新しい Cloud Speech-to-Text で通話や動画音声のテキスト変換精度が向上
Google Cloud Japan Team
Google Cloud の AI を利用した音声サービスが急ピッチで進化を遂げています。今年 3 月には、DeepMind の音声生成モデル WaveNet を採用した音声合成 API の Cloud Text-to-Speech をリリースしました。さらにこのほど、Cloud Speech-to-Text(旧称 : Cloud Speech API)について、2 年前の発表以来最大規模となる改良を行いました。
Cloud Speech API は 2016 年に初めて発表され、1 年近く前から正式提供(GA)されており、半年で 2 倍以上というペースで利用が伸びています。今年 4 月の NAB と SpeechTek の両カンファレンスの開幕に合わせて、私たちは Cloud Speech-to-Text の新機能とアップデートをリリースしました。これにより、通話や動画のテキスト起こしなどの用途で、Cloud Speech-to-Text が一段と便利に利用できるようになったと考えています。
Cloud Speech-to-Text は新たに以下をサポートしています。
- 通話や動画の音声のテキスト変換精度を高める構築済みモデルの選択
- 長時間の音声から変換したテキストの可読性を高める自動的なパンクチュエーション(句読法)
- テキスト変換ワークロードをタグ付けしてグループ化し、Google チームにフィードバックを提供する新しいメカニズム(認識メタデータ)
- 99.9 % の可用性を保証する標準 SLA(サービスレベル契約)
今回のアップデートを詳しく見ていきましょう。
動画音声に対応した新しいテキスト変換モデル
音声認識技術には、人とコンピュータのやりとり(音声コマンドや自動音声応答など)から音声分析(コールセンター分析など)まで、多種多様な用途があります。私たちは Cloud Speech-to-Text の最新バージョンで、通話や動画の音声からのテキスト起こしなど、特定のユース ケース向けにカスタマイズされたモデルを追加しました。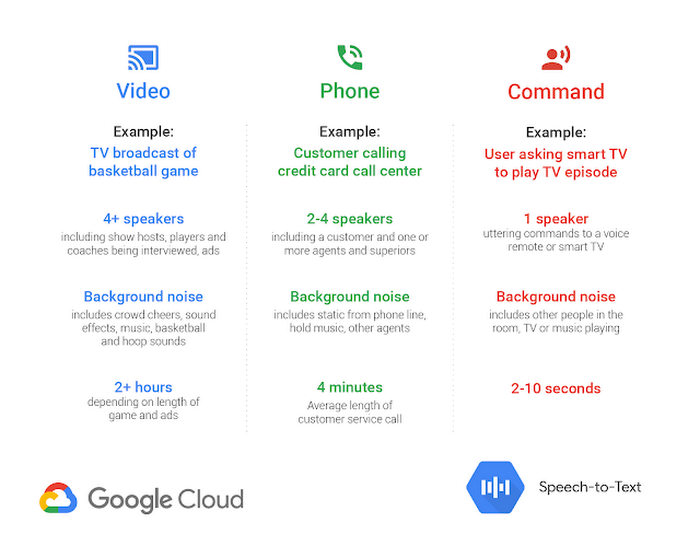
たとえば、着信した米国英語の通話リクエストを、これまでは通話処理に最適化されたエンジンに自動的に転送していました。このエンジンは業界でクラス最高という評価を多くのお客様からいただいているモデルです。今回の最新バージョンでは、お客様は新たに、こうした自動的なモデル選択に依存することなく、お好みのモデルを明示的に選択できるようになりました。
ほとんどの主要クラウド プロバイダーは、着信したリクエストの音声データをプロダクトの改良に利用しています。Google Cloud ではこの手法を避けてきましたが、お客様からは常に、自分たちの実際のデータを使ってモデルを改良してほしいという要望が寄せられています。
私たちはプライバシーに配慮し、データ保護ポリシーに準拠しながら、このニーズに応えたいと考えました。そこで、データ ロギングに関する、業界でも先駆的なオプトイン プログラムを立ち上げ、このデータに基づく最初のモデルとして enhanced phone_call を追加しました。
