Cloud Storage のパフォーマンスを最適化する
Google Cloud Japan Team
Google Cloud Storage は、ほとんどの(すべてではないとしても)開発ニーズに対応できる、Google Cloud Platform の強力な統合型オブジェクト ストレージです。ユーザーに近いエッジでのサービス提供や、CDN(コンテンツ配信ネットワーク)、自動冗長化といった機能をすぐに利用できますし、もちろん、このストレージを使うことによる自社の二酸化炭素排出量はゼロです!
それでも、個々の開発者ごとに Cloud Storage に関して固有のユース ケースや要件があります。Cloud Storage をそのまま使用しても得られるパフォーマンスは素晴らしいですが、この投稿では、特定のユース ケースへの最適化に役立つ高度なコツ、工夫、アドバイスを紹介します。
パフォーマンス基準の確立
まず念頭に置かなければならないのは、測定できないものは改善できないということです。したがって、Cloud Storage バケットのパフォーマンスを最適化するにあたっては、ベースライン予測を確立することが重要になります。
そこで、ここでは perfdiag ユーティリティを実行することをお勧めします。このユーティリティは一連のテストを実行し、Cloud Storage バケットの実際のパフォーマンスを出力します。また、多数のオプションが用意されていますので、自社の使用パターンにできるだけ合うように細かくチューニングできます。
こうしたユーティリティは、基準を確立するのに役立ち、パフォーマンスが期待と異なる場合に、どこに問題があるかを調べるときの手助けとなります。
アップロード パフォーマンスの向上
小さなファイルを高速にアップロードする
Cloud Storage の各アップロード トランザクションには小さなオーバーヘッドが発生します。大量のアップロードを行うシナリオでは、それが処理のパフォーマンスに直結してしまいます。たとえば、1 KB のファイルを 2 万個アップロードすると、各アップロードのオーバーヘッド時間がアップロード時間全体よりも長くなります。
この「処理あたりのオーバーヘッド」という考え方は新しいものではなく、その解決策も同様です。それは処理をバッチ化することです。たとえば、CPU の SIMD プログラミングを行ったことがある人は、バッチ処理が各処理のオーバーヘッドを軽減し、パフォーマンスを高めることをご存じでしょう。
gsutil で “-m” オプションが提供されているのは、それが理由です。このオプションは、ローカル マシンからクラウド バケットに対して、バッチ化された並列(マルチスレッド / 多重処理)アップロードを行い、アップロード パフォーマンスを大幅に向上させます。
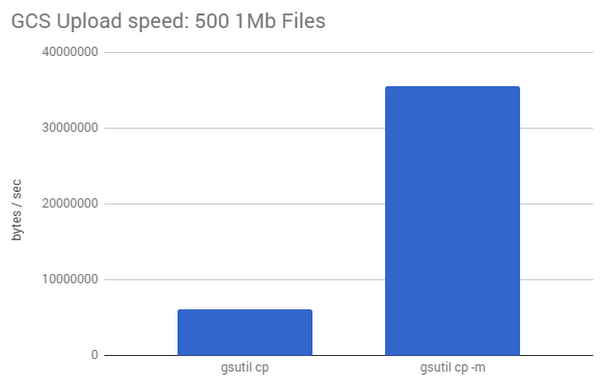
下の図は、200 KB のファイル 100 個を個別にアップロードした場合と、gsutilの -m オプションでバッチ アップロードした場合のパフォーマンスを比較した結果です。この例では、-m オプションによってアップロード速度が 5 倍以上に向上しています。
大きなファイルを効率的にアップロードする
