夏休みの自由工作:TensorFlowでじゃんけんマシンを作る
Google Cloud Japan Team
* この投稿は米国時間 10 月 12 日に投稿されたもの(投稿はこちら)の抄訳です。
Postesd by Google Cloud デベロッパー アドボケイト 佐藤一憲
今年はまとまった夏休みが取れたので、息子といっしょに作れる自由研究のアイディアを探していました。結果、できあがったのが、TensorFlow で作った「じゃんけんマシン」です。

TensorFlow で作った「じゃんけんマシン」
この動画の通り、手袋に付けたセンサーを使ってグー、チョキ、パーのいずれかを判定し、それに負けない手を出すマシンです。単純なおもちゃではありますが、隠し味としてTensorFlowを使いました。TensorFlowでとても簡単な機械学習(ML)のモデルを作成し、手袋につないだ Arduino マイクロコントローラでそれを利用して手の形を読み取る仕組みです。ML を便利なツールとして使うことで、面倒くさがりなプログラマーの私でも柔軟かつ正確でしっかり動くデモを数時間で作成できました。
この記事では、このじゃんけんマシンの作り方を通じて、最先端の AI とは関係のない日常のプログラミングでも ML や TensorFlow を強力な道具として活用する方法を紹介します。じゃんけんマシンのハードウェアは 2 万円程度で購入でき、ソースコードもここで公開しているので、誰でも同じものを作れるはずです。
では以下、じゃんけんマシンの作り方を見ていきます。
手順 1:手袋センサーを作る
じゃんけんマシンのハードウェアは、littleBits を使って作成しました。この製品は子供向けの電子工作キットで、LED やモーター、スイッチ、各種センサー、コントローラー等の様々なモジュールが揃っています。いずれもマグネット式で簡単につなげるので、ハンダ付けはいりません。 今回のマシンの手袋センサーは、ビニール手袋に 3 つの曲げセンサーを貼り付けて作りました。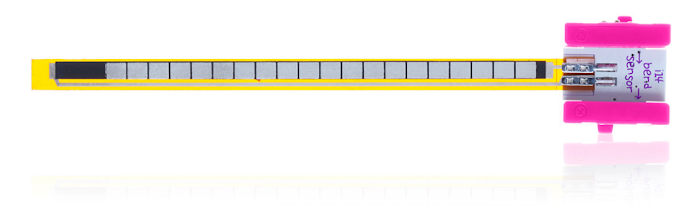
(写真提供:littleBits Electronics, Inc.)
この手袋センサーを手に着けて指を曲げると、その曲げの強さに応じて曲げセンサーから 0V から 5V の電圧が出力されます。その先に LED バーグラフ モジュールをつなげると、それぞれのセンサーがどの程度の圧力を検出しているか見られます。

