ゴミの話 : Apigee Sense の GCP 移行で “データ リター” とコストが削減
Google Cloud Japan Team
Apigee が Google Cloud ファミリーに加わってから 1 年あまりの間に、私たち Google はいくつかの Apigee サービスを Google Cloud Platform(GCP)にデプロイしました。最近では Apigee Sense を GCP に完全に移行し、GCP の高度な機械学習機能を利用できるようにしています。
移行の過程で私たちは重要な経験をしました。“data litter”(データ リター : ゴミになったデータ)と呼んでいる指標の低下という形でパフォーマンスの向上が得られたのです。
この投稿では、データ リターとは何か、データ リターの増加を抑えるにあたって GCP サービスがどのような役割を果たしているかを説明します。投稿を読んでいくうちに、皆さんは自身のアプリケーションにも同じことが当てはまり、データ リターを重要な指標だと考えるようになるかもしれません。
データ リターとは何か
まず、Apigee Sense とその特徴の紹介から始めましょう。Apigee Sense の目的は、Apigee Edge 上で実行される API を攻撃や不正利用から守ることです。そうした攻撃は一般に、APIの オーナーの許可を得ずに実行される自動プロセス、つまりボットによって行われます。Sense は、収集(collect)、分析(analyze)、可視化(visualize)、作用(act)からなる CAVA サイクルを中心に据えて作られており、統計的な機械学習アルゴリズムを用いて人間による監視作業を補います。
私たちは、Apigee Edge を介して毎日実行される数十億件の API 呼び出しの副産物として、大量のトラフィック データを集めています。CAVA サイクルにおける 4 要素の出力はすべてデータベースに格納されるため、データ管理とデータ分析ツール チェーンのコスト、パフォーマンス、スケーラビリティは、私たちにとって重大な関心事です。
アナリティクス アプリケーションを最適化する際は、レイテンシ、品質、スループット、コストに特に注意を払う必要があります。
- レイテンシとは、問題が発生してからそれに気づくまでの遅れのことです。セキュリティの場合は、ボットの攻撃が起きてから攻撃に気づくまでです。
- アルゴリズムの品質(賢さ)は、真偽の陽性と陰性によって計測されます。
- スループットは、アナリティクス アプリケーションにデータが届く平均的なペースです。
- コストはもちろん、平均でどれだけの金額がかかるかです。
私は、この 4 つに加えて、4 要素の相互作用を計測する意味合いを持つ第 5 の指標を好んで使います。それがデータ リターです。
すべてのアナリティクス システムは本質的に GIGO(ガベージ イン / ガベージ アウト)であり、システムに入ってくるデータがゴミ(ガベージ)であれば、処理までの時間がいかに短くても、アルゴリズムがいかに賢くても、毎秒どれだけのデータを処理できても、まったく無意味です。かかるお金がいくらになるかには重要な意味がありますが、それはお金を使い続ける意味がないからに過ぎません。
データ リターの発生源
