SRE および DevOps の手法を使用して、Looker エコシステムを大規模に管理
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
多くの企業が、データドリブンな文化、つまりそれぞれの従業員がデータに基づいて意思決定を行える文化を作り上げることに苦心しています。特に、多数のチームでさまざまなシステムやツールを使用している企業がこれに当てはまります。リーダー、マネージャー、エグゼクティブが Google の SRE 手法や広範な DevOps 手法をチームで活用することを重視しながら取り組みを進めている場合、それはまったくもって適切な方向にあると言えます。
企業や成熟したスタートアップ ビジネスの今日の状況
今日、大企業が数百もの小規模チームに分割され、それぞれのチームが数ペタバイトものデータ、しかも未加工時にはさまざまな形式になっているデータに対処していることも少なくありません。「データへの対処」としては、データの生成、円滑化、消費、処理、可視化、システムへのフィードバックなどがあります。責務が多種多様であるため、スキルセットの種類も多岐にわたります。非常に多くの従業員やチームが、データを使用した作業、ひいては次のようなデータのエコシステム全体に及ぶ任務を担っています。
未加工のソースデータとシステムデータの一元化
ウェアハウスでのデータの保持と変換
データに対するアクセス制御と権限の管理
データのモデリング
アドホックのデータ分析およびデータ探索の実施
データの可視化とレポートの作成
このような状況下で、これらすべてのチームには、サービスの実行を継続し、ダウンストリームのお客様の満足度を維持するという共通の目標があります。言い換えれば、組織が内部で分割されている場合でも、組織全体として、データを活用してより優れたビジネス上の意思決定を行うという、共通の使命を負っています。このため、サイロ化やサブ目標の違いがあっても、すべてのチームの方向性は組織の成功に向けて結束しています。このような一連の多様なデータソースとそれらに対応するチームを支援するために、Looker では 60 を超える言語(データソースからの入力)と 35 を超える出力先(新たなデータソースへの出力)がサポートされます。
次に、Looker エコシステムがデータリッチな組織の中心となる仕組みを表す概略図*を示します。
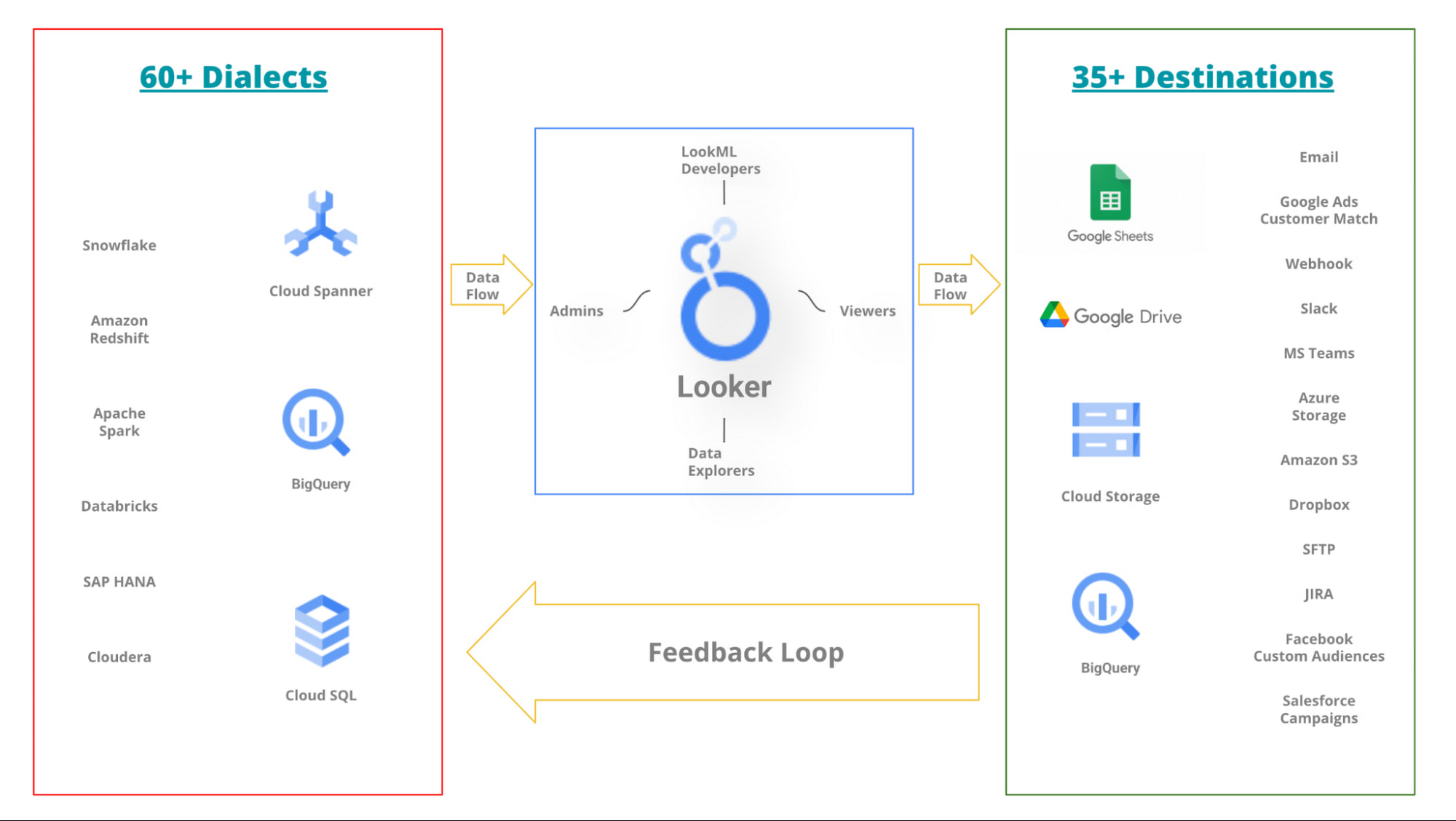
*この図は、各データソースの責任を担っているチームの複雑性を表していません。また、データソース間の依存関係も表していません。Looker Marketplace もエコシステムで重要な役割を担う場合があります。
DevOps および SRE の手法が果たせる役割