曲げセンサーからは 0V - 5V の電圧が出力される

(写真提供:littleBits Electronics, Inc.)

これで、じゃんけんマシンの作成に必要なすべてのハードウェアが揃いました。つづいてはコーディングです。
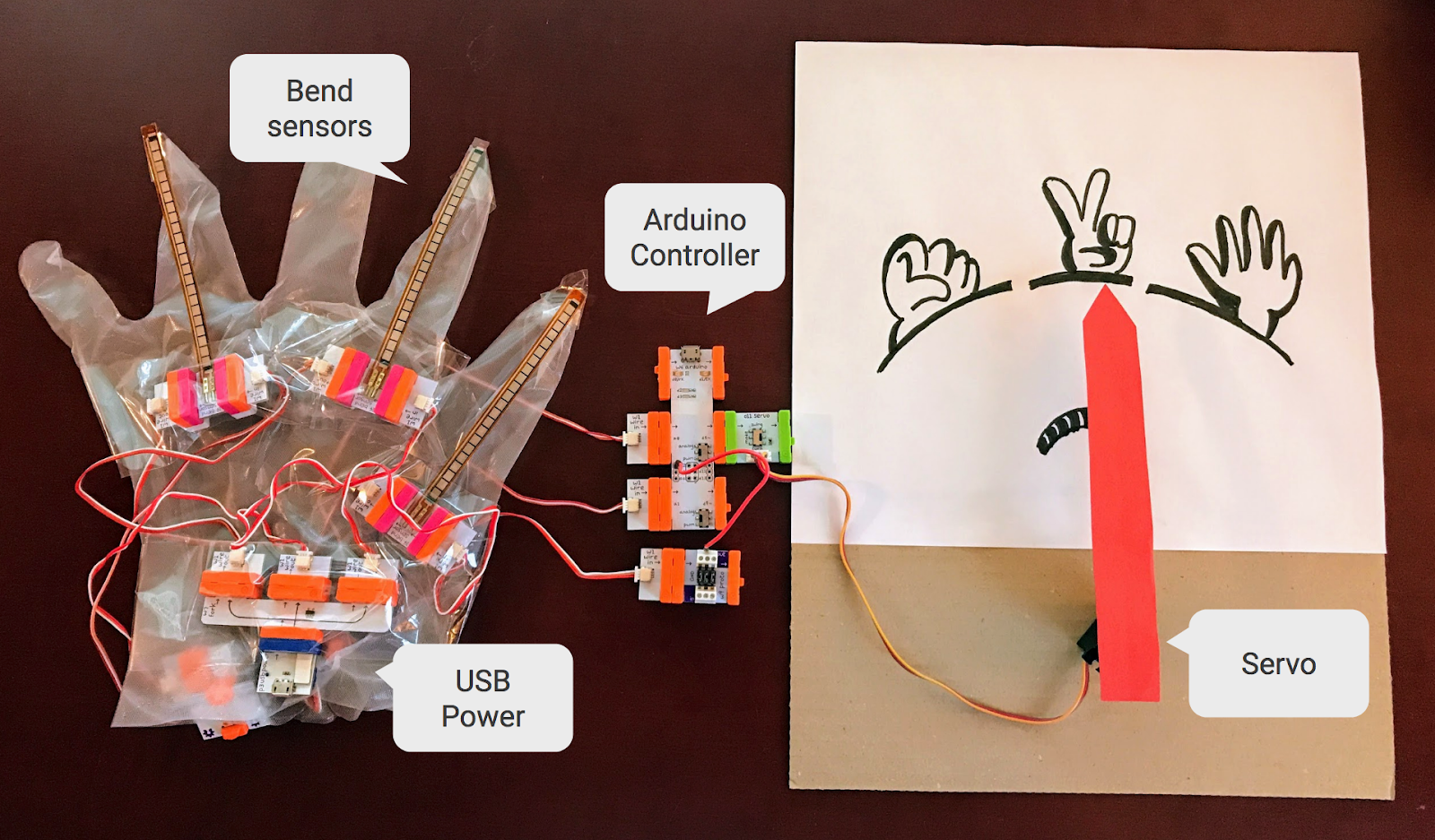
手順 3:曲げセンサーを読み取るコードを書く
まずは、曲げセンサーの出力を読み取るためのプログラムを Arduino モジュールで記述します。Arduino 開発ツールで以下のコードを書きます。このコードは、0.1 秒ごとに曲げセンサーの出力を読み取ってシリアル コンソールに表示します。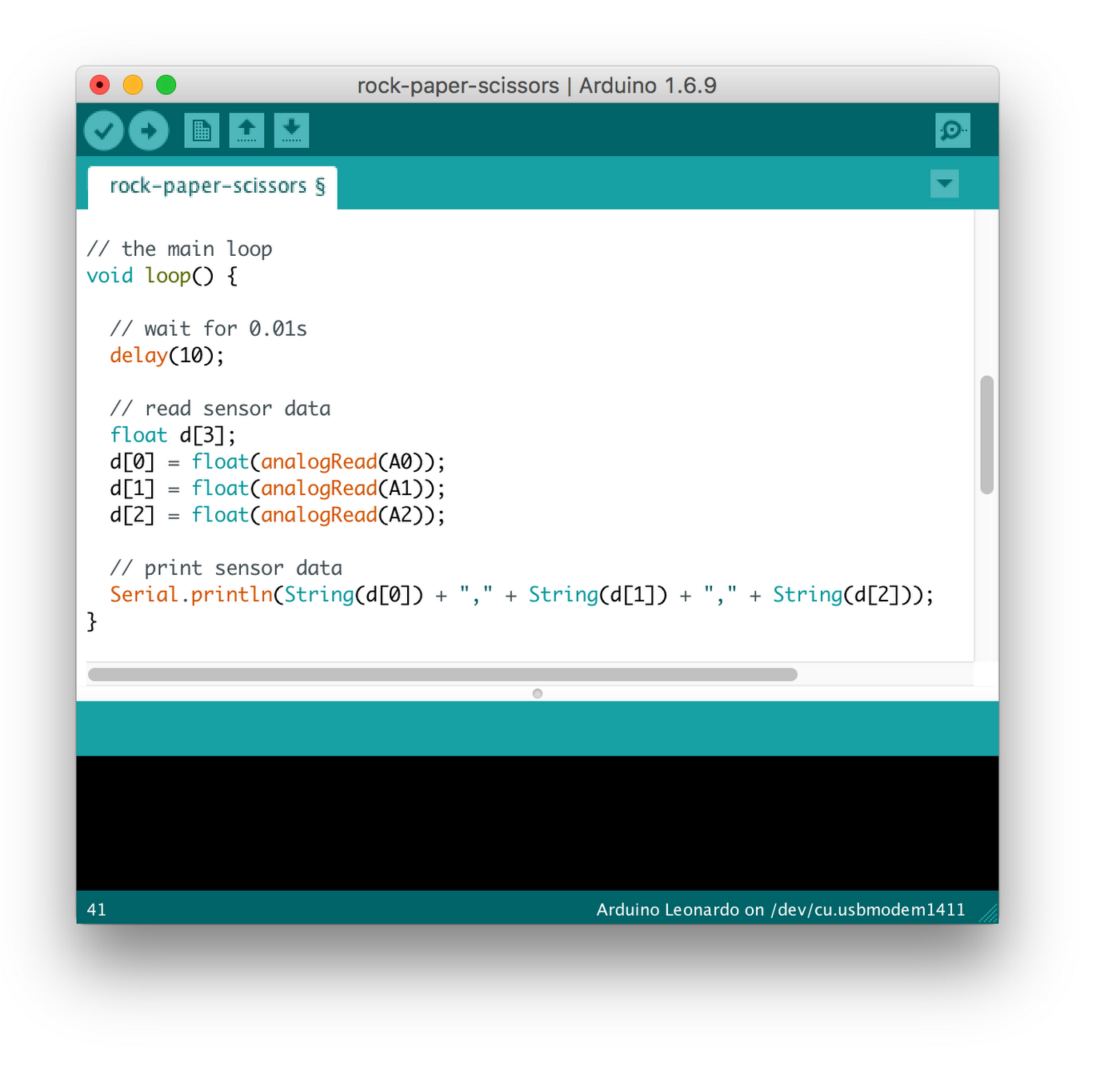
このコードを Arduino モジュールで動かすと、以下のような数字がコンソールに表示されます。
各行の 3 つの数字が、3 つの曲げセンサーからの出力値を表します。上の例は「グー」の形をしたときの数値です。Arduino モジュールは入力された電圧(0V - 5V)を 0〜1023 の数値に変換するので、すべてのセンサーが曲げられていることが分かります。一方、「パー」の形をすると、どのセンサーも曲がらないので、3 つの数値すべてがゼロに近い値になります。
手順 4:Cloud Datalab でデータを可視化する
では、これら 3 つの数値の組み合わせがグーチョキパーのどれを指すのか、どのようにして判定すればよいでしょうか。いちばん手っ取り早い方法は、しきい値を適当に決めて、以下のような条件文をいくつか書くことです。- もしすべての数値が 100 以下なら、たぶんパー
- もしすべての数値が 400 以上なら、たぶんグー
- それ以外なら、たぶんチョキ
とりいそぎ単体テストを通すだけならこれでも構いませんが、柔軟かつしっかりした設計とは言えません。もし息子が「センサーをもっと付けて 10 種類の手のジェスチャーを見分けよう」とか「全身タイツにたくさんのセンサーを貼り付けて体のいろんな姿勢を見分けよう」とか言い出したらどうなるでしょう。この書き方では、センサーの数がちょっと増えただけですぐに手に負えなくなります。私は面倒くさがりなプログラマーなので、気まぐれな顧客の思いつきのリクエストに対しても、基本設計を変えずに柔軟に、かつしっかり対応できるコードを書きたいのです。
