NoSQL を使用するタイミング: Bigtable が大規模なパーソナライズを推進
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
日々進化するニーズの結果として、顧客の期待は変化しています。あらゆる業界において、顧客は個人として扱われることを期待しており、自身の固有のニーズを十分に理解してそれに応えるサービスを提供するよう企業に求めています。このような概念のことを「パーソナライズ」と呼びます。パーソナライズとは、個々の顧客のニーズや好みに応じてカスタマイズされたエクスペリエンスを提供するという考え方であり、これを実現するには、顧客のエクスペリエンスを高める個別化されたインタラクションを生み出すプロセスを確立する必要があります。Salesforce によると、消費者の 84% は、番号ではなく人として扱われることが商品を購入するうえで非常に重要であると答えています。
現在産業界全体でデジタル トランスフォーメーションが進行しており、パーソナライズされたエクスペリエンスを通じて顧客へのサービス向上が図られています。たとえば、小売業者はパーソナライズされたコンテンツ、特典、おすすめ商品を提供することでエンゲージメントとコンバージョンを改善しています。広告テクノロジー組織は、広告の関連性や効果を高めるために、顧客の具体的な興味、購入意向、購買行動などの情報を活用しています。デジタル ミュージック サービスは、顧客の聴取行動や興味に基づいて、顧客が新しい音楽、再生リスト、ポッドキャストを見つけて楽しめるよう支援しています。
パーソナライズを望む顧客の声がますます強まる中、最新のテクノロジーのおかげで多くの企業がこれを実現できるようになっています。この投稿では、パーソナライズ機能の実装に伴う一般的な課題をいくつか取り上げ、それらの課題を Google Cloud の Bigtable のような革新的なデータベース技術によって解決する方法を見ていきます。Bigtable は、10 億以上のユーザーをサポートする Google マップなどの Google の中核サービスを支えるものであり、そのペタバイト規模のスケール、高可用性、高いスループット、価格性能比といった利点は、大規模なパーソナライズの実現を後押しします。
パーソナライズに関する課題
パーソナライズの中心にあるのはデータです。パーソナライズを大規模に提供するには、大量のデータ(顧客固有のデータと、顧客全体にわたる匿名化された集約データの組み合わせ)を保存、管理し、それらのデータにアクセスして個々の顧客の行動、ニーズ、好みを深く理解する必要があります。データベースは、すべてのアクティブな顧客がもたらす大量のデータを同時に高速に書き込める必要があります。さらに、顧客行動に関するデータを継続的に収集する必要もあります。これは、各ステップから次に行うべきアクションを導き出すためであり、たとえばある商品がショッピング カートに追加されたときに関連商品や補完的商品の新しいおすすめ情報を提示することができます。このようなパーソナライズに必要なデータの大部分は半構造化されたスパースデータであり、したがって柔軟なデータモデルを持つデータベースが必要になります。
