Apache Hadoop を Dataproc に移行: 移行計画をサポートするディシジョン ツリー
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Hadoop エコシステムを使用していますか?既存のツールを使い続けながら、リソース管理を簡素化したいとお考えですか?「はい」とお答えになるなら、ぜひ Dataproc をお試しください。このブログ投稿では、Dataproc についての簡単な概要と、Apache Hadoop ワークフローを Google Cloud に移行するための 4 つのシナリオについてご説明します。
Dataproc とは
Dataproc は、オープンソースのデータツールを利用してバッチ処理、クエリ実行、ストリーミング、機械学習を行えるマネージド Apache Spark / Apache Hadoop サービスです。現在 Apache Hadoop エコシステムを使用しており、これを管理するためのより簡単なオプションをお探しであれば、Dataproc をおすすめします。Dataproc の自動化機能を利用すると、クラスタを速やかに作成し、簡単に管理して、必要ないときには無効にして費用を節約できます。管理にかかる時間と費用が削減されるので、最も重要なデータに集中できます。
Dataproc の主な機能
Dataproc はオンデマンドで Hadoop クラスタをインストールし、シンプルで迅速、かつ費用対効果に優れた方法で分析情報を取得します。従来のクラスタ管理作業を簡素化し、数秒でクラスタを作成します。Dataproc には、次の主要機能が含まれます。
30 以上の OSS ツールを含む、Hadoop と Spark エコシステムにおけるオープンソース ツールのサポート
必要に応じてスケールアップやスケールダウンができるカスタマイズ可能な仮想マシン
オンデマンドのエフェメラル クラスタによるコスト削減