そこで、もっとスマートな判定方法を見つけるため、手袋センサーの出力について簡単なデータ分析を行いました。ここで使ったツールが、ポピュラーなデータ分析ツール Jupyter Notebook を Google Cloud Platform に統合したサービス、Cloud Datalab です。これは言わば「まるごと全部入り」のクラウド ベースのデータ分析ツールで、ウェブ UI 上で書いた Python コードから NumPy や Scikit-learn、TensorFlow といった定番ツールをすぐに使えるほか、BigQuery や Cloud Dataflow、Cloud ML Engine などの強力な Google Cloud サービスも Python コードから簡単に呼び出せます。
まず、グーチョキパーそれぞれの形について、手袋センサーからのデータを読み取り、800 行ずつの 3 つの CSV ファイルに保存しました。これを Datalab で以下のような Python コード(コード全体はここにあります)を記述し、NumPy 配列に変換します。
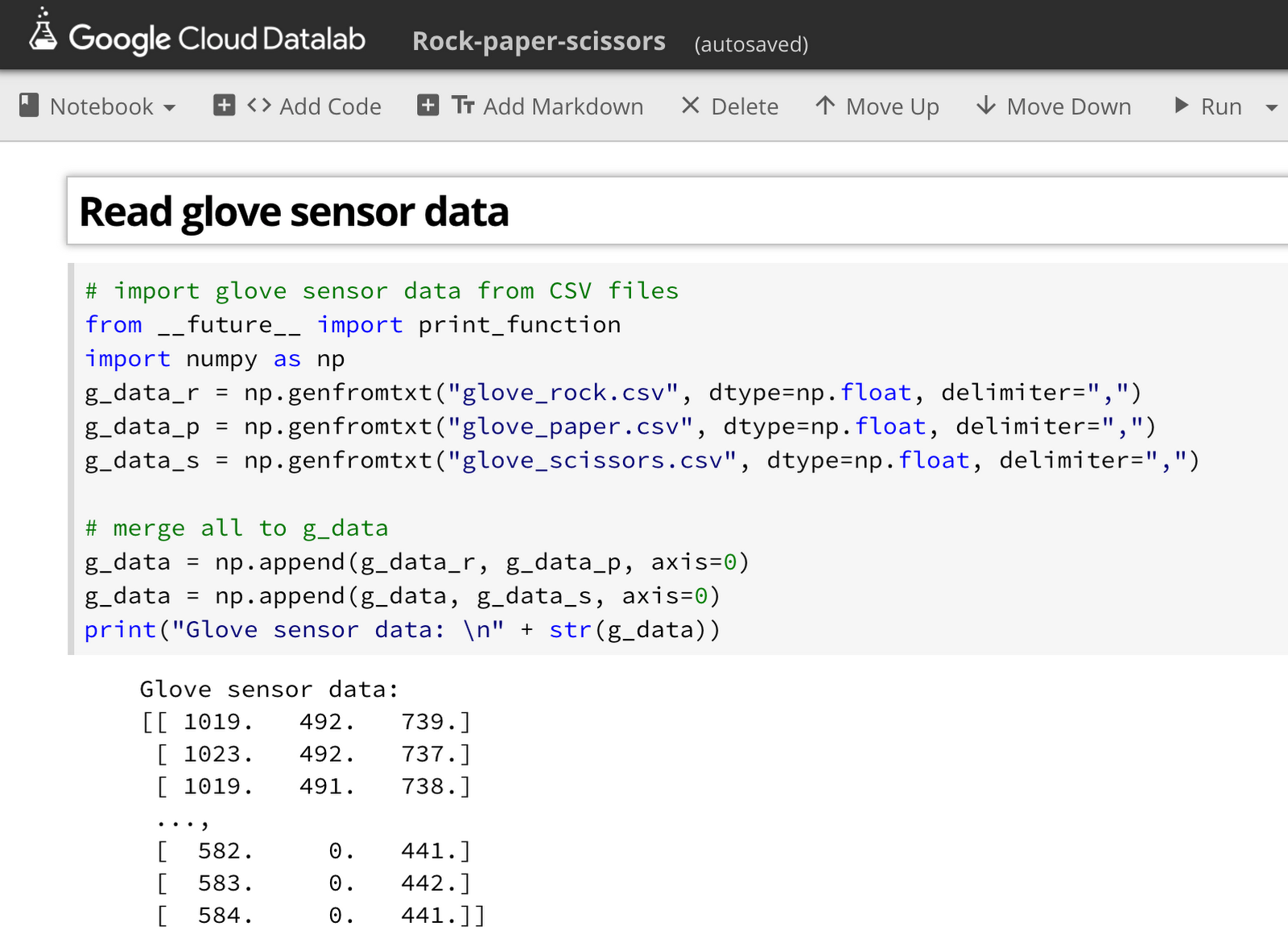
データを NumPy 配列にしておけば、可視化ツールの定番である Matplotlib で簡単に可視化できます。以下のコードで、各センサーの出力を各軸に割り当てた 3D グラフを描画できます。
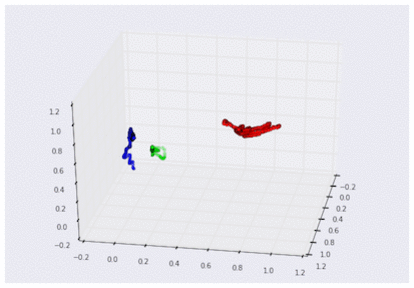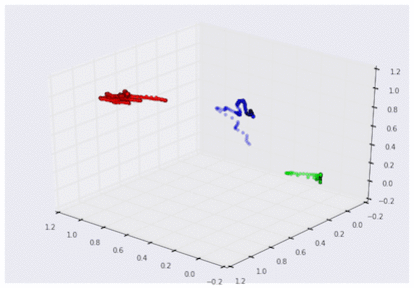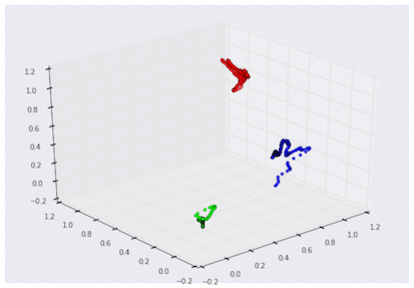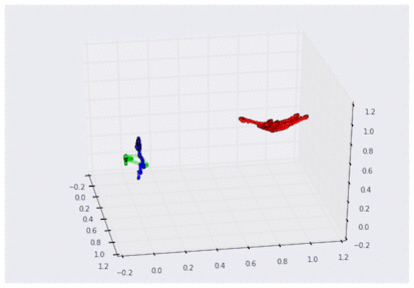
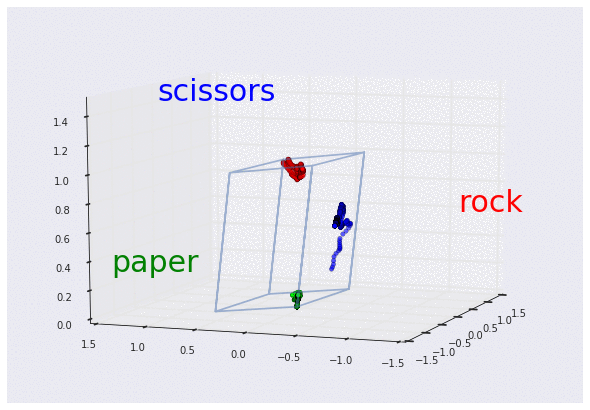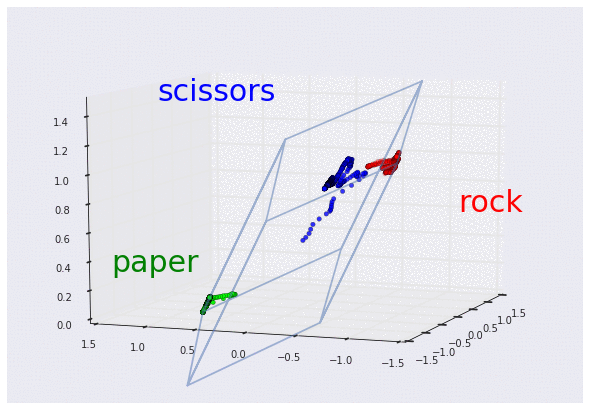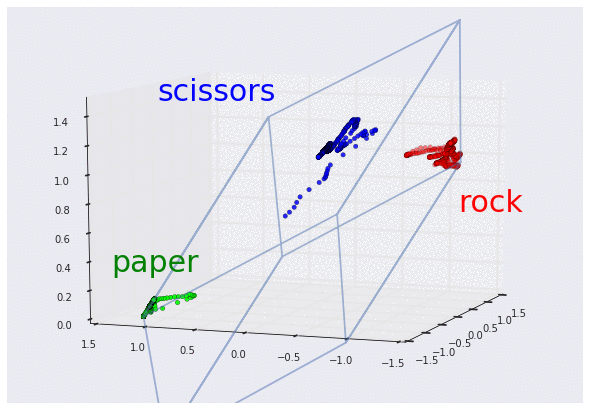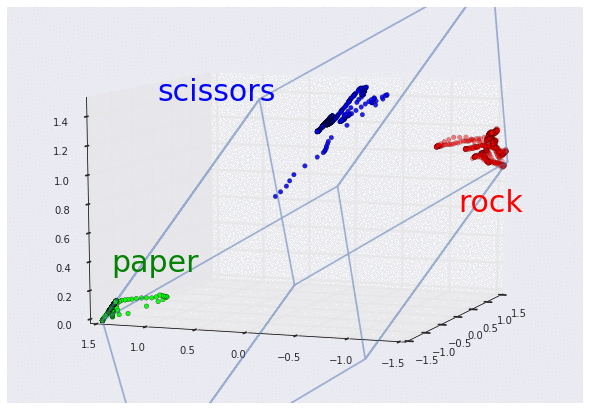
3D グラフで可視化した 3 つの曲げセンサーのデータ
(それぞれグー、チョキ、パーに対応。スケーリング済み)
この 3D グラフを見れば、センサーからのデータがどのような「形」をしているか、より明確に理解できます。
手順 5:線形モデルを作る
