Cloud Spanner Data Boost: 運用データの分析をトランザクション ワークロードから分離する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 8 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
デジタル トランスフォーメーションを継続する組織が直面する大きな障壁の一つは、運用中のライブ データベースに対して分析クエリ、レポートクエリ、または大規模なバッチジョブを中断のリスクなしに安全に実行するにはどうすればよいかということです。このようなクエリは大量のリソースを消費する可能性があり、チェックしていなければビジネス クリティカルなトランザクションを中断させる可能性があります。そのため、データベースのオーナーはデータ共有シナリオに対して厳格な管理や制限を実装しています。Google は、お客様のアプリや意思決定に最新のデータを提供するため、トランザクション システムと分析システムの間の障壁を打ち破ろうとしています。Google Cloud Next ’23 で、Cloud Spanner Data Boost の一般提供が発表されました。Cloud Spanner Data Boost は、分析、レポート、ML などをサポートするために、ワークロードを分離して運用データをオンデマンドでハイ パフォーマンスに処理する画期的な技術です。
Data Boost は、コンピューティングとストレージが分離された Google のアーキテクチャを利用することで、既存のトランザクション ワークロードにほとんど影響を与えずに、分析クエリをストレージ レイヤで直接処理するオンデマンドの分離されたコンピューティング リソースを提供します。さらに、ほぼ無限のスケール、グローバルな外部整合性、比類のない可用性といった Cloud Spanner の長所もすべて兼ね備えています。
従来のアプローチが非効果的で費用がかかる理由
これまで、データ共有の制限や管理に直面したチームは、追加のレプリカを作成するかデータベースをオーバー プロビジョニングすることでこれに対処してきましたが、これには多大な費用と管理上のオーバーヘッドがかかります。その他に、分析システムにデータを供給する拡張パイプラインを構築するケースも見られますが、これには長期的な財務費と運用費がかかります。データが確実に提供されないと業務の遂行に支障を来たすため、今やこうしたパイプラインはクリティカル パス上にあります。つまり、これらのパイプラインでは、データベースと同じレベルの可用性と障害復旧を保証しなければなりません。
