Cloud Monitoring の新機能: 分析、稼働時間チェック、アラートのための優れたツール
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
Google の Cloud Monitoring チームは、ここ数か月間、お客様のインフラストラクチャの問題や Google Cloud 内外で実行されるアプリケーションに関する問題の検出、トラブルシューティング、修復を支援する新機能をリリースするために取り組んできました。そして先日、可視化とトラブルシューティングを行いやすくし、ユーザーにとって主要なエクスペリエンスを統合する、いくつかの新機能をリリースしました。
これらの新機能の一部を詳しく見ていきましょう。
トラブルシューティングを簡素化する新しい可視化ツール
これらの機能はすべて、最も重要なときにテレメトリーを簡単に確認できるようにするためのものです。
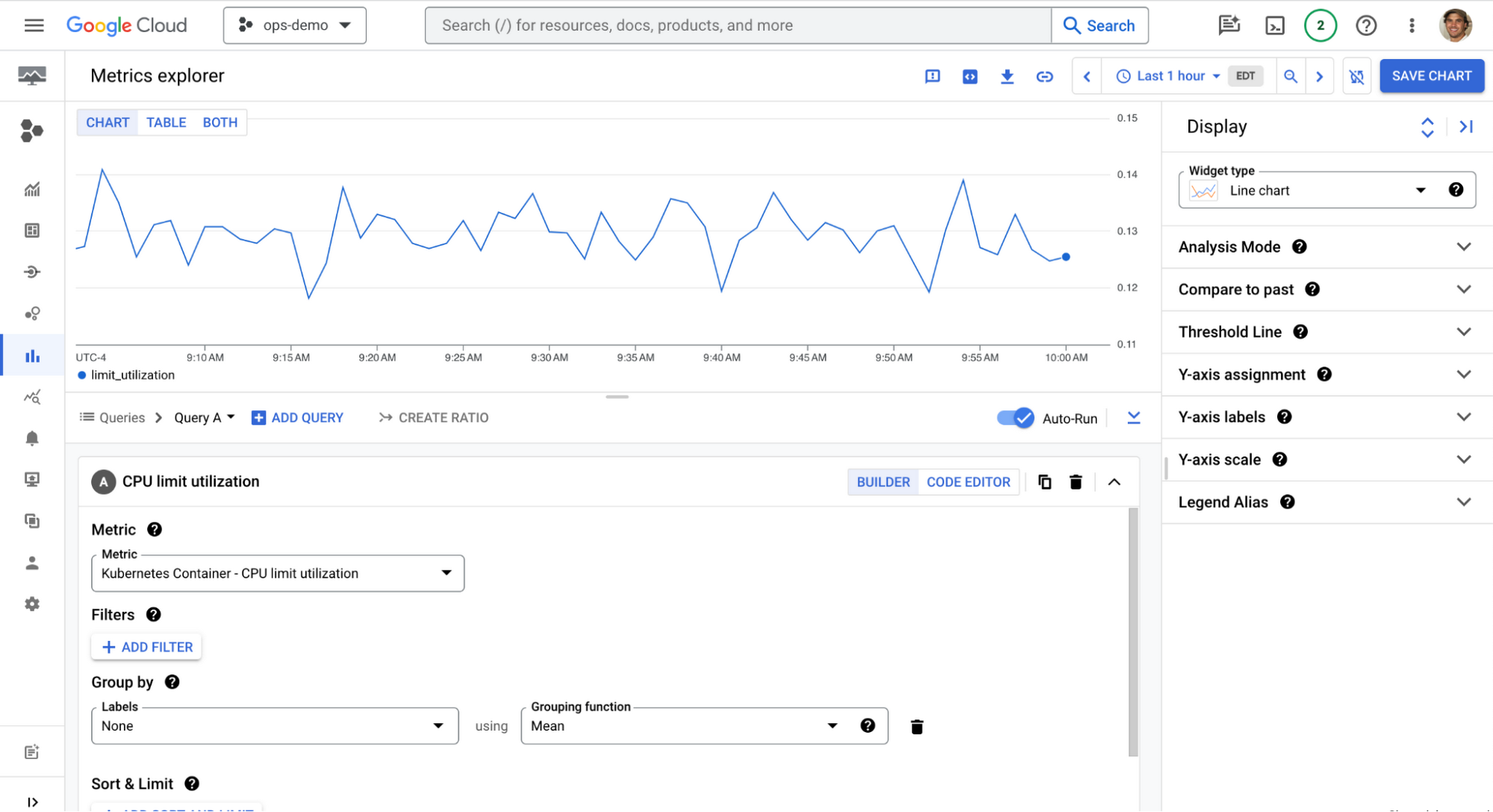
Metrics Explorer の新しいエクスペリエンス