enhanced phone_call モデルの開発にあたっては、Cloud Speech-to-Text とのデータ共有を自ら望んだお客様のデータを使用しました。データ ロギングに関するオプトイン プログラムに参加することを選択したお客様は今後、お客様のデータに基づくこうした強化型モデルにアクセスできるようになります。この enhanced phone_call モデルを通話テスト セットに適用したところ、basic phone_call モデルと比べてエラーが 54 % 少ない結果となりました。
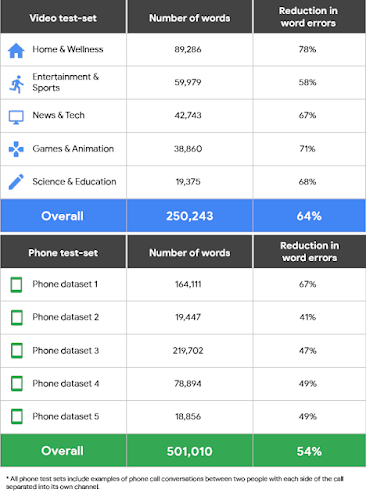
さらに私たちは、動画の音声や、複数の話者による音声の処理に最適化された video(動画)モデルも発表しました。この動画モデルは、YouTube のキャプション機能で使われているのと同様の機械学習技術を採用しており、動画テスト セットに適用した結果はデフォルトのモデルよりエラーが 64 % 少なくなっています。
enhanced phone_call モデルと、プレミアム料金が設定されている video(動画)モデルは、現時点では英語の変換に対応していますが、他の言語についてもすぐに利用できるようになります。また、既存モデルの command_and_search や、長時間音声テキスト変換の default モデルも引き続き提供されます。
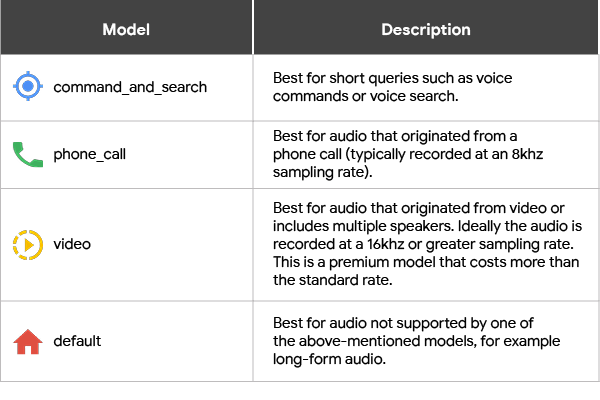
こちらのウェブ サイトにデモが用意されていますので、音声ファイルをアップロードして、これらの各モデルによるテキスト変換結果をご覧ください。
自動パンクチュエーションで読みやすいテキストを生成
多くの人々は、小学校を卒業するまでに基本的なパンクチュエーション(カンマ、ピリオド、疑問符)の使い方を学びます。しかし、音声から変換したテキストにカンマ、ピリオド、疑問符を適切に挿入するのは大変です。実際、ボイスメール メッセージのテキスト変換に取り組み始めた初期の段階で、それがいかに大変なことかを私たちは思い知らされました。変換結果は、複数の文が接続詞やピリオド、セミコロンなしでずらずらとつながり、とても読みにくいものでした。Google は数年前、Google Voice に含まれるボイスメールのテキスト変換サービスで、自動パンクチュエーション機能の提供を開始しました。その担当チームは最近、長時間音声のテキスト変換における自動パンクチュエーションの精度を向上させるため、LSTM(long short-term memory)ニューラル ネットワークを構築しました。パフォーマンスを考慮して設計されたこのモデルは現在、ベータ版が Cloud Speech-to-Text で使用されており、音声から変換されたテキストに自動的にカンマ、疑問符、ピリオドを入れることができます。
認識メタデータでユース ケースを記述
Cloud Speech-to-Text の進化は、この 2 年間に皆さんから寄せられたフィードバックの賜物です。こうしたコミュニケーションを、認識メタデータを使ってさらに活性化させていきたいと考えています。そこで今回、音声や動画から変換したテキストを、“ショッピング アプリの音声コマンド” や “バスケットボールの TV 番組” といったタグで記述できるようにしました。私たちは Cloud Speech-to-Text のユーザー全体にわたってこの情報を集約し、次に何に取り組むかの優先順位を付けるのに役立てます。認識メタデータの提供は、時間とともにユース ケースでの変換精度が上がる可能性を高めることにつながるのです。ただし、このプログラムへの参加は完全に任意です。
お客様のコメント