さて問題は、この生のセンサーデータをグーチョキパーに分類しやすい形にいかにして変換するか、です。そこで使うのが、皆さんが高校や大学で習った魔法のツール、「線形代数」です。線形代数は、ある「空間」から他の「空間」への変換を扱うための数学です。例えば、ある 1 次元空間から他の 1 次元空間への変換は以下の式で表せます。
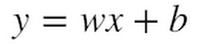
ここで、x と y はそれぞれの 1 次元空間の変数で、w は重み(weight)、そして b はバイアス(bias)と呼ばれます。この式を使えば、「ニューヨーク市のタクシーに乗った距離」の空間から「ニューヨーク市のタクシー料金」の空間への変換が可能です。重み w には 2.5 ドル(マイル単位の料金)、そしてバイアス b には 3.3 ドル(初乗り料金)をそれぞれ設定します。
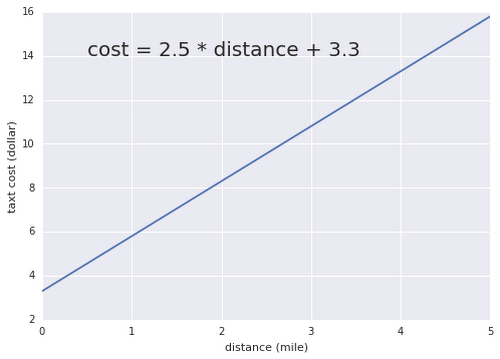
このグラフで分かるように、重みとバイアス(まとめてパラメータと呼ばれます)によって直線の傾きと位置が決まります。これらのパラメータを調整すれば、あらゆる 1 次元空間から他の 1 次元空間への変換を表現できます。
そして、ここからが線形代数の「美しい」ところです。この同じ式を使って、任意の m 次元空間から他の n 次元空間への変換を表せます。例えば以下の式は、ある 3 次元(3D)空間上の一点から他の 3D 空間への一点への変換を行います。
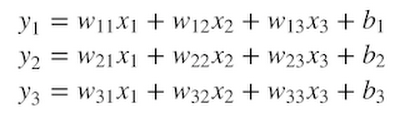
数学者たちは、このごちゃごちゃした式を毎回書く面倒を避けるため、「行列積」というもっと簡単な方法を発明しました。上記の変換は、行列積を使うと以下のように書けます。

もしくは、もっとシンプルに、こう書くこともできます。
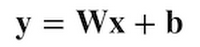
こうして手袋センサーからのデータをグー・チョキ・パーのそれぞれを軸に持つ空間へ変換できれば、後は以下のような条件式を使って簡単に分類できます。
- もしグー軸の値が他より高ければ、たぶんグー
- もしチョキ軸の値が他より高ければ、たぶんチョキ
- もしパー軸の値が他より高ければ、たぶんパー
とりわけ、入力データがたくさんの次元(種類)を含むケースでは線形モデルがさらに役立ちます。例えば全身スーツに 10 や 20 の曲げセンサーを取り付けた場合、線形モデルを使えば、いくつもの体の姿勢(立っている、座っている、しゃがんでいる等々)を各軸に持つ特徴空間への変換を行えます。ちょっとの環境変化ですぐに動かなくなるたくさんの条件式を生の入力データに対して書く必要はありません。また線形モデルは、画像や音声、自然言語、時系列データのように、数百や数千といった高次元のデータや非構造化データから望みの特徴を取り出すためにも使えます。