要するに、データベース内で厳格なリソース管理ポリシーを適用すると、問題が次のどちらかに移行します。1)使用頻度の低い(費用を浪費する)オーバー プロビジョニングされたリソースを用意する。2)優先順位の高い受信クエリを処理するためにどのユーザー / ワークロードを中途で終了させるかを選ぶ。
Google は、もっと良い方法があるはずだと考えています。Cloud Spanner Data Boost は、本当の意味で誰もが運用データを利用できる道を開くことを目指しています。Data Boost を使用すると、BigQuery や Dataproc 上の Spark などのサービスを介して Spanner データを分析する、Dataflow を使用して Spanner データをエクスポートする、カスタムジョブやカスタム アプリケーションで Spanner データを使用するといったことが可能になります。これらはいずれもトランザクション ワークロードにほぼ影響を及ぼしません。
「ブラジルの金融市場に革命を起こしている CERC は、毎秒 10 万件以上の金融トランザクションを低レイテンシで処理しています。Cloud Spanner Data Boost を使用することで、トランザクション ワークロードに影響を与えることなく、より効率的にこのデータに対して分析クエリを実行できるようになりました。これは当社にとって大変重要です。Data Boost は革新的なサービスであり、レプリカの作成やリソースのオーバープロビジョニングのオーバーヘッドなしに、トランザクション データをリアルタイムに低費用で分析できます。」 - CERC、プリンシパル エンジニア、André Guergolet 氏
ワークロードを完全に分離した革新的なアプローチ
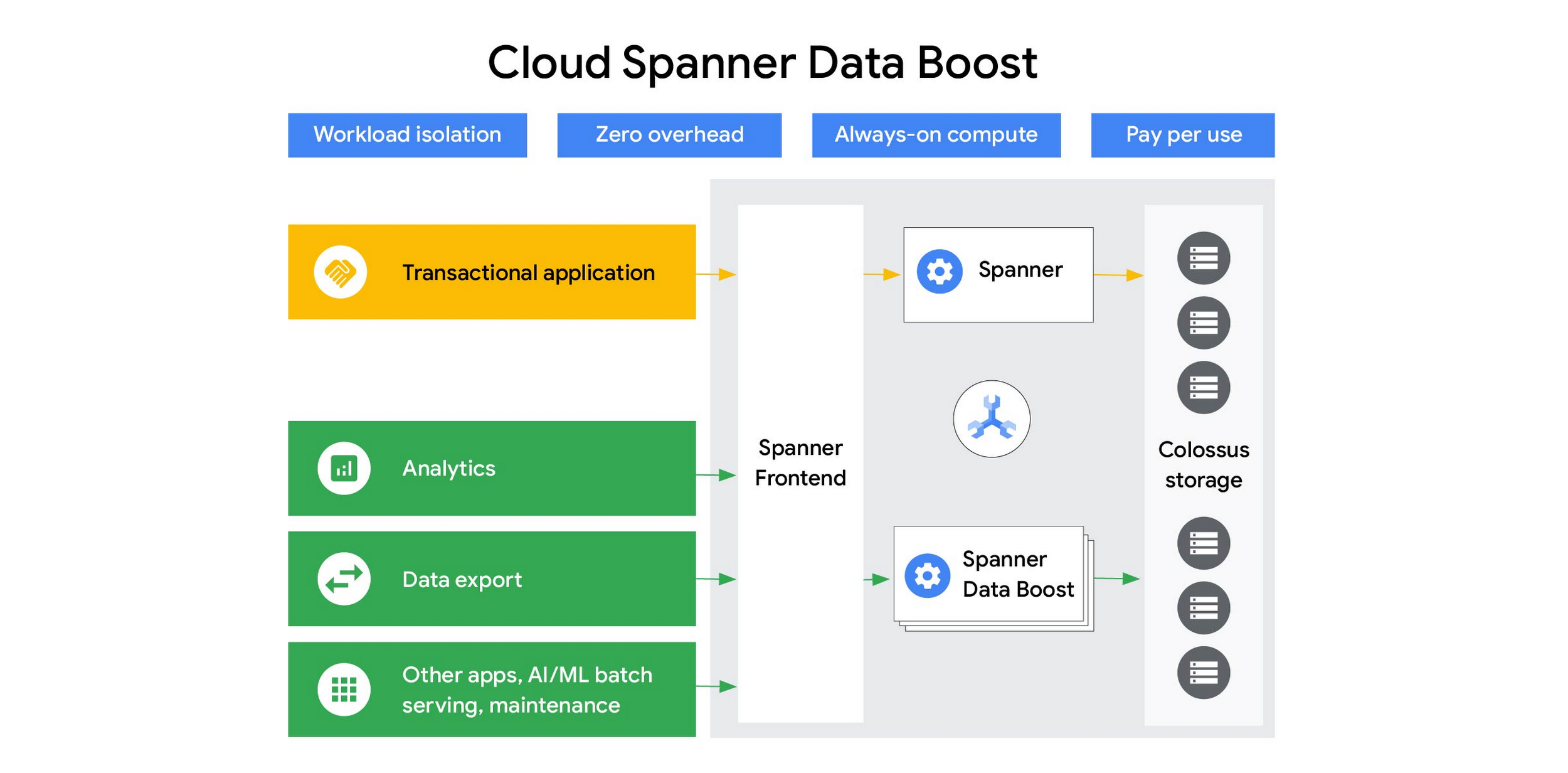
Data Boost では、分析クエリ、バッチ処理ジョブ、一括データ エクスポート操作をトランザクション ワークロードから完全に分離して実行でき、パフォーマンスが大幅に改善されます。Google によって完全に管理されるため、お客様側でキャパシティ プランニングや管理を行う必要はありません。Data Boost は常に稼働しており、ユーザーからのクエリをいつでも受け取る準備ができています。クエリはレプリカではなく Colossus(Spanner の分散ストレージ システム)に保存されているデータに対して直接処理されるため、ユーザーは最新のデータにアクセスできます。このオンデマンドの独立したコンピューティング リソースは、混在したワークロードを容易に扱える柔軟かつスケーラブルで費用対効果に優れたアーキテクチャを提供し、スケーラブルで心配いらずのデータ共有を可能にします。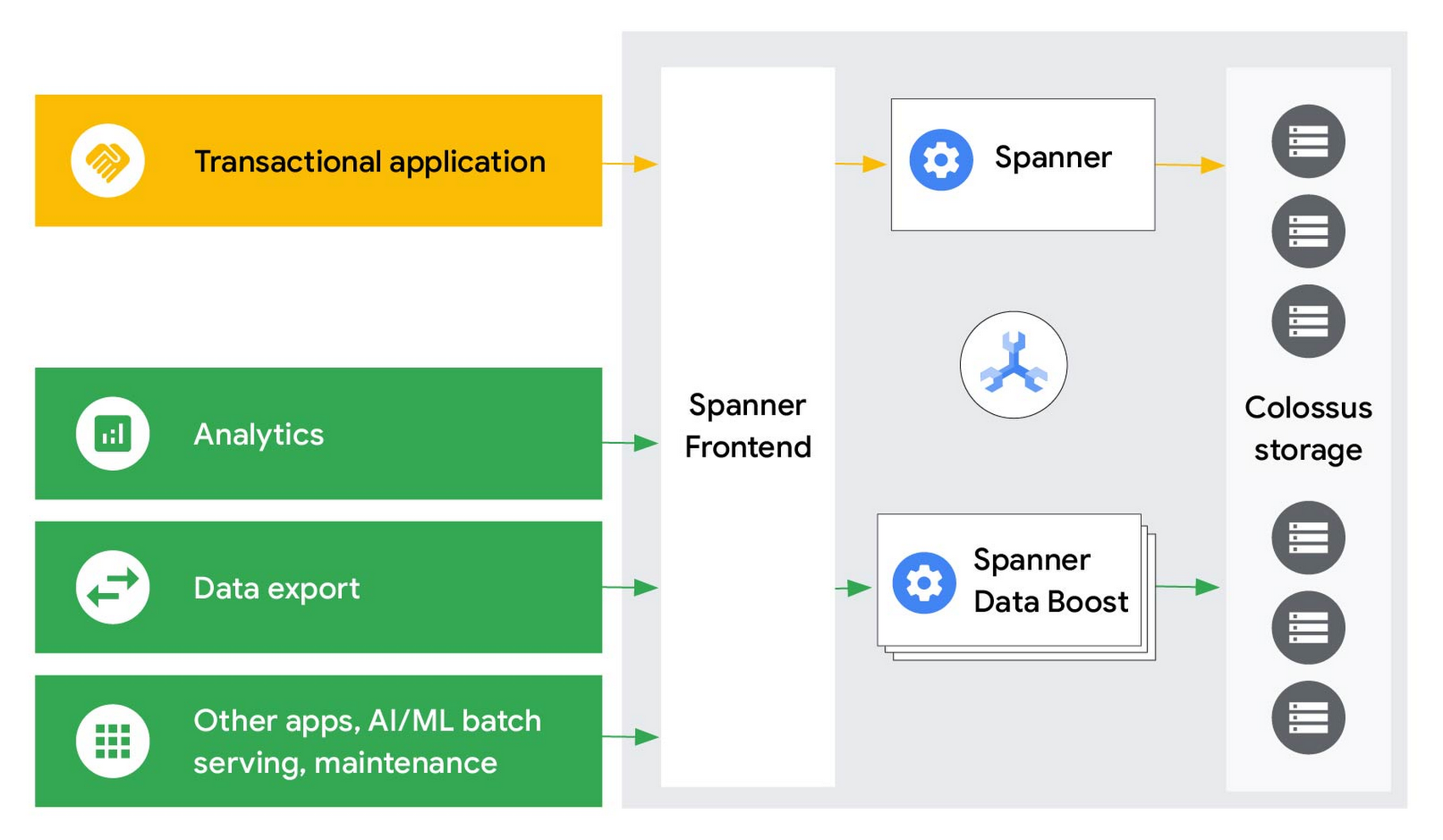
