ゲスト投稿 : Ocado Technology の GCP Census で BigQuery の利用状況を分析
Google Cloud Japan Team
編集者注 : Google Cloud のお客様である Ocado Technology は、BigQuery メタデータを使ってデータ ウェアハウスの使用状況をひと目で見渡せるようにするプログラムを作成しました(しかもオープンソースです!)。このツールはどのような仕組みなのか、どんな問いに答えられるのか、皆さんの環境でどのように役に立つのかについて、同社に解説していただきました。
Ocado Technology では、Google Cloud Platform(GCP)が提供するビッグデータ用のさまざまなサービスをデータ ドリブンの意思決定や機械学習で利用しています。特に、オンライン小売事業用のプロプライエタリ ソリューションである Ocado Smart Platform では、データ アナリティクス向けのメインのストレージ ソリューションとして Google BigQuery を活用しています。
BigQuery は Ocado プラットフォームの根幹をなす GCP サービスです。そのため私たちは、そこに格納されているデータを簡単に俯瞰できるようにしたいと考え、BigQuery テーブルのメタデータを収集して分析のために BigQuery に格納する GCP Census というツールを作りました。BigQuery に格納されているすべてのデータの概要を把握し、次のような問いに答えられるようにしたいと思ったのです。
- どのデータセット / テーブルが最も大きく、最もコストがかかっているか
- テーブル / パーティションの数はいくつなのか
- 経時的にテーブル / パーティションはどれくらいの頻度で更新されているか
- 経時的にデータセット / テーブル / パーティションはどのように増えているか
- 特定の位置に格納されているテーブル / データセットはどれか
この投稿記事では、組織における BigQuery の利用状況を分析するにあたって、私たちが GCP Census をどのように設計したのか、またこのツールで何かできるのかを紹介します。
なお、このツールは最近オープンソースとなりました。ぜひダウンロードしてご活用ください。
Ocado における BigQuery の利用状況
私たちは BigQuery にペタバイト規模のデータを格納しており、それらは複数の GCP プロジェクトと数十万のテーブルに分かれています。BigQuery はエンタープライズ クラウド向けのデータ ウェアハウスとして、特にスピード、スケーラビリティ、信頼性の面で便利な機能を多数備えています。1 つ例を挙げましょう。最近私たちは日付テーブルの代わりに、さまざまな利点を持つ分割テーブルを使うようになりました。それによって BigQuery 環境はさらに複雑化し、大規模化しましたが、BigQuery では次のようにメタデータの分析方法が限られています。
- プロジェクトごとの全データ サイズ(課金データより)