ただし、線形モデルは「銀の弾丸」ではありません。複雑な非構造化データや高次元データを高い精度で分類するには、ニューラルネットワークやサポートベクターマシンのような非線型モデルが必要になる場合もあります。これらのモデルでは、非線形変換を用いて入力データをより洗練された方法で加工できます。そこで、まずは計算が簡単な線形モデルから試してみて、もし十分な精度が得られない場合にはより複雑な非線形モデルを試す、といった使い分けができます。
手順 6:TensorFlow にパラメータを探させる
ここまでで、線形モデルの強力さは理解できたはずです。でも、肝心の変換のための重みやバイアスといったパラメータは、どのようにして決めればよいのでしょうか。その答えが機械学習です。機械学習を使えば、実際に観測された入力データを元に、線形モデルでベストな変換を行うためのパラメータを自動で探すことができます。例えば TensorFlow を使って以下のようなコードを書いて、線形モデルの「y = Wx + b」の式を計算グラフとして定義します。
このコードでは、tf.Variable を呼び出して 3 x 3 の重みの行例と 3 次元のバイアスのベクトルを作成し、ゼロで初期化する設定を行っています。また、tf.placeholder を呼び出し、手袋センサーデータを入力として受け取るためのプレースホルダー(入り口)を作成します。tf.matmul は、その手袋センサーデータと重みの間の行列積を定義します(glove_data を第一引数にする理由については記事の最後で解説します)。
これらのメソッド呼び出し(TensorFlow の低レベル APIと呼ばれます)は、この時点では計算を始めません。以下のような計算グラフを作成するだけです。
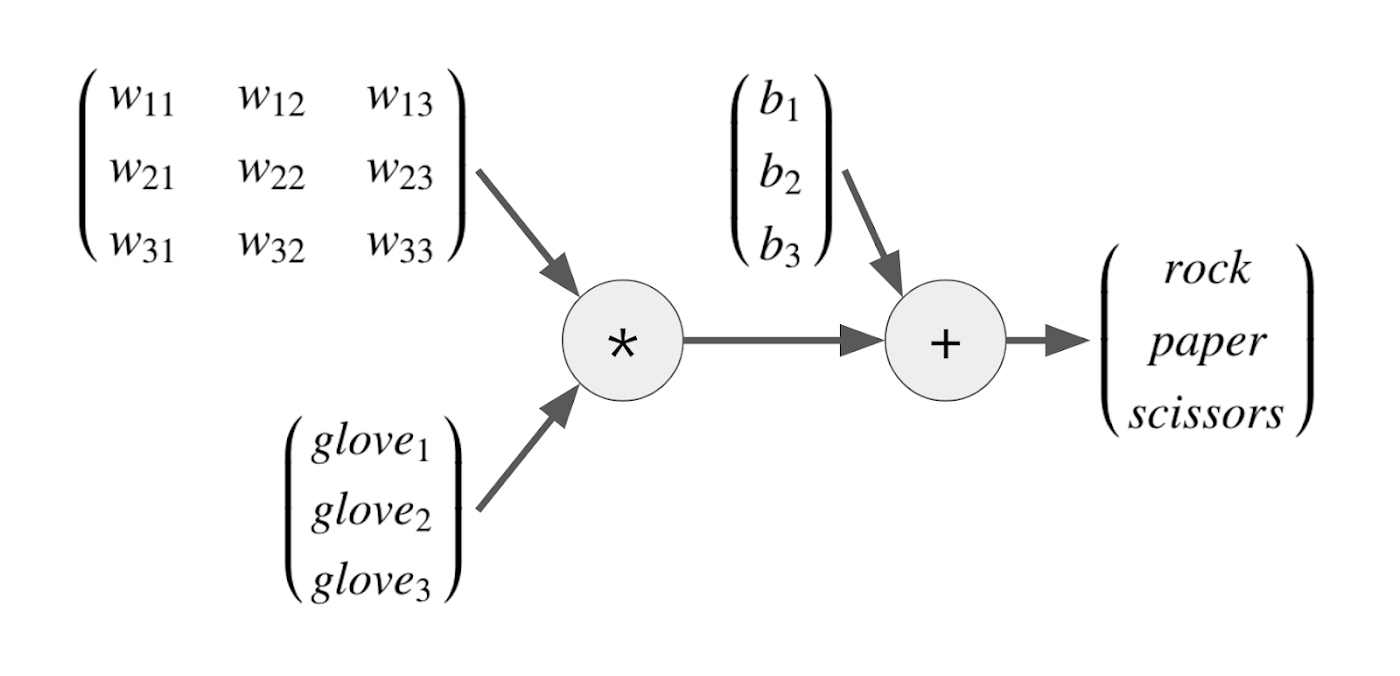
そして機械学習と TensorFlow のもっとも強力なところは、この計算グラフのパラメータ(重みとバイアス)を自動計算してくれることです。我々プログラマーは、手袋センサーデータ(glove1, 2, 3)と、その変換結果として欲しい値(rock、paper、scissors)を与えるだけです。すると TensorFlow は、計算グラフを「逆向き」に計算して、その変換を行うための最適なパラメータを探そうとします。この自動計算のことを機械学習では「モデルの学習」と呼びます。