他の Google Cloud の分析やセキュリティ サービスとの緊密な統合
Dataproc の仕組み
Hadoop / Spark ジョブを Dataproc に移行するには、データを Google Cloud Storage にコピーし、ファイルパスを HDFS から GS に更新するだけです。
詳細については、次の動画をご覧ください。

Dataproc はストレージとコンピューティングを分離します。たとえば、分析対象のログが外部アプリケーションから送信され、これをデータソースに保存するとします。Cloud Storage のデータは Dataproc により処理され、その後再び Cloud Storage や BigQuery、Bigtable に保存されます。また、そのデータをノートブックでの分析に使用して、ログを Cloud Monitoring や Cloud Logging に送信することもできます。
ストレージが分離されているため、長期運用クラスタでは、ジョブごとに 1 つのクラスタを使用できます。コスト削減にあたり、ラベルでグループ化され選択されたエフェメラル クラスタを使用することも可能です。もちろん、アプリケーションのニーズに合わせて適切な量のメモリ、CPU、ディスクを使用することでもコストを削減できます。
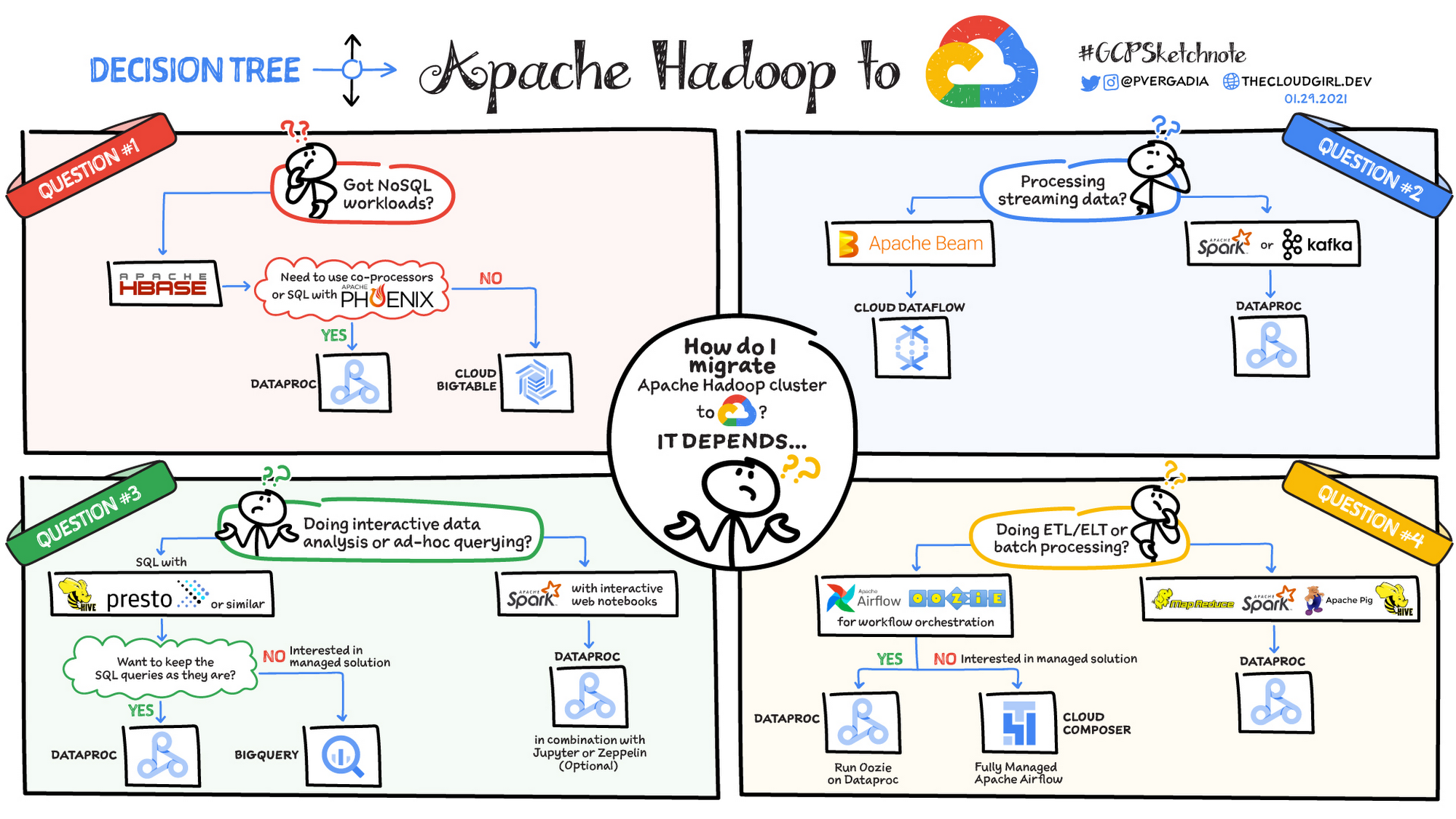
考慮すべき移行シナリオ
ここで、Hadoop クラスタを Dataproc に移行する際の方法を決めるのに役立つ 4 つの一般的なシナリオについてご紹介します。
NoSQL ワークロードを移行しようとしていますか?
ストリーミング データを処理していますか?
インタラクティブなデータ分析またはアドホック クエリを行っていますか?
ETL またはバッチ処理を行っていますか?
質問 1: NoSQL ワークロードはありますか?