最も理想的なのは、これらすべてのチームがシングルスレッド組織として調和しており、すべての内部プロセスがスムーズな状態で、全従業員が新しいことを試せる(つまり常に失敗、学習、反復、再現できる)状態です。組織の複雑性が増すにつれ、オーバーヘッドや優先順位のずれが生じて、このような理想的な状況を実現することがきわめて難しくなってきます。このような状況において、DevOps および SRE の手法の基本理念を取り入れます。Google SRE の手法について詳しくは、まずこちらを参照してください。DevOps および SRE の手法の中心には、成熟したコミュニケーションおよびコラボレーションの手法があります。
Looker エコシステムに有用なベスト プラクティスに焦点を合わせて見ていきましょう。
共通目標を持つ。複数のチームで共通の責務とする目標を立てる必要があります。これにより、チーム間で心理的な安心と透明性の文化を構築できます。
組織全体のデータの流れを可視化する。これにより、各チームがどのような役割を担っているか、より効果的に連携するにはどうすればよいかを理解できます。
ゴールデン シグナル(主要な指標)について合意する。これには、データの更新頻度、データの正確性、一元化されたダッシュボードのレイテンシなどがあります。こういったシグナルを立てることで、各チームはエラー バジェットや SLI を設定できるようになります。
さまざまなチームにわたるコミュニケーションおよびコラボレーションの手法について合意する。
標準の双方向コミュニケーション モード - Google Chat スペースやSlack チャンネルを共有します。
共同で所有しているドキュメント ページ、共有のロードマップ項目、再利用可能なツールといったアーティファクトに焦点を合わせます。たとえば、System Activity ダッシュボードにすべての関係者がアクセスできるようにし、組織に合わせてカスタマイズしたメモを表示します。
通常は主要な変更、想定されるダウンタイム、主要な指標に関する事後分析といった議題について話し合う定期的なフォーラムを設定します。その他の議題としては、組織全体で用語を統一するために、LookML の基準の共通セット(一元的に定義された label、group_label、description など)を定義、精査することが挙げられます。
得られた教訓などを気軽に共有する機会、TGIF、ランチ ミーティング、シャドーイングの機会を持つことを推進します。互いに学び、教えることは、チームの発展に大きな影響を及ぼします。チームが、普段の日常業務から少しそれたサイド プロジェクトで絆を深めることも多々あります。
チェンジ マネジメントの手法について相互に合意する。各チームに依存関係があるため、変更によって他のチームに影響が及ぶ可能性があります。そういった変更を体系的に計画してはどうでしょうか。たとえば、高度なデプロイモードに対して共通の基準を設定します。
継続的な改善を促進する。各チームにとって重要なことを改善し、迅速化し、コスト最適化する方法を常に探ります。
データフローを再検討する。主要な再編成の後には、その組織的な変更によって、確立されていたメカニズムが壊されていないことを確認します。