一般に、Apigee Sense のようなアナリティクス アプリケーションでデータ リターが発生する要因は 3 つあります。- 分析の適時性 : Sense のようなデータ駆動型の分析エンジンは、決断を下す必要に迫られると、その時点で利用可能なデータを用いて決断しようとします。決断が遅れると、現に行われているボットの攻撃を阻止することにはあまり役に立ちません。そのため、決断を下すにあたって使えるデータがあまりなければ、分析エンジンはそのわずかな情報で決断を下し、先に進みます。遅れて届いたデータは、もう役に立たないので捨てられます。これがデータ リターになります。
- データ処理の弾力性 : データが届くペースが速すぎて分析エンジンが追いつかなくなると、届いたデータが溜まってバック プレッシャーの原因になります。これを解決するには、分析エンジンのサイズ(そしてコスト)を増やすか、圧力を下げるために一部のデータを捨てるかのどちらかを選ばなければなりません。しかし、分析エンジンはすぐにスケールアップできるとは限りませんし、コスト上の理由からスケールアップを諦めなければならない場合もあります。そのため、アナリティクス パイプラインに減圧弁を入れることになり、その結果データ リターが発生します。
- トランザクション処理のスケーラビリティ : ターゲット データベースがダウンしていたり、処理結果生成のペースに追いついていけなかったりすると、パイプラインを止めて入力データを捨てるしかありません。分析結果を利用することも格納することもできないのにデータを分析しても、それは無意味だからです。これもデータ リターが発生する要因となります。
以上のことからもわかるように、データ リターは、分析システムの品質を総合的に示す指標になります。データ リターが少なくなるのは、パイプライン、分析エンジン、ターゲット データベースがすべて適切にチューニングされ、期待どおりに動作しているときに限ります。
第 1 のタイプ(分析の適時性)のデータ リターを減らす最も簡単な方法は、レイテンシを発生させてパイプラインの処理ペースを下げることです。同様に、第 2 のタイプ(データ処理の弾力性)の場合は、コストをかけて巨大なクラスタを構築し、分析エンジンを実行することが解決の方法となります。また、第 3 のタイプ(トランザクション処理のスケーラビリティ)では、データベースのハードウェアを強化すればデータ リターは減少します。
もっとも、どの方法を選んだとしても、レイテンシが増加してシステムの価値を損なうか、コストが増えるのを覚悟しなければなりません。
GCP への移行
Apigee ではデータ カバレッジ指標を使ってデータ リターを推計しています。大まかに言えば、捨てられるなどの理由で分析に使用されなかったデータがどれだけあるかをデータ カバレッジから逆算するのです。Sense の分析チェーンを GCP 上に移行したとき、最も過酷な顧客ユース ケースの 1 つではデータ カバレッジ指標が 80 % 未満から 99.8 % に増えました。別の言い方をすると、データ リターは 5 分の 1(20 %)以上から 500 分の 1(0.2 %)まで減少したということです。これは約 100 分の 1、つまり 2 桁分の低下です。
次のグラフは、決断を下すにあたって使用できたデータの割合が GCP への移行の前後でどのように変化したかを示しています。対象は 4 つの異なる API で、これは Sense をご利用の一部のお客様の場合を表しています。
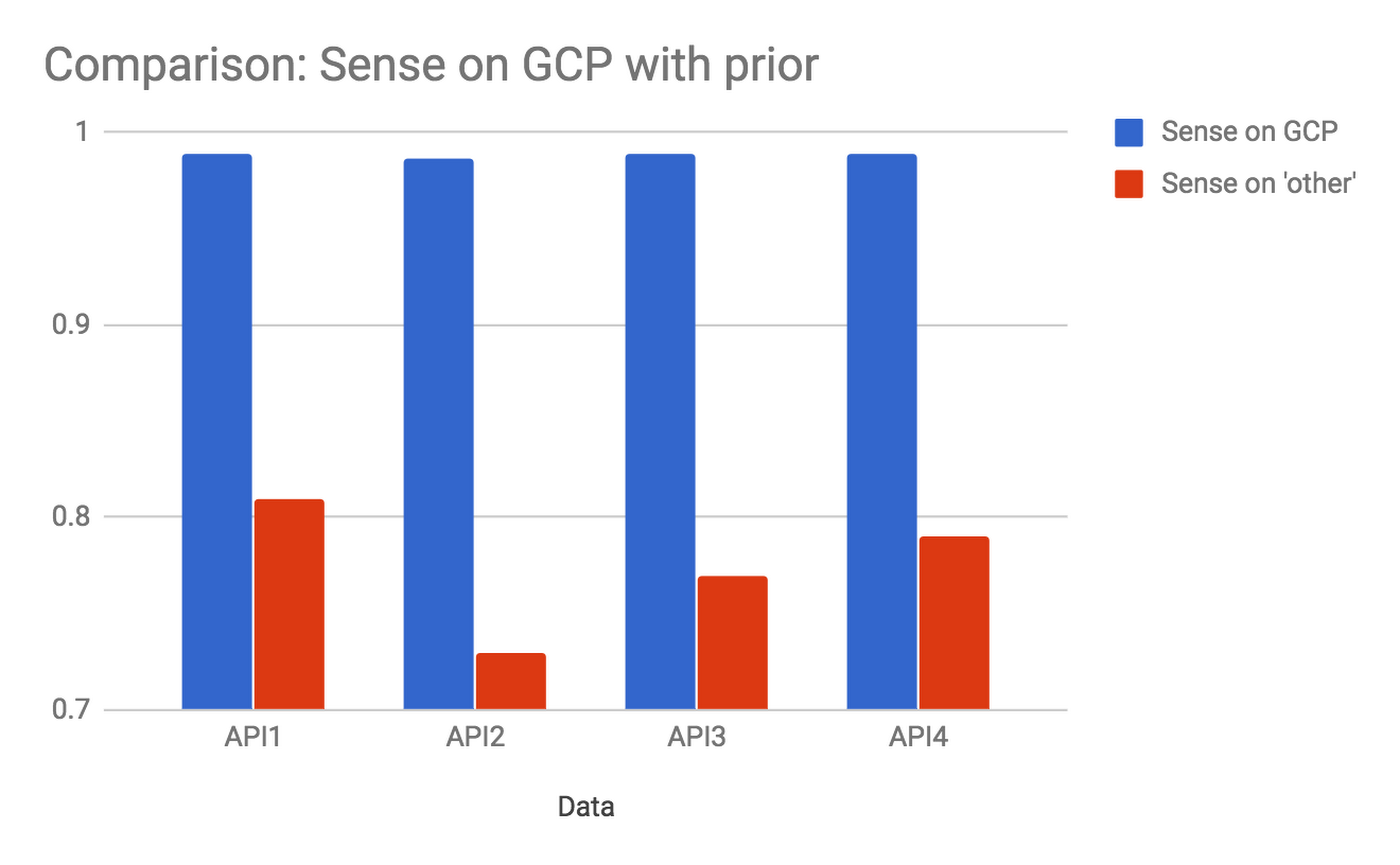
しかも、これらの改善に加え、デプロイされたシステムのコストとパイプラインのレイテンシが低下するという結果が得られました。スループットとアルゴリズムは変わりませんが、レイテンシとコストは下がっているのです。