Spanner ユーザーが Data Boost の使用を開始するために必要なことは、Spanner IAM ユーザーまたはロールに Data Boost を使用する権限を与え、アプリケーション接続で Data Boost を使用することを指定することだけです。コードまたはスキーマの変更は必要ありません。データベースのオーナーは引き続きデータを完全に制御でき、特定のユーザーによる Data Boost を介したアクセスを許可または拒否できます。このモデルでは、適切なアクセス権限を持つすべてのユーザーが、キャパシティ プロビジョニング、リソース分離、スケールの制限に制約されることなく、Data Boost を介して Spanner のデータを処理できます。重要なトランザクション データのオーナーは、トランザクション ワークロードに悪影響が及ぶことを心配せずに、分析、ML モデルのトレーニング、監査用の大規模なデータ エクスポートのようなワークロードのために広範にデータ共有を許可できます。
「Data Boost のような、本番環境データから分析情報を引き出す際の運用上のオーバーヘッドを低減することを狙った機能は、本当にありがたいものです。これまで従来のデータストアに対して分析クエリを実行していたときは、本番環境データをいったん別のデータストアにプッシュしてから分析クエリを実行するのが安全な経路でした。これはミッション クリティカルな読み取り / 書き込みの中断を防ぐことを意図したものでしたが、このアプローチは管理するインフラストラクチャが多く、したがってオーバーヘッドが高くなります。Data Boost は、これを変革する方向への第一歩となるでしょう。BigQuery やその他のサードパーティ ツールを接続して、他のサービスの読み取り / 書き込みに影響を与えずに本番環境の Cloud Spanner データベースをクエリできるのは、実に強力だと思います。これはチームや組織を加速させる可能性を秘めています。」 - Deloitte Consulting LLP、AI およびデータ部門シニア マネージャー、Yatin Chopra 氏
自動化された最適化により、より少ない労力でより多くのことを行う
