ダーク ローンチとは何か : CRE が現場で学んだこと
Google Cloud Japan Team
新しいサービスを立ち上げるときは、予期されるトラフィックに対応したいと思うと同時に、途中で何かが起こっても実際のユーザーに影響を及ぼすことは避けたいと考えるものです。では、どうすればサービスの本格稼働の前に問題を見つけることができるのでしょうか。そんなときはダーク ローンチ(dark launch)を検討してください。
ダーク ローンチとは、実際のユーザーから発生したトラフィックをコピーして新サービスに送信し、新サービスからの結果をユーザーに返す前に破棄することです(注 : ダーク ローンチを “フィーチャー トグル”(機能切り替え)と呼ぶこともありますが、それだとサービスの立ち上げに伴う “ダーク” な隠れトラフィックの側面を捉えることはできません)。
ダーク ローンチでできることは次の 2 点です。
- 新サービスが、既存サービスと同様に実際のユーザーのクエリに対応でき、以前にはなかった不具合が発生するようなことがないことを確認する。
- 現実的な負荷のもとでサービスのパフォーマンスがどうなるかを測定する。
どこでトラフィックを分けるか : クライアント? それともサーバー?
ダーク ローンチを検討するにあたってカギとなるポイントの 1 つは、どこでトラフィックのコピーや分岐を行うかということです。通常これはアプリケーションのフロントエンドで行います。つまり、(負荷分散後に)ユーザーから HTTP リクエストを受信してレスポンスを計算する最初のサービスのところです。ここは変更によるフリクションが最も低いため、分岐点として理想的なのです。この場合の変更というのは、新しいバックエンドに送る外部トラフィックの割合を変更することを指します。ダーク ローンチのトラフィックの割合を 0 % に戻すよう迅速にアプリケーションのフロントエンドに設定変更をプッシュできることは、ダーク ローンチのプロセス上(非常に重大なことではないにしろ)大切なことなのです。
既存のアプリケーション フロントエンドを変更したくないときは、アプリケーション フロントエンドの新旧バージョン双方に対してトラフィックを分岐し、レスポンスの差分を処理する新しいプロキシ サービスにリプレースするのもよいでしょう。
ただし、これには負荷分散の設定を調整してダーク ローンチ前にプロキシを挿入し、その後取り除く必要があるため、ダーク ローンチの複雑さが増します。そのプロキシには独自のモニタリングやアラートがほぼ確実に必要となるでしょう。ユーザー トラフィックのすべてがそこを通過することに加え、まったく新しいコードとなるためです。それが壊れてしまったら、かなり困ったことになります。
そのほか、クライアント レベルでトラフィックを 2 つの異なる URL に送るという方法もあります。1 つはオリジナル サービスに送り、もう 1 つは新しいサービスに送るのです。完全に新しいアプリケーション フロントエンドのダーク ローンチを行い、既存アプリケーションのフロントエンドからトラフィックを送ることが現実的ではない場合(たとえば、オープンソース バイナリによって稼働していたウェブ サイトを自分のカスタム アプリケーションで稼働させようと考えている場合)、この方法が唯一の解決策となります。しかし、このアプローチにも別の課題があります。
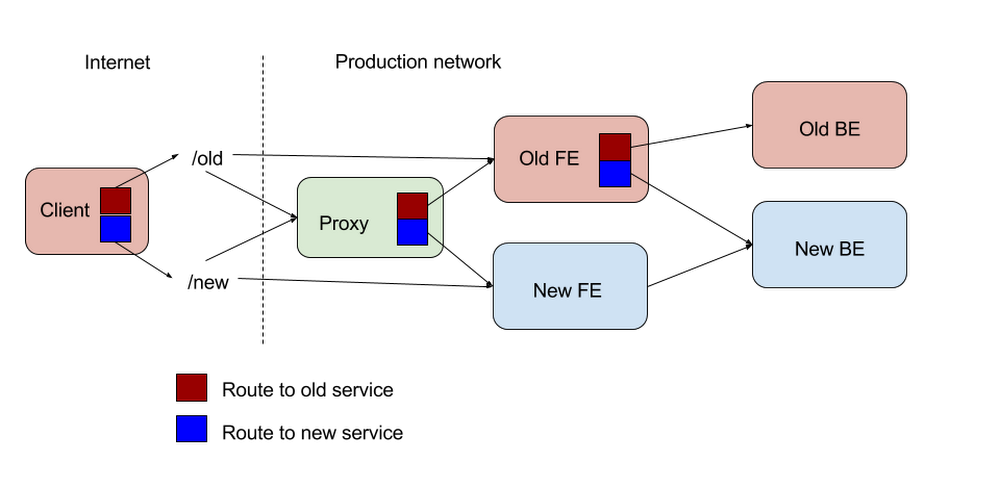
クライアントを変更することで生じる主なリスクは、クライアントの動作を制御できないことです。新しいアプリケーションへのトラフィックを抑制する必要がある場合は、少なくとも関連するすべてのモバイル アプリケーションに設定の更新をプッシュしなくてはなりません。しかし、大半のモバイル アプリケーションには設定変更を動的に伝達するフレームワークが組み込まれていないため、このようなケースでは新たにモバイル アプリケーションをリリースする必要があります。また、モバイル アプリケーションからのトラフィックが倍増し、ユーザー データの消費量が増える可能性もあります。
クライアントの変更で生じるもう 1 つのリスクは、宛先変更が通知されることです。特にモバイル アプリケーションのティアダウンがいつも外部から注目されている場合、これは危険です。レスポンスの差分取得やロギングについても、クライアント内で行うよりもアプリケーション フロントエンドで行うほうがとても簡単です。
ダーク ローンチの効果測定法
ダーク ローンチは、その効果を実際に測定しないのであれば、実施する意義はほとんどありません。では、トラフィックを分岐させたときに、どうすれば新サービスが実際に稼働していることを把握できるのでしょうか。負荷がかかっている状態でどのようにパフォーマンスを測定すればよいのでしょうか。