新しい Metrics Explorer では、よりシンプルな UI と改善された情報アーキテクチャにより、指標を簡単に確認できます。問題調査時における複数の指標の相関関係のサポート強化、同一チャート上での複数のクエリの表示、追加表示アクション(過去との比較など)の見つけやすさの向上、新しく直感的なタイムフレーム ピッカー、MQL や PromQL の使用による高度なクエリの明確なサポートが提供されます。これによって、必要な指標を見つけやすくなり、その意味を理解しやすくなります。
共有可能なダッシュボード
共有可能なダッシュボードを使用すると、共通の問題について他のユーザーと協力して取り組んだり、IAM 権限を調整してリアルタイムでの支援に必要なアクセス権をチームメンバーに与えたりすることが容易になります。共有可能なダッシュボードを作成するには、ダッシュボードの右上にある共有ボタンをクリックして、共有したいユーザーのメールアドレスを入力するだけです。共有が許可されると、そのユーザーの Monitoring アカウントでダッシュボードを表示できるようになります。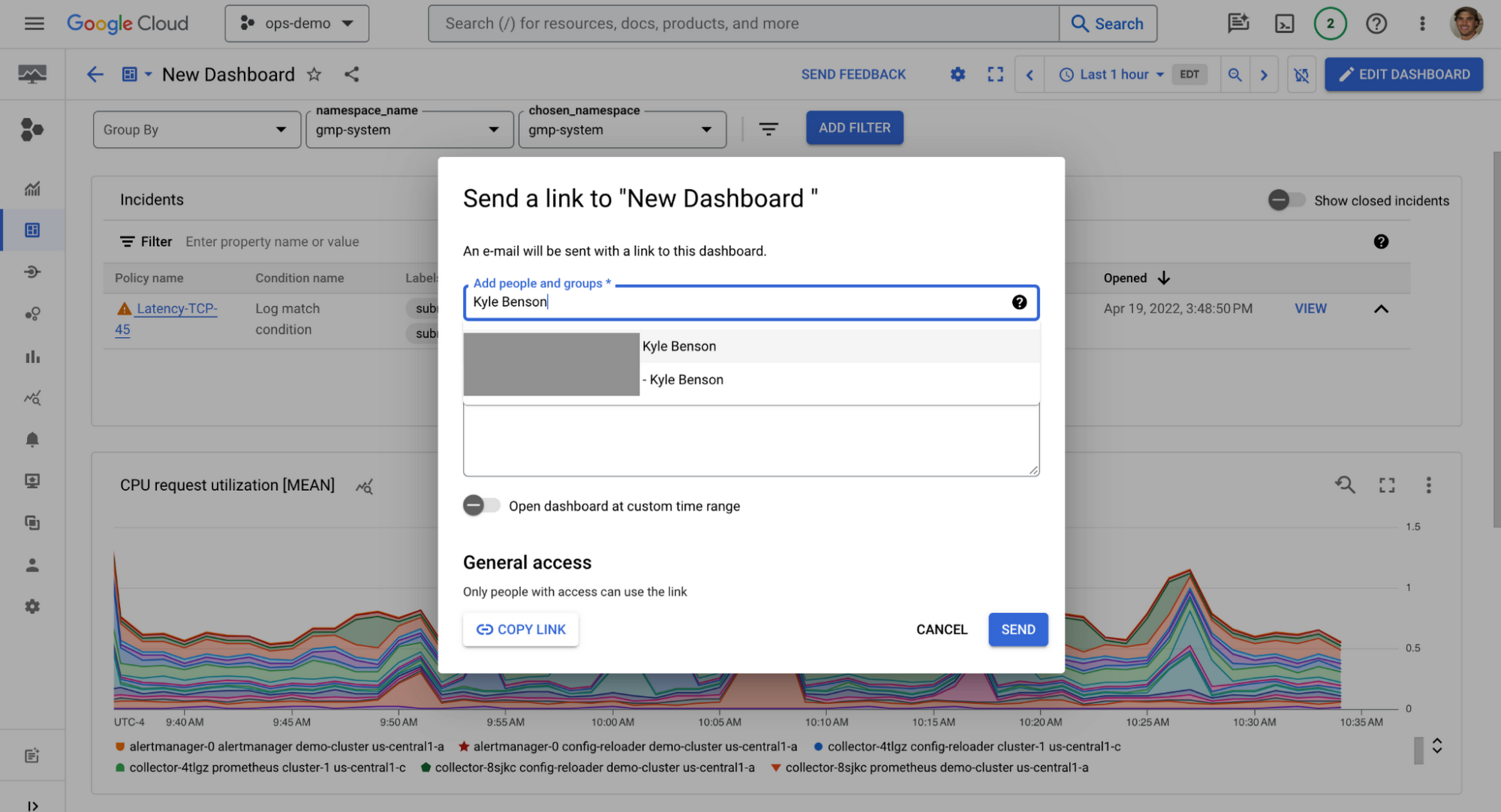
新しいインシデント ウィジェット