レイテンシに敏感なトランザクション ワークロードに影響を与えずにワークロードを混在できることに加えて、この独立したスケールアウトなデータ処理能力は、パフォーマンスも大幅に改善します。Data Boost は、クエリの実行方法を決定する際に、最適な手段を自動的かつ自立的に判断できます。たとえば、既存のワークロードとのリソース競合のリスクなしにどれだけ多くの並列度でクエリを実行できるかを判断できます。
料金は実際に使用した分だけ
この技術をより一層魅力的にしているのは、従量課金モデルです。使用量は、クエリの処理に必要な CPU、メモリ、データアクセスを含むサーバーレス処理ユニット(SPU)によって測定されます。発生する料金は、クエリによって実際に使用された SPU 分だけです。ランプアップ費用やクールダウン費用は必要ないので、全体的な費用を削減できます。ユーザーがキャパシティ プランニングや管理の負担から解放されるのは言うまでもありません。費用超過を避けるため、管理者はユーザー別または特定のクエリ別に使用状況を監査して制限することもできます。
重要なトランザクション データのオーナーは、ユーザーが必要なときに必要なデータにアクセスできるように、トランザクション ワークロードを中断させるリスクなしに、組織全体にわたる広範なデータ共有を許可できます。ユーザーはソース データベースである Spanner のデータに直接アクセスするため、きめ細かいアクセス制御などの既存のすべてのセキュリティ管理や監査コントロールが適用されます。したがって、ユーザーがアクセスできるのは権限を与えられたデータのみに限定されます。これにより、データの無秩序な拡散が軽減されます。さらに、管理すべきコピーが少なくなることから、データ ガバナンスに関する負担も少なくなります。
わずか 1 分でゼロからヒーローに
Data Boost の主な設計上の考慮事項の一つは、お客様が Data Boost を使い始めてその力を行使するために要する時間と労力を最小限に抑えることでした。私たちが目指したのは、お客様がコードではなく純粋に構成によって恩恵を受けることであり、これは成功したと思います。ユーザーはデータベース スキーマもアプリケーション コードも変更する必要はありません。必要なのは、必須の IAM 権限を付与し、既存の接続文字列またはオブジェクトに構成パラメータを追加することだけです。たとえば、BigQuery からの連携クエリ、または Cloud Spanner コンソールからのデータ エクスポート ジョブに対して Data Boost を有効にするには、文字どおりボックスをチェックするだけで済みます。
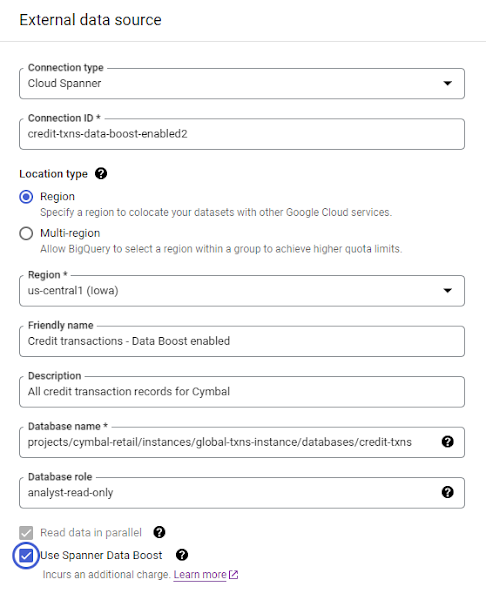