大規模なパーソナライズを行うには、大量のデータをほぼリアルタイムに読み出す必要があります。そうすることで、シームレスなユーザー エクスペリエンス(アプリケーションの総レイテンシは通常 100 ms 未満)を提供するクリティカルなサービス提供パスを確立できます。これは、データベースへのリクエストの結果が 1 桁ミリ秒のレイテンシで返されなければならないことを意味します。アプリケーションのレイテンシは、同時に利用している顧客の数が増えても低下しないようにする必要があります。データは効率的に整理し、他のツールと統合する必要があります。これにより、深い分析クエリや機械学習(ML)モデルを使用してパーソナライズされたおすすめ情報を生成し、集約データをオペレーショナル データベースに保存して顧客へのサービス提供に役立てることができます。また、分析のために大規模なバッチ読み取りを行う能力も必要であり、アプリケーションのサービス提供パフォーマンスを損なわずにこれを行える必要があります。
さらに、アプリケーションの普及に伴ってデータベース費用が爆発的に増加しないようにすることも必要です。データベースには、総所有コスト(TCO)が一貫して低く、データ量やスループットのニーズが増大しても高い価格性能比が維持されるものを選ぶ必要があります。世界中のすべてのユーザーに一貫した予測可能なパフォーマンスを提供するため、データベースにはシームレスかつ線形にスケールする機能が必要です。また、複雑なデータベースの管理に手間を取られることなくアプリケーションに意識を集中できるよう、データベースは管理しやすいものでなければなりません。
NoSQL データベースがパーソナライズに最適な理由
設計上のトレードオフは、あらゆるデータベースに存在しています。40 年前にリレーショナル データベースが設計されたとき、ストレージ、コンピューティング、メモリは現在よりも数千倍高価でした。データベースは単一のサーバーにデプロイされて同時ユーザー数はかなり少なく、システムへのアクセスは、ユーザーがネットワークにアクセスできる通常の営業時間中に集中する傾向がありました。リレーショナル データベースは、このようなリソース、費用、使い方を念頭に置いて設計されました。そのため、ストレージとメモリを効率よく使用することが特に重視されており、単一のサーバーにデプロイすることが前提となっていました。
ストレージ、メモリ、コンピューティングの価格が下がり、データとワークロードが増大してコモディティ ハードウェアの容量を超えると、エンジニアは別の目標に焦点を合わせてこれらのトレードオフを再検討し始めました。その後、スケーラビリティを得るために分散アーキテクチャを前提とした新たな種類のデータベースが登場し、特にクラウド インフラストラクチャによってこの種のデータベースは簡単にスケールできるようになりました。このアプローチでは、今度は SQL の精巧さとリレーショナル システムで培われたデータ整合性機能やトランザクション機能の大部分を捨てることがトレードオフとなりました。このようなシステムのことを一般に「NoSQL データベース」と呼びます。
