Cloud Spanner を使ってメール パーソナライズ システムを再構築したリクルートテクノロジーズ
Google Cloud Japan Team
* この投稿は米国時間 3 月 27 日、株式会社リクルートテクノロジーズ の データAI戦略統括部で エンジニア を務める 松﨑 遥 氏と、Google の Cloud Customer Engineer である 寳野 雄太 によって投稿されたもの(投稿はこちら)の抄訳です。
編集部注 : 今回は、東京に本拠を置くリクルートテクノロジーズの投稿をお届けします。電子メール マーケティング プラットフォームを GCP 上に構築している同社は、最近そのデータベースを Cloud Spanner に移行しました。コスト削減や運用要件への対応に加え、従来の HBase ベースのデータベース システムよりも高い可用性が得られることが目的です。また、Cloud Spanner を使用することで、データをあらかじめ転送することなく、リアルタイムに指標(KPI)を算出することを可能にしました。この投稿を読めば、同社のワークロードがどのようなものか、Cloud Spanner がいかに同社の狙いに合致しているかがおわかりいただけるでしょう。
私たちリクルートテクノロジーズは、電子メール マーケティング システムの開発とメンテナンスを行っています。世界の人口が 80 億人弱と言われている中、このシステムは、数百に及ぶリクルートのウェブ サービスを利用している数千万人の最終顧客に対してパーソナライズされた電子メールを配信するというもので、最高かつ最適な顧客体験の提供を目指しています。
リクルートは 1960 年に創業し、当初は新卒者の採用や就職の支援に特化していましたが、長年の事業展開を経て、人生や生活のさまざまなシーンやイベントに関わるプロバイダーを支援するようになりました。旅行プラン、不動産、レストラン、美容院、ヘアサロンなど多種多様な分野のプロバイダーと協力し、商品やサービスを通じて最終顧客とつながるためのお手伝いをするソフトウェアやサービスを提供しています。
リクルートは電子メールを、最終顧客向けの主要なマーケティング ツールの 1 つと位置づけ、クライアント企業や広告主と最終顧客とのコミュニケーション チャネルとして幅広く運用しています。最終顧客に配信する電子メールは、その効果を最大限に高めるため、個々にカスタマイズします。
このビジネス目標に向けて、私たちはプロプライエタリ システムである “Soup” を開発し、Google Cloud Platform(GCP)にホストしています。Soup は、このシステムに不可欠となる複雑なカスタマイズ データを、Google Cloud Spanner を利用して管理する “結合組織” です。
もちろん、アイデアを実際に機能するプロダクトとして実現するのは “言うは易く行うは難し” です。私たちは膨大なデータセットを使用していますので、高い可用性やリアルタイムのデータ提供といった要件への対応は特に厄介です。しかも、既存の複雑なオンプレミス環境の一部は、クラウドへの移行過程においても維持しなければならず、そのために私たちはハイブリッド環境を運用することとなり、プロジェクトの遂行は一段と困難なものになりました。
Soup の基本
まず、なぜ “Soup”(スープ)という名前なのでしょうか? このアプリケーションの名前は、実は日本語では “出し分け” と言います。これは、スープの一種である “だし” にちなんだものなのです。
理論上は、Soup はかなりシンプルなアプリケーションです。その API は、ユーザーのユーザー ID を使って計算したユーザー データをベースとするリコメンデーション結果を返します。Soup は、前もって計算されたリコメンデーションを取り込み、電子メール生成エンジンに提供し、指標をトラックします。また、顧客向け電子メールの送信は行わず、数千万人に上るユーザー向けのパーソナライズやカスタマイズに使用する大量のデータ全体を管理します。さらに、こうして送信される電子メールの開封、リンクのクリックなどのメタデータに関連する、算出された指標も管理します。
Soup は Cloud Spanner に加えて、App Engine フレキシブル環境(Node.js)、BigQuery、Data Studio、Stackdriver といった GCP サービスも利用します。
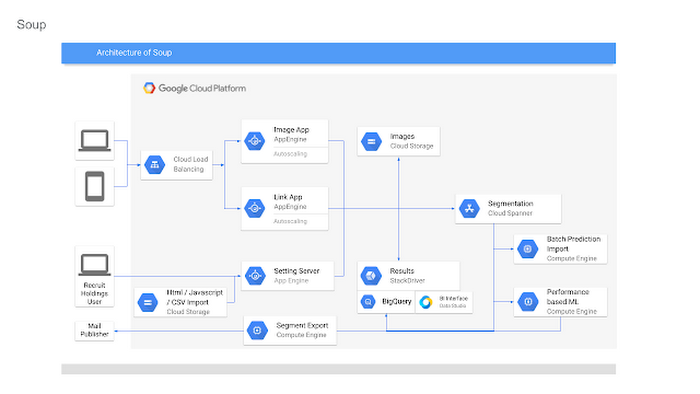