ダッシュボード用の新しいインシデント ウィジェットでは、他の主要な指標やログのビジュアルとともに、アクティブなインシデントを確認できます。これにより、それらのインシデントを解決するために迅速なアクションを起こすことができます。インシデント ウィジェットを表示するには、Monitoring コンソールの [インシデント] タブをクリックします。ウィジェットには、すべてのアクティブなインシデントのリストが、その重大度、ステータス、影響を受けるリソースとともに表示されます。また、インシデントをクリックすると、根本原因や影響を受けるユーザーなどの詳細を表示できます。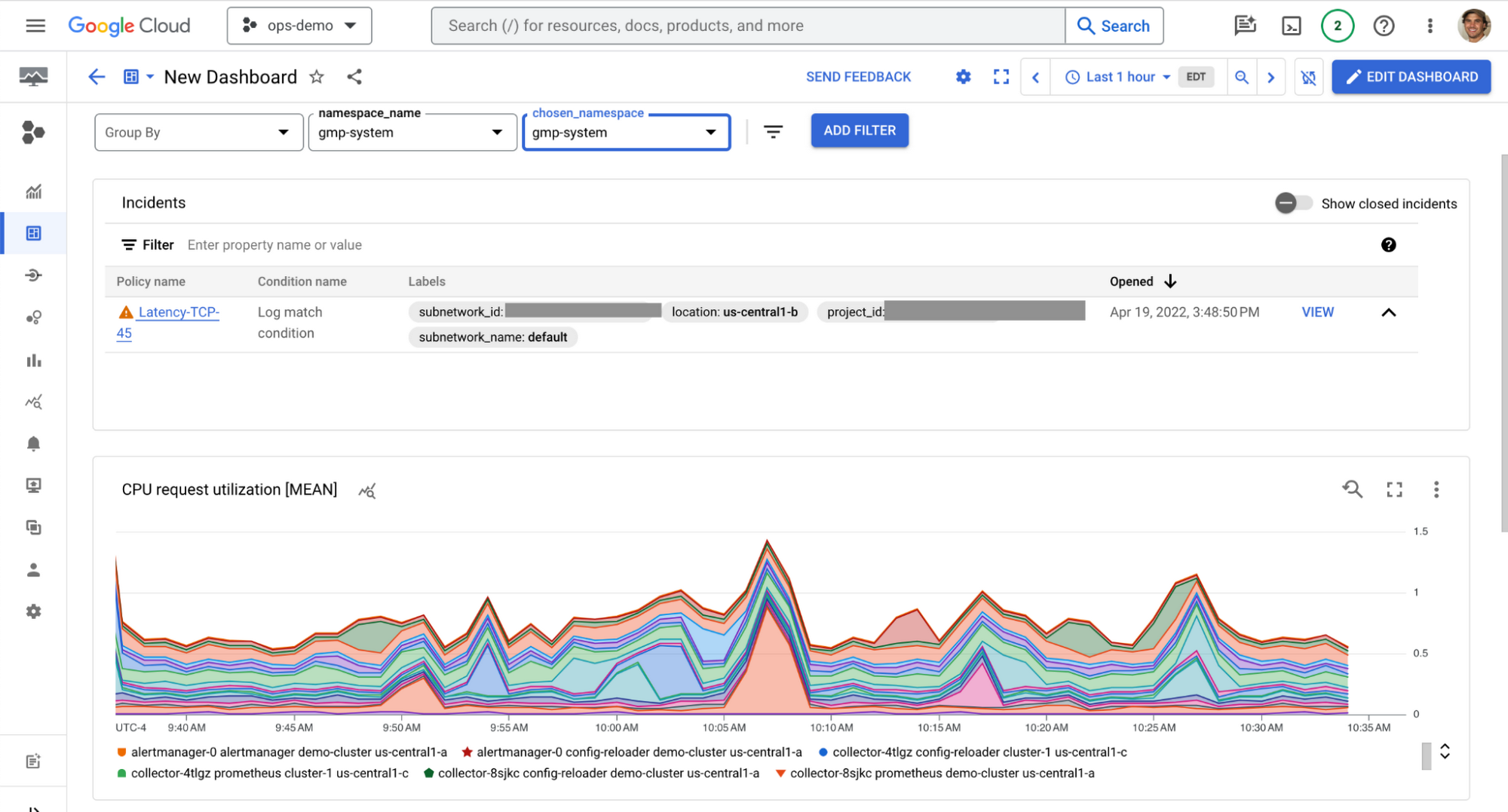
一貫性の向上
シンプルで視覚的に一貫性のあるインターフェースにより、Google Cloud 全体で Monitoring を簡単に使用できるようになり、Monitoring が提供するデータを理解しやすくなります。たとえば、新しい Metrics Explorer には他の Monitoring ビューと同じデザインが採用されているため、ビューを簡単に切り替えることができます。さらに、新しいインシデント ウィジェットは他の Monitoring ビューと統合されているため、すべてのインシデントを 1 か所で見ることができます。