従来のリレーショナル データベースは、時間が経ってもほとんど変化しない固定スキーマを前提としています。このデータ構造の予測可能性にはさまざまな最適化が可能になるという利点がありますが、その一方で、新しいデータ要素や可変のデータ要素をアプリケーションに追加するのが困難で煩雑になるという側面もあります。Key-Value ストアやドキュメント データベースなどの NoSQL データベースは、スキーマの厳格さを緩和し、リレーショナル データベースよりもはるかに容易にデータ構造を経時的に進化させることができます。そのデータモデルは柔軟であり、アプリケーションのイノベーションのペースが加速するとともに、ML モデルでの反復処理の能力が向上します。これはパーソナライズに不可欠です。さらに、Cloud Bigtable のようなシステムが持つスケーラビリティには、数百万ものユーザーに同時にパーソナライズを提供しながら、カスタマー エクスペリエンスをパーソナライズする方法を進化させ続ける力があります。
Cloud Bigtable で大規模なパーソナライズを実現する方法
Cloud Bigtable には、1 秒間に数百万のリクエストを処理する、ペタバイトのデータをコスト効率よく保存する[1]、1 桁ミリ秒の一貫した読み書きレイテンシを提供するといった、大規模なパーソナライズを支える機能があります。Bigtable の特長は、高性能でありながら低い運用コストで TCO を削減している点です。
Spotify、Segment、Algolia の各社は、すでに Bigtable を使用して個々の顧客向けにパーソナライズされたエクスペリエンスを構築しています。それぞれのリンクをクリックして導入事例をご覧ください。このプレゼンテーションでは、Spotify の Peter Sobot 氏が Bigtable をパーソナライズにどのように活用しているかについて語っています。
自社のアプリケーションがロケットのように発進し、ユーザー数が 2 億 5,000 万人まで増加するシナリオを想像してみましょう。ピーク時には 175 万人のユーザーが同時にアプリケーションにアクセスし[2]、各ユーザーが 1 分間に 2 件のリクエストをデータベースに送信するとします。つまり、1 分間にデータベースに届くリクエストの数は 350 万件で、1 秒間に換算すると約 58,300 件になります。このワークロードを実行するための Bigtable の料金は、1 日あたり 400 ドル以下から始まります。[3]