- 1 つのテーブルのサイズ(BigQuery UI または REST API より)
- __TABLES_SUMMARY__ と __PARTITIONS_SUMMARY__ からは、テーブル / パーティションのリスト、最終更新日時などの基本的な情報しか得られない
そこで私たちは、データの俯瞰図を得るために新たなレイヤを追加することにしました。
GCP Census のアーキテクチャ
レイヤの追加は、結果として GCP Census を編み出しました。このツールは Python で書かれた Google App Engine アプリで、BigQuery テーブルから定期的にメタデータを収集し、BigQuery に格納します。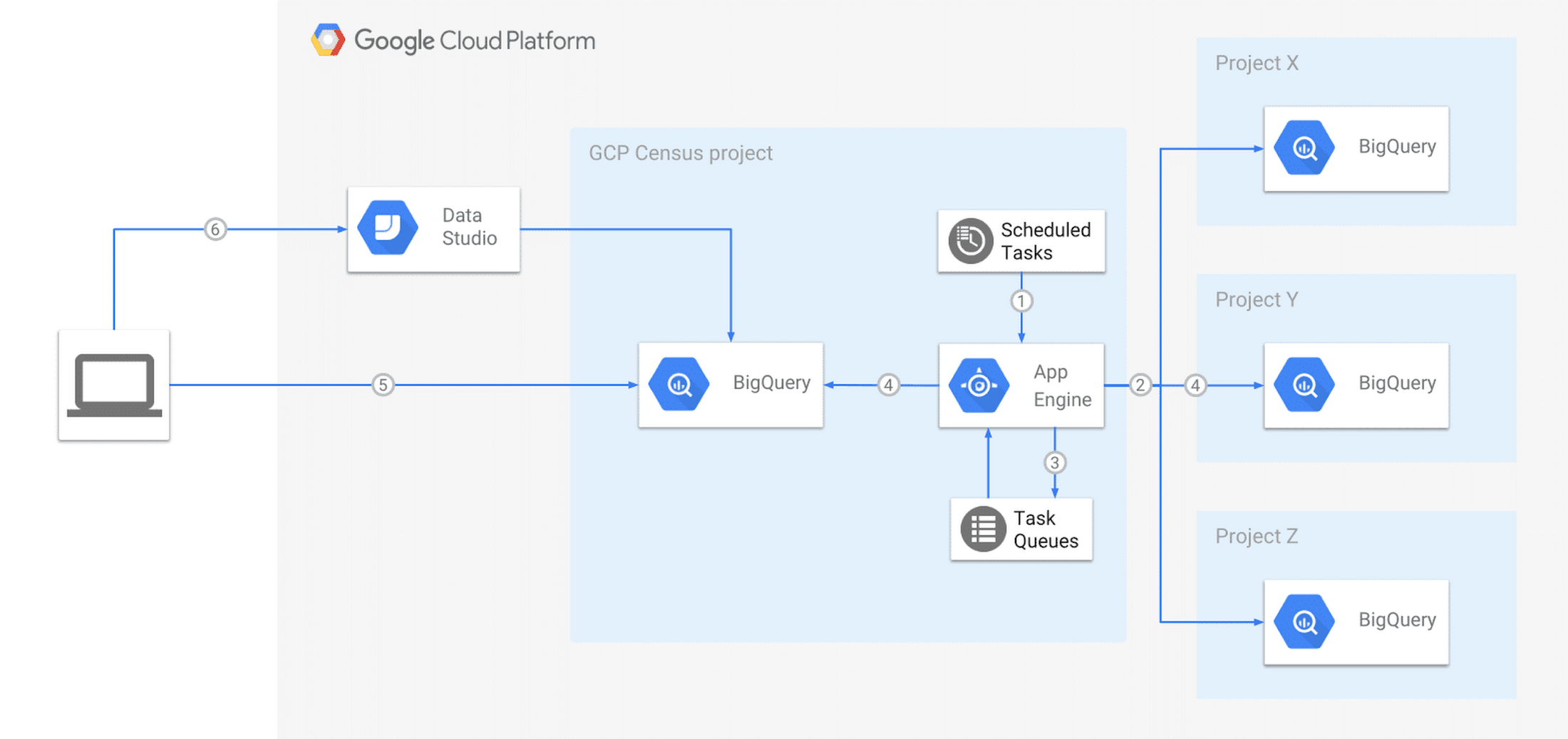
GCP Census の仕組みは次のとおりです。
- App Engine の cron によって日次実行がトリガーされます。
- アクセスできるすべての製品 / データセット / テーブルのメタデータをクローリングします。
- 各テーブルのためのタスクを作り、App Engine Task Queue での実行をスケジューリングします。
- タスク ワーカーが REST API を使ってテーブルのメタデータを収集し、メタデータ テーブルにストリーミングします。分割テーブルの場合は、GCP Census が分割テーブルにクエリを送ってパーティションのサマリー情報を取得し、partition_metadata テーブルに格納します。
GCP Census はスケーラビリティが高く、数百万のテーブル / パーティションを簡単にスキャンできます。セットアップも簡単で、IAM アクセスを持つリソースをスキャンする前に、関連するテーブルやビューを自動的に作成します。App Engine Firewall と粒度の細かいアクセス制御を活用したセキュアでクラウド ネイティブなソリューションに仕上がっており、App Engine のスケーラビリティと信頼性も備わっています。
GCP Census の使い方
GCP Census を使用することの利点について説明しましょう。まず、UI や API を通じて BigQuery にクエリを送ることにより、あらゆる問いに答えられるようになります。GCP Census メタデータへのクエリの例をいくつか紹介します。
- GCP Census がアクセスするすべてのデータの数の取得
SELECT sum(numBytes) FROM
`YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0`
- すべてのテーブルとパーティションの数の取得
SELECT count(*)
FROM `YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0`
SELECT count(*) FROM `YOUR-PROJECT-ID.bigquery_views.partition_metadata_v1_0`