つまり機械学習を使えば、プログラマーは入力データと出力データを与えるだけで、その中間にあるいちばん重要な変換手段をコンピュータで自動計算できます。これはつまり自動プログラミングのようなもので、日々のちょっとしたプログラミングでも手軽に使える便利なツールです。いわばエンジニアのための「21 世紀の電卓」が機械学習と言えます。
手順 7:学習の「コーチ」を定義する
さて、こうして定義した線形モデルの学習を行うには、「コーチ」を付けなくてはなりません。以下の 2 行が、モデルの学習を正しい方向に導くコーチとして働きます。ここで、rps_labels は手袋センサーデータの「ラベル」を受け取るためのプレースホルダーです。このラベルには、手袋センサーデータ(glove_data)の各行がグーチョキパーのいずれかを TensorFlow に教えるための以下のようなデータ(800 x 3 = 2400 行)を渡します。
ここで、[1 0 0] はグー、[0 1 0] はパー、[0 0 1] はチョキを表します。このようなラベルの書き方は「one-hot ラベル」と呼ばれ、機械学習ではよく使われる方法です。
コードの 2 行目では、tf.losses.softmax_cross_entropy を呼び出して損失関数を定義しています。この softmax(ソフトマックス)や cross entropy(クロスエントロピー)、損失関数とは何でしょうか? それぞれの Wikipedia ページは数式だらけで難解ですが、とりあえず以下のように理解しておけば OK です。
- ソフトマックスは rps_data の数値を 0.0〜1.0 の範囲にぎゅっと押しつぶします。すると、この値を「手袋センサーデータがグーチョキパーそれぞれを表す確率」として扱えます
- クロスエントロピーは「ソフトマックスで予測したグーチョキパー確率」と「rps_labels に入る one-hot ラベル(本当の答え)」の差を計算します
- 損失関数とは、機械学習のモデルが「どの程度のエラーを生じるか」を測る関数です。今回は上記のクロスエントロピーを損失関数として使います

クロスエントロピーは予測したグーチョキパー確率と本当の答えの差を計算する
(Martin Gorner「TensorFlow and deep learning, without a PhD」から引用)