Bigtable は、ノードを追加することでスループットを線形にスケールします。コンピューティングとストレージが切り離されている Bigtable は、一貫したパフォーマンスが得られるようにノードとデータの関連付けを調整することで、スループットを自動的に構成します。あるノードの負荷が高くなると、トラフィックの一部が負荷の低い別のノードに自動的に移動されて、全体的なパフォーマンスが改善されます。Bigtable は、各リージョンにローカルに書き込んだ後に別のリージョンにレプリケートするリージョン間レプリケーションもサポートしています。これにより、顧客に地理的に近い場所でデータを管理できるため、ネットワーク レイテンシが短縮され、世界中のどのリージョンの顧客にも予測可能な低レイテンシの読み取り / 書き込みを提供できます。
Bigtable は、Google Cloud によって開発、運用されている NoSQL データベースです。列ファミリーのデータモデルを備えているため、顧客の行動や好みに関連付けられた可変のデータ要素を柔軟に保存でき、すべての顧客に及ぶそのようなデータ要素を大量に保存してアプリケーションで迅速に反復処理できます。Bigtable は、それぞれ数百万の列を持つ数兆の行をサポートします。Bigtable の 1 つの行には最大 256 MB のデータを格納できるため、ある特定の顧客のパーソナライズされたデータをすべて 1 行に保持できる余裕があります。Bigtable のテーブルはスパース(低密度)であり、行内の使用されていない列についてのストレージ ペナルティはありません。つまり、料金は値が格納されている列についてのみ発生します。
BigQuery ML を使用すれば、BigQuery で直接 ML モデルを作成および実行してパーソナライズされたおすすめ情報を生成し、それを Bigtable に書き戻すことができます。Bigtable のデータは BigQuery に簡単に流し込むことができ、深い分析クエリの実行やおすすめ情報の生成に役立ちます。計算されたおすすめ情報などの集約データは Bigtable に書き戻されるため、アプリケーションからこれらのおすすめ情報を低レイテンシかつ大規模にユーザーに提示できます。
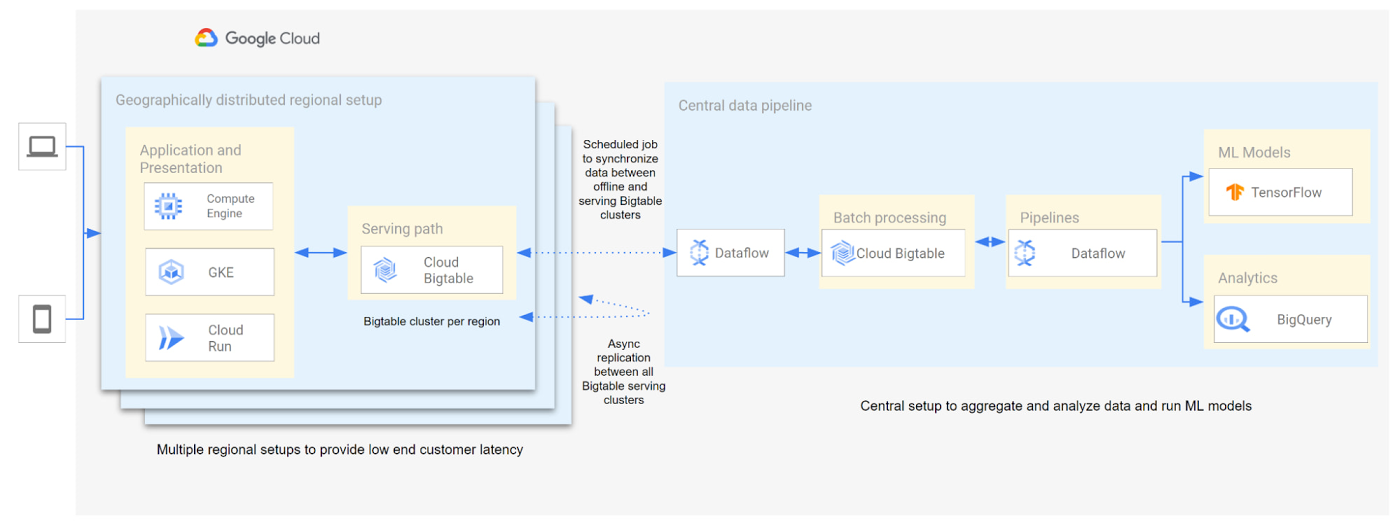
次に、e コマースにおけるパーソナライズの概念的スキーマの例を示します。
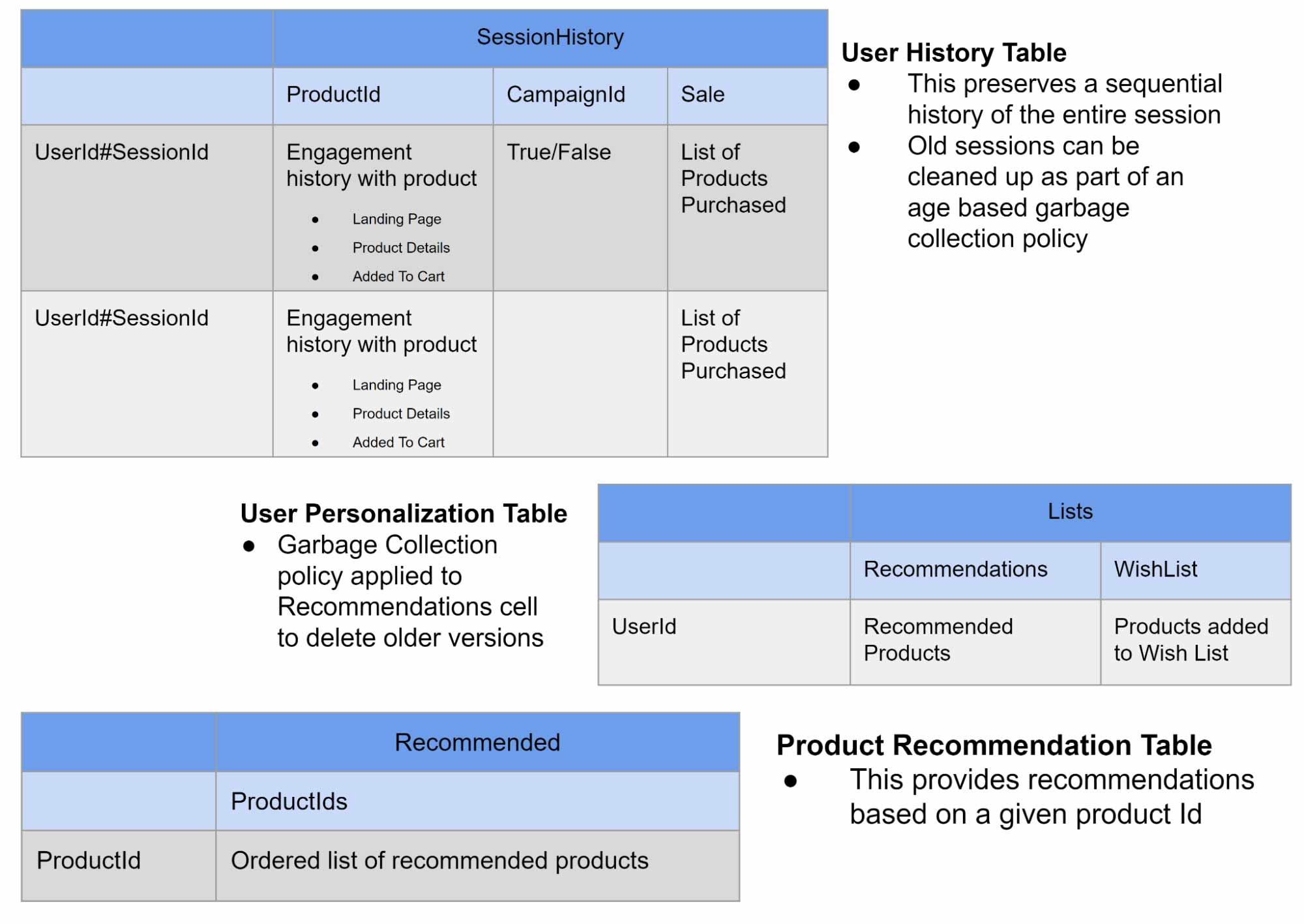
次の表は、パーソナライズのユースケース要件と Bigtable がそれらの要件にどのように対応するかを簡単にまとめたものです。
パーソナライズのユースケース要件 | Bigtable がこれらの要件に対応する方法 |
すべてのアクティブ ユーザーの大量データの高速な読み取りと書き込み | 超高速のスループット(数百万オペレーション/秒)、ノードを追加することでスループットを線形にスケール |
一貫性のある高速なパフォーマンス、アプリケーションのレイテンシは通常 100 ms 未満 | レイテンシが 10 ms 未満の一貫した読み取りと書き込み、ノードとデータの関連付けを調整することでスループットを自動的に設定 |
各顧客の行動や好みによってマッピングされたデータを大量に保存 | Bigtable の 1 つの行に最大 256 MB のデータを格納可能、数兆の行と数百万の列をサポート