- サイズが大きい上位 100 種のデータセットの選択
SELECT projectId, datasetId, sum(numBytes) as totalNumBytes
FROM `YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0`
GROUP BY projectId, datasetId ORDER BY totalNumBytes DESC LIMIT 100
- サイズが大きい上位 100 種のテーブルの選択
SELECT projectId, datasetId, tableId, numBytes
FROM `YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0`s
ORDER BY numBytes DESC LIMIT 100
- サイズが大きい上位 100 種のパーティションの選択
SELECT projectId, datasetId, tableId, partitionId, numBytes
FROM `YOUR-PROJECT-ID.bigquery_views.partition_metadata_v1_0`
ORDER BY numBytes DESC LIMIT 100
必要に応じてメタデータから Google Data Studio ダッシュボードを作ることも可能です。BigQuery コネクタを使用すれば、簡単かつシンプルにData Studio ダッシュボードを作ることができます。プロジェクト、データセット、テーブルごとのデータの分割やストレージ コストの算出も簡単です。私たちは、最大のプロジェクト、データセット、テーブルを迅速に調べるために複数の Data Studio ダッシュボードを使っています。
以下は、私たちが使用している Data Studio ダッシュボードの 1 つです(実データは編集されています)。
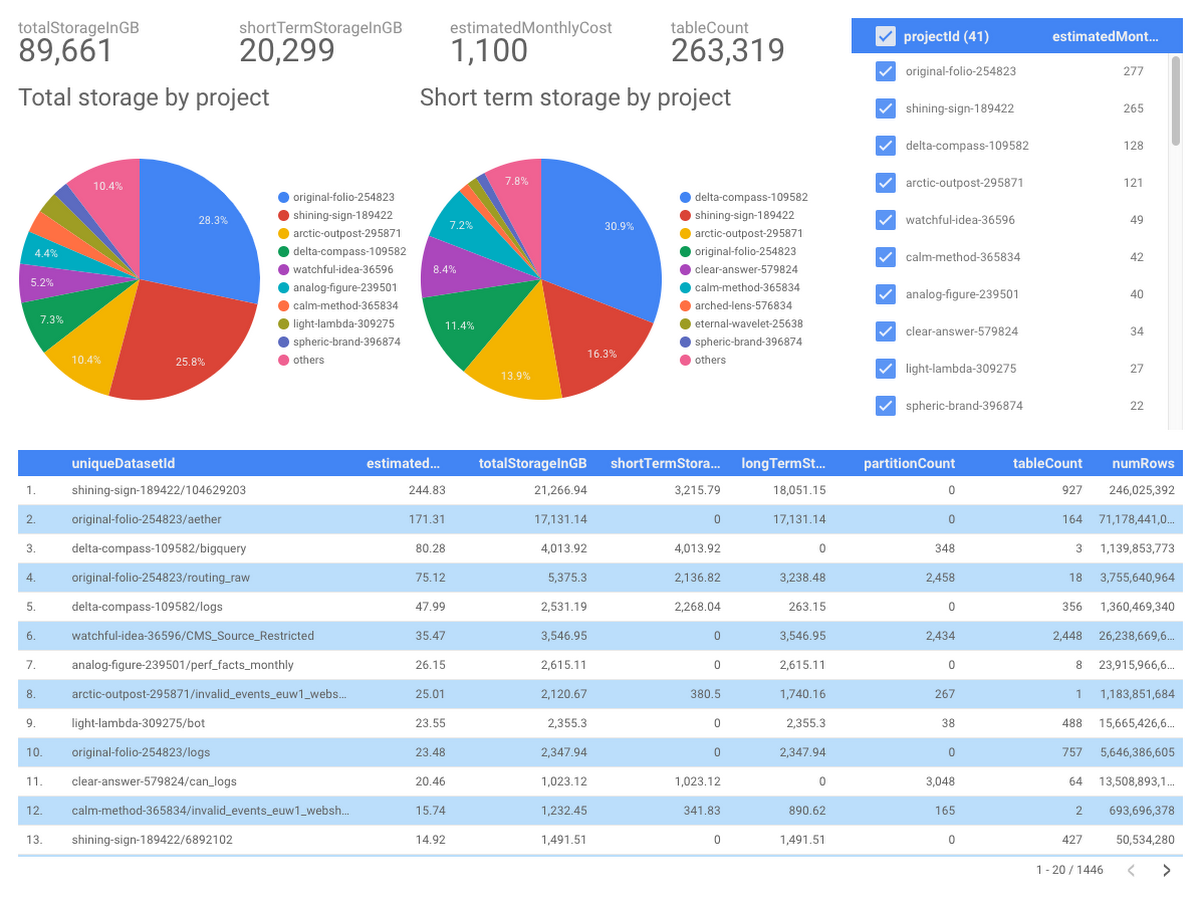
GCP Census により、私たちは自社データの特徴を知ることができました。たとえば、毎日更新されているデータや最近書き換えられた履歴パーティションを把握できるようになったのです。
また、誰も使っていないのに大きなコストがかかっている巨大な一時テーブルなど、経費の削減につなげられそうなものも特定できます。実際、私たちは運用全体について多くのことを学び、コストを大幅に節減しました。
GCP Census のソースコード、インストールおよびセットアップの手順はこちらをご覧ください。皆さんのアイデアやコントリビューションをお待ちしています。
* この投稿は米国時間 1 月 17 日、Ocado Technology の Senior Software Engineer である Marcin Kołda 氏によって投稿されたもの(投稿はこちら)の抄訳です。
- By Marcin Kołda, Senior Software Engineer at Ocado Technology