稼働時間チェックによるブラックボックス モニタリングの拡張
Cloud Monitoring の稼働時間チェックを使用すると、リソースが利用可能かどうか、期待どおりに動作しているかどうかをエンドユーザーの視点から判断できます。このたび、稼働時間チェックが複数の Google Cloud サービスと統合されました。
GKE 稼働時間チェックの統合
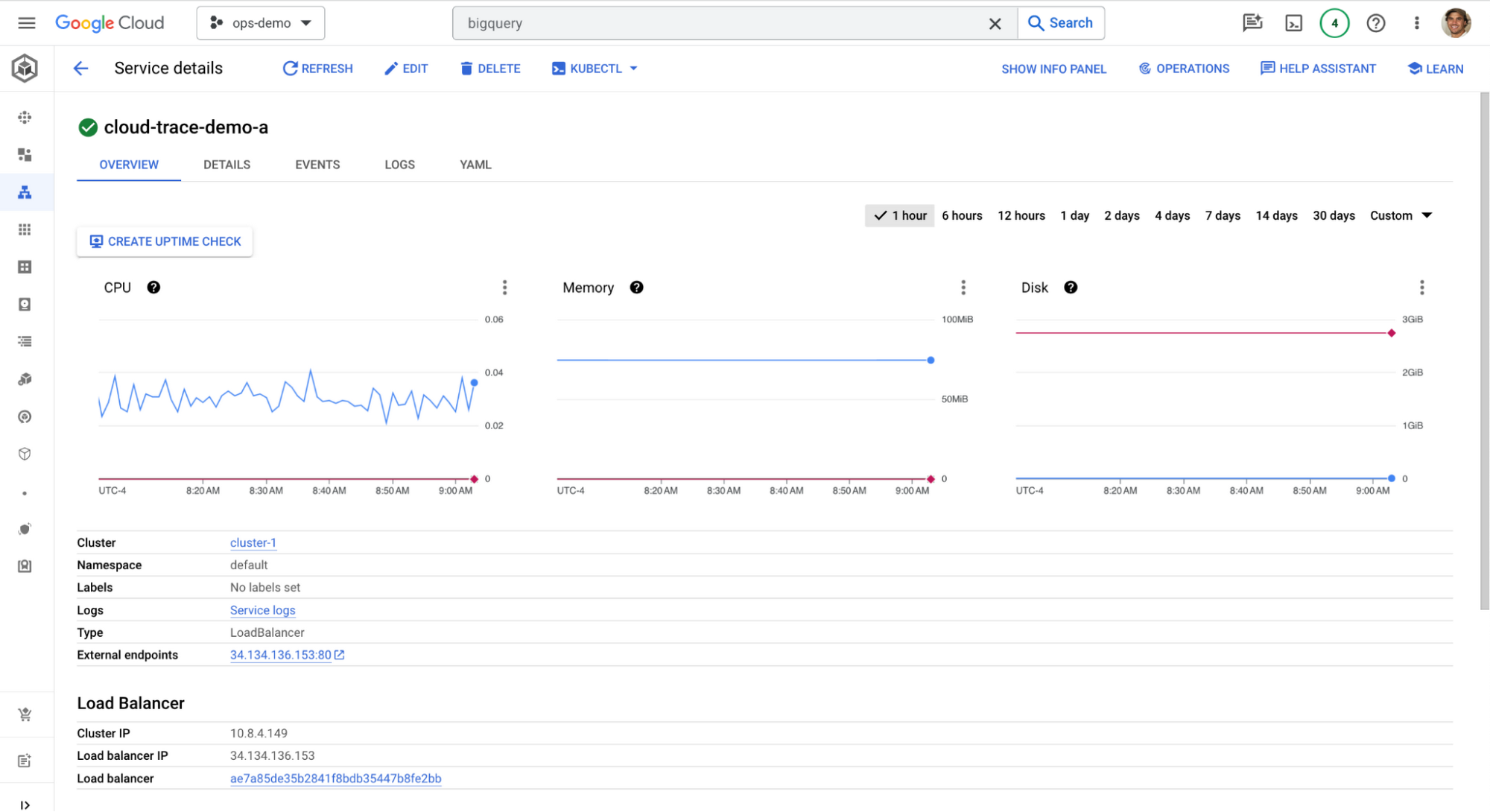
GKE サービス稼働時間チェックのサポートが拡張され、Google Kubernetes Engine コンソールから稼働時間チェックを直接作成できるようになりました。GKE UI 内でサービスの状態を確認している場合、現在の場所を離れることなく、直接その UI から稼働時間チェックを作成できます。稼働時間チェックは、追加の計測を必要とせずにサービスのモニタリングを開始できる非常に簡単な方法の一つです。ユーザーが GKE サービスのモニタリングを迅速に開始できる点で優れています。