私たちから見て、Cloud Speech-to-Text の新バージョンは実にエキサイティングな仕上がりとなっています。ですが、私たちの話よりもお客様のコメントに耳を傾けていただければと思います。音声のような非構造化データはリッチな情報に満ちていますが、そこから簡単に価値を引き出して管理できるアプリケーションを見つけることに多くの企業が苦労しています。Descript は、音声ファイルをドキュメントのように簡単に編集、表示できるようにします。当社では、このアプリケーションの基盤として Cloud Speech-to-Text を選択しました。私たちがテストしたところでは、Cloud Speech-to-Text は最も高度な音声認識技術であり、新しい動画モデルは、私たちが調査した他のどの技術と比べてもエラーが半分にとどまります。料金モデルもシンプルであり、私たちはユーザーにベストな価格でアプリケーションを提供できます。
Andrew Mason 氏、Descript の CEO
LogMeIn の GoToMeeting は、市場をリードするコラボレーション ソフトウェアを世界中の数百万人のユーザーに提供しています。私たちは常に最高のカスタマー エクスペリエンスを追求しており、会議の録画データをテキスト化できるソリューションを数多く評価した結果、Cloud Speech-to-Text の新しい動画モデルの精度が断然優れていることがわかりました。Google サービスとの連携により、GoToMeeting による会議録画のテキスト化をサポートすることで、会議の後もお客様の価値創出に貢献できるのはうれしいことです。
Matt Kaplan 氏、LogMeIn の コラボレーション プロダクト担当最高プロダクト責任者
私たち InteractiveTel は、リアルタイム通話テキスト変換および分析サービスを、リリース当初から Cloud Speech-to-Text を使って提供しています。Google が Cloud Speech-to-Text の機能とパフォーマンスを急ピッチで高めていくことにいつも驚かされていますが、新しい phone_call モデルを使った変換の結果には衝撃を受けました。新しい phone_call モデルに切り替えただけで、変換精度が他のプロバイダーを 64 % も上回り、Google の一般的な狭帯域モデルと比べても 48 % 高くなったからです。
Jon Findley 氏、InteractiveTel のリード プロダクト エンジニア
ユーザーとのつながりを持ち、学ぶことを望んでいる企業にとって、高品質のテキスト変換技術との出会いは可能性の扉を広げることになります。最新のアップデートが施された Cloud Speech-to-Text により、お客様はシンプルな REST API を通じて、Google の機械学習専門家チームによる最新の研究成果にアクセスできます。
利用料金は、動画を除くすべてのモデルでの音声認識が 0.006 ドル / 15 秒(利用時間が月間 60 分までは無料、以下同じ)、新しい動画モデルでの音声認識が 0.012 ドル / 15 秒です。なお、動画音声認識は 2018 年 5 月 31 日までの試用期間に限り、他の音声認識と同じ料金(0.006 ドル / 15 秒)でご利用いただけます。詳細は、プロダクト ページのデモをお試しになるか、ドキュメントをご覧ください。
* この投稿は米国時間 4 月 9 日、Cloud AI の Product Manager である Dan Aharon によって投稿されたもの(投稿はこちら)の抄訳です。
- By Dan Aharon, Product Manager, Cloud AI