gsutil ユーティリティを使用すると、オブジェクト作成を自動的に用いて、Cloud Storage にアップロードしたい大きなローカル ファイルの並列アップロードを行うことができます。この機能は、大きなファイルをコンポーネントに分割し、それらを並列にアップロードして、それらがクラウドに到着したらファイルを再作成する(そして、ローカルに作成した一時的なコンポーネントを削除する)という仕組みです。
この機能を有効にするには、gsutil で “parallel_composite_upload_threshold” オプションを指定します(または、コンソール出力が示すように、.boto ファイルを更新します)。
“localbigfile” は、サイズが 150 MB より大きいファイルを示します。このコマンドは、データを 150 MB 以下のチャンクに分割し、それらを並行してアップロードすることでアップロード パフォーマンスを高めます(使用可能なチャンクの数には制限があります。詳しくはドキュメントをご覧ください)。
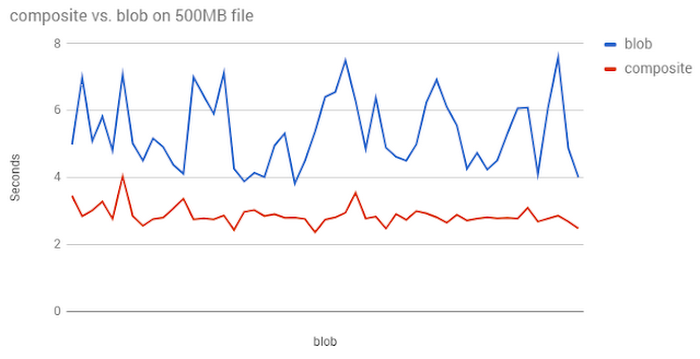
下のグラフは、500 MB のファイル 100 個を使って、こうした複合アップロードと通常のアップロードの速度を比較したときの結果を示しています。
順次命名のボトルネックを回避
多数のファイルを Cloud Storage にアップロードする際、Google Cloud のフロントエンドは、アップロード接続を多数のバックエンド シャードに自動的に分散し、転送を処理します。この自動分散は、デフォルトではファイルの名前 / パスに基づいて行われます。これは、ファイルがさまざまなディレクトリに存在する場合には非常に有益です。各ファイルがさまざまなシャードに適切に分散されるからです。
このことは、ファイル名の付け方がアップロード速度に影響を与えうることを意味します。たとえば以下のように、タイムスタンプを含むディレクトリ構造を使用しているとしましょう。
YYYY/MM/DD/CUSTOMER/timestamp
このディレクトリ構造のせいで、アップロード速度に問題が生じる可能性があります。ファイル名が非常に似ているので、接続の大部分が同じシャードに誘導されるからです。接続数が十分に多くなれば、すぐにパフォーマンスが低下するおそれがあります。このシナリオは、タイムスタンプと深く関連するデータセット(写真やセンサー データ ログのような)では非常に一般的です。
この問題のシンプルな解決策は、フォルダ名やファイル名を変更し、それらが線形にならないようにすることです。たとえば、(固定範囲で)均等に分散されたハッシュをファイル名の先頭に追加すれば、線形性が崩れ、ロード バランサは、より適切に接続のパーティショニングを行えます。
下の例は、線形の命名が行われたファイル群と、ファイル名の先頭にハッシュが追加されたファイル群のアップロードに要した時間の違いを示しています。

補足しておくと、この名称変更プロセスによってパイプラインのデータ依存関係が壊れる場合は、アップロードが完了したあとに、ファイルのハッシュを削除するスクリプトを実行してください。
ダウンロード パフォーマンスの向上
最適なフェッチ サイズの設定