Cloud Run の稼働時間チェック
Cloud Run 専用の稼働時間チェックが新たに導入され、Cloud Run サービスに対するターゲットの作成が容易になり、エンドユーザーやお客様の立場からサービスの健全性をより適切に追跡できるようになりました。
アラートの改善
アラート ポリシーは、トラブルシューティングを行ううえで重要な要素です。Google Cloud の経験が浅いユーザーがシグナルとノイズを見分けられるように、オンボーディングを簡素化するための推奨事項が提供されるようになりました。
推奨アラート ポリシー
先日、Google Cloud の主要サービスのモニタリングを開始するために役立つ推奨アラート ポリシーを導入しました。これには、ネットワーキング サービス、Compute Engine、GKE が含まれます。テンプレートは Cloud コンソールで利用可能で、GitHub からプログラムで取得できます。以下は UI の例です。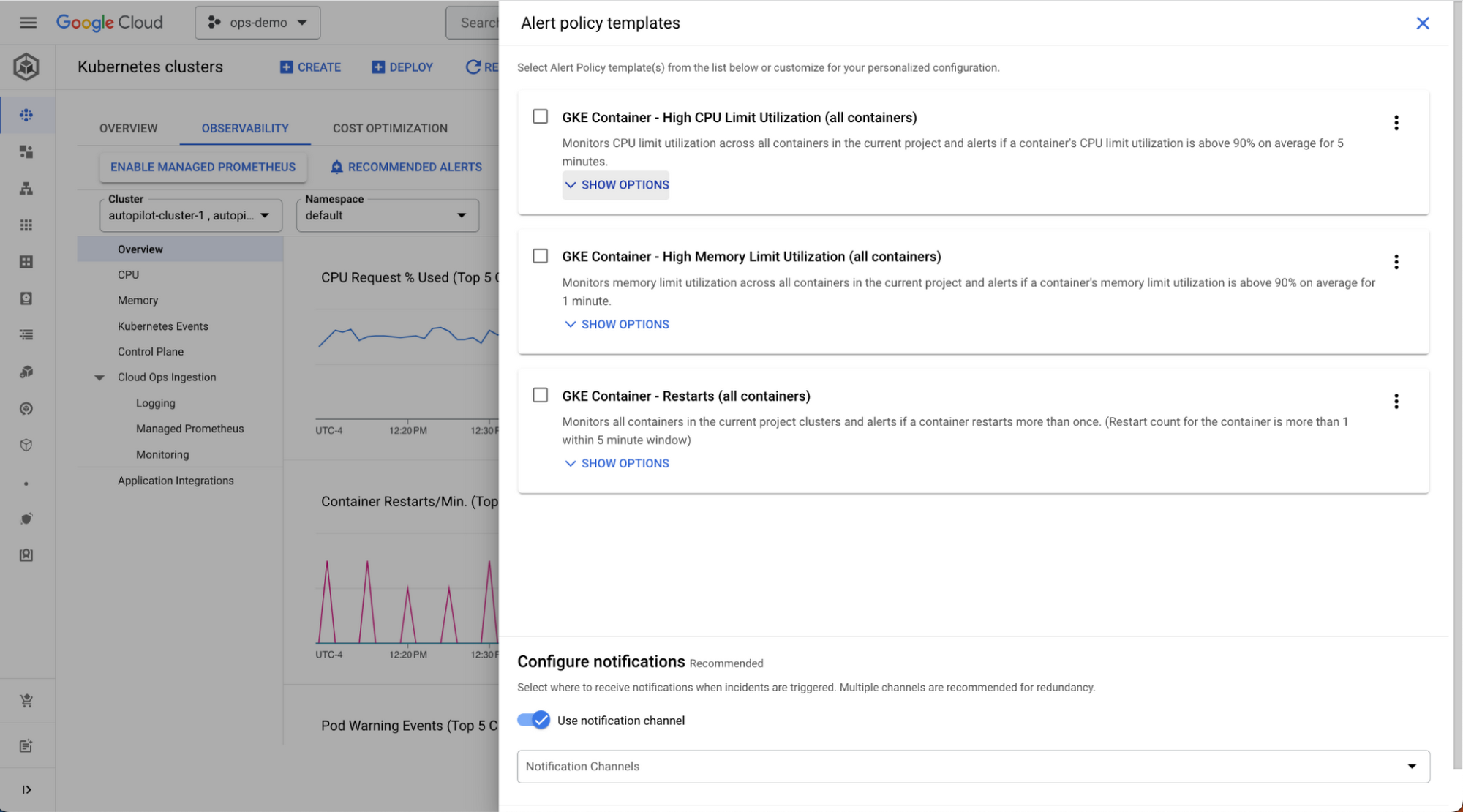
アラートのスヌーズ
ノイズを減らすために、アラートをスヌーズできるようになりました。これは、計画的なメンテナンス期間中や、既知の拡大しつつある障害への対処中などに便利です。この機能は現在、API、UI、Terraform 対応の gCloud で利用可能です。スヌーズが繰り返されるようにスケジュールを設定する場合は、API を呼び出して cron ジョブを使用します。組み込みの繰り返し機能は、今後サポートされる予定です。
シグナル コレクションの簡素化
最後に、新しい Ops エージェントの統合により、OpenTelemetry Protocol(OTLP)指標とトレースを Compute Engine ワークロードから簡単に収集できるようになりました。Ops エージェントと OTLP を組み合わせることで、プッシュベースの指標、自動認証、Prometheus / PromQL との互換性を実現できます。
Google Cloud Monitoring をご利用の場合は、ぜひこれらの新機能をお試しになり、トラブルシューティング エクスペリエンスの改善にお役立てください。新機能に関するフィードバックがございましたら、右上の疑問符アイコンを選択し、[フィードバックを送信] からご意見をお寄せください。