ソフトマックスとクロスエントロピーを組み合わせて損失関数を定義することで、我々が作った線形モデルとそのパラメータによる変換が「本当の答えと比べてどの程度間違っているか」が分かります。この損失関数が「コーチ」として働くことで、TensorFlow は最適なパラメータを探すときの正しい方向を知ることができます。
ちなみに、線形モデルとソフトマックスを組み合わせる方法は「多項ロジスティック回帰」もしくは「ソフトマックス回帰」と呼ばれ、統計学や機械学習ではもっともポピュラーな手法のひとつです。
手順 8:線形モデルの学習
線形モデルを定義できたので、TensorFlow のオプティマイザー(学習器)を使って線形モデルの学習を行います。ここで使う tf.train.GradientDescentOptimizer は、TensorFlow に備わるオプティマイザーのひとつです。損失関数が返すエラーをなるべく小さくするにはパラメータをどのように調整すればいいか、勾配降下法を用いて計算してくれます。
オプティマイザーを使ってモデルの学習を行うには、TensorFlow の Session に備わる run メソッドを呼び出し、その引数としてオプティマイザーと学習データ(2400 個の手袋センサーデータとそのラベル)を渡します。このとき、オプティマイザーはパラメータの値をほんのちょっとしか動かしません(その幅は learning_rate 引数で指定しますが、大きくし過ぎると学習がうまく行きません)。よって、学習を進めるにはこの run メソッドを何千回と繰り返し呼び出す必要があります。このループの実行中、1000 回ごとに損失関数の値を表示してみると、以下のようにモデルのエラーが徐々に減っていく様子がわかります。
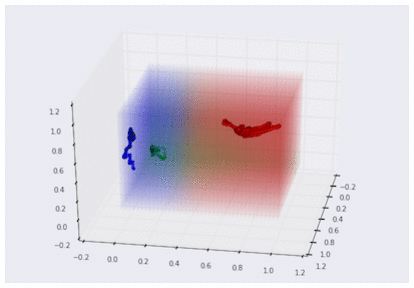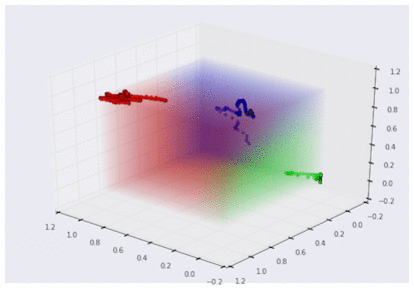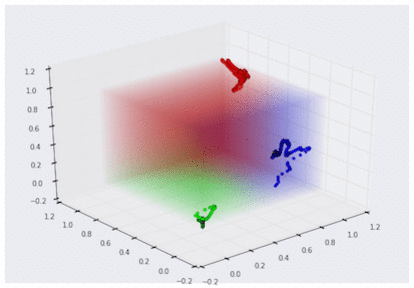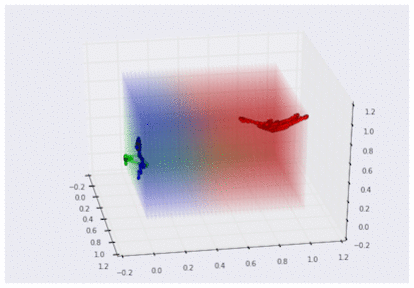
損失関数の値が十分に小さくなった時には、手袋センサーデータをグーチョキパー空間に変換するための最適なパラメータができあがっています。ソフトマックスが返すグーチョキパー確率を手袋センサー空間で色分け表示してみると、以下のような結果が得られます。
手順 9:Arduinoで線形モデルを使う