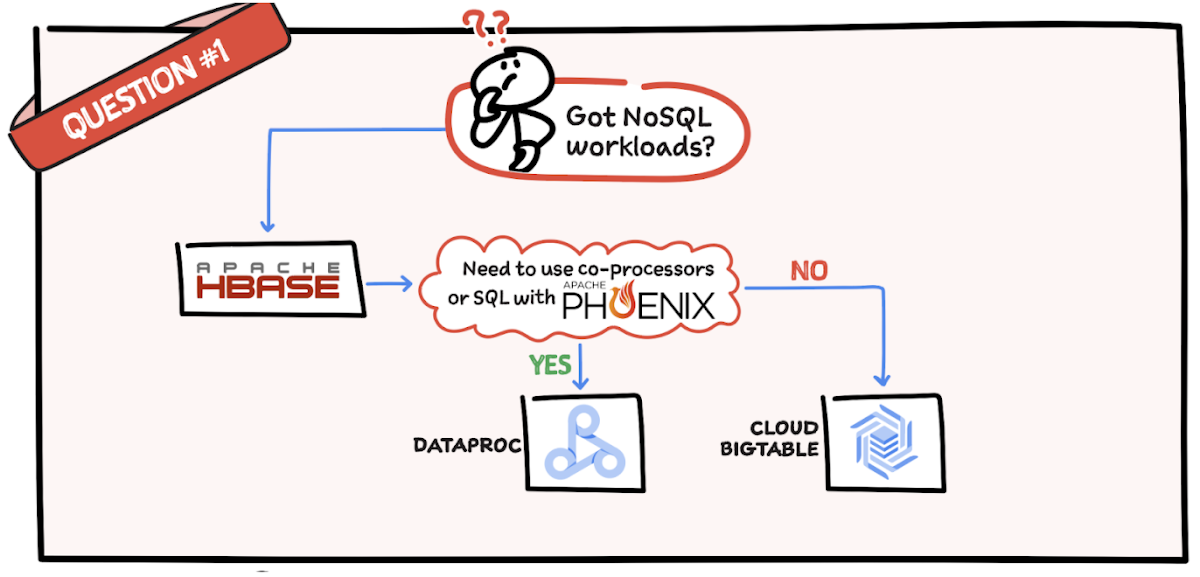
HBase を使用している場合、Phoenix で共同プロセッサもしくは SQL を使用する必要があるかどうかを確認します。これらが必要な場合は、Dataproc は最適な選択肢です。共同プロセッサや SQL が必要でない場合は、Bigtable が適しています。
質問 2: ストリーミング データを処理していますか?
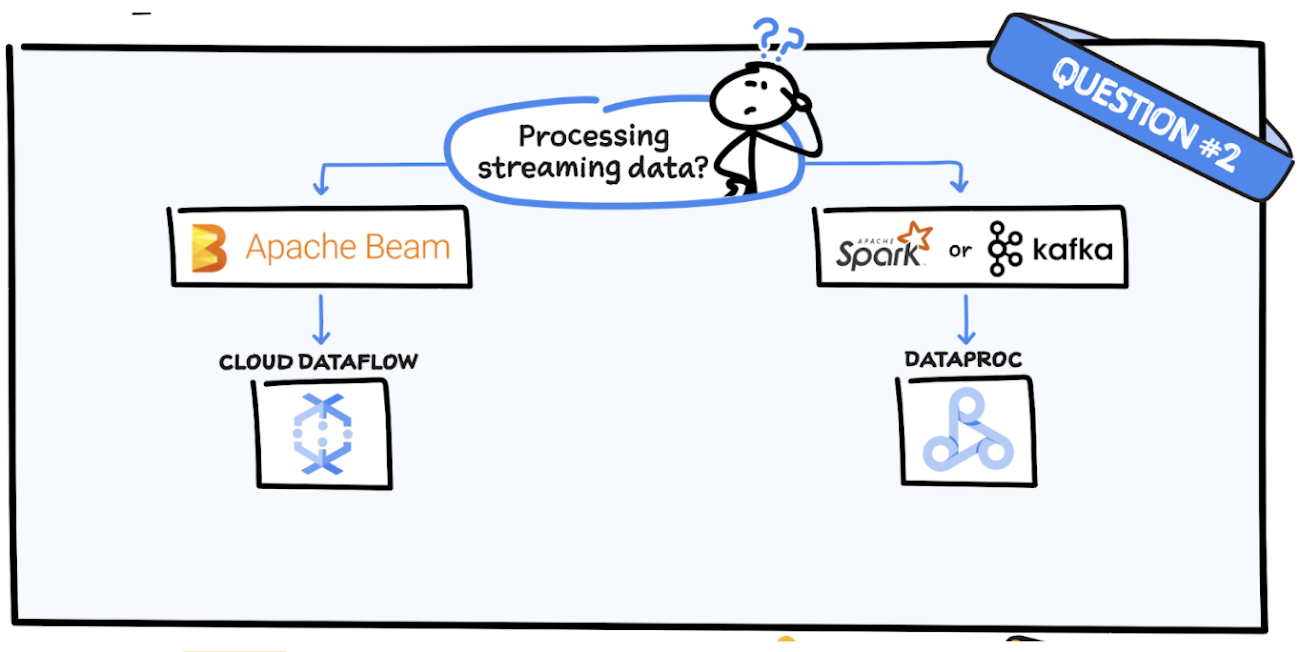
Apache Beam を使用している場合、Dataflow を使用するのが合理的といえます。なぜなら、Beam SDK に基づいているからです。Spark あるいは Kafka を使用している場合は、Dataproc が適しています。
質問 3: インタラクティブなデータ分析またはアドホック クエリを行っていますか?