|
低い TCO | 低い TCO で高スループットのワークロードに対応、費用と複雑さを低減するフルマネージド サービス、単一のクラスタをセットアップするオプション(可用性 SLA は 99.9%)によって TCO をさらに削減 |
柔軟なデータモデルで a)すべてのユーザーに及ぶ可変データ要素の保存、b)アプリケーションによる迅速な反復処理といった要件に応える | 柔軟な列ファミリー データモデル |
無制限のスケール | GB から PB までの無制限のスケール、数兆の行と数百万の列をサポート、線形のスケーラビリティ、コンピューティングとストレージを別々にスケール可能
|
ビジネス クリティカルな信頼性 | 99.99% の可用性 SLA と複数のゾーンにまたがるレプリケーション、ゾーン障害の発生時に自動的にフェイルオーバー、Google の中核サービスを支えてきた確固たる実績 |
世界中どこでも一貫したパフォーマンス | リージョン間レプリケーションによってデータをユーザーの近くに移動することが可能、世界中で低レイテンシの読み取りと書き込みを提供 |
アプリケーションの読み取り / 書き込みに影響を与えずに、大規模なバッチ読み取りや分析ワークロードを実行 | バッチ読み取りが原因でサービス提供ワークロードの処理速度が低下しないようにするため、アプリケーション プロファイルとレプリケーションを使用してワークロードを分離することが可能 |
オープンで統合されている | HBase、BigQuery、TensorFlow、Apache Beam、Hadoop、Dataproc、Dataflow と互換性あり |
管理が容易 | フルマネージド サービス |
Bigtable はフルマネージドであり、お客様をデータベース管理の複雑さから解放します。これにより、深くパーソナライズされたエクスペリエンスを顧客に提供することに専念できます。Bigtable の詳細については、こちらをご覧ください。
[1] ストレージ料金(HDD)は $0.026/GB/月から始まります(us-central1)。
[2] アプリケーションは 1 日 24 時間使用可能で、ユーザー セッションの平均時間は 5 分(Android アプリの平均)、日中のピークは平均の 2 倍とします。(2 億 5,000 万 ÷ (24 時間 ÷ 5 分) ×2 = 1,736,111 ピーク同時ユーザー数(us-central1 リージョン)
[3] Cloud Bigtable の us-central1 リージョンの料金。月あたり 25 TB の SSD ストレージ(ユーザーあたり 100 KB、ユーザー数 2 億 5,000 万人分)と
月あたり 10 のコンピューティング ノード(レプリケーションなし)を前提とし、データ バックアップを含みます。Bigtable の料金の詳細については、こちらをご覧ください。
-プロダクト管理、データベース担当ディレクター Amit Patel