前述したように、Cloud Storage ではリクエストごとにトランザクションのオーバーヘッドが必ず発生します。つまり、(アップロードの場合と同様に)ダウンロードにおいても、データのダウンロードに必要なリクエストのサイズと回数のスイート スポットを見つけることができれば、パフォーマンスの向上につながるということです。
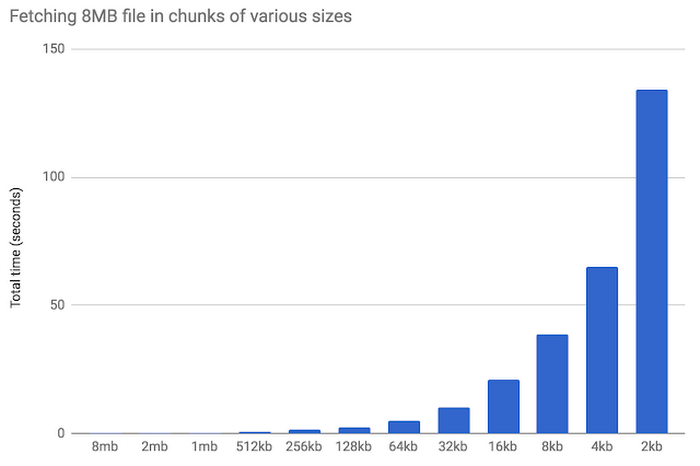
デモとして、8 MB のファイルをさまざまなサイズのチャンクでフェッチしてみましょう。下のグラフから、ブロック サイズが大きくなるとパフォーマンスが向上することがわかります。チャンク サイズが小さくなると、トランザクションあたりのオーバーヘッドが増加し、パフォーマンスが低下しています。
このグラフは、シングルストリームのスループットがきわめて優れる Cloud Storage のパフォーマンスを浮き彫りにしています。これは、アップロードとダウンロードの両方に言えることです。Cloud Storage のパフォーマンスは、サイズが 1 MB 程度の大きなリクエストのときに最も高くなります。そのため、小さなリクエストを使用しなければならない場合は、それらの並列化を試み、固定レイテンシの影響の軽減を図るようにしてください。
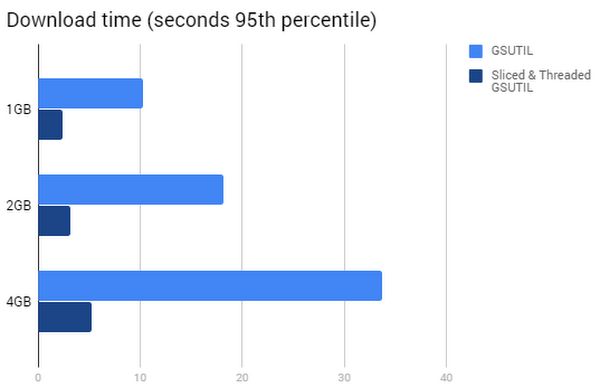
GSUTIL での大きなファイルの読み取りを最適化
マルチギガバイト ファイルをインスタンスにダウンロードして処理しなければならない場合、gsutil のデフォルト設定は大きなファイルの転送に最適化されていないということに注意が必要です。パフォーマンスを改善するには、スライシングの利用やスレッド数を調整したほうがよいかもしれません。
GSUTIL のデフォルト設定では、ファイルのダウンロードを 4 つのスレッドで実行しますが、使用されるプロセスは 1 つだけです。そのため、1 つのファイルを強力な Compute Engine VM にコピーする場合は、スレッド数を制限し、複数のプロセスを使用するようにシステムを強制することで、パフォーマンスを向上させることができます。
GSUTIL には、大きなファイルの場合に役に立つすばらしい機能があります。Cloud Storage から大きなオブジェクトをダウンロードするときは、HTTP Range GET リクエストを使用して、“スライスされた” ダウンロードを並行して実行できるのです。
下のグラフからわかるように、HTTP Range GET リクエストによるスライスされたスレッド ダウンロードを使用することで、ダウンロード時間を大幅に短縮できます。
以上、急場しのぎのトリックを交えつつ、Cloud Storage 環境から最大限のパフォーマンスを引き出すためのテクニックを紹介しました。ほかにも有用なコツをご存じでしたら、ソーシャル メディアでお知らせください。取り上げてほしいトピックについても、お待ちしています。
また、Google Cloud Platform の YouTube チャンネルにぜひご登録ください。クラウド アプリケーションの最適化に威力を発揮するコツやテクニックをお届けしています。
* この投稿は米国時間 3 月 7 日、Developer Advocate の Colt McAnlis によって投稿されたもの(投稿はこちら)の抄訳です。
- By Colt McAnlis, Developer Advocate