2 か月前のリリース以来、顧客ベースと処理トラフィックは増加していますが、コストの低下と可用性およびパフォーマンスの向上は一貫しています。同様のユース ケースでは以前よりも信頼性の高い答えを早く手に入れられるようになり、しかもコストは低くなっています。
データ リターはどこに行ったのか
Sense パイプラインには、データ リターの増加要因として、“データ処理の弾力性” と “トランザクション処理のスケーラビリティ” の 2 つの問題がありました。私たちは、できるかぎり早く攻撃発生を警告できるようにするため、適切なレイテンシを設定してシステム自身がデータ リターを生み出さないようにシステムを設計しました。私たちの環境では、想定外のデータ リターを削減するにあたって、次に示す GCP プラットフォームの 2 つの特徴が大きく貢献したのです。
- システムの弾力性 : データがシステムに届くペースは一定ではなく、特に攻撃されているときはペースが上がります。システムは、最も役に立つときに最も強いプレッシャーを受けるため、データの届くペースが中央値を著しく超えてプロビジョニングされることなくスパイクに対応できる弾力性が必要になります。そうでなければ、パイプラインの減圧弁を絶えず作動させることになってしまいます。
- 強力なトランザクション処理能力 : 処理チェーン最後尾のデータベースにかかるトランザクション処理の負荷は攻撃時にピークに達します。さらにデータベースは、ユーザー エクスペリエンスとシステム保護措置のパフォーマンス特性も左右します。そして、これらはいずれも API が攻撃にさらされているときに負荷を増加させます。したがって、トランザクション処理能力は、システムの限界に近い需要に合わせて簡単にスケーリングできなければなりません。
私たちは、今回の移行の一環として分析チェーンを Cloud Dataproc に移しましたが、これにより、安定したコストで強力な弾力性を得られました。最も大きなコスト要因となっていたアナリティクス パイプラインの処理能力を、Dataproc に移行することで大幅に引き上げたのです。コストを増加させることなく、ピーク時の需要を満たすのに必要な弾力性が得られました。
また、ターゲット データベースの BigQuery への移行も行いました。BigQuery は、費用対効果が高い形で処理の分散とスケーリングを可能にします。実際、その能力は私たちのニーズを超えているにもかかわらず、要したコストは最もリーズナブルな IT 予算でお釣りがくるほどでした。これで、チェーン最後尾のバック プレッシャー問題は完全に消えました。
データ リターの 3 つの発生源のうち 2 つが消えたので、私たちのチームは、“分析の適時性” を高めることに全力を注げるようになりました。収集した場所からデータを確実に分析エンジンに送り、従来よりも低いレイテンシで適切かつインテリジェントな判断を下せるようにしたのです。これは、Sense が最初から目標としてきたことでした。
Apigee Sense を GCP に移行することにより、私たちは自らの運命を自らの手に取り戻せたように感じています。お客様にも、サービスの信頼性向上だけでなく、新機能をお届けするまでの期間の短縮という形で、今回の移行によるメリットを感じていただけるでしょう。
* この投稿は米国時間 1 月 10 日、Software Engineer である Sridhar Rajagopalan によって投稿されたもの(投稿はこちら)の抄訳です。
- By Sridhar Rajagopalan, Software Engineer


