のストレージを使用するとコストが非常に高くつきます。需要に合わせた形でインフラストラクチャのコストを抑えるためには、すばやくデプロイ / 破棄できるソリューションが必要です。さらに、最大限の柔軟性を確保するには、1)サイト、クラウド相互間、2)「アクティブ」な処理で使うファイル形式と「非アクティブ」なストレージ / アーカイブ / バックアップで使うコストのかからないオブジェクト形式との間、の両方でデータを簡単にやり取りできるポータビリティの高いソリューションが理想的です。
ファイル ストレージ問題の解決方法
上述のようなストレージの要件を満たし、研究の要件拡大にも対応するために、私たちは複雑な MD ワークフローのバックボーンとして、Elastifile のクロスクラウド データ ファブリックを使うことにしました。ソリューションの中心は、クラウドおよびハイブリッド クラウド環境で高いパフォーマンスとスケーラビリティを実現するように設計された、ソフトウェアのみによる分散ファイル システムの Elastifile Cloud File System(ECFS)です。ECFS は、クラウド規模でノイズの多い異種環境をサポートするように作られており、データ集約的な科学計算ワークフローのメイン ストレージに特に適しています。
Elastifile のファイル システムは、データのポータビリティとポリシー ベースの制御を容易にするため、Elastifile の「データ コンテナ」を介してアプリケーションから操作できるようになっています。各ファイル システムは、複雑なワークフローに含まれる並列、トランザクション アプリケーションのサポートに必要な厳格な整合性を維持しつつ、単一のネームスペースのもとで複数のクラウド インスタンスにまたがることができます。
私たちは、GCP 上に ECFS をデプロイすることにより、MD ワークフローを単純化、最適化することができました。そして、上で述べた PDB 規模のスクリーニングの概念検証として、500 種の一意なタンパク質に適用してみました。
この計算では、GCP 上で動作する SLURM クラスタを使っています。コンピュート ノードは 16 個の n1-highcpu-32 インスタンスで、各インスタンスには 8 個の GPU が接続され、合計で 120 個の K80 GPU と 512 個の CPU が使用できます。ストレージ機能は、すべてのコンピュート ノードにマウントされている 6 TB の Elastifile データ コンテナによって提供されます。
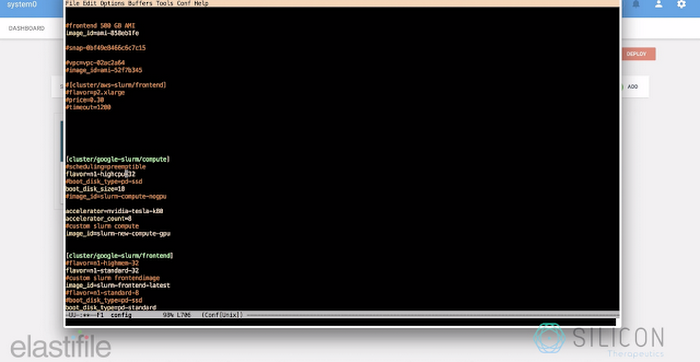
Elastifile を導入する前は、このようなワークフローにおけるストレージのプロビジョニングや管理には複雑な手作業が必要でした。具体的には、手作業で入力データセットを分割し、それぞれ専用のディスクを持つ複数の異なるクラスタを作成していました。このようなことをしていたのは、1 つの巨大なディスクを作ると、大きなメタデータのために NFS が問題を起こすことが多かったからです。
各クラスタへの出力が終わると、ディスクをスナップショットとして保存しました。アクセスのためにインスタンスをスピンアップし、データ アクセス用の認証情報を共有していましたが、このアクセス パターンはエラーを起こしやすく、セキュリティにも問題がありました。また、規模が大きくなると、この種のマニュアル プロセスは時間がかかり、致命的エラーやデータ消失のリスクがありました。