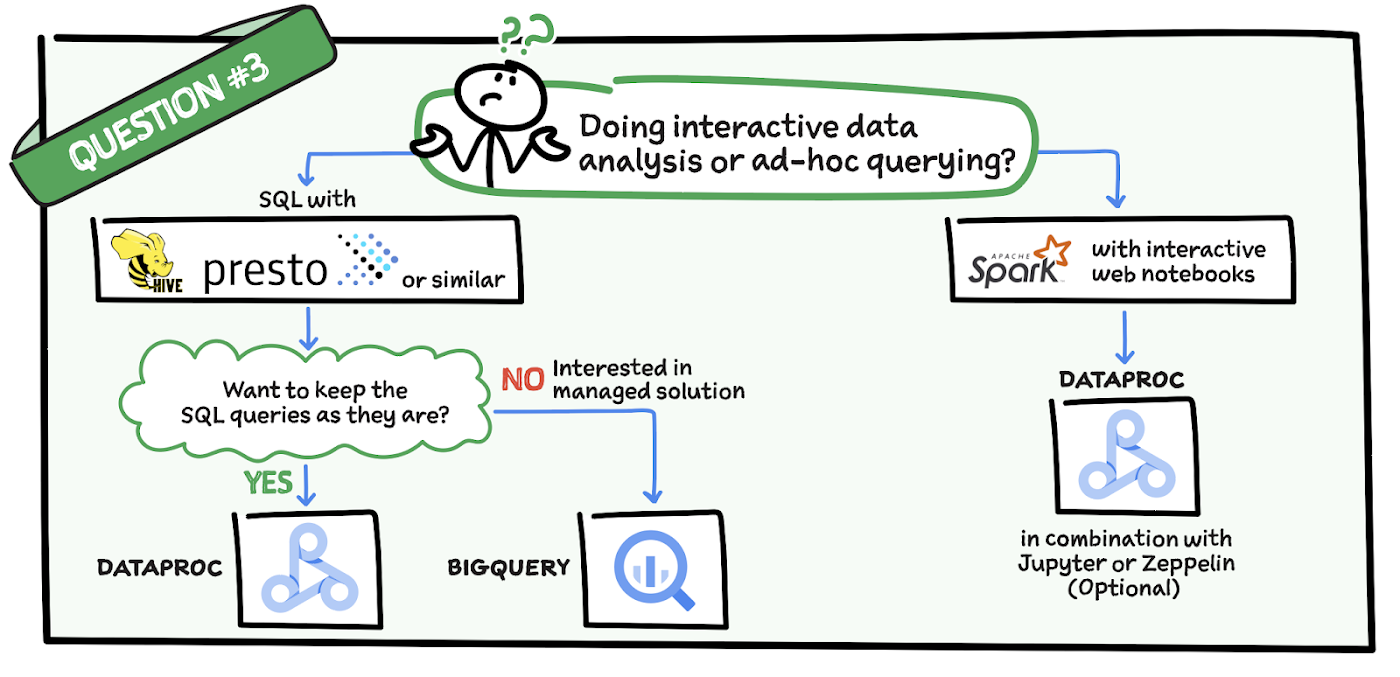
インタラクティブなノートブックを使用して Spark でインタラクティブなデータ分析を行っている場合、Dataproc は Jupyter Notebook や Zeppelin との組み合わせに最適です。なお、Hive や Presto で SQL を使用してデータ分析を行っていて、その方法を維持する場合にも Dataproc は適しています。ただし、インタラクティブなデータ分析に向けたマネージド ソリューションに関心がある場合は、BigQuery を検討されることをおすすめします。BigQuery は、フルマネージドのデータ分析に対応したデータ ウェアハウジング ソリューションです。
質問 4: ETL またはバッチ処理を行っていますか?