その最も簡単な方法は、ダーク ローンチのトラフィックが増加している状況下で新サービスの負荷をモニタリングすることです。事実上、これはあらかじめ用意されたトラフィックではなく本番のトラフィックを使っているため、非常に現実的な負荷テストとなります。ダーク ローンチの比率が 100 % となり典型的な負荷サイクルを超えたら(一般的には最低 1 日は必要ですが)、実際にサービスを稼働させてもサーバーが落ちることはないと、ある程度確信できるでしょう。
サービスの宣伝を計画している場合は、サービスに対する追加の負荷を最大限に拡大し、控えめな乗数に基づいたサービス立ち上げの見積もりを調整しましょう。たとえば、エンドユーザーの待ち時間に影響を与えることなく、ライブ ユーザーのクエリごとにダーク ローンチのクエリを 3 つ生成できるとします。これで、ダーク ローンチを行ったサービスがピーク時の 3 倍のトラフィックをどう処理するのかをテストできることになります。
ただし、3 倍に膨れ上がったトラフィックがシステムに流れ込むと運用上のリスクを背負うことになる、という点は覚えておいてください。“こっそり行う” ローンチであるはずなのに、突然 “明るくなる” 危険性を秘めることになります。別の言い方をすれば、サービスがまさに火を噴いて、黄色やオレンジの光を放つようになるかもしれないのです。ダーク ローンチをまだ SRE に相談していないのであれば、今すぐ彼らへの連絡手段を確保し、何を計画しているかを伝えましょう。
サービスごとにピークの時間帯は異なります。世界中のトラフィックに対応し、直接ユーザーとつながっているサービスの場合は、だいたい米国時間の月曜から木曜の午前にピークを迎えます。この時間帯にユーザーがトラフィックを独占することが多いためです。
逆に、写真アップロード受信サービスのようなものは週末にピークを迎える傾向があります。ユーザーは週末に多くの写真を撮影しますし、お正月など大型連休の時期にはトラフィックが急増するのです。したがって、ダーク ローンチを行うにあたっては、待つことが妥当な範囲内で最も重いトラフィックをカバーするようにしてください。
また、ダーク ローンチ中は常にサービス負荷を測定すべきだと私たちは考えています。それがサービスを示すデータであり、ほとんど努力をしなくても測定できるためです。
ただし、負荷だけに気を取られないようにして、以下の測定についても考慮してください。
ログの必要性
受信リクエストを従来のバックエンドと新しいバックエンドに分離するポイントは、一般的にはアプリケーションのフロントエンド部分にあたりますが、この部分は通常、レスポンスが戻ってくるところでもあります。つまりこの部分は、記録したレスポンスを分析するにあたって最適なポイントとなるのです。新しいバックエンドの結果はユーザーには戻さないため、通常はアプリケーション フロントエンドのモニタリングからは直接見えないようになっています。代わりに、アプリケーションがこのレスポンスを内部でログ化します。
アプリケーションは通常、レスポンス コード(20X、40X、50X など)や、バックエンドに対するクエリのレイテンシ、さらにはレスポンスのサイズなどをログ化しようとします。適切な比較による分析のためには、こうした情報を新旧両方のバックエンドでログ化する必要があります。たとえば、もし旧バックエンドが、あるリクエストに対して 40 倍のレスポンスを返してきたとしたら、新バックエンドも同様のレスポンスを返すことが見込まれます。そのときのログは、開発者が簡単に比較でき、簡単に違いを見つけ出せるようなものでなくてはなりません。
また、新旧サービスからのレスポンスは、ダーク ローンチ期間中は常にログ化し、比較することを強くお勧めします。そうすることで、新しいサービスが実際のトラフィックで想定どおりに動くかどうかを把握できるためです。ロギングのボリュームが非常に大きく、パフォーマンスやコストへの影響を抑えるためにサンプルだけを使うことにした場合は、ログ サンプルには含まれていないものの、トラフィック内で見つかっていないエラーがあるということを考慮するようにしてください。
保護用のタイムアウト
新バックエンドが、一部のトラフィックやすべてのトラフィックにおいて旧バックエンドよりも遅くなることは十分にありえます(もちろん速くなることもありますが、それだとあまり面白くありません)。この遅延の原因が、アプリケーションまたはクライアントが、クライアントにレスポンスを返す前に新旧バックエンドの両方のレスポンスを待っているためだとすれば問題です。
一般的なアプローチとしては、新バックエンド コールを非同期にするか、もしくは適切に短いタイムアウトを適用し、その後リクエストを破棄してタイムアウトをログに残すようにすることです。ただし、後者はライブ トラフィックの平均およびパーセンタイル レイテンシに悪影響を及ぼす可能性があるため、前者の非同期アプローチをお勧めします。