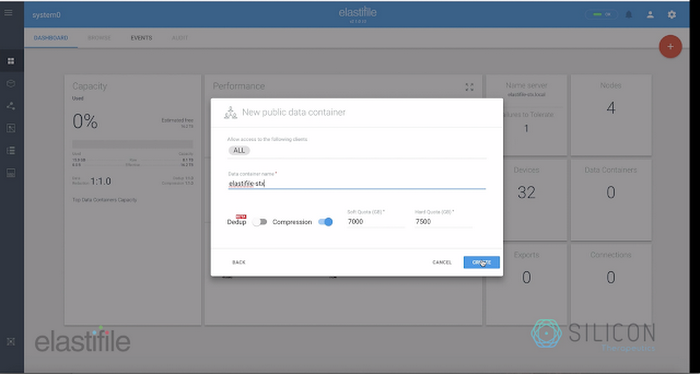
ところが、Elastifile の導入後、ストレージ リソースのデプロイと管理は迅速かつ容易な作業へと変わりました。単純に希望する容量を指定すれば、ECFS クラスタが自動的にデプロイ、構成され、SLURM が管理するコンピュート リソースから利用できるようになったのです。しかも、これに要するのはわずか数分にすぎません。
また、あとで必要になったら、ボタンを一度押すだけで、容量を追加してクラスタを拡張できます。これで、インフラストラクチャはワークフローの要件やデータの規模のダイナミックな変化に対処できます。Elastifile は、クラウド ベースのファイル システムのデプロイを単純化かつ自動化し、手作業によるストレージのプロビジョニングに伴う複雑さやリスクを低減したのです。
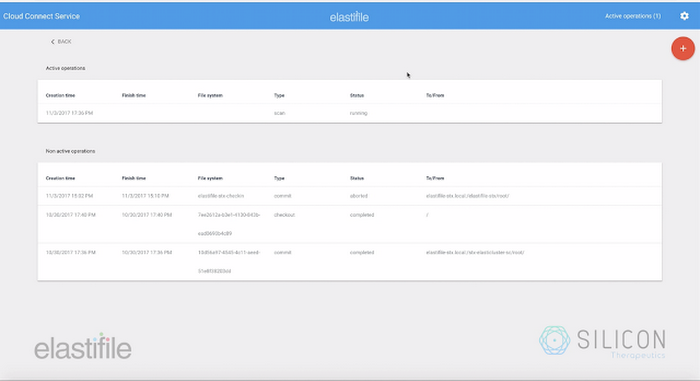
さらに、Elastifile の CloudConnect サービスを使用することで、ECFS と Cloud Storage の間でデータをシームレスに昇格、降格できるようになり、インフラストラクチャのコストを低減できました。Elastifile のデータ コンテナから Google バケットへのデータの移動は Elastifile CloudConnect で単純化され、データ移動後は Elastifile インフラストラクチャを解体すれば不要なコストを削減できます。
私たちにとって、このデータ移動はとても重要です。このデータのサブセットをローカル デスクトップ上で可視化、分析する必要があるからです。Elastifile のデータ パフォーマンス、並列性、スケーラビリティ、共有性、ポータビリティを組み合わせることにより、私たちは従来よりも短時間で大規模な分子分析を多くこなせるようになりました。これは前進であり、より良い薬剤候補を見つけ出すうえで役に立つでしょう。
次のステップでは、PDB のすべての一意なタンパク質構造を対象とするところまでワークフローの規模を拡大し、スクリーニング後のデータに深層学習分析を加え、タンパク質動力学、ドラッガビリティ、強結合リガンドから関連パターンを見つけられるようにするつもりです。
GCP 上での高度に並列的なオンクラウド分子分析をサポートする Elastifile の詳しい仕組みについては、こちらのデモ動画をご覧ください。また、Elastifile のサイトも参照してください。
* この投稿は米国時間 2 月 6 日、Silicon Therapeutics の Chief Science Officer である Woody Sherman 氏と、同じく Principal Investigator である Vipin Sachdeva 氏によって投稿されたもの(投稿はこちら)の抄訳です。
- By Woody Sherman, Chief Science Officer and Vipin Sachdeva, Principal Investigator, Silicon Therapeutics