Soup の要件
高い可用性
ユーザーが電子メールを開こうとするときにシステムが利用できないとなると、ユーザーはコンテンツが何もない空白の画面を見る羽目になります。そうなれば、その電子メールに関わる売上げが失われるだけでなく、ユーザーがそれ以降、私たちからの電子メールを開く可能性も小さくなってしまいます。
低いレイテンシ
ユーザー ID を与えられたら、システムは予測に使うすべてのデータを調べ、適切なコンテンツ(HTML ファイル、1 つの画像、複数の画像、他のコンテンツ)を生成し、提供する必要があります。これらすべてをきわめて高速に行わなければなりません。
リアルタイムのログ取り込みと高速な JOIN
今日のマーケティング環境では、ユーザー行動を追跡することと、それに基づく動的リコメンデーションができることは必須です。しかも、私たちの世界はリアルタイム化が進んでいます。これまでは、コンテンツをお客様の行動に適応させるのに 1 週間以上かかっても問題なかったかもしれません。それが今では、1 日の遅れですらコンバージョンと機会損失の分かれ目になりえます。
課題
数十億通のパーソナライズされた電子メールを数千万人のお客様に配信するには、固有の課題に対処しなければなりません。私たちの従来のオンプレミス システムは、オープンソースの NoSQL データベースである Apache HBase と、同じくオープンソースのデータ ウェアハウス ソフトウェアである Apache Hive をベースにしていました。この環境には次に示す 3 つの大きな難点がありました。
クラスタのサイジング
電子メール マーケティングは集中的に発生するワークロードです。通常、大量の電子メールを一斉に配信し、それに伴って大量の計算処理が必要になり、それが完了すると静かな時間がしばらく続きます。私たちの電子メール ワークロードでは、大量のリコメンデーションを前もって計算し、電子メールが開かれると動的に提供します。
ところが、オンプレミスではあまり柔軟性がなく、クラスタのサイズ変更を手動で行わなければなりませんでした。電子メールが開かれ、それに伴うシステムへのリクエストが、処理可能なトラフィックを上回ると、いつもエラーに悩まされました。HBase / Hive システムのクラスタ サイズがリクエストの増大に追いつかなかったからです。
パフォーマンス
2 番目の問題はスキーマ モデルのパフォーマンス最適化でした。Soup にはいくつかのメイン関数があります。お客様の追跡データを Soup に書き込むサービスがあり、下流の “customers” がそのデータを読み取り、パーソナライズされた電子メールを作成します。
書き込み側では、データが Soup に書き込まれたら、書き込まれたデータを集約する必要があります。私たちは当初、オンプレミスでこれを行っていましたが、非常に面倒で時間がかかっていました。HBase では集約クエリが用意されていないうえに、トラフィックの集中に対応したスケーリングも困難だったからです。
転送の遅延
さらに、データ転送に要する時間も問題でした。パーソナライズされた電子メールを大量に配信するにあたってリコメンデーション モデルを生成するのですが、生成の必要が生じるたびに、HBase から Hive に必要なデータを転送してモデルを作成し、データを HBase に戻さなければなりませんでした。この複雑なデータ転送に 2 ~ 3 日を要しており、これでは、お客様に最高のサービスを提供するために必要となるアジリティは確保できません。
Cloud Spanner を使えば、すべてのデータを 1 か所に保存でき、簡単にデータ テーブルを結合して集約を行えるので、時間のかかるデータ転送は不要です。このモデルにより、リコメンデーションの生成時間を従来の数日から 1 分未満に短縮し、リアルタイム化を実現できると考えています。
なぜ Cloud Spanner なのか
オンプレミスで運用してきた従来のアプリケーションと比べて、Cloud Spanner はコストや運用要件が低く、高い可用性も提供します。そして最も重要なことは、データを転送せずにリアルタイムで指標(KPI)を計算できることでした。Cloud Spanner では、KPI をリアルタイムでモニタリングするカスタム ダッシュボードに SQL クエリを送ることで、それが可能になります。