サイロ化やサブ目標の違いがあっても、すべてのチームの方向性は組織の成功に向けて結束しています。
オーバー エンジニアリングになっていないか。
エコシステムの成熟過程において、システムがオーバー エンジニアリング状態になる、つまり意図せず環境にトイルを加えてしまう可能性があります。コミュニケーションのギャップが原因であることが多いトイルの例としては、次のようなものがあります。
成果やアクション プランが導き出されないミーティング - これは特に生じることの多いトイルの一つで、ミーティングの最初の意図が無効になっているのに、フォーラムで決定事項を再検討しようとしません。
不要な承認 - シングルスレッドのチームは、不要な依存関係を作ることが多く、チームが変更を行えなくなる可能性があります。
メンテナンス時間枠の未調整 - 複数のチームにわたる変更は相互に排他的ではない可能性があるため、メンテナンスの時間枠が調整されていないと、エンドユーザーに不測の影響が生じることがあります。
魅力的だが不要なツール - サイド プロジェクトは、管理されていないと、ビジネスで使用されない不要なツールを生む可能性があります。コラボレーションは、ビジネス上の実際の問題を解決するには効果的ですが、そのためには優先度が適切に設定されていることを確認し直すことも必要です。
不明確な領域 - 責任の共有モデルを採用している場合、所有者のいないギャップであることが多い不明確な領域が生じてしまうことがあります。長期的にはこれによって複雑性が増す可能性があります。たとえば、コンテンツ配信のスケジュールに柔軟性を与えるには、コラボレーションでエラーが生じるジョブの数を低減する必要があります。これによって、Looker インスタンスのパフォーマンスが低下する可能性があるからです。
指標における矛盾 - 内部指標に貢献したチームをどのように労うかに特別な注意が必要な場合があります。たとえば、あるチームがデータの正確性を重視しており、別のチームが更新頻度を重視している場合、規模が大きくなると、2 つのチームは互いに同調していない可能性があります。
まとめ
まとめると、大規模な組織でユニバーサル セマンティック モデルの統合の中心として Looker を使用して、データをどのように処理するかについて説明してきました。大量の多様なデータを処理するには、チームは共通目標を定めることから開始して、強力なコラボレーションに力を注ぐ必要があります。また、これらの複雑性に対処しながら取り組みを進めるうえで DevOps および SRE の手法がどのように役立つかについても説明しました。最後に、過度に構造化されたシステムの副次的影響について確認しました。ここから前進するには、対象範囲内のデータフローおよび複数のチーム間でのコラボレーションの成熟度を分析することから始めるようおすすめします。
その他の読みものとリソース
- テクニカル アカウント マネージャー(中東担当)Saurabh Bangad