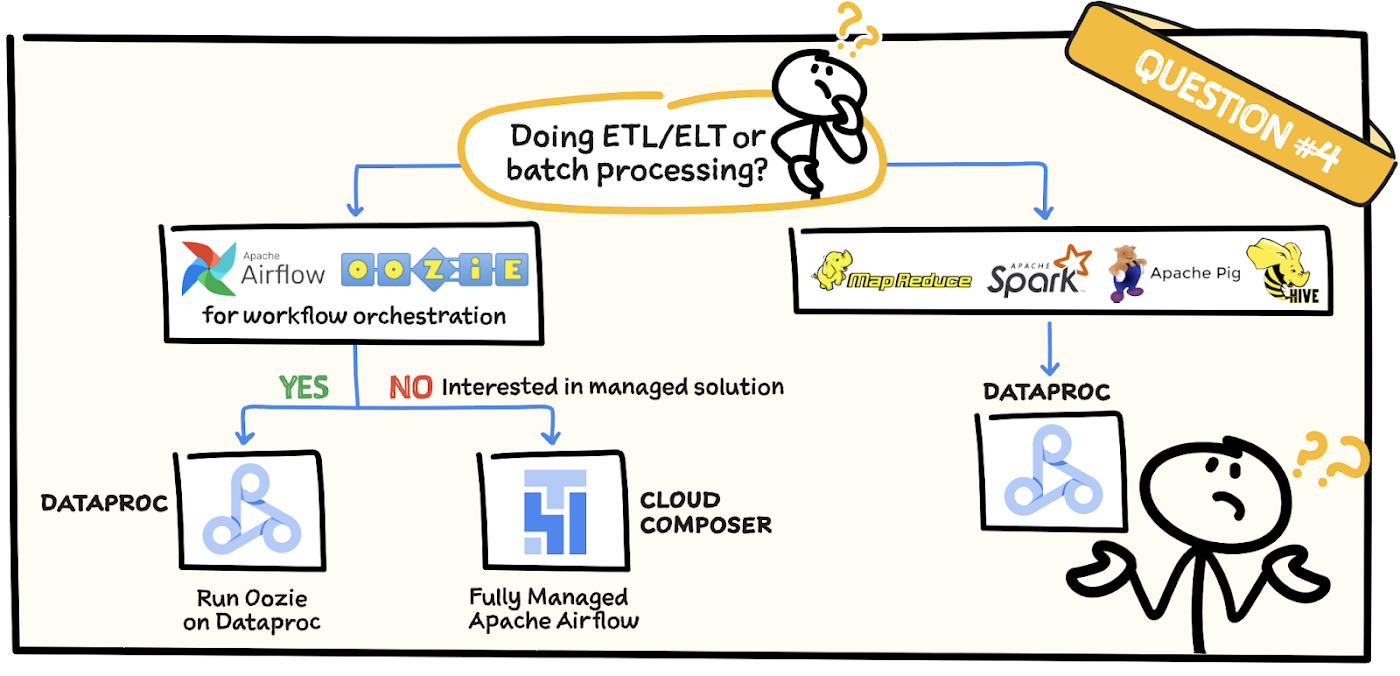
MapReduce、Pig、Spark、Hive を使用して ETL やバッチ処理を実行している場合は、Dataproc を使用します。また、Apache Airflow や Oozie のようなワークフロー オーケストレーション ツールを使用していて、ジョブをそのまま維持する場合にも Dataproc が最適です。ただし、マネージド ソリューションを使用する場合は、Apache Airflow により管理される Cloud Composer をご確認ください。
まとめ
Apache Hadoop クラスタを Google Cloud に移行する計画を立てる際に役立つ、4 つのさまざまなシナリオについてご紹介しました。
詳細については、Dataproc プロダクトのページをご覧ください。
#GCPSketchnote や同様の Cloud コンテンツの詳細については、Twitter や Instagram で @pvergadia をフォローしてください。thecloudgirl.dev もぜひご覧ください。
-Google デベロッパー アドボケイト Priyanka Vergadia