さらに、Spark ジョブや社内開発したカスタム アプリケーションで Data Boost を有効にするには、Data Boost を使用するための接続パラメータを追加するだけです。

誰もが利用できる
上記の例は主として他の Google Cloud サービスに関連していますが、Data Boost はすべての人に開かれていて、誰でもアクセスできます。すべての Spanner クライアントでサポートされているため、デベロッパーは「enableDataBoost」パラメータを追加してその値を「true」に設定するだけで、ワークロードの分離をアプリケーションに提供できます。実際、cdata、Deepnote、Denodo、Integrate.io、Nexla などの ISV はすでに自社のアプリケーションで Data Boost を有効にしています(これらの先行企業は、このブログの執筆より早くにエンジニアリング作業を完了したことを考えると、特筆に値します)。
「Integrate.io のお客様は、自社のデータ エコシステム内で卓越した相互運用性を保証するソリューションを必要としています。Google Cloud Spanner Data Boost を使用すれば、チームは Spanner インスタンス上の既存のワークロードに摩擦や影響を与えることなく分析クエリやデータ エクスポートを実行できます。」 - Integrate.io、最高技術責任者、Mark Smallcombe 氏
Data Boost を使ってみる
トランザクション データベースに対してバッチまたは分析ワークロードを実行しても、あるいはデータ共有を広範に許可しても、今やまったく心配無用です。アナリストやその他のユーザーは、レイテンシに敏感なトランザクション ワークロードに影響を与えずに、セルフサービスによって必要な最新データにアクセスでき、既存のセキュリティ管理もすべて適用されます。何より素晴らしいのは、おそらくコーヒーを飲みながらすべてのセットアップを完了でき、もう一杯飲み終わる頃にはもう全体的な運用費が下がっているかもしれない、ということです。
ご使用の環境で Data Boost を有効にする方法について詳しくは、こちらのドキュメントに記載されたガイダンスをご覧ください。あるいは、Google Cloud コンソールに移動して自力で試してみてもかまいません。きっと、こんなにすぐに使えるのかと驚かれることでしょう。
- シニア プロダクト マネージャー Joe Yong
- クラウドネイティブ データベース プロダクト マーケティング リード Ashish Chopra