非同期アプローチでは、新サービスに対するコールに適切なタイムアウトを設定し、メイン ユーザーのパスからそのコールが非同期になるようにします。こうすることで、ダーク ローンチが本番のトラフィックに与える影響を最小限に抑えることができます。
差分 : 変更部分とその重要性
新旧サービスからのレスポンスが明らかに異なるダーク ローンチでは、新サービスの信頼度が最も高くなります。これは通常、ミューテーションではできません。同じミューテーションを 2 度並行して適用させることができないためです。そんなことをすると、衝突や混乱が生じてしまいます。
差分は、新バックエンドが旧バックエンドと暫定的に互換性があることを確認できる、ほぼ完璧な方法です。Google では通常、プロトコル バッファ フィールドのレベルでこれが行われます。リストの順番を変更するなど、違いを容認することをよしとするフィールドもあります。ここで妥協が必要となります。というのも、正確で意味のある比較には追加の開発作業が必要ですが、そうした比較を行えばローンチのリスクが低減できるからです。また、差分のあるレスポンスの数が少ないと思われる場合は、実際にサービス開始の準備が整う前に、“差分のエラー バジェット” を新サービスに与え、その予算内に収めるようにしてもよいでしょう。
特にコンテンツが複雑な場合、新旧の結果は明確に差があるようにしなくてはなりません。そうすることで、新サービスが旧サービスの暫定的な代替サービスとなることに確信が持てるようになります。複雑なレスポンスの場合は、差分にエラー バジェットを設定するか(たとえば、レスポンスの差分を最高 1 % まで許容する)、もしくは、情報量が少なかったり差分がつけにくかったりするフィールドを比較対象から外すことを強くお勧めします。
これですべてうまくいくのですが、この差分の最適な方法とはどういったものなのでしょうか。サービス内のインラインで統計をエキスポートし、差分のログを取ることも 1 つの方法ですが、これが常に最適な方法となるわけではありません。ダーク ローンチのリクエストを発行するサービスから、差分やレポートをオフロードするほうがよい場合もあります。
Google では差分サービスを複数用意しています。バッチを比較するものもありますし、ライブ ストリームのデータを処理するもの、ライブ トラフィックの差分を見るための UI を提供するものもあります。自分のサービスにおいて、差分によって何が必要なのかを見極め、適切なものを採用しましょう。
本番稼働へ
ダーク ローンチでトラフィックを 100 % 新サービスに課すことができれば、本番に移行することは論理上たいしたことではありません。トラフィックが新旧サービスに分けられたポイントで、旧サービスのレスポンスの代わりに新サービスのレスポンスを返すだけです。新サービスに対してタイムアウトを適用している場合は、そのタイムアウトを旧サービスへと変更します。
これでおしまいです。旧サービスのモニタリングを無効にし、電源を切り、コンピュータのリソースを再利用し、ソース コードのリポジトリから消しましょう(旧サービスの停止を祝うためにチームで食事会を開催するかどうかは自由ですが、私たちは開催することを強くお勧めします)。本番稼働しているサービスはすべてサポートや信頼性が求められるものなので、サービスを停止して数を減らすことは、新サービスを追加することと同じくらい重要なことなのです。
しかし、残念ながら人生はそう簡単にはいきません(id Software の John Cash 氏がかつて、「私は『理論』に移動したい。そこではすべてが機能しているからだ」と述べていました)。新サービスにバグがあった場合に備えて、旧サービスを少なくとも数週間は稼働させ、トラフィックを受信できるようにしておかなくてはならないでしょう。
もし新サービスに不具合が発生したら、再帰的に稼働することがわかっている旧サービスを最終的なリクエスト処理担当とするようにしてください。そうすることで、時間のプレッシャーをあまり感じることなく新サービスの不具合を修正できます。
新旧サービスの切り替えは、上述の説明より複雑な作業になるかもしれません。次回のブログ記事では、移行の複雑さやリスクを高める問題について掘り下げたいと思います。
まとめ
既存トラフィック上で新サービスを立ち上げる際、ダーク ローンチが貴重な手段となり、その管理がさほど難しくないことを理解いただけたでしょうか。このブログ シリーズの第 2 弾では、ダーク ローンチの調整が難しいケースを検証し、その手ほどきについて解説します。
* この投稿は米国時間 8 月 3 日、Customer Reliability Engineer である Adrian Hilton によって投稿されたもの(投稿はこちら)の抄訳です。
- By Adrian Hilton, Customer Reliability Engineer