Soup は GCP で実行されるようになりましたが、リコメンデーション自体はまだオンプレミス Hadoop クラスタで生成されています。計算されたリコメンデーションは、上述の理由から Cloud Spanner に保存されます。GCP に移行してクラウド向けの設計としたことで、エラー率は以前の毎秒 4 % から毎秒 0.005 % へと 800 分の 1 に低下しました。これは、電子メールを日本のすべてのユーザーに一斉に配信したときに、「1 人のユーザーが 1 通の電子メールで 1 つの画像を見ることができない」ことを意味します。こうした電子メールは 10 点以上の画像を含むことが多いので、このエラー率は許容範囲です。
また、Cloud Spanner はスケーリングの問題も解決してくれました。Soup は今後、さまざまな地域に散在した 100 万同時ユーザーをサポートしなければならなくなります。同様に、Soup はピーク時に読み込み側で 5,000 クエリ / 秒(QPS)を実行する必要があり、近いうちにこの要件は 2 万~ 3 万 QPS に高まります。Cloud Spanner は、Soup が実行しなければならない各種の複雑なトランザクションをすべて処理できるうえに、水平方向のスケーリングが容易に可能です。
得られた教訓
抱えるユーザーの数が 10 人か 1,000 万人かに関係なく、私たちはデータベースを Cloud Spanner に移行する過程で、参考になるヒントをたくさん得ました。
スケーリングに備える
私たちは最初からスケーリングを考慮し、スピードや高可用性などの指標を使って具体的な要件の概要をまとめました。このように要件を明確にしておけば、それを満たすソリューションを選択してシステムを構築できます。私たちの認識は弾力的なスケーリングが必要というものでした。
Cloud Spanner を採用したことで、求めていたリレーショナル データベース構造と、ビジネス要件への対応に必要なスケーラビリティおよび可用性との間でありがちなトレードオフに陥らず、どちらについても妥協せずに済みました。同様に、成長企業では、成長に対する人為的な制約の発生を望みません。Cloud Spanner ではデータベースのサイズを “任意の大きさ” にスケーリングできますので、この制約がなく、将来データへのニーズが拡大しても、アプリケーションの書き換えや移行を行う必要はありません。
現実的なダウンタイム対策を講じる
私たちのサービスにとって、ダウンタイムは文字どおり、数千の機会損失につながります。そのため、エラーの影響がユーザーに及ばないように、どのソリューションでも事実上ゼロ ダウンタイムを要求しなければなりませんでした。これはとても重要でした。Google Cloud は Cloud Spanner に SLA 保証を提供しています。私たちが自社で構築するものよりも、このソリューションのほうが高い可用性と耐障害性を提供するのです。
自動化すべき管理に時間を浪費しない
数百万人のユーザーを対象とする数十億通の電子メールのサービスを手がけるうえで、データベース システムの安定稼働に必要なメンテナンスや管理は、時間配分の優先順位が最も低い作業です。もちろん、このことはごく小規模なサービスを手がける場合にも当てはまります。誰しも、自動化すべき作業に多くの時間はかけられません。
ハイブリッドを恐れない
私たちのプロジェクトでは、高速なデータ アクセスのためにクラウドを利用するとともに、既存のオンプレミス環境もバッチ処理に使用するというハイブリッド アーキテクチャが効果的でした。私たちは将来、ワークロード全体をクラウドに移行するかもしれませんが、オンプレミスに置くほうが都合のよいデータもまだあり、現在は大量のデータをオンプレミスに保存しています。
リアルタイムを目指す
今のところ、Cloud Spanner に対して読み書きが可能なのは小さなボリュームのデータのみです。そのため、リコメンデーションにリアルタイムに変更を加えることはできません。Cloud Spanner がバッチとストリーミング接続をサポートすれば、よりリアルタイムのリコメンデーションを提供し、より最適な結果をお届けできるようになるでしょう。
全体的に見て、私たちは Cloud Spanner と GCP に大いに満足しています。クラウドに移行するうえで、Google Cloud はすばらしいパートナーです。そのユニークなサービスのおかげで、私たちはお客様に最高のサービスを提供し、競争力を発揮しています。