以上で、手袋センサーデータをグーチョキパーに分類するためのしっかりとした方法が用意できました。最後に Arduino のコーディングを仕上げましょう。モデルの学習を終えた Datalab 上で sess.run(weights) を実行すると、学習済みの重みの値が得られます。これをコピーして、Arduino のコードに以下のようにペーストします。バイアスについても同じことを行います。
これで、手袋センサーデータをグーチョキパー空間に変換する線形モデルが Arduino 上に用意できました。手袋センサーデータと重み、バイアス間の行列積と和を計算する以下のコードを書きます。
これらの計算結果のうち、一番大きな値がグーチョキパーの分類結果です(ソフトマックスを計算する必要はありません)。あとは、サーボモジュールを動かしてじゃんけんに勝つ手を指し示します。
機械学習によるじゃんけんマシンは以上で完成です。
まとめ
この記事で見てきたように、線形モデルは、任意の m 次元空間を他の n 次元空間に線形変換する強力なツールとして使えます。もし今後、生の入力データをたくさんの条件式で調べたりするケースに遭遇したら、ぜひこの方法を試してみてください。生データを直接扱うよりも、特徴空間(この記事の例ではグーチョキパー空間)に変換したデータを扱う方がぐっと簡単です。ここでキーとなる技術は、機械学習と TensorFlow です。これらを使えば、線形モデルの最適なパラメータを自動で探せます。最先端のディープラーニングや AI ではない毎日の普通のプログラミングでも、柔軟でしっかり動くコードを書くツールとして活用できます。
謝辞
この記事をレビューし貴重なフィードバックをいただいた中井悦司さん、そしてじゃんけんマシンのかっこいい盤面を書いてくれた息子に感謝します。補足:tf.matmul の使い方について
今回の例では、プレースホルダーを使って2400個の手袋センサーデータを一度に受け取ります。そのため、tf.matmul を呼び出す際には以下のように glove_data と weights を入れ替えたほうが、よりシンプルに書けます。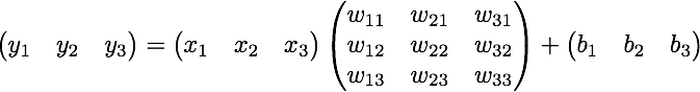
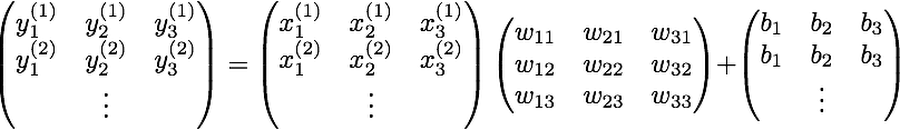
| 複雑に見えるかもしれませんが、この一行で意図した通りに動きますので心配はいりません。 |
1 : 厳密にはアフィン変換と呼ばれます


