Cloud Spanner : ミッションクリティカルな業務に対応するグローバルなデータベース サービス
Google Cloud Japan Team
グローバルな分散リレーショナル データベース サービス Cloud Spanner をパブリック ベータとしてリリースしました。ACID トランザクションや SQL が利用できるにも関わらず、水平スケーリングと高可用性を実現しています。
これまでクラウド アプリケーションを構築するとき、トランザクションの一貫性を保証するリレーショナル データベースと、シンプルながら水平スケーリングとデータ分散が可能な NoSQL データベースのどちらかを選択する必要がありました。Cloud Spanner は、この選択の必要をなくし、1 つのフルマネージド サービスとして両方の主要な機能を提供します。
Cloud Spanner は、我々の顧客である世界中の小売業、製造業、卸売業にとてつもなく大きな価値をもたらすでしょう。簡単なプロビジョニングとスケーラビリティ、それが世界中のユーザーにクラウド ベースのオムニチャネル サプライチェーン ソリューションを提供する我々のビジネスを後押しします。
John Sarvari, Group Vice President of Technology, JDA
小売業向けソリューションやサプライチェーン ソフトウェアのリーディング プロバイダである JDA は、2015 年から、新しいアプリケーションの開発とデリバリの基盤に Google Cloud Platform(GCP)を利用しています。Cloud Spanner の初期ユーザーでもあり、データを扱うときに必要な一貫性と高可用性を実現しながら、今後 IoT などの新しい情報ソースから送られてくる爆発的な量のデータを処理できるポテンシャルがあると見ています。
Cloud Spanner は、Cloud SQL、Cloud Datastore、Cloud Bigtable と並び、 GCPのデータベース サービスのポートフォリオをより完全なものにします。
マネージド サービスであることで、Cloud Spanner はデータベース管理者に次のようなメリットを提供します。
- ハードウェアとソフトウェアの管理に費やしてきた時間を、アプリケーションのロジックに充てることができる
- シャーディングやクラスタリングをすることなく RDBMS ソリューションをスケールアウトできる
- リレーショナル データベースから NoSQL データベースへ移行せずに水平スケーリングを実現できる
- レプリケーションやフェイルオーバーのためにインフラストラクチャーを計画する必要もなく、高可用性は維持され、災害からも保護される
- データ レイヤの暗号化、ID とアクセス管理、監査ロギングから、統合的なセキュリティを得られる
Cloud Spanner を使ったアプリケーション開発は、使い慣れたリレーショナル データベース環境の標準ツールと言語が使えることから、余計に複雑になることはありません。そのため在庫管理、金融取引、制御システムなどで、そのシステムが対応できなくなるほど肥大化しているリレーショナル データベースで行われている処理に利用することにも適しています。Cloud Spanner は、分散トランザクション、スキーマ、DDL 文、SQL クエリ、JDBC ドライバに対応し、Java、Go、Python、Node.js 等のクライアント ライブラリも用意しています。
他の Cloud Spanner ユーザーからのフィードバック
オンライン学習ツールの Quizlet は、毎月 2,000 万人以上の生徒と教師をサポートしています。メインのデータベースには MySQL が使われ、ビジネスとしてもそのパフォーマンスと安定性が重大な課題であるなか、毎年 50% ずつユーザー数が増える状況で、その負荷に対応するためにデータベースを何倍にもスケールさせることを強いられました。そこで、テーブルを他のデータベースに分割し(垂直シャーディング)、クエリの負荷はレプリカに移し、クエリの能力を増強させてきました。しかし、このテクニックはすぐに限界に達します。MySQL の 1 つのシャードがサポートできる規模をテーブルが超えてしまったのです。そこで Quizlet は他のスケーラブルなアーキテクチャを探し、その中で Cloud Spanner を、簡単にリレーショナル データベースをスケーリングでき、アプリケーションもシンプルにできるソリューションとして見出しました。
これまでの経験とパフォーマンス テストから、大規模なリレーショナル データベースへのクエリ負荷に対応できる最も魅力的な選択肢は Cloud Spanner です。NoSQL データベースと同様のパフォーマンスとスケーラビリティがありながら、SQL が使える。これは現実的にシャーディングした MySQL の代わりになり得ます。本当に素晴らしいテクノロジーで、データベース管理するということが劇的なまでにシンプルになるでしょう。
Peter Bakkum, Platform Lead, Quizlet
Cloud Spanner の歴史
これまで長い間、リレーショナル データ モデルと SQL を備えたデータベースに依存して、業務上の要件を満たすアプリケーションが構築されてきました。その間にスケールや速度、効率的なデータ処理という面で勝る NoSQL ソリューションが現れましたが、ストロング コンシステンシーが要求される状況には対応できません。今でも 2 つの最適とは言えない手段からの選択がお客様を悩ませていますが、 2007 年、Google のシステム リサーチャーとエンジニアのチームは、このギャップを埋めるグローバルな分散データベースの開発を始めます。2012 年には Spanner のリサーチ ペーパーを発表し、Spanner に含まれる多くのイノベーションについて説明しました。そして、次の表のように両方の優れた機能を持つデータベースに至ります。
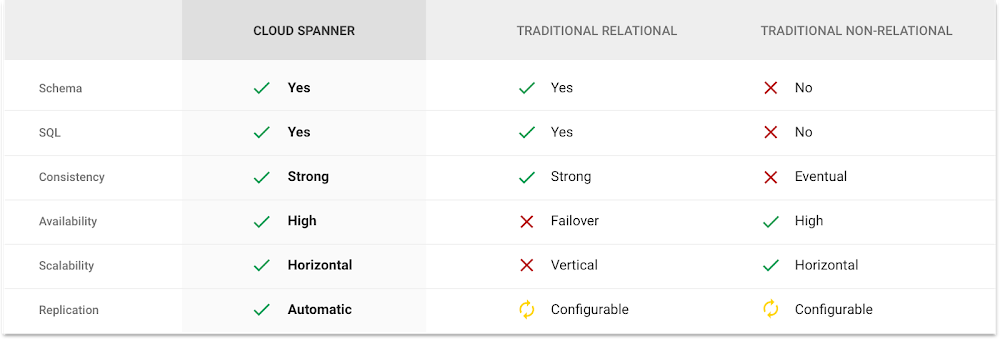
注目してほしいのは、このような機能の組み合わせを CAP 定理に違反することなく実現したことです。その方法は、CAP 定理を提案した Eric Brewer(Google の Vice President of Infrastructure)が投稿した記事で説明しています。
Cloud Spanner のテストは内部で数年にわたり行われ、より実際的なテストになるように数百種類のアプリケーションと世界中のデータセンターのペタ バイトにもなるデータが使われました。Spanner は秒間数千万ものクエリに対応し、Google では AdWords や Google Play といった私たちにとって重要なサービスの一部を動かしています。
データで膨れ上がった MySQL や PostgreSQL を使っていたり、イベンチュアル コンシステンシーのデータベースで自前のトランザクション処理をしようと苦労しているなら、Cloud Spanner は探し求めていたソリューションになるかもしれません。Cloud Spanner のページでより多くのことを調べたら、次世代データベース サービスを使ったアプリケーションの開発に着手しましょう。
* この投稿は米国時間 2 月 14 日、Cloud Spanner の Product Manager である Deepti Srivastava によって投稿されたもの(投稿はこちら)の抄訳です。
- By Deepti Srivastava, Product Manager for Cloud Spanner


